Past the Fundamentals: Reinforcement Studying with Jax — Half I: Introduction and Core Ideas | by Lando L | Could, 2023
A number of the most important breakthroughs in synthetic intelligence are impressed by nature and the RL paradigm is not any exception. This easy but highly effective idea is closest to how we people study and could be seen as an important component of what we’d anticipate from a synthetic basic intelligence: Studying by means of trial and error. This method to studying teaches us about trigger and impact, and the way our actions affect our surroundings. It teaches us how our behaviour can both hurt or profit us, and permits us to develop methods to attain our long-term targets.
What’s RL?
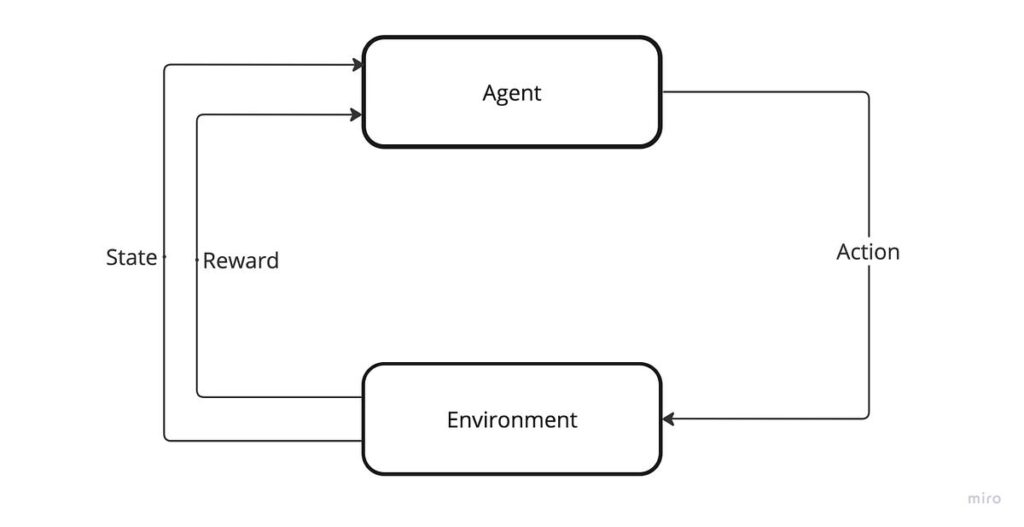
The RL paradigm is a robust and versatile machine studying method that allows resolution makers to study from their interactions with the atmosphere. It attracts from a variety of concepts and methodologies for locating an optimum technique to maximise a numerical reward. With an extended historical past of connections to different scientific and engineering disciplines, analysis in RL is well-established. Nevertheless, whereas there’s a wealth of educational success, sensible purposes of RL within the business sphere stay uncommon. Essentially the most well-known examples of RL in motion are computer systems attaining super-human stage efficiency on video games resembling chess and Go, in addition to on titles like Atari and Starcraft. Lately, nevertheless, we’ve seen a rising variety of industries undertake RL strategies.
How is it used as we speak?
Regardless of the low stage of business adoption of RL, there are some thrilling purposes within the area of:
- Well being: Dynamic therapy regime; automated analysis; drug discovery
- Finance: Buying and selling; dynamic pricing; danger administration
- Transportation: Adaptive visitors management; autonomous driving
- Suggestion: Internet search; information advice; product advice
- Pure Language Processing: textual content summarization; query answering; machine translation; dialog era
A great way to realize an understanding of RL use circumstances is to think about an instance problem. Allow us to think about we try to assist our good friend study to play a musical instrument. Every morning, our good friend tells us how motivated they really feel and the way a lot they’ve discovered throughout yesterday’s follow, and asks us how they need to proceed. For causes unknown to us, our good friend has a restricted set of learning selections: Taking a time off, practising for one hour, or practising for 3 hours.
After observing our good friend’s progress, we’ve seen a couple of fascinating traits:
- It seems that the progress our good friend is making is straight correlated with the quantity of hours they follow.
- Constant follow periods make our good friend progress quicker.
- Our good friend doesn’t do effectively with lengthy practising periods. Each time we instructed them to check for 3 hours, the subsequent day they felt drained and unmotivated to proceed.
From our observations, we’ve created a graph modeling their studying progress utilizing state machine notation.

Allow us to focus on once more our findings based mostly on our mannequin:
- Our good friend has three distinct emotional states: impartial, motivated, and demotivated.
- On any given day, they’ll select to follow for zero, one, or three hours, besides when they’re feeling demotivated — wherein case learning for zero hours (or not learning) is their solely out there possibility.
- Our good friend’s temper is predictive: Within the impartial state, practising for one hour, will make them really feel motivated the next day, whereas practising for 3 hours will go away them feeling demotivated und not practising in any respect will preserve them in a impartial state. Conversely, within the motivated state, one hour of follow will keep our good friend’s motivation, whereas three hours of follow will demotivate them and no follow in any respect will go away them feeling impartial. Lastly, within the demotivated state, our good friend will chorus from learning altogether, leading to them feeling impartial the subsequent day.
- Their progress is closely influenced by their temper and the quantity of follow they put in: the extra motivated they’re and the extra hours they dedicate to follow, the quicker they may study and develop.
Why did we construction our findings like this? As a result of it helps us mannequin our problem utilizing a mathematical framework known as finite Markov resolution processes (MDPs). This method helps us achieve a greater understanding of the issue and the way to greatest tackle it.
Markov Decission Processes
Finite MDPs present a helpful framework to mannequin RL issues, permitting us to summary away from the specifics of a given drawback and formulate it in a means that may be solved utilizing RL algorithms. In doing so, we’re in a position to switch learnings from one drawback to a different, as a substitute of getting to theorise about every drawback individually. This helps us to simplify the method of fixing advanced RL issues. Formally, a finite MDP is a management course of outlined by a four-tuple:

The four-tuple (S, A, P, R) defines 4 distinct parts, every of which describes a particular side of the system. S and A outline the set of states and actions respectively. Whereas, P denotes the transition operate and R denotes the reward operate. In our instance, we outline our good friend’s temper as our set of states S and their follow selections as our set of actions A. The transition operate P, visualised by arrows within the graph, exhibits us how our good friend’s temper will likely be altered relying on the quantity of learning they do. Moreover, the reward operate R is used to measure the progress our good friend has made, which is influenced by their temper and the follow selections they make.
Insurance policies and worth capabilities
Given the MDP, we are able to now develop methods for our good friend. Drawing on the knowledge of our favourite cooking podcast, we’re reminded that to grasp the artwork of cooking one should develop a routine of practising a bit of day by day. Impressed by this concept, we develop a method for our good friend that advocates for a constant follow schedule: follow for one hour day by day. In RL principle, methods are known as insurance policies or coverage capabilities, and are outlined as mappings from the set of states to the chances of every doable motion in that state. Formally, a coverage π is a likelihood distribution over actions a given state s.

To stick to the “follow a bit of day by day” mantra, we set up a coverage with a 100% likelihood of practising for one hour in each the impartial and motivated states. Nevertheless, within the demotivated state, we skip follow 100% of the time, since it’s the solely out there motion. This instance demonstrates that insurance policies could be deterministic, as a substitute of returning a full likelihood distribution over out there actions, they return a degenerate distribution with a single motion which is taken completely.

As a lot as we belief our favorite cooking podcast, we want to learn the way effectively our good friend is doing by following our technique. In RL lingo we communicate of evaluating our coverage, which is outlined by the worth operate. To get a primary impression, allow us to calculate how a lot data our good friend is gaining by following our technique for ten days. Assuming they begin the follow feeling impartial, they may achieve one unit of information on the primary day and two models of information thereafter, leading to a complete of 19 models. Conversely, if our good friend had already been motivated on the primary day, they’d have gained 20 models of information and if that they had began feeling demotivated, they’d have gained solely 17 models.
Whereas this calculation could seem a bit of arbitrary at first, there are literally a couple of issues we are able to study from it. Firstly, we intuitively discovered a method to assign our coverage a numerical worth. Secondly, we observe that this worth relies on the temper our good friend begins in. That mentioned, allow us to take a look on the formal definition of worth capabilities. A worth operate v of state s is outlined because the anticipated discounted return an agent receives beginning in state s and following coverage π thereafter. We confer with v because the state-value operate for coverage π. The place we outline the state-value operate because the anticipated worth E of the discounted return G when beginning in state s

The place we outline the state-value operate because the anticipated worth E of the discounted return G when beginning in state s. Because it seems, our first method is in truth not far off the precise definition. The one distinction is that we based mostly our calculations on the sum of information positive aspects over a set variety of days, versus the extra goal anticipated discounted return G. In RL principle, the discounted return is outlined because the sum of discounted future rewards:

The place R denotes the reward at timestep t multiplied by the low cost price denoted by a lowercase gamma. The low cost price lies within the interval of zero to at least one and determines how a lot worth we assign to future rewards. To raised perceive the implication of the low cost price on the sum of rewards allow us to contemplate the particular circumstances of assigning gamma to zero or to at least one. By setting gamma to zero, we contemplate solely quick rewards and disrespect any future rewards, which means the discounted return would solely equal the reward R at timestep t+1. Conversely, when gamma is ready to at least one, we assign any future rewards their full worth, thus the discounted return would equal the sum of all future rewards.
Outfitted with the idea of worth capabilities and discounted returns we are able to now correctly consider our coverage. Firstly, we have to determine on an appropriate low cost price for our instance. We should discard zero as a doable candidate, as it might not account for the long-term worth of information era we’re eager about. A reduction price of 1 also needs to be averted, as our instance doesn’t have a pure notion of a remaining state; thus, any coverage that features common follow of the instrument, regardless of how ineffective, would yield an infinite quantity of information with sufficient time. Therefore, chosing a reduction price of 1, would make us detached between having our good friend follow day by day or yearly. After rejecting the particular circumstances of zero and one, we’ve to decide on an appropriate low cost price between the 2. The smaller the low cost price, the much less worth is assigned to future rewards and vice versa. For our instance, we set the low cost price to 0.9 and calculate the discounted returns for every of our good friend’s moods. Allow us to begin once more with the motivated state. As an alternative of contemplating solely the subsequent ten days, we calculate the sum of all discounted future rewards, leading to 20 models of information. The calculation is as follows¹:

Observe, by introducing a reduction price smaller than one, the sum of an infinite variety of future rewards remains to be fixed. The subsequent state we want to analyze is the impartial state. On this state, our agent choses to follow for one hour, gaining one unit of information, after which transitions to the motivated state. This simplifies the calculation course of tremendously, as we already know the worth of the motivated state.
As a remaining step, we are able to additionally calculate the worth operate of the demotivated state. The method is analogous to the impartial state, leading to a worth of a bit of over 17.

By analyzing the state-value capabilities of our coverage in all states, we are able to deduce that the motivated state is probably the most rewarding, which is why we must always instruct our good friend to succeed in it as shortly as doable and stay there.
I encourage you to think about creating various coverage capabilities and evaluating them utilizing the state-value operate. Whereas a few of them could also be extra profitable within the brief time period, they won’t generate as a lot models of information as our proposed principle within the long-term². If you wish to dig deeper into the maths behind MDPs, insurance policies and worth capabilities, I extremely suggest “Reinforcement Studying — An Introduction” by Richard S. Sutton and Andrew G. Barto. Alternatively, I counsel trying out the “RL Course by David Silver” on YouTube.
What if our good friend was not into music, however as a substitute requested us to assist them construct a self-driving automobile, or our supervisor instructed our workforce to develop an improved recommender system? Sadly, discovering the optimum coverage for our instance is not going to assist us a lot with different RL issues. Due to this fact, we have to devise algorithms which can be able to fixing any finite MDP².
Within the following weblog posts you’ll discover the way to apply numerous RL algorithms to sensible examples. We’ll begin with tabular answer strategies, that are the only type of RL algorithms and are appropriate for fixing MDPs with small state and motion areas, such because the one in our instance. We’ll then delve into deep studying to sort out extra intricate RL issues with arbitrarily massive state and motion areas, the place tabular strategies are not possible. These approximate options strategies would be the focus of the second a part of this course. Lastly, to conclude the course, we are going to cowl among the most revolutionary papers within the area of RL, offering a complete evaluation of every one, together with sensible examples as an instance the idea.




