Dialogue-guided clever doc processing with basis fashions on Amazon SageMaker JumpStart
Clever doc processing (IDP) is a expertise that automates the processing of excessive volumes of unstructured information, together with textual content, pictures, and movies. IDP gives a big enchancment over handbook strategies and legacy optical character recognition (OCR) techniques by addressing challenges comparable to price, errors, low accuracy, and restricted scalability, in the end main to higher outcomes for organizations and stakeholders.
Pure language processing (NLP) is among the latest developments in IDP that has improved accuracy and consumer expertise. Nonetheless, regardless of these advances, there are nonetheless challenges to beat. As an illustration, many IDP techniques should not user-friendly or intuitive sufficient for simple adoption by customers. Moreover, a number of current options lack the potential to adapt to adjustments in information sources, rules, and consumer necessities by means of steady enchancment and updates.
Enhancing IDP by means of dialogue entails incorporating dialogue capabilities into IDP techniques. By enabling customers to work together with IDP techniques in a extra pure and intuitive manner, by means of multi-round dialogue by adjusting inaccurate info or including lacking info aided with activity automation, these techniques can change into extra environment friendly, correct, and user-friendly.
On this put up, we discover an revolutionary strategy to IDP that makes use of a dialogue-guided question resolution utilizing Amazon Foundation Models and SageMaker JumpStart.
Answer overview
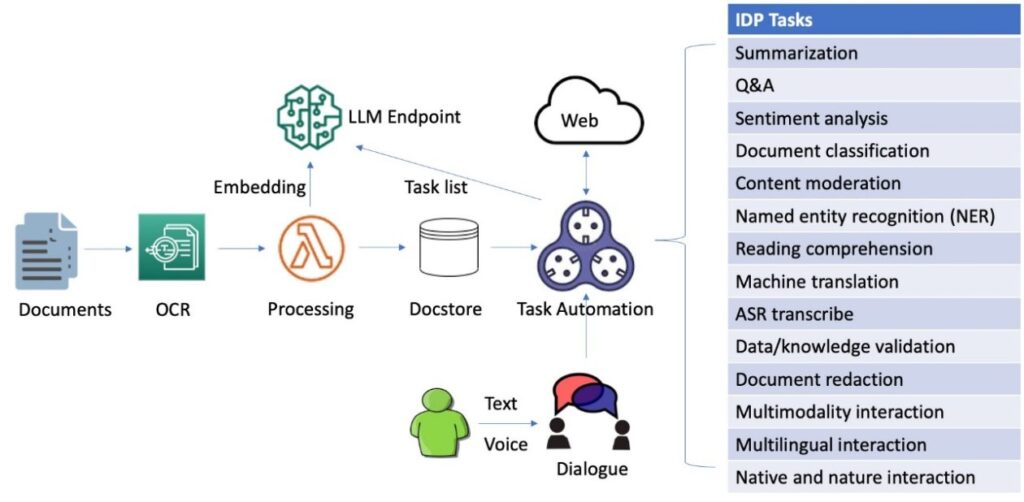
This revolutionary resolution combines OCR for info extraction, a neighborhood deployed massive language mannequin (LLM) for dialogue and autonomous tasking, VectorDB for embedding subtasks, and LangChain-based activity automation for integration with exterior information sources to rework the way in which companies course of and analyze doc contexts. By harnessing generative AI applied sciences, organizations can streamline IDP workflows, improve consumer expertise, and increase total effectivity.
The next video highlights the dialogue-guided IDP system by processing an article authored by the Federal Reserve Board of Governors, discussing the collapse of Silicon Valley Financial institution in March 2023.
The system is able to processing pictures, massive PDF, and paperwork in different format and answering questions derived from the content material by way of interactive textual content or voice inputs. If a consumer must inquire past the doc’s context, the dialogue-guided IDP can create a sequence of duties from the textual content immediate after which reference exterior and up-to-date information sources for related solutions. Moreover, it helps multi-round conversations and accommodates multilingual exchanges, all managed by means of dialogue.
Deploy your individual LLM utilizing Amazon basis fashions
One of the promising developments in generative AI is the mixing of LLMs into dialogue techniques, opening up new avenues for extra intuitive and significant exchanges. An LLM is a kind of AI mannequin designed to grasp and generate human-like textual content. These fashions are skilled on huge quantities of information and include billions of parameters, permitting them to carry out varied language-related duties with excessive accuracy. This transformative strategy facilitates a extra pure and productive interplay, bridging the hole between human instinct and machine intelligence. A key benefit of native LLM deployment lies in its capability to boost information safety with out submitting information outdoors to third-party APIs. Furthermore, you possibly can fine-tune your chosen LLM with domain-specific information, leading to a extra correct, context-aware, and pure language understanding expertise.
The Jurassic-2 collection from AI21 Labs, that are based mostly on the instruct-tuned 178-billion-parameter Jurassic-1 LLM, are integral components of the Amazon basis fashions obtainable by means of Amazon Bedrock. The Jurassic-2 instruct was particularly skilled to handle prompts which are directions solely, often called zero-shot, with out the necessity for examples, or few-shot. This methodology offers essentially the most intuitive interplay with LLMs, and it’s the most effective strategy to grasp the perfect output in your activity with out requiring any examples. You may effectively deploy the pre-trained J2-jumbo-instruct, or different Jurassic-2 fashions obtainable on AWS Market, into your individual personal digital personal cloud (VPC) utilizing Amazon SageMaker. See the next code:
import ai21, sagemaker
# Outline endpoint identify
endpoint_name = "sagemaker-soln-j2-jumbo-instruct"
# Outline real-time inference occasion sort. You may also select g5.48xlarge or p4de.24xlarge occasion varieties
# Please request P occasion quota enhance by way of <a href="https://console.aws.amazon.com/servicequotas/dwelling" goal="_blank" rel="noopener">Service Quotas console</a> or your account supervisor
real_time_inference_instance_type = ("ml.p4d.24xlarge")
# Create a Sgaemkaer endpoint then deploy a pre-trained J2-jumbo-instruct-v1 mannequin from AWS Market Place.
model_package_arn = "arn:aws:sagemaker:us-east-1:865070037744:model-package/j2-jumbo-instruct-v1-0-20-8b2be365d1883a15b7d78da7217cdeab"
mannequin = ModelPackage(
position=sagemaker.get_execution_role(),
model_package_arn=model_package_arn,
sagemaker_session=sagemaker.Session()
)
# Deploy the mannequin
predictor = mannequin.deploy(1, real_time_inference_instance_type,
endpoint_name=endpoint_name,
model_data_download_timeout=3600,
container_startup_health_check_timeout=600,
)After the endpoint has been efficiently deployed inside your individual VPC, you possibly can provoke an inference activity to confirm that the deployed LLM is functioning as anticipated:
response_jumbo_instruct = ai21.Completion.execute(
sm_endpoint=endpoint_name,
immediate="Clarify deep studying algorithms to eighth graders",
numResults=1,
maxTokens=100,
temperature=0.01 #topic to scale back “hallucination” by utilizing widespread phrases.
)Doc processing, embedding, and indexing
We delve into the method of constructing an environment friendly and efficient search index, which kinds the muse for clever and responsive dialogues to information doc processing. To start, we convert paperwork from varied codecs into textual content content material utilizing OCR and Amazon Textract. We then learn this content material and fragment it into smaller items, ideally across the measurement of a sentence every. This granular strategy permits for extra exact and related search outcomes, as a result of it allows higher matching of queries in opposition to particular person segments of a web page reasonably than the whole doc. To additional improve the method, we use embeddings such because the sentence transformers library from Hugging Face, which generates vector representations (encoding) of every sentence. These vectors function a compact and significant illustration of the unique textual content, enabling environment friendly and correct semantic matching performance. Lastly, we retailer these vectors in a vector database for similarity search. This mixture of methods lays the groundwork for a novel doc processing framework that delivers correct and intuitive outcomes for customers. The next diagram illustrates this workflow.
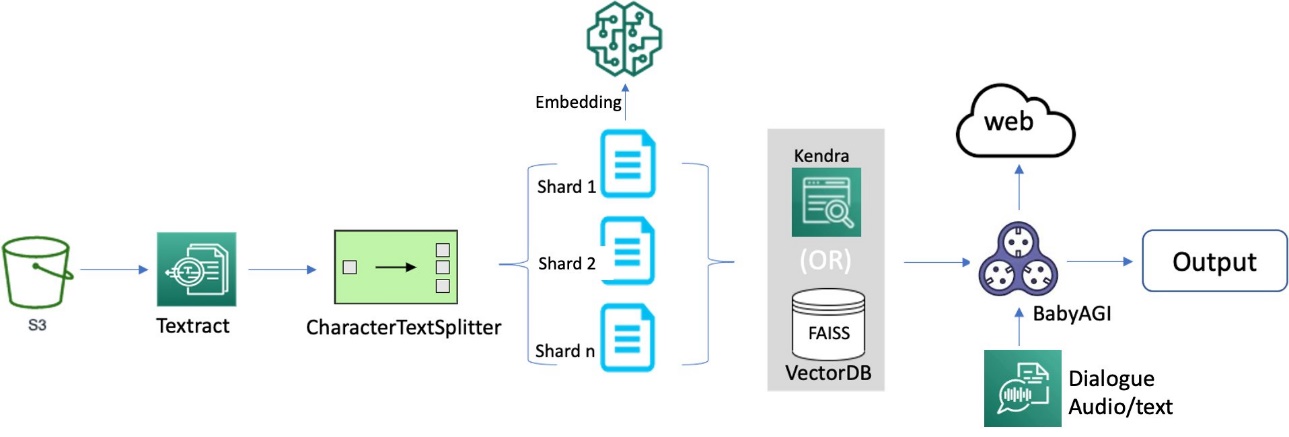
OCR serves as an important aspect within the resolution, permitting for the retrieval of textual content from scanned paperwork or photos. We will use Amazon Textract for extracting textual content from PDF or picture recordsdata. This managed OCR service is able to figuring out and analyzing textual content in multi-page paperwork, together with these in PDF, JPEG or TIFF codecs, comparable to invoices and receipts. The processing of multi-page paperwork happens asynchronously, making it advantageous for dealing with in depth, multi-page paperwork. See the next code:
def pdf_2_text(input_pdf_file, historical past):
historical past = historical past or []
key = 'input-pdf-files/{}'.format(os.path.basename(input_pdf_file.identify))
strive:
response = s3_client.upload_file(input_pdf_file.identify, default_bucket_name, key)
besides ClientError as e:
print("Error importing file to S3:", e)
s3_object = {'Bucket': default_bucket_name, 'Title': key}
response = textract_client.start_document_analysis(
DocumentLocation={'S3Object': s3_object},
FeatureTypes=['TABLES', 'FORMS']
)
job_id = response['JobId']
whereas True:
response = textract_client.get_document_analysis(JobId=job_id)
standing = response['JobStatus']
if standing in ['SUCCEEDED', 'FAILED']:
break
time.sleep(5)
if standing == 'SUCCEEDED':
with open(output_file, 'w') as output_file_io:
for block in response['Blocks']:
if block['BlockType'] in ['LINE', 'WORD']:
output_file_io.write(block['Text'] + 'n')
with open(output_file, "r") as file:
first_512_chars = file.learn(512).exchange("n", "").exchange("r", "").exchange("[", "").replace("]", "") + " [...]"
historical past.append(("Doc conversion", first_512_chars))
return historical past, historical pastWhen coping with massive paperwork, it’s essential to interrupt them down into extra manageable items for simpler processing. Within the case of LangChain, this implies dividing every doc into smaller segments, comparable to 1,000 tokens per chunk with an overlap of 100 tokens. To realize this easily, LangChain makes use of specialised splitters designed particularly for this goal:
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders import TextLoader
separator="n"
overlap_count = 100. # overlap depend between the splits
chunk_size = 1000 # Use a hard and fast cut up unit measurement
loader = TextLoader(output_file)
paperwork = loader.load()
text_splitter = CharacterTextSplitter(separator=separator, chunk_overlap=overlap_count, chunk_size=chunk_size, length_function=len)
texts = text_splitter.split_documents(paperwork)The period wanted for embedding can fluctuate based mostly on the scale of the doc; for instance, it may take roughly 10 minutes to complete. Though this time-frame is probably not substantial when coping with a single doc, the ramifications change into extra notable when indexing tons of of gigabytes versus simply tons of of megabytes. To expedite the embedding course of, you possibly can implement sharding, which allows parallelization and consequently enhances effectivity:
from langchain.document_loaders import ReadTheDocsLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from sentence_transformers import SentenceTransformer
import numpy as np
import ray
from embeddings import LocalHuggingFaceEmbeddings
# Outline variety of splits
db_shards = 10
loader = TextLoader(output_file)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1000,
chunk_overlap = 100,
length_function = len,
)
@ray.distant()
def process_shard(shard):
embeddings = LocalHuggingFaceEmbeddings('multi-qa-mpnet-base-dot-v1')
end result = Chroma.from_documents(shard, embeddings)
return end result
# Learn the doc content material and cut up them into chunks.
chunks = text_splitter.create_documents([doc.page_content for doc in documents], metadatas=[doc.metadata for doc in documents])
# Embed the doc chunks into vectors.
shards = np.array_split(chunks, db_shards)
futures = [process_shard.remote(shards[i]) for i in vary(db_shards)]
texts = ray.get(futures)Now that we have now obtained the smaller segments, we are able to proceed to symbolize them as vectors by means of embeddings. Embeddings, a method in NLP, generate vector representations of textual content prompts. The Embedding class serves as a unified interface for interacting with varied embedding suppliers, comparable to SageMaker, Cohere, Hugging Face, and OpenAI, which streamlines the method throughout totally different platforms. These embeddings are numeric portrayals of concepts reworked into quantity sequences, permitting computer systems to effortlessly comprehend the connections between these concepts. See the next code:
# Select a SageMaker deployed native LLM endpoint for embedding
llm_embeddings = SagemakerEndpointEmbeddings(
endpoint_name=<endpoint_name>,
region_name=<area>,
content_handler=content_handler
)After creating the embeddings, we have to make the most of a vectorstore to retailer the vectors. Vectorstores like Chroma are specifically engineered to assemble indexes for fast searches in high-dimensional areas in a while, making them completely fitted to our goals. Instead, you should utilize FAISS, an open-source vector clustering resolution for storing vectors. See the next code:
from langchain.vectorstores import Chroma
# Retailer vectors in Chroma vectorDB
docsearch_chroma = Chroma.from_documents(texts, llm_embeddings)
# Alternatively you possibly can select FAISS vectorstore
from langchain.vectorstores import FAISS
docsearch_faiss = FAISS.from_documents(texts, llm_embeddings)You may also use Amazon Kendra to index enterprise content material and produce exact solutions. As a completely managed service, Amazon Kendra gives ready-to-use semantic search options for superior doc and passage rating. With the high-accuracy search in Amazon Kendra, you possibly can receive essentially the most pertinent content material and paperwork to optimize the standard of your payload. This ends in superior LLM responses in comparison with conventional or keyword-focused search strategies. For extra info, check with Quickly build high-accuracy Generative AI applications on enterprise data using Amazon Kendra, LangChain, and large language models.
Interactive multilingual voice enter
Incorporating interactive voice enter into doc search gives a myriad of benefits that improve the consumer expertise. By enabling customers to verbally articulate search phrases, doc search turns into extra pure and intuitive, making it less complicated and faster for customers to seek out the knowledge they want. Voice enter can bolster the precision of search outcomes, as a result of spoken search phrases are much less prone to spelling or grammatical errors. Interactive voice enter renders doc search extra inclusive, catering to a broader spectrum of customers with totally different language audio system and tradition background.
The Amazon Transcribe Streaming SDK lets you carry out audio-to-speech recognition by integrating straight with Amazon Transcribe merely with a stream of audio bytes and a fundamental handler. Instead, you possibly can deploy the whisper-large mannequin domestically from Hugging Face utilizing SageMaker, which gives improved information safety and higher efficiency. For particulars, check with the sample notebook revealed on the GitHub repo.
# Select ASR utilizing a domestically deployed Whisper-large mannequin from Hugging Face
picture = sagemaker.image_uris.retrieve(
framework='pytorch',
area=area,
image_scope="inference",
model='1.12',
instance_type="ml.g4dn.xlarge",
)
model_name = f'sagemaker-soln-whisper-model-{int(time.time())}'
whisper_model_sm = sagemaker.mannequin.Mannequin(
model_data=model_uri,
image_uri=picture,
position=sagemaker.get_execution_role(),
entry_point="inference.py",
source_dir="src",
identify=model_name,
)
# Audio transcribe
transcribe = whisper_endpoint.predict(audio.numpy())The above demonstration video reveals how voice instructions, along side textual content enter, can facilitate the duty of doc summarization by means of interactive dialog.
Guiding NLP duties by means of multi-round conversations
Reminiscence in language fashions maintains an idea of state all through a consumer’s interactions. This entails processing a sequence of chat messages to extract and rework information. Reminiscence varieties differ, however every will be understood utilizing standalone capabilities and inside a sequence. Reminiscence can return a number of information factors, comparable to latest messages or message summaries, within the type of strings or lists. This put up focuses on the best reminiscence type, buffer reminiscence, which shops all prior messages, and demonstrates its utilization with modular utility capabilities and chains.
The LangChain’s ChatMessageHistory class is a vital utility for reminiscence modules, offering handy strategies to save lots of and retrieve human and AI messages by remembering all earlier chat interactions. It’s best for managing reminiscence externally from a sequence. The next code is an instance of making use of a easy idea in a sequence by introducing ConversationBufferMemory, a wrapper for ChatMessageHistory. This wrapper extracts messages right into a variable, permitting them to be represented as a string:
from langchain.reminiscence import ConversationBufferMemory
reminiscence = ConversationBufferMemory(return_messages=True)LangChain works with many widespread LLM suppliers comparable to AI21 Labs, OpenAI, Cohere, Hugging Face, and extra. For this instance, we use a domestically deployed AI21 Labs’ Jurassic-2 LLM wrapper utilizing SageMaker. AI21 Studio additionally offers API entry to Jurassic-2 LLMs.
from langchain import PromptTemplate, SagemakerEndpoint
from langchain.llms.sagemaker_endpoint import ContentHandlerBase
from langchain.chains.question_answering import load_qa_chain
immediate= PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
class ContentHandler(ContentHandlerBase):
content_type = "utility/json"
accepts = "utility/json"
def transform_input(self, immediate: str, model_kwargs: Dict) -- bytes:
input_str = json.dumps({immediate: immediate, **model_kwargs})
return input_str.encode('utf-8')
def transform_output(self, output: bytes) -- str:
response_json = json.masses(output.learn().decode("utf-8"))
return response_json[0]["generated_text"]
content_handler = ContentHandler()
llm_ai21=SagemakerEndpoint(
endpoint_name=endpoint_name,
credentials_profile_name=f'aws-credentials-profile-name',
region_name="us-east-1",
model_kwargs={"temperature":0},
content_handler=content_handler)
qa_chain = VectorDBQA.from_chain_type(
llm=llm_ai21,
chain_type="stuff",
vectorstore=docsearch,
verbose=True,
reminiscence=ConversationBufferMemory(return_messages=True)
)
response = qa_chain(
{'question': query_input},
return_only_outputs=True
)Within the occasion that the method is unable to find an applicable response from the unique paperwork in response to a consumer’s inquiry, the mixing of a third-party URL or ideally a task-driven autonomous agent with exterior information sources considerably enhances the system’s capability to entry an unlimited array of knowledge, in the end bettering context and offering extra correct and present outcomes.
With AI21’s preconfigured Summarize run methodology, a question can entry a predetermined URL, condense its content material, after which perform query and reply duties based mostly on the summarized info:
# Name AI21 API to question the context of a particular URL for Q&A
ai21.api_key = "<YOUR_API_KEY>"
url_external_source = "<your_source_url>"
response_url = ai21.Summarize.execute(
supply=url_external_source,
sourceType="URL" )
context = "<concate_document_and_response_url>"
query = "<question>"
response = ai21.Reply.execute(
context=context,
query=query,
sm_endpoint=endpoint_name,
maxTokens=100,
)For extra particulars and code examples, check with the LangChain LLM integration document in addition to the task-specific API documents supplied by AI21.
Job automation utilizing BabyAGI
The duty automation mechanism permits the system to course of complicated queries and generate related responses, which drastically improves the validity and authenticity of doc processing. LangCain’s BabyAGI is a strong AI-powered activity administration system that may autonomously create, prioritize, and run duties. One of many key options is its capability to interface with exterior sources of knowledge, comparable to the online, databases, and APIs. A method to make use of this function is to combine BabyAGI with Serpapi, a search engine API that gives entry to engines like google. This integration permits BabyAGI to go looking the online for info associated to duties, permitting BabyAGI to entry a wealth of knowledge past the enter paperwork.
BabyAGI’s autonomous tasking capability is fueled by an LLM, a vector search database, an API wrapper to exterior hyperlinks, and the LangChain framework, permitting it to run a broad spectrum of duties throughout varied domains. This allows the system to proactively perform duties based mostly on consumer interactions, streamlining the doc processing pipeline that includes exterior sources and making a extra environment friendly, clean expertise. The next diagram illustrates the duty automation course of.
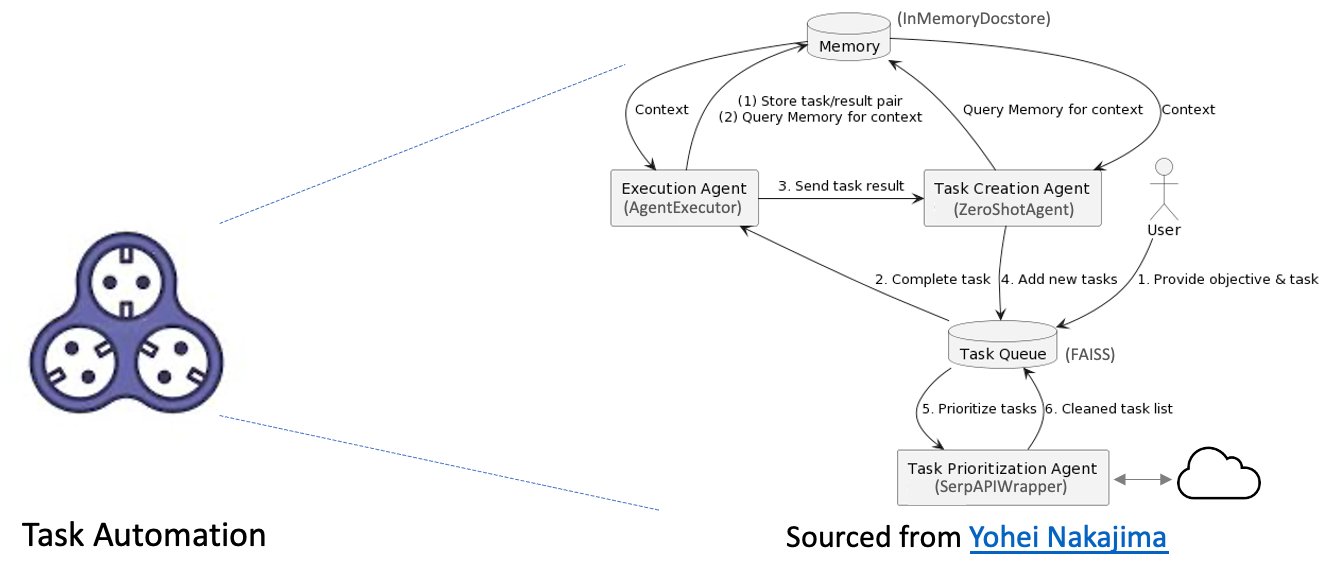
This course of contains the next parts:
- Reminiscence – The reminiscence shops all the knowledge that BabyAGI wants to finish its duties. This contains the duty itself, in addition to any intermediate outcomes or information that BabyAGI has generated.
- Execution agent – The execution agent is accountable for finishing up the duties which are saved within the reminiscence. It does this by accessing the reminiscence, retrieving the related info, after which taking the mandatory steps to finish the duty.
- Job creation agent – The duty creation agent is accountable for producing new duties for BabyAGI to finish. It does this by analyzing the present state of the reminiscence and figuring out any gaps in information or understanding. When a spot has been recognized, the duty creation agent generates a brand new activity that can assist BabyAGI fill that hole.
- Job queue – The duty queue is an inventory of the entire duties that BabyAGI has been assigned. The duties are added to the queue within the order wherein they have been acquired.
- Job prioritization agent – The duty prioritization agent is accountable for figuring out the order wherein BabyAGI ought to full its duties. It does this by analyzing the duties within the queue and figuring out those which are most necessary or pressing. The duties which are most necessary are positioned on the entrance of the queue, and the duties which are least necessary are positioned behind the queue.
See the next code:
from babyagi import BabyAGI
from langchain.docstore import InMemoryDocstore
import faiss
# Set temperatur=0 to generate essentially the most frequent phrases, as a substitute of extra “poetically free” conduct.
new_query = """
What occurred to the First Republic Financial institution? Will the FED take the identical motion because it did on SVB's failure?
"""
# Allow verbose logging and use a hard and fast embedding measurement.
verbose = True
embedding_size = 1536
# Utilizing FAISS vector cluster for vectore retailer
index = faiss.IndexFlatL2(embedding_size)
vectorstore = FAISS(llm_embeddings.embed_query, index, InMemoryDocstore({}), {})
# Select 1 iteration for demo and 1>N>10 for actual. If None, it can loop indefinitely
max_iterations: Non-obligatory[int] = 2
# Name bayagi class for activity automation
baby_agi = BabyAGI.from_llm(
llm=llm_embedding, vectorstore=vectorstore, verbose=verbose, max_iterations=max_iterations<br />)
response = baby_agi({"goal": new_query})Let’s study the duties gathered and their outcomes from a single iteration, used for demonstration functions, to perform the target in response to the consumer’s inquiry. BabyAGI operates by means of a steady cycle of the next steps:
- A activity creation agent formulates a brand new activity.
- The brand new activity is integrated into the duty queue.
- The duty prioritization agent establishes the sequence wherein duties needs to be tackled.
- The run agent accomplishes the duty.
- The duty end result is saved within the reminiscence.
- The cycle repeats.
This iterative course of allows BabyAGI to study and develop over time. Because it efficiently completes an growing variety of duties, BabyAGI’s information and comprehension of the world increase. Consequently, it may generate and effectively run extra intricate and superior duties. By augmenting the iteration depend, you possibly can improve the result by means of the reorganization of the duty checklist, which focuses on the objective and the result of previous duties, in the end yielding extra pertinent and exact responses.
See the next instance output:
*****TASK LIST*****
1: Make a todo checklist
*****NEXT TASK*****
1: Make a todo checklist
> Coming into new AgentExecutor chain...
Thought: I have to analysis the First Republic Financial institution and the FED's motion
Motion: Search
Motion Enter: What occurred to the First Republic Financial institution? Will the FED take the identical
motion because it did on SVB's failure?
Remark: First Republic's failure was on account of a run on deposits following the
collapse of Silicon Valley Financial institution and Signature Financial institution. JPMorgan Chase acquired
First Republic Financial institution on Could 1, 2023. Should you had insured or uninsured cash in First Republic accounts, your funds are secure and now managed by JPMorgan Chase.
Thought: I have to analysis the FED's motion on SVB's failure
Motion: Search
Motion Enter: What motion did the FED tackle SVB's failure?
Remark: The Hutchins Middle explains how the Federal Reserve has responded to the
March 2023 failures of Silicon Valley Financial institution and Signature Financial institution.
Thought: I now know the ultimate reply
Remaining Reply: The FED responded to the March 2023 failures of Silicon Valley Financial institution and <br />Signature Financial institution by offering liquidity to the banking system. JPMorgan
Chase acquired First Republic Financial institution on Could 1, 2023, and when you had insured
or uninsured cash in First Republic accounts, your funds are secure and
now managed by JPMorgan Chase.
> Completed chain.
*****TASK RESULT*****
The Federal Reserve responded to the March 2023 failures of Silicon Valley Financial institution and Signature Financial institution by offering liquidity to the banking system. It's unclear what motion the FED will absorb response to the failure of First Republic Financial institution.
***TASK LIST***
2: Analysis the timeline of First Republic Financial institution's failure.
3: Analyze the Federal Reserve's response to the failure of Silicon Valley Financial institution and Signature Financial institution.
4: Evaluate the Federal Reserve's response to the failure of Silicon Valley Financial institution and Signature Financial institution to the Federal Reserve's response to the failure of First Republic Financial institution.
5: Examine the potential implications of the Federal Reserve's response to the failure of First Republic Financial institution.
6: Establish any potential dangers related to the Federal Reserve's response to the failure of First Republic Financial institution.<br />*****NEXT TASK*****
2: Analysis the timeline of First Republic Financial institution's failure.
> Coming into new AgentExecutor chain...
Will the FED take the identical motion because it did on SVB's failure?
Thought: I ought to seek for details about the timeline of First Republic Financial institution's failure and the FED's motion on SVB's failure.
Motion: Search
Motion Enter: Timeline of First Republic Financial institution's failure and FED's motion on SVB's failure
Remark: March 20: The FDIC decides to interrupt up SVB and maintain two separate auctions for its conventional deposits unit and its personal financial institution after failing ...
Thought: I ought to search for extra details about the FED's motion on SVB's failure.
Motion: Search
Motion Enter: FED's motion on SVB's failure
Remark: The Fed blamed failures on mismanagement and supervisory missteps, compounded by a dose of social media frenzy.
Thought: I now know the ultimate reply.
Remaining Reply: The FED is more likely to take comparable motion on First Republic Financial institution's failure because it did on SVB's failure, which was to interrupt up the financial institution and maintain two separate auctions for its conventional deposits unit and its personal financial institution.</p><p>> Completed chain.
*****TASK RESULT*****
The FED responded to the March 2023 failures of ilicon Valley Financial institution and Signature Financial institution
by offering liquidity to the banking system. JPMorgan Chase acquired First Republic
Financial institution on Could 1, 2023, and when you had insured or uninsured cash in First Republic
accounts, your funds are secure and now managed by JPMorgan Chase.*****TASK ENDING*****With BabyAGI for activity automation, the dialogue-guided IDP system showcased its effectiveness by going past the unique doc’s context to deal with the consumer’s question in regards to the Federal Reserve’s potential actions in regards to the First Republic Financial institution’s failure, which occurred in late April 2023, 1 month after the sample publication, compared to SVB’s failure. To realize this, the system generated a to-do checklist and accomplished duties sequentially. It investigated the circumstances surrounding the First Republic Financial institution’s failure, pinpointed potential dangers tied to the Federal Reserve’s response, and in contrast it to the response to SVB’s failure.
Though BabyAGI stays a piece in progress, it carries the promise of revolutionizing machine interactions, creative pondering, and downside decision. As BabyAGI’s studying and enhancement persist, it is going to be able to producing extra exact, insightful, and creative responses. By empowering machines to study and evolve autonomously, BabyAGI may facilitate their help in a broad spectrum of duties, starting from mundane chores to intricate problem-solving.
Constraints and limitations
Dialogue-guided IDP gives a promising strategy to enhancing the effectivity and effectiveness of doc evaluation and extraction. Nonetheless, we should acknowledge its present constraints and limitations, comparable to the necessity for information bias avoidance, hallucination mitigation, the problem of dealing with complicated and ambiguous language, and difficulties in understanding context or sustaining coherence in longer conversations.
Moreover, it’s necessary to contemplate confabulations and hallucinations in AI-generated responses, which can result in the creation of inaccurate or fabricated info. To handle these challenges, ongoing developments are specializing in refining LLMs with higher pure language understanding capabilities, incorporating domain-specific information and creating extra strong context-aware fashions. Constructing an LLM from scratch will be expensive and time-consuming; nonetheless, you possibly can make use of a number of methods to enhance current fashions:
- High quality-tuning a pre-trained LLM on particular domains for extra correct and related outputs
- Integrating exterior information sources identified to be secure throughout inference for enhanced contextual understanding
- Designing higher prompts to elicit extra exact responses from the mannequin
- Utilizing ensemble fashions to mix outputs from a number of LLMs, averaging out errors and minimizing hallucination probabilities
- Constructing guardrails to stop fashions from veering off into undesired areas whereas making certain apps reply with correct and applicable info
- Conducting supervised fine-tuning with human suggestions, iteratively refining the mannequin for elevated accuracy and decreased hallucination.
By adopting these approaches, AI-generated responses will be made extra dependable and worthwhile.
The duty-driven autonomous agent gives important potential throughout varied purposes, however it is important to contemplate key dangers earlier than adopting the expertise. These dangers embody:
- Knowledge privateness and safety breaches on account of reliance on the chosen LLM supplier and vectorDB
- Moral issues arising from biased or dangerous content material era
- Dependence on mannequin accuracy, which can result in ineffective activity completion or undesired outcomes
- System overload and scalability points if activity era outpaces completion, requiring correct activity sequencing and parallel administration
- Misinterpretation of activity prioritization based mostly on the LLM’s understanding of activity significance
- The authenticity of the info it acquired from the online
Addressing these dangers is essential for accountable and profitable utility, permitting us to maximise the advantages of AI-powered language fashions whereas minimizing potential dangers.
Conclusions
The dialogue-guided resolution for IDP presents a groundbreaking strategy to doc processing by integrating OCR, automated speech recognition, LLMs, activity automation, and exterior information sources. This complete resolution allows companies to streamline their doc processing workflows, making them extra environment friendly and intuitive. By incorporating these cutting-edge applied sciences, organizations cannot solely revolutionize their doc administration processes, but in addition bolster decision-making capabilities and significantly increase total productiveness. The answer gives a transformative and revolutionary means for companies to unlock the total potential of their doc workflows, in the end driving development and success within the period of generative AI. Check with SageMaker Jumpstart for different options and Amazon Bedrock for added generative AI fashions.
The authors wish to sincerely specific their appreciation to Ryan Kilpatrick, Ashish Lal, and Kristine Pearce for his or her worthwhile inputs and contributions to this work. In addition they acknowledge Clay Elmore for the code pattern supplied on Github.
In regards to the authors
 Alfred Shen is a Senior AI/ML Specialist at AWS. He has been working in Silicon Valley, holding technical and managerial positions in numerous sectors together with healthcare, finance, and high-tech. He’s a devoted utilized AI/ML researcher, concentrating on CV, NLP, and multimodality. His work has been showcased in publications comparable to EMNLP, ICLR, and Public Well being.
Alfred Shen is a Senior AI/ML Specialist at AWS. He has been working in Silicon Valley, holding technical and managerial positions in numerous sectors together with healthcare, finance, and high-tech. He’s a devoted utilized AI/ML researcher, concentrating on CV, NLP, and multimodality. His work has been showcased in publications comparable to EMNLP, ICLR, and Public Well being.
 Dr. Vivek Madan is an Utilized Scientist with the Amazon SageMaker JumpStart crew. He obtained his PhD from College of Illinois at Urbana-Champaign and was a Put up Doctoral Researcher at Georgia Tech. He’s an lively researcher in machine studying and algorithm design and has revealed papers in EMNLP, ICLR, COLT, FOCS, and SODA conferences.
Dr. Vivek Madan is an Utilized Scientist with the Amazon SageMaker JumpStart crew. He obtained his PhD from College of Illinois at Urbana-Champaign and was a Put up Doctoral Researcher at Georgia Tech. He’s an lively researcher in machine studying and algorithm design and has revealed papers in EMNLP, ICLR, COLT, FOCS, and SODA conferences.
 Dr. Li Zhang is a Principal Product Supervisor-Technical for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms, a service that helps information scientists and machine studying practitioners get began with coaching and deploying their fashions, and makes use of reinforcement learning with Amazon SageMaker. His previous work as a principal analysis employees member and grasp inventor at IBM Analysis has received the test of time paper award at IEEE INFOCOM.
Dr. Li Zhang is a Principal Product Supervisor-Technical for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms, a service that helps information scientists and machine studying practitioners get began with coaching and deploying their fashions, and makes use of reinforcement learning with Amazon SageMaker. His previous work as a principal analysis employees member and grasp inventor at IBM Analysis has received the test of time paper award at IEEE INFOCOM.
 Dr. Changsha Ma is an AI/ML Specialist at AWS. She is a technologist with a PhD in Laptop Science, a grasp’s diploma in Schooling Psychology, and years of expertise in information science and impartial consulting in AI/ML. She is obsessed with researching methodological approaches for machine and human intelligence. Outdoors of labor, she loves mountaineering, cooking, searching meals, mentoring school college students for entrepreneurship, and spending time with mates and households.
Dr. Changsha Ma is an AI/ML Specialist at AWS. She is a technologist with a PhD in Laptop Science, a grasp’s diploma in Schooling Psychology, and years of expertise in information science and impartial consulting in AI/ML. She is obsessed with researching methodological approaches for machine and human intelligence. Outdoors of labor, she loves mountaineering, cooking, searching meals, mentoring school college students for entrepreneurship, and spending time with mates and households.




