Sparse video tubes for joint video and picture imaginative and prescient transformers – Google AI Weblog
Video understanding is a difficult drawback that requires reasoning about each spatial info (e.g., for objects in a scene, together with their places and relations) and temporal information for actions or occasions proven in a video. There are a lot of video understanding purposes and duties, reminiscent of understanding the semantic content of web videos and robot perception. Nonetheless, present works, reminiscent of ViViT and TimeSFormer, densely course of the video and require vital compute, particularly as mannequin measurement plus video size and backbone enhance.
In “Rethinking Video ViTs: Sparse Video Tubes for Joint Image and Video Learning”, to be offered at CVPR 2023, we introduce a easy method that turns a Vision Transformer (ViT) mannequin picture encoder into an environment friendly video spine utilizing sparse video tubes (learnable visible representations of samples from the video) to scale back the mannequin’s compute wants. This method can seamlessly course of each photos and movies, which permits it to leverage each picture and video knowledge sources throughout coaching. This coaching additional permits our sparse tubes ViT mannequin to coalesce picture and video backbones collectively to serve a twin position as both a picture or video spine (or each), relying on the enter. We display that this mannequin is scalable, could be tailored to massive pre-trained ViTs with out requiring full fine-tuning, and achieves state-of-the-art outcomes throughout many video classification benchmarks.
 |
| Utilizing sparse video tubes to pattern a video, mixed with a typical ViT encoder, results in an environment friendly visible illustration that may be seamlessly shared with picture inputs. |
Constructing a joint image-video spine
Our sparse tube ViT makes use of a typical ViT spine, consisting of a stack of Transformer layers, that processes video info. Earlier strategies, reminiscent of ViViT, densely tokenize the video after which apply factorized attention, i.e., the eye weights for every token are computed individually for the temporal and spatial dimensions. In the usual ViT structure, self-attention is computed over the entire token sequence. When utilizing movies as enter, token sequences change into fairly lengthy, which may make this computation gradual. As a substitute, within the methodology we suggest, the video is sparsely sampled utilizing video tubes, that are 3D learnable visible representations of varied sizes and shapes (described in additional element beneath) from the video. These tubes are used to sparsely pattern the video utilizing a large temporal stride, i.e., when a tube kernel is just utilized to a couple places within the video, fairly than each pixel.
By sparsely sampling the video tubes, we are able to use the identical international self-attention module, fairly than factorized consideration like ViViT. We experimentally present that the addition of factorized consideration layers can hurt the efficiency because of the uninitialized weights. This single stack of transformer layers within the ViT spine additionally permits higher sharing of the weights and improves efficiency. Sparse video tube sampling is completed by utilizing a big spatial and temporal stride that selects tokens on a hard and fast grid. The big stride reduces the variety of tokens within the full community, whereas nonetheless capturing each spatial and temporal info and enabling the environment friendly processing of all tokens.
Sparse video tubes
Video tubes are 3D grid-based cuboids that may have totally different shapes or classes and seize totally different info with strides and beginning places that may overlap. Within the mannequin, we use three distinct tube shapes that seize: (1) solely spatial info (leading to a set of 2D picture patches), (2) lengthy temporal info (over a small spatial space), and (3) each spatial and temporal info equally. Tubes that seize solely spatial info could be utilized to each picture and video inputs. Tubes that seize lengthy temporal info or each temporal and spatial info equally are solely utilized to video inputs. Relying on the enter video measurement, the three tube shapes are utilized to the mannequin a number of occasions to generate tokens.
A set place embedding, which captures the worldwide location of every tube (together with any strides, offsets, and many others.) relative to all the opposite tubes, is utilized to the video tubes. Totally different from the earlier realized place embeddings, this mounted one higher permits sparse, overlapping sampling. Capturing the worldwide location of the tube helps the mannequin know the place every got here from, which is particularly useful when tubes overlap or are sampled from distant video places. Subsequent, the tube options are concatenated collectively to type a set of N tokens. These tokens are processed by a typical ViT encoder. Lastly, we apply an consideration pooling to compress all of the tokens right into a single illustration and enter to a totally related (FC) layer to make the classification (e.g., taking part in soccer, swimming, and many others.).
 |
| Our video ViT mannequin works by sampling sparse video tubes from the video (proven on the backside) to allow both or each picture or video inputs to be seamlessly processed. These tubes have totally different shapes and seize totally different video options. Tube 1 (yellow) solely captures spatial info, leading to a set of 2D patches that may be utilized to picture inputs. Tube 2 (purple) captures temporal info and a few spatial info and tube 3 (inexperienced) equally captures each temporal and spatial info (i.e., the spatial measurement of the tube x and y are the identical because the variety of frames t). Tubes 2 and three can solely be utilized to video inputs. The place embedding is added to all of the tube options. |
Scaling video ViTs
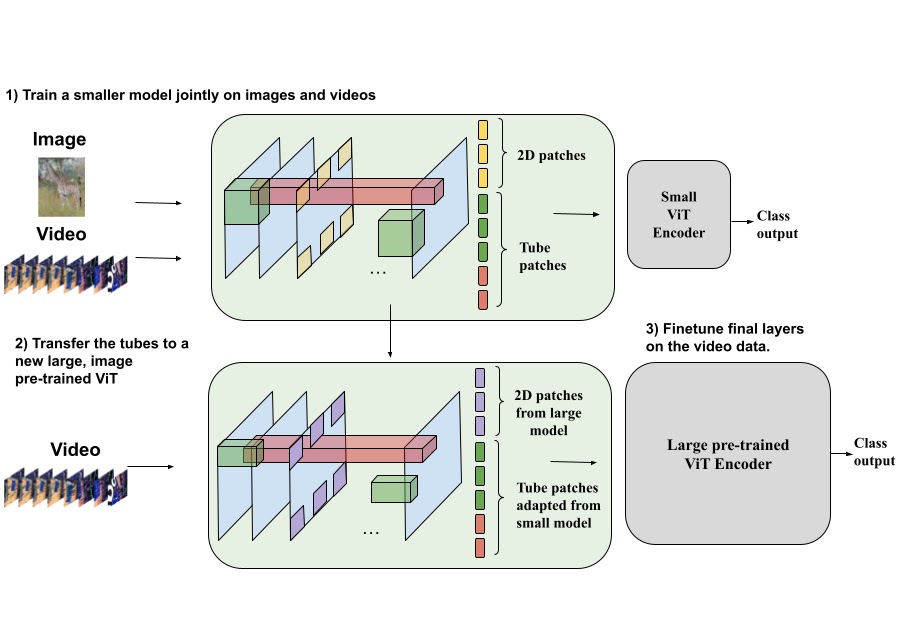
The method of constructing video backbones is computationally intensive, however our sparse tube ViT mannequin permits computationally environment friendly scaling of video fashions, leveraging beforehand skilled picture backbones. Since picture backbones could be tailored to a video spine, massive picture backbones could be was massive video backbones. Extra particularly, one can switch the realized video characteristic representations from a small tube ViT to a big pre-trained picture ViT and prepare the ensuing mannequin with video knowledge for just a few steps, versus a full coaching from scratch.
 |
| Our method permits scaling a sparse tube ViT in a extra environment friendly approach. Particularly, the video options from a small video ViT (prime community) could be transferred to a big, pre-trained picture ViT (backside community), and additional fine-tuned. This requires fewer coaching steps to realize robust efficiency with the big mannequin. That is useful as massive video fashions may be prohibitively costly to coach from scratch. |
Outcomes
We consider our sparse tube ViT method utilizing Kinetics-400 (proven beneath), Kinetics-600 and Kinetics-700 datasets and evaluate its efficiency to a protracted listing of prior strategies. We discover that our method outperforms all prior strategies. Importantly, it outperforms all state-of-the-art strategies skilled collectively on picture+video datasets.
 |
| Efficiency in comparison with a number of prior works on the favored Kinetics-400 video dataset. Our sparse tube ViT outperforms state-of-the-art strategies. |
Moreover, we take a look at our sparse tube ViT mannequin on the Something-Something V2 dataset, which is usually used to judge extra dynamic actions, and in addition report that it outperforms all prior state-of-the-art approaches.
 |
| Efficiency on the One thing-One thing V2 video dataset. |
Visualizing some realized kernels
It’s attention-grabbing to know what sort of rudimentary options are being realized by the proposed mannequin. We visualize them beneath, exhibiting each the 2D patches, that are shared for each photos and movies, and video tubes. These visualizations present the 2D or 3D info being captured by the projection layer. For instance, within the 2D patches, numerous frequent options, like edges and colours, are detected, whereas the 3D tubes seize primary shapes and the way they might change over time.
 |
| Visualizations of patches and tubes realized the sparse tube ViT mannequin. High row are the 2D patches and the remaining two rows are snapshots from the realized video tubes. The tubes present every patch for the 8 or 4 frames to which they’re utilized. |
Conclusions
We have now offered a brand new sparse tube ViT, which may flip a ViT encoder into an environment friendly video mannequin, and might seamlessly work with each picture and video inputs. We additionally confirmed that giant video encoders could be bootstrapped from small video encoders and image-only ViTs. Our method outperforms prior strategies throughout a number of well-liked video understanding benchmarks. We imagine that this straightforward illustration can facilitate way more environment friendly studying with enter movies, seamlessly incorporate both picture or video inputs and successfully remove the bifurcation of picture and video fashions for future multimodal understanding.
Acknowledgements
This work is carried out by AJ Piergiovanni, Weicheng Kuo and Anelia Angelova, who at the moment are at Google DeepMind. We thank Abhijit Ogale, Luowei Zhou, Claire Cui and our colleagues in Google Analysis for his or her useful discussions, feedback, and help.






