Motivating Self-Consideration | Ryan Xu
We don’t need to utterly exchange the worth of v_Riley with v_dog, so let’s say that we take a linear mixture of v_Riley and v_dog as the brand new worth for v_Riley:
v_Riley = get_value('Riley')
v_dog = get_value('canine')ratio = .75
v_Riley = (ratio * v_Riley) + ((1-ratio) * v_dog)
This appears to work alright, we’ve embedded a little bit of the that means of the phrase “canine” into the phrase “Riley”.
Now we wish to try to apply this type of consideration to the entire sentence by updating the vector representations of each single phrase by the vector representations of each different phrase.
What goes unsuitable right here?
The core downside is that we don’t know which phrases ought to tackle the meanings of different phrases. We might additionally like some measure of how a lot the worth of every phrase ought to contribute to one another phrase.
Half 2
Alright. So we have to know the way a lot two phrases needs to be associated.
Time for try quantity 2.
I’ve redesigned our vector database so that every phrase truly has two related vectors. The primary is similar worth vector that we had earlier than, nonetheless denoted by v. As well as, we now have unit vectors denoted by ok that retailer some notion of phrase relations. Particularly, if two ok vectors are shut collectively, it signifies that the values related to these phrases are more likely to affect one another’s meanings.
With our new ok and v vectors, how can we modify our earlier scheme to replace v_Riley’s worth with v_dog in a manner that respects how a lot two phrases are associated?
Let’s proceed with the identical linear mixture enterprise as earlier than, however provided that the ok vectors of each are shut in embedding house. Even higher, we will use the dot product of the 2 ok vectors (which vary from 0–1 since they’re unit vectors) to inform us how a lot we should always replace v_Riley with v_dog.
v_Riley, v_dog = get_value('Riley'), get_value('canine')
k_Riley, k_dog = get_key('Riley'), get_key('canine')relevance = k_Riley · k_dog # dot product
v_Riley = (relevance) * v_Riley + (1 - relevance) * v_dog
It is a little bit unusual since if relevance is 1, v_Riley will get utterly changed by v_dog, however let’s ignore that for a minute.
I need to as a substitute take into consideration what occurs once we apply this sort of thought to the entire sequence. The phrase “Riley” can have a relevance worth with one another phrase by way of dot product of oks. So, perhaps we will as a substitute replace the worth of every phrase proportionally to the worth of the dot product. For simplicity, let’s additionally embrace it’s dot product with itself as a strategy to protect it’s personal worth.
sentence = "Evan's canine Riley is so hyper, she by no means stops transferring"
phrases = sentence.cut up()# get hold of a listing of values
values = get_values(phrases)
# oh yeah, that is what ok stands for by the best way
keys = get_keys(phrases)
# get riley's relevance key
riley_index = phrases.index('Riley')
riley_key = keys[riley_index]
# generate relevance of "Riley" to one another phrase
relevances = [riley_key · key for key in keys] #nonetheless pretending python has ·
# normalize relevances to sum to 1
relevances /= sum(relevances)
# takes a linear mixture of values, weighted by relevances
v_Riley = relevances · values
Okay that’s adequate for now.
However as soon as once more, I declare that there’s one thing unsuitable with this method. It’s not that any of our concepts have been carried out incorrectly, however moderately there’s one thing basically completely different between this method and the way we truly take into consideration relationships between phrases.
If there’s any level on this article the place I actually actually suppose that it is best to cease and suppose, it’s right here. Even these of you who suppose you totally perceive consideration. What’s unsuitable with our method?

Relationships between phrases are inherently uneven! The way in which that “Riley” attends to “canine” is completely different from the best way that “canine” attends to “Riley”. It’s a a lot greater deal that “Riley” refers to a canine, not a human, then the identify of the canine.
In distinction, the dot product is a symmetric operation, which signifies that in our present setup, if a attends to b, then b attends equally sturdy to a! Really, that is considerably false as a result of we’re normalizing the relevance scores, however the level is that the phrases ought to have the choice of attending in an uneven manner, even when the opposite tokens are held fixed.
Half 3
We’re virtually there! Lastly, the query turns into:
How can we most naturally lengthen our present setup to permit for uneven relationships?
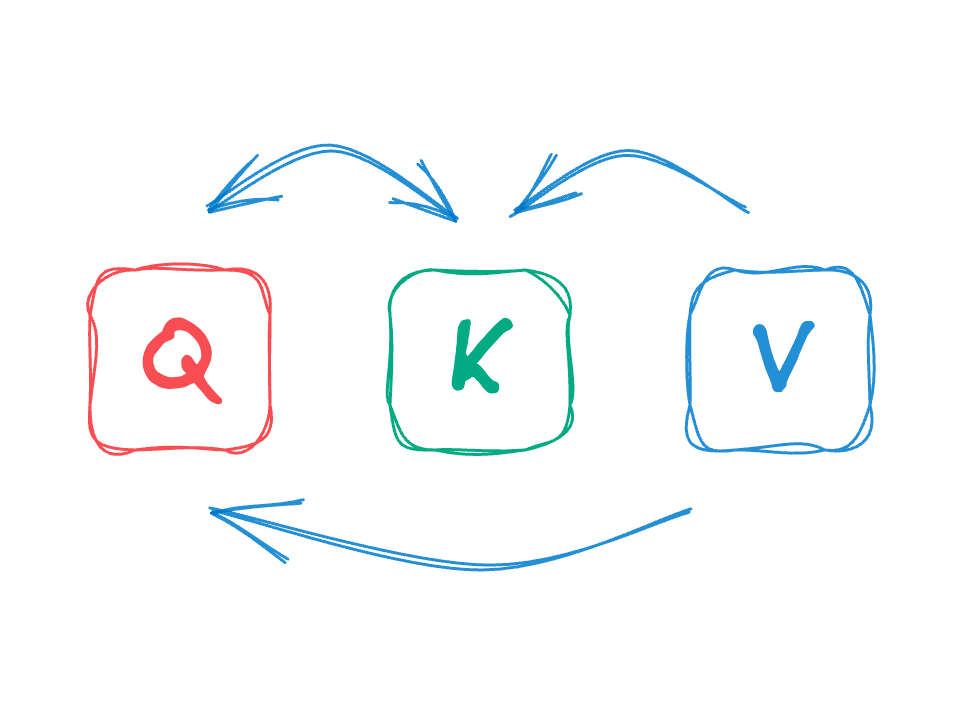
Properly what can we do with yet another vector kind? We nonetheless have our price vectors v, and our relation vector ok. Now we now have yet one more vector q for every token.
How can we modify our setup and use q to realize the uneven relationship that we wish?
These of you who’re accustomed to how self-attention works will hopefully be smirking at this level.
As a substitute of computing relevance k_dog · k_Riley when “canine” attends to “Riley”, we will as a substitute question q_Riley towards the key k_dog by taking their dot product. When computing the opposite manner round, we can have q_dog · k_Riley as a substitute — uneven relevance!
Right here’s the entire thing collectively, computing the replace for each worth without delay!
sentence = "Evan's canine Riley is so hyper, she by no means stops transferring"
phrases = sentence.cut up()
seq_len = len(phrases)# get hold of arrays of queries, keys, and values, every of form (seq_len, n)
Q = array(get_queries(phrases))
Ok = array(get_keys(phrases))
V = array(get_values(phrases))
relevances = Q @ Ok.T
normalized_relevances = relevances / relevances.sum(axis=1)
new_V = normalized_relevances @ V





