Speed up time to perception with Amazon SageMaker Knowledge Wrangler and the facility of Apache Hive

Amazon SageMaker Data Wrangler reduces the time it takes to mixture and put together knowledge for machine studying (ML) from weeks to minutes in Amazon SageMaker Studio. Knowledge Wrangler allows you to entry knowledge from all kinds of widespread sources (Amazon S3, Amazon Athena, Amazon Redshift, Amazon EMR and Snowflake) and over 40 different third-party sources. Beginning at the moment, you possibly can connect with Amazon EMR Hive as an enormous knowledge question engine to herald massive datasets for ML.
Aggregating and making ready massive quantities of knowledge is a essential a part of ML workflow. Knowledge scientists and knowledge engineers use Apache Spark, Apache Hive, and Presto working on Amazon EMR for large-scale knowledge processing. This weblog submit will undergo how knowledge professionals might use SageMaker Knowledge Wrangler’s visible interface to find and connect with current Amazon EMR clusters with Hive endpoints. To prepare for modeling or reporting, they will visually analyze the database, tables, schema, and creator Hive queries to create the ML dataset. Then, they will rapidly profile knowledge utilizing Knowledge Wrangler visible interface to judge knowledge high quality, spot anomalies and lacking or incorrect knowledge, and get recommendation on how you can take care of these issues. They will leverage extra widespread and ML-powered built-in analyses and 300+ built-in transformations supported by Spark to research, clear, and engineer options with out writing a single line of code. Lastly, they will additionally prepare and deploy fashions with SageMaker Autopilot, schedule jobs, or operationalize knowledge preparation in a SageMaker Pipeline from Knowledge Wrangler’s visible interface.
Answer overview
With SageMaker Studio setups, knowledge professionals can rapidly establish and connect with current EMR clusters. As well as, knowledge professionals can uncover EMR clusters from SageMaker Studio using predefined templates on demand in only a few clicks. Prospects can use SageMaker Studio common pocket book and write code in Apache Spark, Hive, Presto or PySpark to carry out knowledge preparation at scale. Nonetheless, not all knowledge professionals are acquainted with writing Spark code to arrange knowledge as a result of there’s a steep studying curve concerned. They will now rapidly and easily connect with Amazon EMR with out writing a single line of code, because of Amazon EMR being an information supply for Amazon SageMaker Knowledge Wrangler.
The next diagram represents the totally different parts used on this answer.
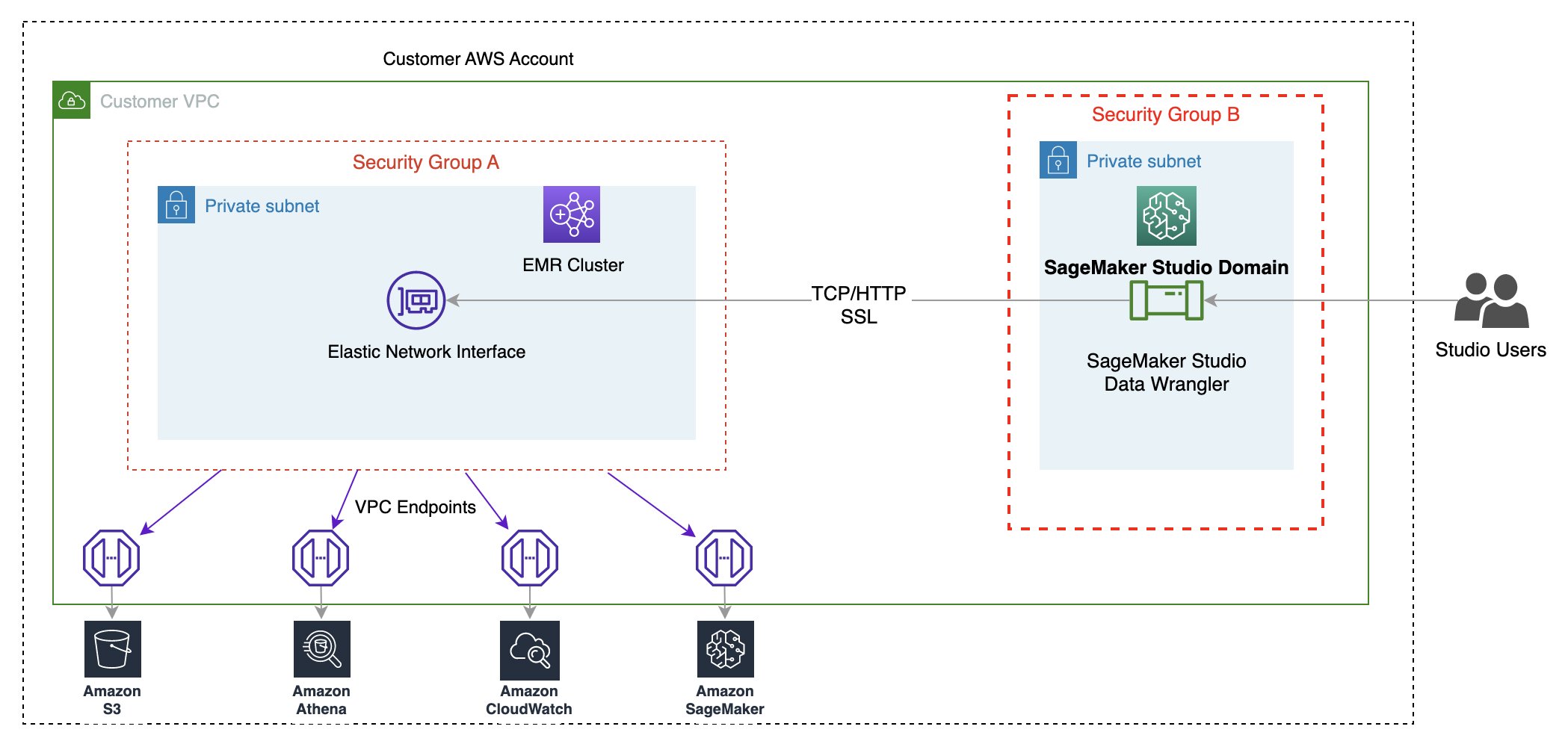
We show two authentication choices that can be utilized to determine a connection to the EMR cluster. For every possibility, we deploy a singular stack of AWS CloudFormation templates.
The CloudFormation template performs the next actions when every possibility is chosen:
- Creates a Studio Area in VPC-only mode, together with a person profile named
studio-user. - Creates constructing blocks, together with the VPC, endpoints, subnets, safety teams, EMR cluster, and different required sources to efficiently run the examples.
- For the EMR cluster, connects the AWS Glue Knowledge Catalog as metastore for EMR Hive and Presto, creates a Hive desk in EMR, and fills it with knowledge from a US airport dataset.
- For the LDAP CloudFormation template, creates an Amazon Elastic Compute Cloud (Amazon EC2) occasion to host the LDAP server to authenticate the Hive and Presto LDAP person.
Choice 1: Light-weight Entry Listing Protocol
For the LDAP authentication CloudFormation template, we provision an Amazon EC2 occasion with an LDAP server and configure the EMR cluster to make use of this server for authentication. That is TLS enabled.
Choice 2: No-Auth
Within the No-Auth authentication CloudFormation template, we use a regular EMR cluster with no authentication enabled.
Deploy the sources with AWS CloudFormation
Full the next steps to deploy the setting:
- Check in to the AWS Management Console as an AWS Identity and Access Management (IAM) person, ideally an admin person.
- Select Launch Stack to launch the CloudFormation template for the suitable authentication situation. Be sure the Area used to deploy the CloudFormation stack has no current Studio Area. If you have already got a Studio Area in a Area, you could select a distinct Area.
LDAP 
No Auth - Select Subsequent.
- For Stack title, enter a reputation for the stack (for instance,
dw-emr-hive-blog). - Go away the opposite values as default.
- To proceed, select Subsequent from the stack particulars web page and stack choices.
The LDAP stack makes use of the next credentials.- username:
david - password:
welcome123
- username:
- On the evaluate web page, choose the test field to substantiate that AWS CloudFormation may create sources.
- Select Create stack. Wait till the standing of the stack modifications from
CREATE_IN_PROGRESStoCREATE_COMPLETE. The method normally takes 10–quarter-hour.
Arrange the Amazon EMR as an information supply in Knowledge Wrangler
On this part, we cowl connecting to the present Amazon EMR cluster created by way of the CloudFormation template as an information supply in Knowledge Wrangler.
Create a brand new knowledge circulation
To create your knowledge circulation, full the next steps:
- On the SageMaker console, click on Domains, then click on on StudioDomain created by working above CloudFormation template.
- Choose studio-user person profile and launch Studio.

- Select Open studio.
- Within the Studio House console, select Import & put together knowledge visually. Alternatively, on the File dropdown, select New, then select Knowledge Wrangler Move.
- Creating a brand new circulation can take a couple of minutes. After the circulation has been created, you see the Import knowledge web page.

- Add Amazon EMR as an information supply in Knowledge Wrangler. On the Add knowledge supply menu, select Amazon EMR.

You possibly can browse all of the EMR clusters that your Studio execution position has permissions to see. You’ve got two choices to connect with a cluster; one is thru interactive UI, and the opposite is to first create a secret using AWS Secrets Manager with JDBC URL, together with EMR cluster info, after which present the saved AWS secret ARN within the UI to connect with Hive. On this weblog, we observe the primary possibility.
- Choose one of many following clusters that you simply wish to use. Click on on Subsequent, and choose endpoints.

- Choose Hive, connect with Amazon EMR, create a reputation to establish your connection, and click on Subsequent.

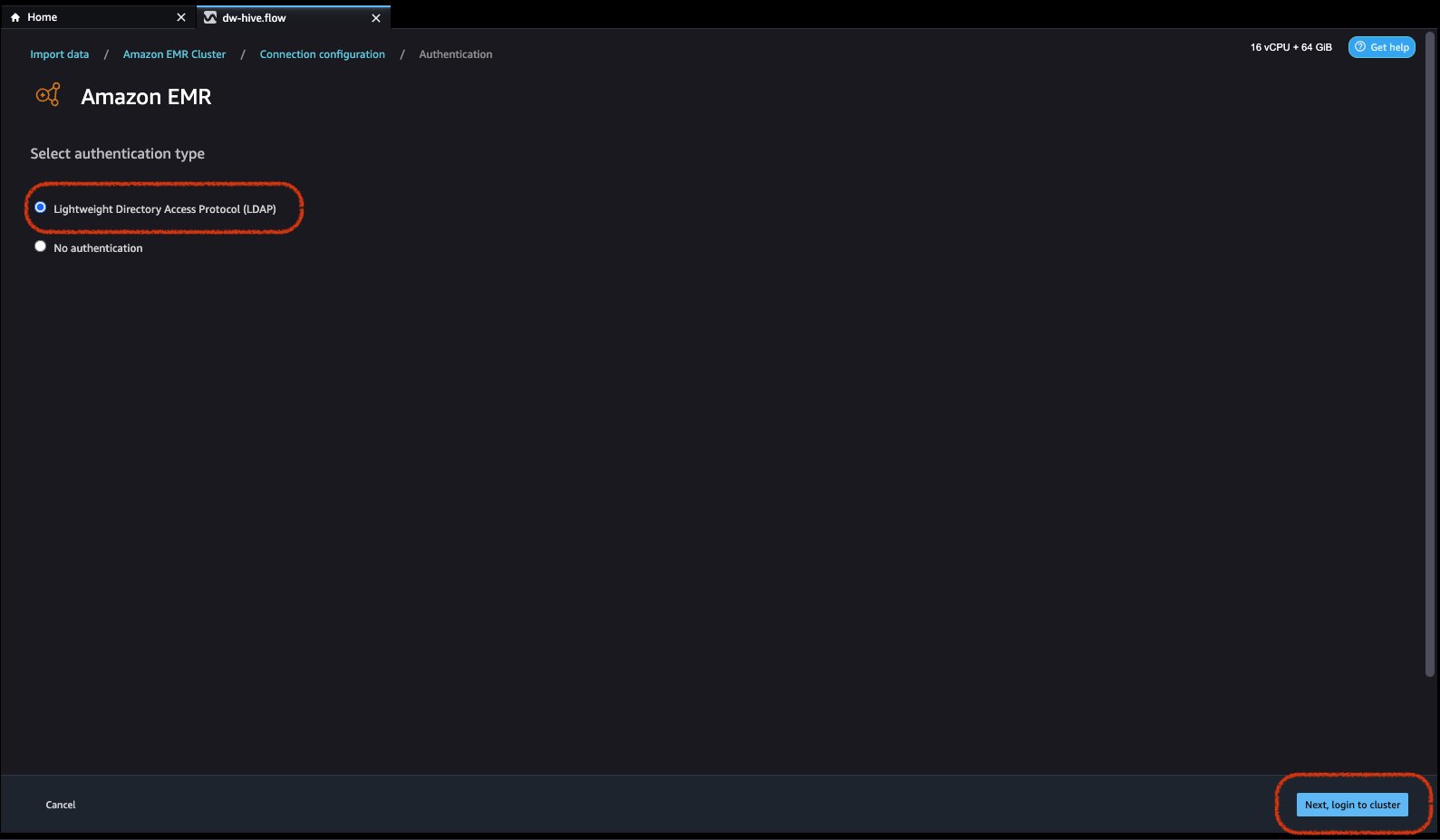
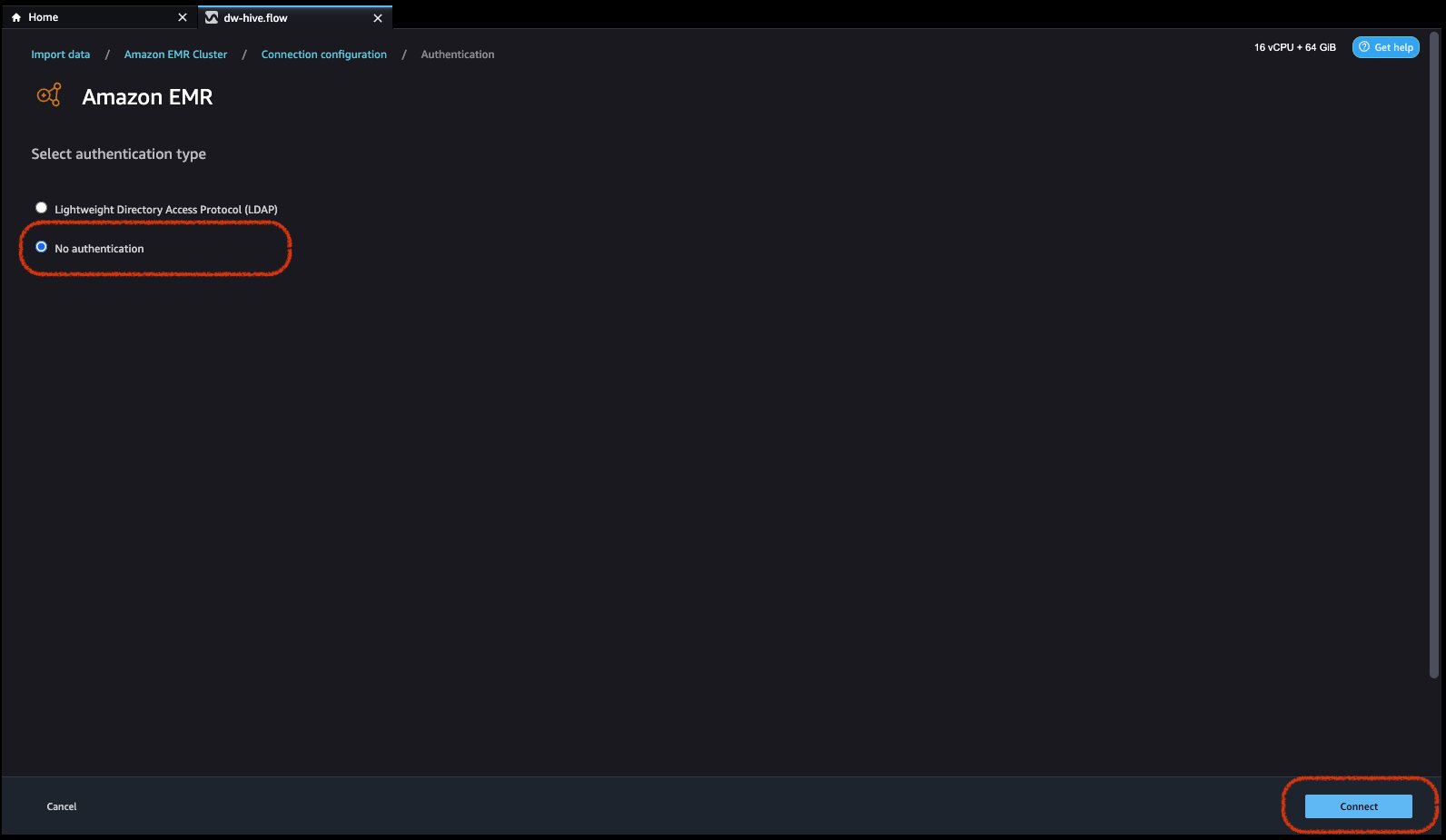
- Choose authentication kind, both Light-weight Listing Entry Protocol (LDAP) or No authentication.
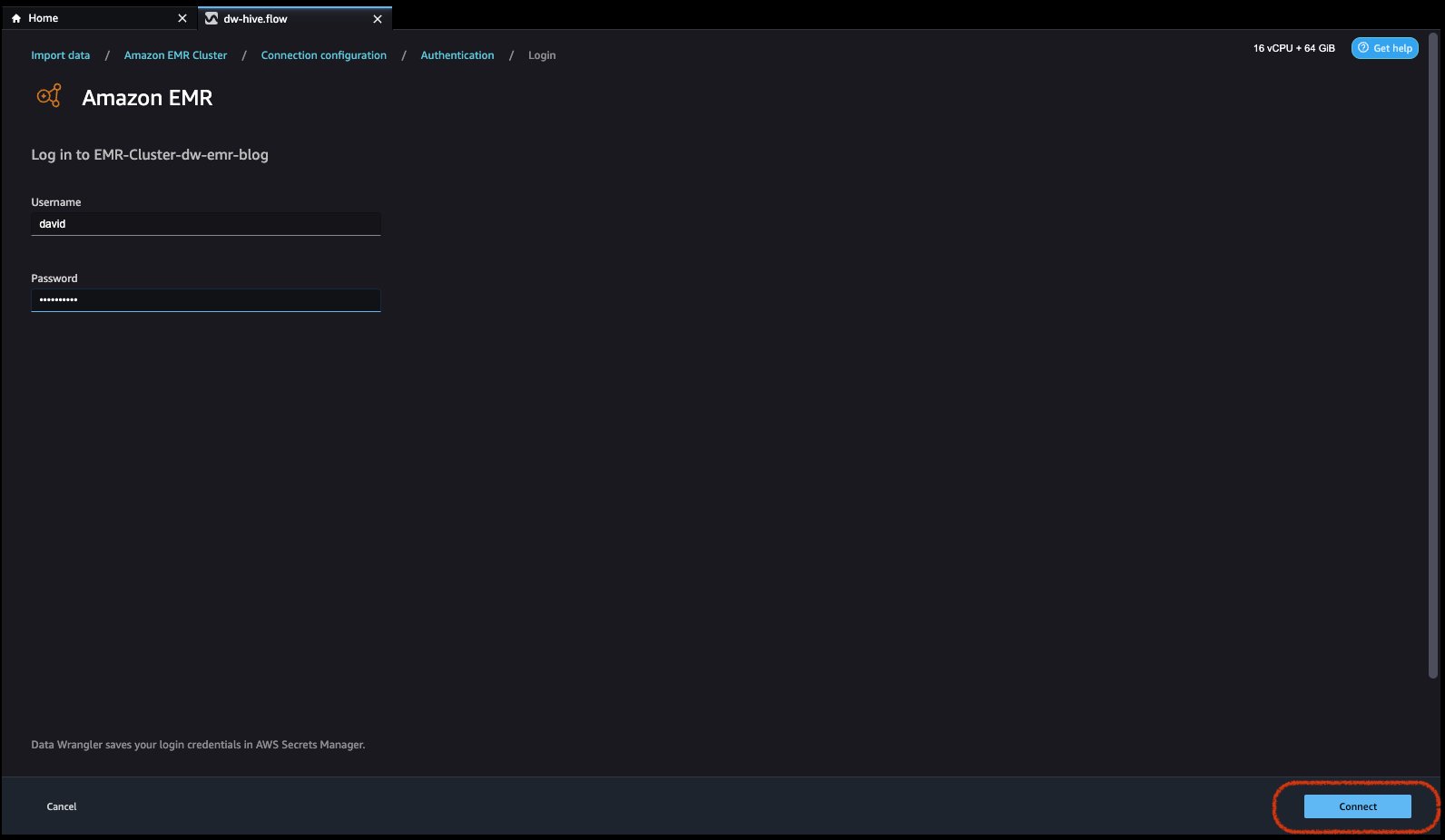
For Light-weight Listing Entry Protocol (LDAP), choose the choice and click on Subsequent, login to cluster, then present username and password to be authenticated and click on Join.
For No Authentication, you’ll be related to EMR Hive with out offering person credentials inside VPC. Enter Knowledge Wrangler’s SQL explorer web page for EMR.
- As soon as related, you possibly can interactively view a database tree and desk preview or schema. You may as well question, discover, and visualize knowledge from EMR. For preview, you’ll see a restrict of 100 data by default. When you present a SQL assertion within the question editor field and click on the Run button, the question will likely be executed on EMR’s Hive engine to preview the info.

The Cancel question button permits ongoing queries to be canceled if they’re taking an unusually very long time.
- The final step is to import. As soon as you might be prepared with the queried knowledge, you could have choices to replace the sampling settings for the info choice in keeping with the sampling kind (FirstK, Random, or Stratified) and sampling measurement for importing knowledge into Knowledge Wrangler.
Click on Import. The put together web page will likely be loaded, permitting you so as to add varied transformations and important evaluation to the dataset.
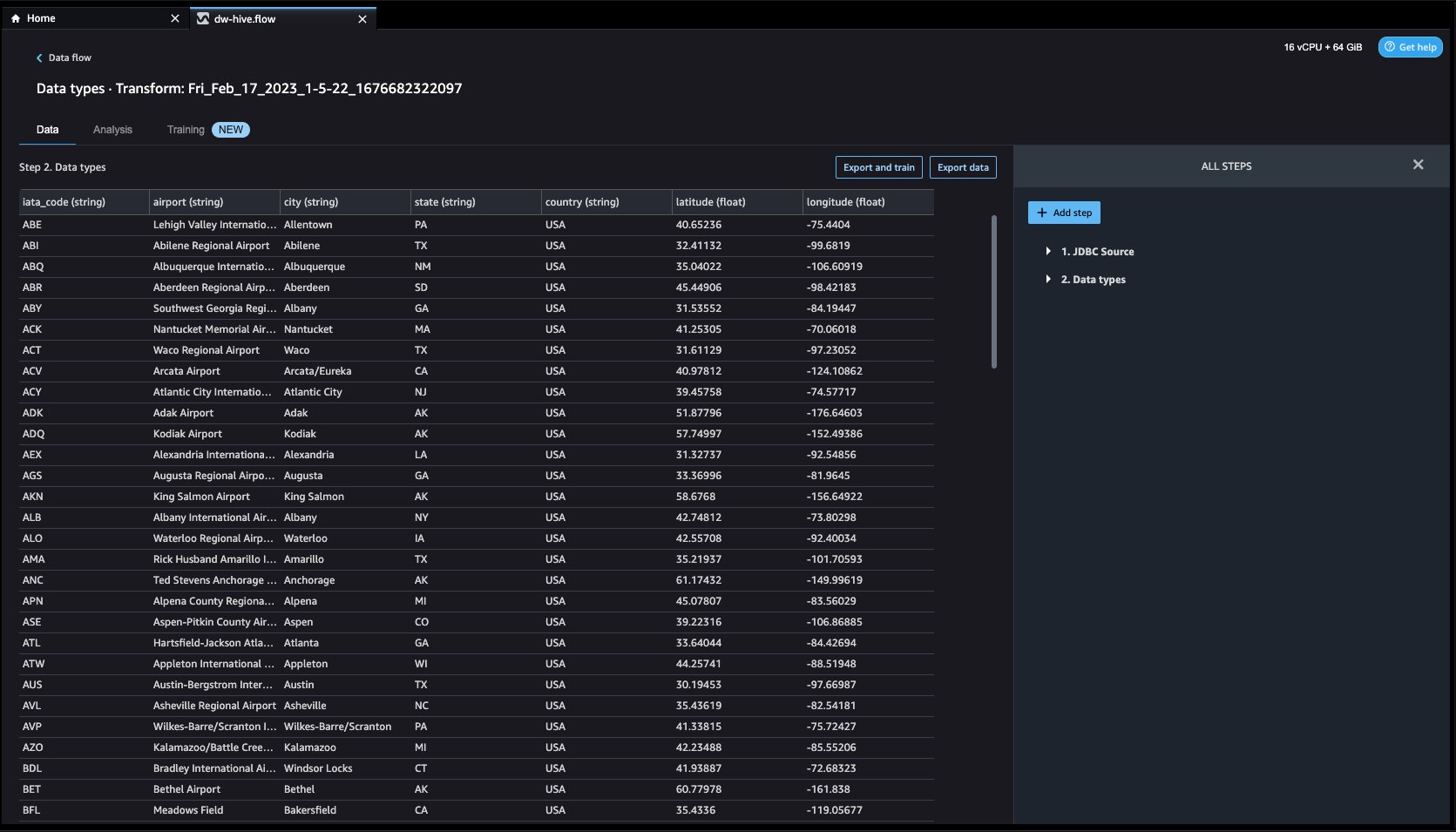
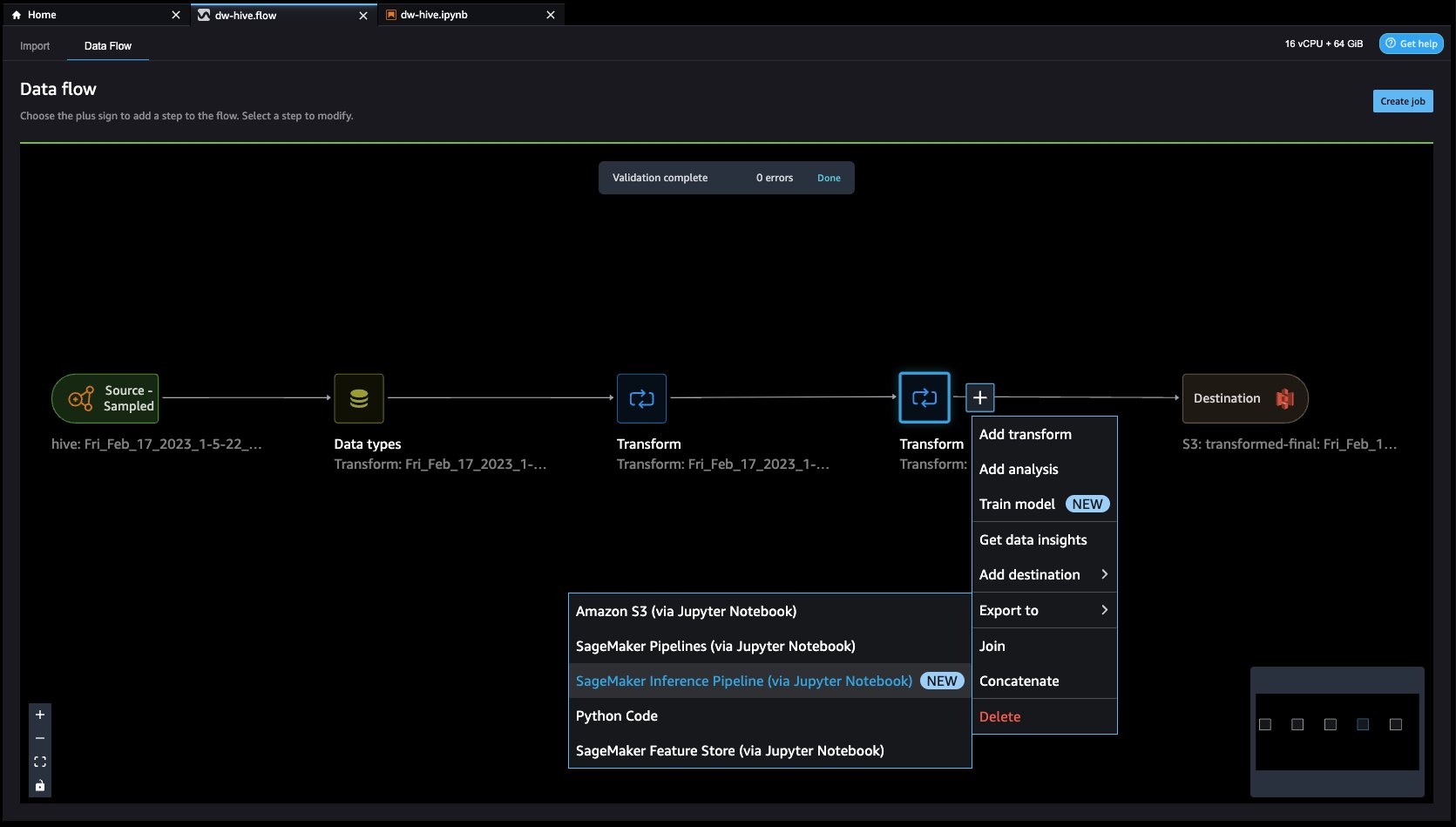
- Navigate to Knowledge circulation from the highest display screen and add extra steps to the circulation as wanted for transformations and evaluation. You possibly can run a data insight report to establish knowledge high quality points and get suggestions to repair these points. Let’s have a look at some instance transforms.
- Within the Knowledge circulation view, you must see that we’re utilizing EMR as an information supply utilizing the Hive connector.

- Let’s click on on the + button to the correct of Knowledge sorts and choose Add rework. While you do this, you’ll return to the Knowledge view.

Let’s discover the info. We see that it has a number of options corresponding to iata_code, airport, metropolis, state, nation, latitude, and longitude. We will see that the complete dataset is predicated in a single nation, which is the US, and there are lacking values in latitude and longitude. Lacking knowledge could cause bias within the estimation of parameters, and it may well scale back the representativeness of the samples, so we have to carry out some imputation and deal with lacking values in our dataset.

- Let’s click on on the Add Step button on the navigation bar to the correct. Choose Deal with lacking. The configurations could be seen within the following screenshots.
Below Remodel, choose Impute. Choose the Column kind as Numeric and Enter column names latitude and longitude. We will likely be imputing the lacking values utilizing an approximate median worth.
First click on on Preview to view the lacking worth after which click on on replace so as to add the rework.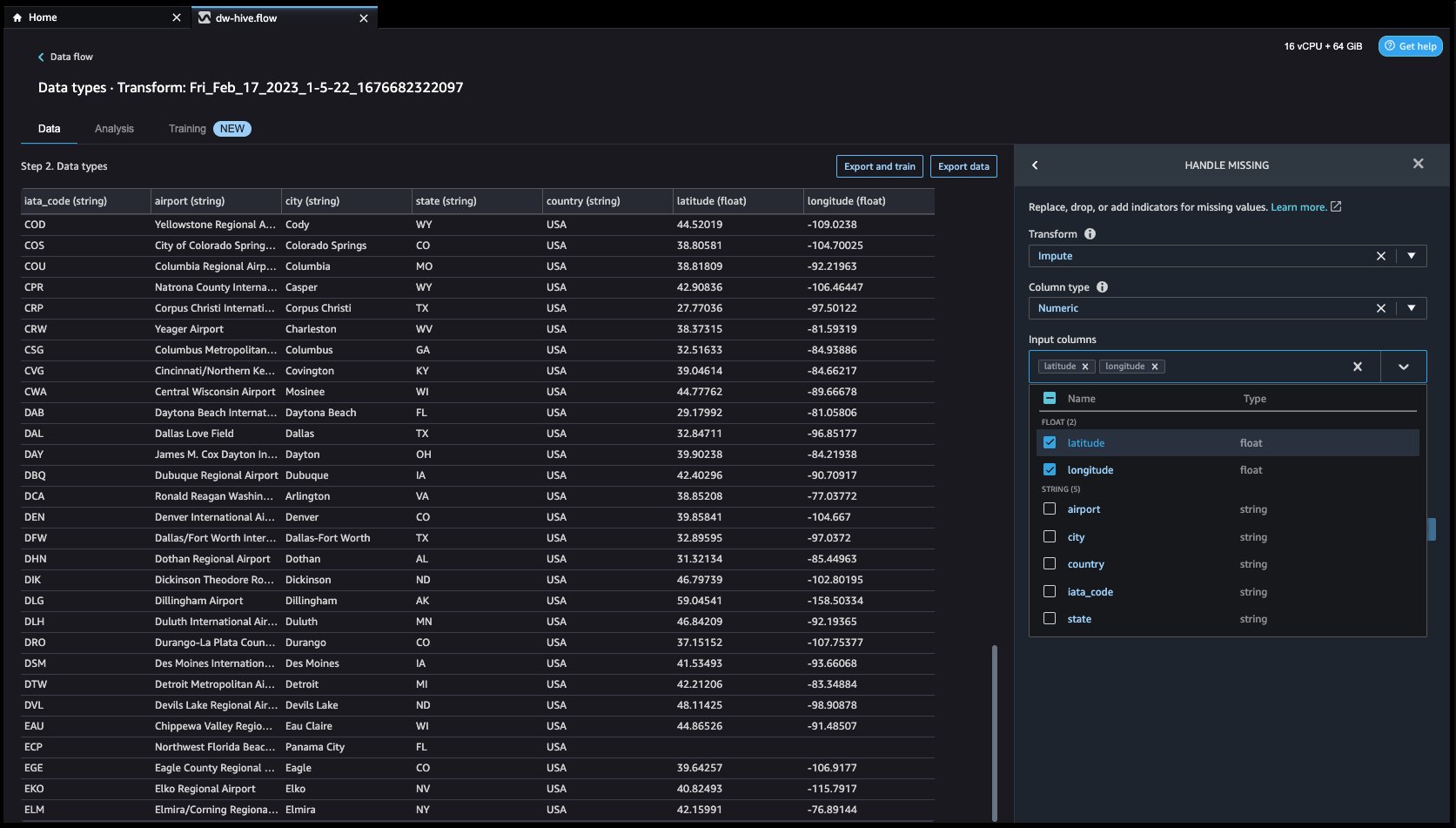
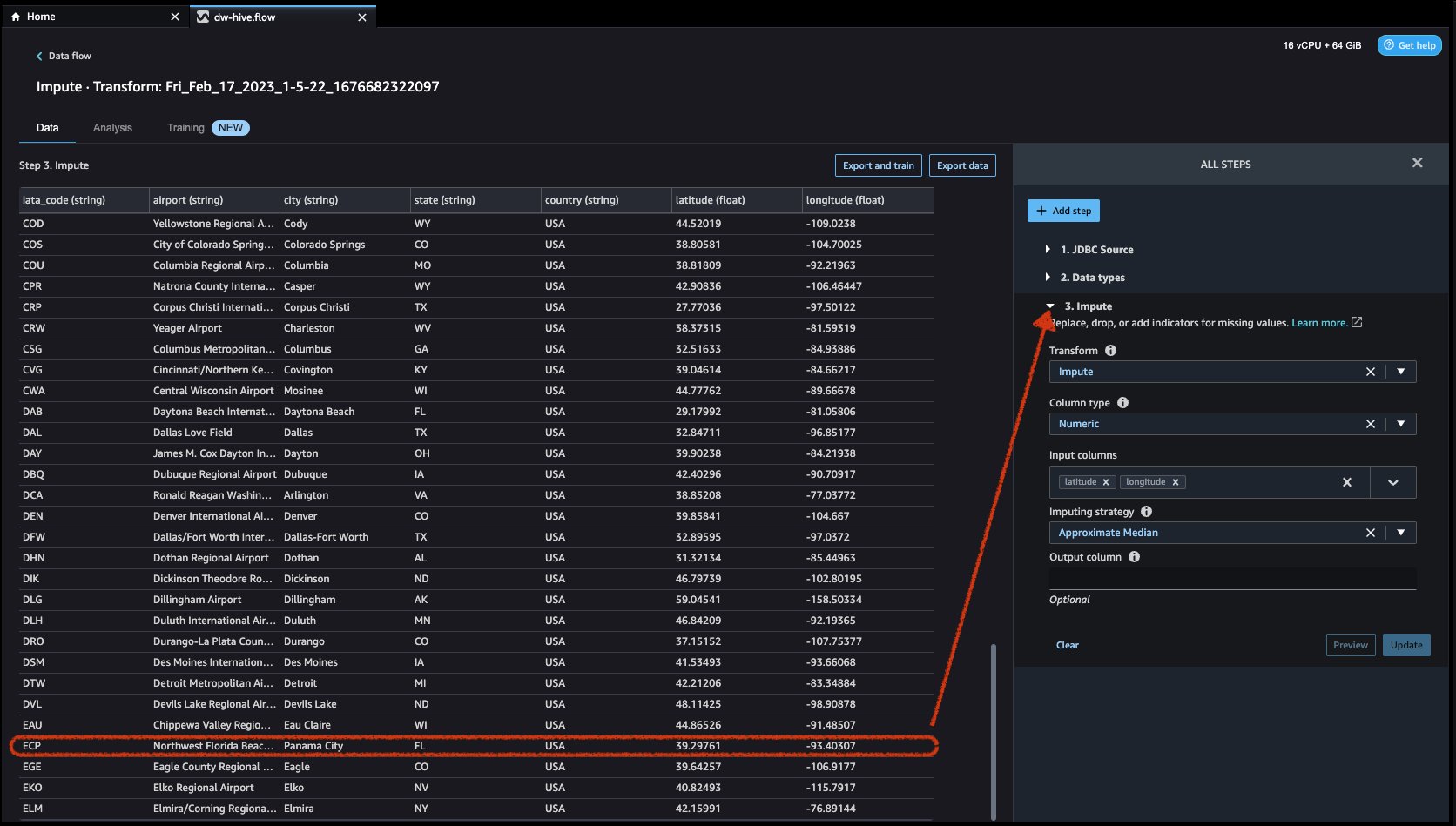
- Allow us to now have a look at one other instance rework. When constructing an ML mannequin, columns are eliminated if they’re redundant or don’t assist your mannequin. The commonest solution to take away a column is to drop it. In our dataset, the characteristic nation could be dropped because the dataset is particularly for US airport knowledge. To handle columns, click on on the Add step button on the navigation bar to the correct and choose Handle columns. The configurations could be seen within the following screenshots. Below Remodel, choose Drop column, and underneath Columns to drop, choose nation.


- Click on on Preview after which Replace to drop the column.

- Function Retailer is a repository to retailer, share, and handle options for ML fashions. Let’s click on on the + button to the correct of Drop column. Choose Export to and select SageMaker Feature Store (by way of Jupyter pocket book).

- By choosing SageMaker Feature Store because the vacation spot, it can save you the options into an current characteristic group or create a brand new one.


We have now now created options with Knowledge Wrangler and simply saved these options in Function Retailer. We confirmed an instance workflow for characteristic engineering within the Knowledge Wrangler UI. Then we saved these options into Function Retailer instantly from Knowledge Wrangler by creating a brand new characteristic group. Lastly, we ran a processing job to ingest these options into Function Retailer. Knowledge Wrangler and Function Retailer collectively helped us construct computerized and repeatable processes to streamline our knowledge preparation duties with minimal coding required. Knowledge Wrangler additionally gives us flexibility to automate the identical knowledge preparation flow utilizing scheduled jobs. We will additionally routinely train and deploy models using SageMaker Autopilot from Knowledge Wrangler’s visible interface, or create coaching or characteristic engineering pipeline with SageMaker Pipelines (by way of Jupyter Pocket book) and deploy to the inference endpoint with SageMaker inference pipeline (by way of Jupyter Pocket book).
Clear up
In case your work with Knowledge Wrangler is full, the next steps will assist you to delete the sources created to keep away from incurring extra charges.
- Shut down SageMaker Studio.
From inside SageMaker Studio, shut all of the tabs, then choose File then Shut Down. As soon as prompted choose Shutdown All.

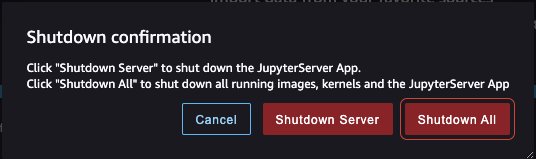
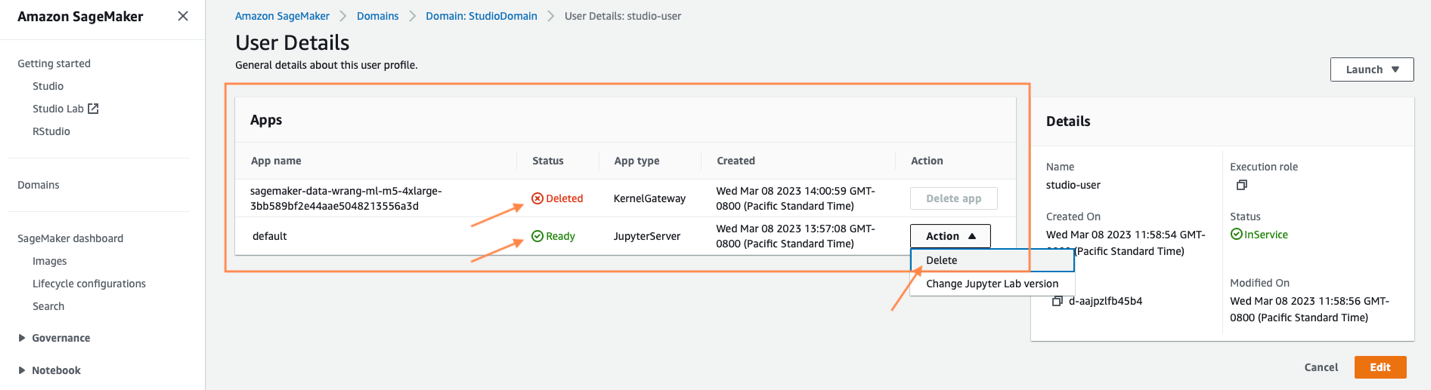
Shutdown may take a couple of minutes based mostly on the occasion kind. Be sure all of the apps related to the person profile obtained deleted. In the event that they weren’t deleted, manually delete the app related underneath person profile.
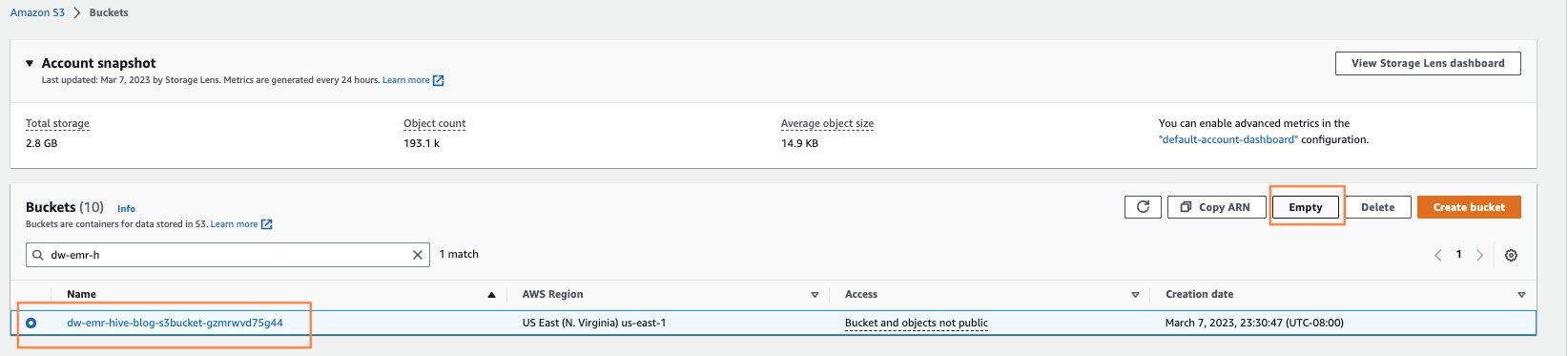
- Empty any S3 buckets that had been created from CloudFormation launch.
Open the Amazon S3 web page by looking for S3 within the AWS console search. Empty any S3 buckets that had been created when provisioning clusters. The bucket can be of format dw-emr-hive-blog-.
- Delete the SageMaker Studio EFS.
Open the EFS web page by looking for EFS within the AWS console search.
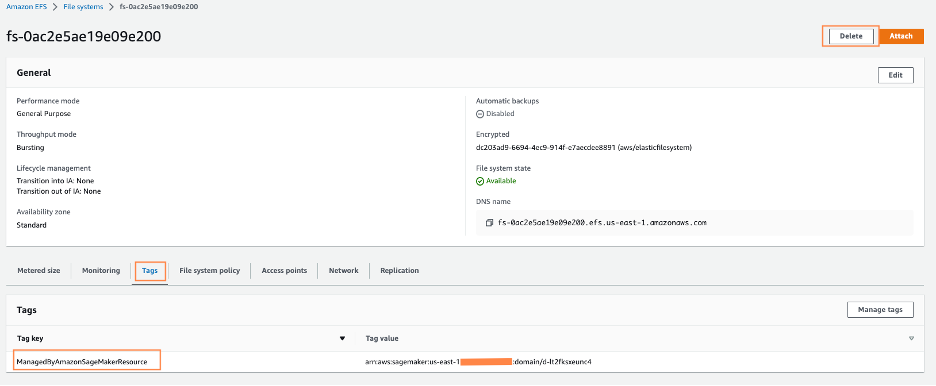
Find the filesystem that was created by SageMaker. You possibly can affirm this by clicking on the File system ID and confirming the tag ManagedByAmazonSageMakerResource on the Tags tab.
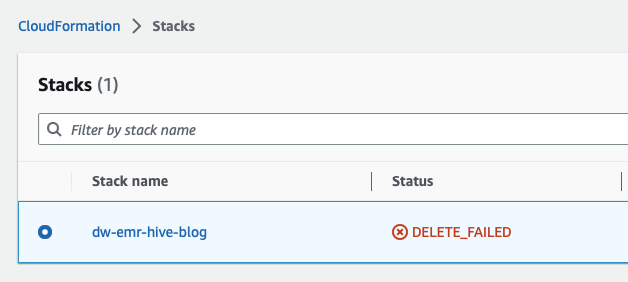
- Delete the CloudFormation stacks. Open CloudFormation by looking for and opening the CloudFormation service from the AWS console.
Choose the template beginning with dw- as proven within the following display screen and delete the stack as proven by clicking on the Delete button.

That is anticipated and we are going to come again to this and clear it up within the subsequent steps.
- Delete the VPC after the CloudFormation stack fails to finish. First open VPC from the AWS console.
- Subsequent, establish the VPC that was created by the SageMaker Studio CloudFormation, titled
dw-emr-, after which observe the prompts to delete the VPC.
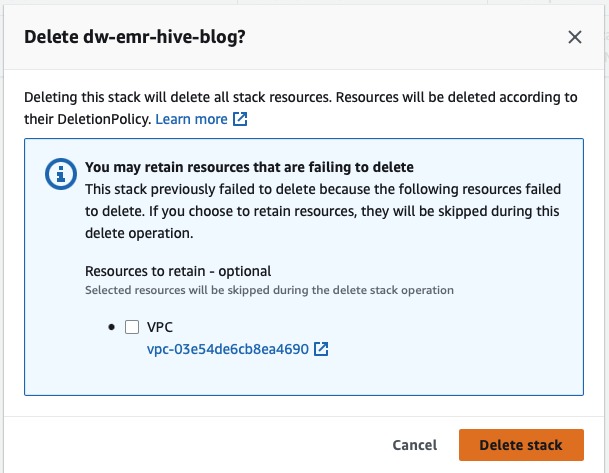
- Delete the CloudFormation stack.
Return to CloudFormation and retry the stack deletion for dw-emr-hive-blog.
Full! All of the sources provisioned by the CloudFormation template described on this weblog submit will now be eliminated out of your account.
Conclusion
On this submit, we went over how you can arrange Amazon EMR as an information supply in Knowledge Wrangler, how you can rework and analyze a dataset, and how you can export the outcomes to a knowledge circulation to be used in a Jupyter pocket book. After visualizing our dataset utilizing Knowledge Wrangler’s built-in analytical options, we additional enhanced our knowledge circulation. The truth that we created an information preparation pipeline with out writing a single line of code is critical.
To get began with Knowledge Wrangler, see Prepare ML Data with Amazon SageMaker Data Wrangler and see the newest info on the Data Wrangler product page and AWS technical documents.
Concerning the Authors
 Ajjay Govindaram is a Senior Options Architect at AWS. He works with strategic prospects who’re utilizing AI/ML to unravel complicated enterprise issues. His expertise lies in offering technical route in addition to design help for modest to large-scale AI/ML utility deployments. His data ranges from utility structure to large knowledge, analytics, and machine studying. He enjoys listening to music whereas resting, experiencing the outside, and spending time together with his family members.
Ajjay Govindaram is a Senior Options Architect at AWS. He works with strategic prospects who’re utilizing AI/ML to unravel complicated enterprise issues. His expertise lies in offering technical route in addition to design help for modest to large-scale AI/ML utility deployments. His data ranges from utility structure to large knowledge, analytics, and machine studying. He enjoys listening to music whereas resting, experiencing the outside, and spending time together with his family members.
 Isha Dua is a Senior Options Architect based mostly within the San Francisco Bay Space. She helps AWS enterprise prospects develop by understanding their targets and challenges, and guides them on how they will architect their functions in a cloud-native method whereas making certain resilience and scalability. She’s obsessed with machine studying applied sciences and environmental sustainability.
Isha Dua is a Senior Options Architect based mostly within the San Francisco Bay Space. She helps AWS enterprise prospects develop by understanding their targets and challenges, and guides them on how they will architect their functions in a cloud-native method whereas making certain resilience and scalability. She’s obsessed with machine studying applied sciences and environmental sustainability.
 Varun Mehta is a Options Architect at AWS. He’s obsessed with serving to prospects construct Enterprise-Scale Effectively-Architected options on the AWS Cloud. He works with strategic prospects who’re utilizing AI/ML to unravel complicated enterprise issues.
Varun Mehta is a Options Architect at AWS. He’s obsessed with serving to prospects construct Enterprise-Scale Effectively-Architected options on the AWS Cloud. He works with strategic prospects who’re utilizing AI/ML to unravel complicated enterprise issues.





