Exploring Generative AI in conversational experiences: An Introduction with Amazon Lex, Langchain, and SageMaker Jumpstart
Prospects anticipate fast and environment friendly service from companies in right now’s fast-paced world. However offering wonderful customer support could be considerably difficult when the quantity of inquiries outpaces the human sources employed to handle them. Nevertheless, companies can meet this problem whereas offering customized and environment friendly customer support with the developments in generative synthetic intelligence (generative AI) powered by giant language fashions (LLMs).
Generative AI chatbots have gained notoriety for his or her capability to mimic human mind. Nevertheless, not like task-oriented bots, these bots use LLMs for textual content evaluation and content material era. LLMs are based mostly on the Transformer architecture, a deep studying neural community launched in June 2017 that may be educated on an enormous corpus of unlabeled textual content. This method creates a extra human-like dialog expertise and accommodates a number of matters.
As of this writing, corporations of all sizes need to use this know-how however need assistance determining the place to start out. If you’re trying to get began with generative AI and using LLMs in conversational AI, this publish is for you. We’ve got included a pattern mission to shortly deploy an Amazon Lex bot that consumes a pre-trained open-source LLM. The code additionally contains the place to begin to implement a customized reminiscence supervisor. This mechanism permits an LLM to recall earlier interactions to maintain the dialog’s context and tempo. Lastly, it’s important to focus on the significance of experimenting with fine-tuning prompts and LLM randomness and determinism parameters to acquire constant outcomes.
Resolution overview
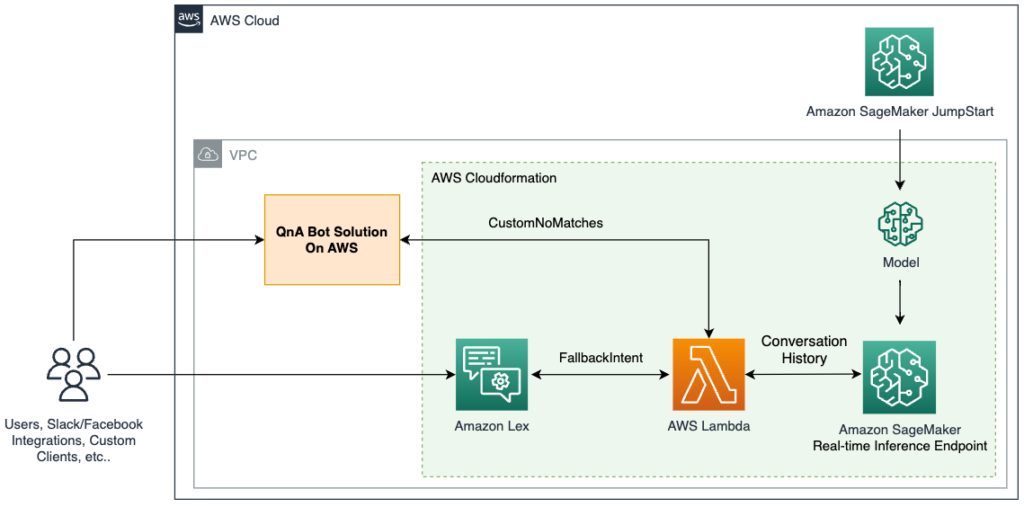
The answer integrates an Amazon Lex bot with a preferred open-source LLM from Amazon SageMaker JumpStart, accessible by means of an Amazon SageMaker endpoint. We additionally use LangChain, a preferred framework that simplifies LLM-powered purposes. Lastly, we use a QnABot to offer a person interface for our chatbot.

First, we begin by describing every part within the previous diagram:
- JumpStart provides pre-trained open-source fashions for numerous downside varieties. This lets you start machine studying (ML) shortly. It contains the FLAN-T5-XL model, an LLM deployed right into a deep studying container. It performs nicely on numerous pure language processing (NLP) duties, together with textual content era.
- A SageMaker real-time inference endpoint allows quick, scalable deployment of ML fashions for predicting occasions. With the power to combine with Lambda capabilities, the endpoint permits for constructing customized purposes.
- The AWS Lambda perform makes use of the requests from the Amazon Lex bot or the QnABot to organize the payload to invoke the SageMaker endpoint utilizing LangChain. LangChain is a framework that lets builders create purposes powered by LLMs.
- The Amazon Lex V2 bot has the built-in
AMAZON.FallbackIntentintent kind. It’s triggered when a person’s enter doesn’t match any intents within the bot. - The QnABot is an open-source AWS resolution to offer a person interface to Amazon Lex bots. We configured it with a Lambda hook perform for a
CustomNoMatchesmerchandise, and it triggers the Lambda perform when QnABot can’t discover a solution. We assume you’ve already deployed it and included the steps to configure it within the following sections.
The answer is described at a excessive stage within the following sequence diagram.
Main duties carried out by the answer
On this part, we take a look at the main duties carried out in our resolution. This resolution’s whole mission supply code is offered to your reference on this GitHub repository.
Dealing with chatbot fallbacks
The Lambda perform handles the “don’t know” solutions by way of AMAZON.FallbackIntent in Amazon Lex V2 and the CustomNoMatches merchandise in QnABot. When triggered, this perform appears on the request for a session and the fallback intent. If there’s a match, it arms off the request to a Lex V2 dispatcher; in any other case, the QnABot dispatcher makes use of the request. See the next code:
Offering reminiscence to our LLM
To protect the LLM reminiscence in a multi-turn dialog, the Lambda perform features a LangChain custom memory class mechanism that makes use of the Amazon Lex V2 Sessions API to maintain monitor of the session attributes with the continued multi-turn dialog messages and to offer context to the conversational mannequin by way of earlier interactions. See the next code:
The next is the pattern code we created for introducing the customized reminiscence class in a LangChain ConversationChain:
Immediate definition
A immediate for an LLM is a query or assertion that units the tone for the generated response. Prompts perform as a type of context that helps direct the mannequin towards producing related responses. See the next code:
Utilizing an Amazon Lex V2 session for LLM reminiscence help
Amazon Lex V2 initiates a session when a person interacts to a bot. A session persists over time except manually stopped or timed out. A session shops metadata and application-specific knowledge generally known as session attributes. Amazon Lex updates consumer purposes when the Lambda perform provides or modifications session attributes. The QnABot contains an interface to set and get session attributes on high of Amazon Lex V2.
In our code, we used this mechanism to construct a customized reminiscence class in LangChain to maintain monitor of the dialog historical past and allow the LLM to recall short-term and long-term interactions. See the next code:
Stipulations
To get began with the deployment, it’s essential fulfill the next stipulations:
Deploy the answer
To deploy the answer, proceed with the next steps:
- Select Launch Stack to launch the answer within the
us-east-1Area:
- For Stack identify, enter a singular stack identify.
- For HFModel, we use the
Hugging Face Flan-T5-XLmannequin accessible on JumpStart. - For HFTask, enter
text2text. - Preserve S3BucketName as is.
These are used to seek out Amazon Simple Storage Service (Amazon S3) property wanted to deploy the answer and will change as updates to this publish are revealed.

- Acknowledge the capabilities.
- Select Create stack.
There must be 4 efficiently created stacks.

Configure the Amazon Lex V2 bot
There’s nothing to do with the Amazon Lex V2 bot. Our CloudFormation template already did the heavy lifting.
Configure the QnABot
We assume you have already got an present QnABot deployed in your atmosphere. However in case you need assistance, comply with these instructions to deploy it.
- On the AWS CloudFormation console, navigate to the primary stack that you simply deployed.
- On the Outputs tab, make a remark of the
LambdaHookFunctionArnas a result of it’s essential insert it within the QnABot later.

- Log in to the QnABot Designer Consumer Interface (UI) as an administrator.
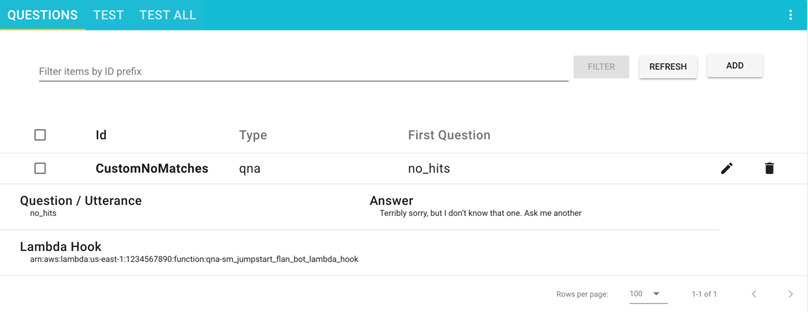
- Within the Questions UI, add a brand new query.

- Enter the next values:
- ID –
CustomNoMatches - Query –
no_hits - Reply – Any default reply for “don’t know”
- ID –
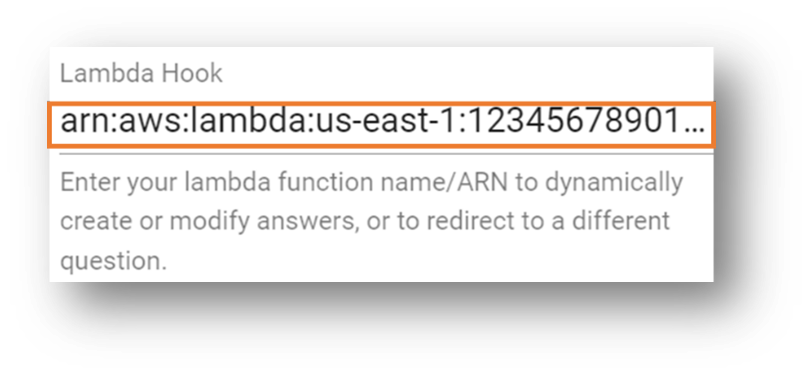
- Select Superior and go to the Lambda Hook part.
- Enter the Amazon Useful resource Title (ARN) of the Lambda perform you famous beforehand.
- Scroll right down to the underside of the part and select Create.
You get a window with a hit message.

Your query is now seen on the Questions web page.
Check the answer
Let’s proceed with testing the answer. First, it’s price mentioning that we deployed the FLAN-T5-XL mannequin offered by JumpStart with none fine-tuning. This may increasingly have some unpredictability, leading to slight variations in responses.
Check with an Amazon Lex V2 bot
This part helps you take a look at the Amazon Lex V2 bot integration with the Lambda perform that calls the LLM deployed within the SageMaker endpoint.
- On the Amazon Lex console, navigate to the bot entitled
Sagemaker-Jumpstart-Flan-LLM-Fallback-Bot.
This bot has been configured to name the Lambda perform that invokes the SageMaker endpoint internet hosting the LLM as a fallback intent when no different intents are matched. - Select Intents within the navigation pane.

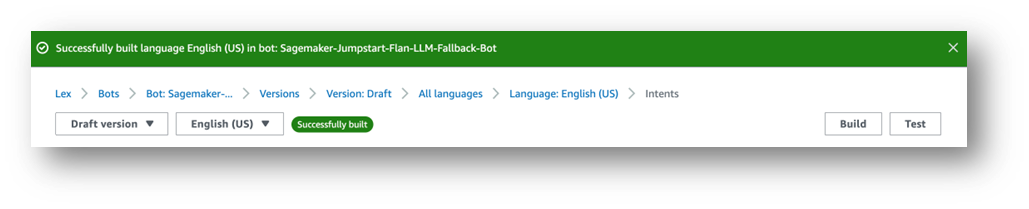
On the highest proper, a message reads, “English (US) has not constructed modifications.”
- Select Construct.
- Look ahead to it to finish.
Lastly, you get a hit message, as proven within the following screenshot.
- Select Check.
A chat window seems the place you may work together with the mannequin.
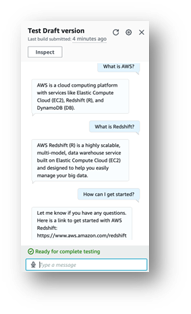
We advocate exploring the built-in integrations between Amazon Lex bots and Amazon Connect. And likewise, messaging platforms (Fb, Slack, Twilio SMS) or third-party Contact Facilities utilizing Amazon Chime SDK and Genesys Cloud, for instance.
Check with a QnABot occasion
This part exams the QnABot on AWS integration with the Lambda perform that calls the LLM deployed within the SageMaker endpoint.
- Open the instruments menu within the high left nook.
- Select QnABot Consumer.
- Select Signal In as Admin.

- Enter any query within the person interface.
- Consider the response.

Clear up
To keep away from incurring future costs, delete the sources created by our resolution by following these steps:
- On the AWS CloudFormation console, choose the stack named
SagemakerFlanLLMStack(or the customized identify you set to the stack). - Select Delete.
- If you happen to deployed the QnABot occasion to your exams, choose the QnABot stack.
- Select Delete.
Conclusion
On this publish, we explored the addition of open-domain capabilities to a task-oriented bot that routes the person requests to an open-source giant language mannequin.
We encourage you to:
- Save the dialog historical past to an exterior persistence mechanism. For instance, it can save you the dialog historical past to Amazon DynamoDB or an S3 bucket and retrieve it within the Lambda perform hook. On this approach, you don’t have to depend on the interior non-persistent session attributes administration provided by Amazon Lex.
- Experiment with summarization – In multiturn conversations, it’s useful to generate a abstract that you should use in your prompts so as to add context and restrict the utilization of dialog historical past. This helps to prune the bot session measurement and hold the Lambda perform reminiscence consumption low.
- Experiment with immediate variations – Modify the unique immediate description that matches your experimentation functions.
- Adapt the language mannequin for optimum outcomes – You are able to do this by fine-tuning the superior LLM parameters equivalent to randomness (
temperature) and determinism (top_p) in response to your purposes. We demonstrated a pattern integration utilizing a pre-trained mannequin with pattern values, however have enjoyable adjusting the values to your use circumstances.
In our subsequent publish, we plan that can assist you uncover the right way to fine-tune pre-trained LLM-powered chatbots with your personal knowledge.
Are you experimenting with LLM chatbots on AWS? Inform us extra within the feedback!
Assets and references
Concerning the Authors
 Marcelo Silva is an skilled tech skilled who excels in designing, creating, and implementing cutting-edge merchandise. Beginning off his profession at Cisco, Marcelo labored on numerous high-profile initiatives together with deployments of the primary ever service routing system and the profitable rollout of ASR9000. His experience extends to cloud know-how, analytics, and product administration, having served as senior supervisor for a number of corporations like Cisco, Cape Networks, and AWS earlier than becoming a member of GenAI. At the moment working as a Conversational AI/GenAI Product Supervisor, Marcelo continues to excel in delivering modern options throughout industries.
Marcelo Silva is an skilled tech skilled who excels in designing, creating, and implementing cutting-edge merchandise. Beginning off his profession at Cisco, Marcelo labored on numerous high-profile initiatives together with deployments of the primary ever service routing system and the profitable rollout of ASR9000. His experience extends to cloud know-how, analytics, and product administration, having served as senior supervisor for a number of corporations like Cisco, Cape Networks, and AWS earlier than becoming a member of GenAI. At the moment working as a Conversational AI/GenAI Product Supervisor, Marcelo continues to excel in delivering modern options throughout industries.
 Victor Rojo is a extremely skilled technologist who’s passionate in regards to the newest in AI, ML, and software program growth. Together with his experience, he performed a pivotal position in bringing Amazon Alexa to the US and Mexico markets whereas spearheading the profitable launch of Amazon Textract and AWS Contact Middle Intelligence (CCI) to AWS Companions. As the present Principal Tech Chief for the Conversational AI Competency Companions program, Victor is dedicated to driving innovation and bringing cutting-edge options to fulfill the evolving wants of the business.
Victor Rojo is a extremely skilled technologist who’s passionate in regards to the newest in AI, ML, and software program growth. Together with his experience, he performed a pivotal position in bringing Amazon Alexa to the US and Mexico markets whereas spearheading the profitable launch of Amazon Textract and AWS Contact Middle Intelligence (CCI) to AWS Companions. As the present Principal Tech Chief for the Conversational AI Competency Companions program, Victor is dedicated to driving innovation and bringing cutting-edge options to fulfill the evolving wants of the business.
 Justin Leto is a Sr. Options Architect at Amazon Net Companies with a specialization in machine studying. His ardour helps prospects harness the facility of machine studying and AI to drive enterprise development. Justin has offered at international AI conferences, together with AWS Summits, and lectured at universities. He leads the NYC machine studying and AI meetup. In his spare time, he enjoys offshore crusing and enjoying jazz. He lives in New York Metropolis together with his spouse and child daughter.
Justin Leto is a Sr. Options Architect at Amazon Net Companies with a specialization in machine studying. His ardour helps prospects harness the facility of machine studying and AI to drive enterprise development. Justin has offered at international AI conferences, together with AWS Summits, and lectured at universities. He leads the NYC machine studying and AI meetup. In his spare time, he enjoys offshore crusing and enjoying jazz. He lives in New York Metropolis together with his spouse and child daughter.
 Ryan Gomes is a Information & ML Engineer with the AWS Skilled Companies Intelligence Observe. He’s keen about serving to prospects obtain higher outcomes by means of analytics and machine studying options within the cloud. Exterior work, he enjoys health, cooking, and spending high quality time with family and friends.
Ryan Gomes is a Information & ML Engineer with the AWS Skilled Companies Intelligence Observe. He’s keen about serving to prospects obtain higher outcomes by means of analytics and machine studying options within the cloud. Exterior work, he enjoys health, cooking, and spending high quality time with family and friends.
 Mahesh Birardar is a Sr. Options Architect at Amazon Net Companies with specialization in DevOps and Observability. He enjoys serving to prospects implement cost-effective architectures that scale. Exterior work, he enjoys watching motion pictures and mountaineering.
Mahesh Birardar is a Sr. Options Architect at Amazon Net Companies with specialization in DevOps and Observability. He enjoys serving to prospects implement cost-effective architectures that scale. Exterior work, he enjoys watching motion pictures and mountaineering.
 Kanjana Chandren is a Options Architect at Amazon Net Companies (AWS) who’s keen about Machine Studying. She helps prospects in designing, implementing and managing their AWS workloads. Exterior of labor she loves travelling, studying and spending time with household and buddies.
Kanjana Chandren is a Options Architect at Amazon Net Companies (AWS) who’s keen about Machine Studying. She helps prospects in designing, implementing and managing their AWS workloads. Exterior of labor she loves travelling, studying and spending time with household and buddies.





