Rapidly construct high-accuracy Generative AI functions on enterprise information utilizing Amazon Kendra, LangChain, and huge language fashions
Generative AI (GenAI) and huge language fashions (LLMs), comparable to these accessible quickly by way of Amazon Bedrock and Amazon Titan are remodeling the way in which builders and enterprises are capable of remedy historically complicated challenges associated to pure language processing and understanding. A number of the advantages provided by LLMs embody the flexibility to create extra succesful and compelling conversational AI experiences for customer support functions, and enhancing worker productiveness via extra intuitive and correct responses.
For these use circumstances, nonetheless, it’s vital for the GenAI functions implementing the conversational experiences to fulfill two key standards: restrict the responses to firm information, thereby mitigating mannequin hallucinations (incorrect statements), and filter responses in accordance with the end-user content material entry permissions.
To limit the GenAI software responses to firm information solely, we have to use a method referred to as Retrieval Augmented Era (RAG). An software utilizing the RAG strategy retrieves info most related to the consumer’s request from the enterprise data base or content material, bundles it as context together with the consumer’s request as a immediate, after which sends it to the LLM to get a GenAI response. LLMs have limitations across the most phrase depend for the enter immediate, subsequently selecting the best passages amongst 1000’s or thousands and thousands of paperwork within the enterprise, has a direct influence on the LLM’s accuracy.
In designing efficient RAG, content material retrieval is a vital step to make sure the LLM receives probably the most related and concise context from enterprise content material to generate correct responses. That is the place the extremely correct, machine studying (ML)-powered intelligent search in Amazon Kendra performs an essential function. Amazon Kendra is a completely managed service that gives out-of-the-box semantic search capabilities for state-of-the-art rating of paperwork and passages. You should use the high-accuracy search in Amazon Kendra to supply probably the most related content material and paperwork to maximise the standard of your RAG payload, yielding higher LLM responses than utilizing standard or keyword-based search options. Amazon Kendra provides easy-to-use deep studying search fashions which can be pre-trained on 14 domains and don’t require any ML experience, so there’s no have to cope with phrase embeddings, doc chunking, and different lower-level complexities sometimes required for RAG implementations. Amazon Kendra additionally comes with pre-built connectors to fashionable information sources comparable to Amazon Simple Storage Service (Amazon S3), SharePoint, Confluence, and web sites, and helps widespread doc codecs comparable to HTML, Phrase, PowerPoint, PDF, Excel, and pure textual content information. To filter responses based mostly on solely these paperwork that the end-user permissions enable, Amazon Kendra provides connectors with entry management listing (ACL) help. Amazon Kendra additionally provides AWS Identity and Access Management (IAM) and AWS IAM Identity Center (successor to AWS Single Signal-On) integration for user-group info syncing with buyer id suppliers comparable to Okta and Azure AD.
On this submit, we exhibit tips on how to implement a RAG workflow by combining the capabilities of Amazon Kendra with LLMs to create state-of-the-art GenAI functions offering conversational experiences over your enterprise content material. After Amazon Bedrock launches, we are going to publish a follow-up submit exhibiting tips on how to implement related GenAI functions utilizing Amazon Bedrock, so keep tuned.
Resolution overview
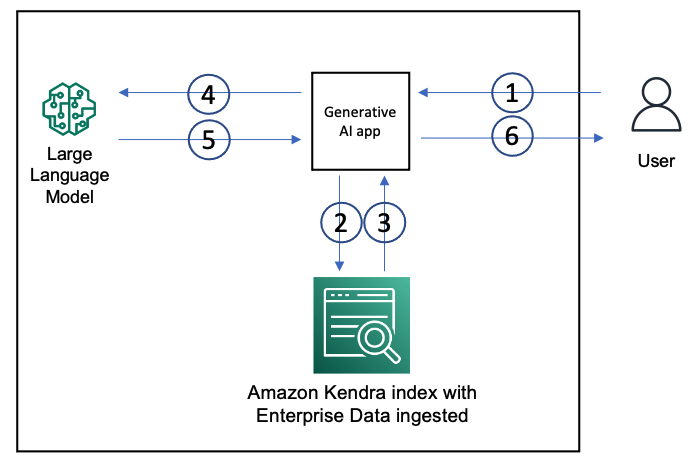
The next diagram exhibits the structure of a GenAI software with a RAG strategy.

We use an Amazon Kendra index to ingest enterprise unstructured information from information sources comparable to wiki pages, MS SharePoint websites, Atlassian Confluence, and doc repositories comparable to Amazon S3. When a consumer interacts with the GenAI app, the movement is as follows:
- The consumer makes a request to the GenAI app.
- The app points a search question to the Amazon Kendra index based mostly on the consumer request.
- The index returns search outcomes with excerpts of related paperwork from the ingested enterprise information.
- The app sends the consumer request and together with the information retrieved from the index as context within the LLM immediate.
- The LLM returns a succinct response to the consumer request based mostly on the retrieved information.
- The response from the LLM is distributed again to the consumer.
With this structure, you may select probably the most appropriate LLM on your use case. LLM choices embody our companions Hugging Face, AI21 Labs, Cohere, and others hosted on an Amazon SageMaker endpoint, in addition to fashions by firms like Anthropic and OpenAI. With Amazon Bedrock, it is possible for you to to decide on Amazon Titan, Amazon’s personal LLM, or companion LLMs comparable to these from AI21 Labs and Anthropic with APIs securely with out the necessity on your information to go away the AWS ecosystem. The extra advantages that Amazon Bedrock will supply embody a serverless structure, a single API to name the supported LLMs, and a managed service to streamline the developer workflow.
For the perfect outcomes, a GenAI app must engineer the immediate based mostly on the consumer request and the particular LLM getting used. Conversational AI apps additionally have to handle the chat historical past and the context. GenAI app builders can use open-source frameworks comparable to LangChain that present modules to combine with the LLM of selection, and orchestration instruments for actions comparable to chat historical past administration and immediate engineering. We have now offered the KendraIndexRetriever class, which implements a LangChain retriever interface, which functions can use at the side of different LangChain interfaces comparable to chains to retrieve information from an Amazon Kendra index. We have now additionally offered just a few pattern functions within the GitHub repo. You’ll be able to deploy this resolution in your AWS account utilizing the step-by-step information on this submit.
Stipulations
For this tutorial, you’ll want a bash terminal with Python 3.9 or greater put in on Linux, Mac, or Home windows Subsystem for Linux, and an AWS account. We additionally advocate utilizing an AWS Cloud9 occasion or an Amazon Elastic Compute Cloud (Amazon EC2) occasion.
Implement a RAG workflow
To configure your RAG workflow, full the next steps:
- Use the offered AWS CloudFormation template to create a brand new Amazon Kendra index.
This template consists of pattern information containing AWS on-line documentation for Amazon Kendra, Amazon Lex, and Amazon SageMaker. Alternately, if in case you have an Amazon Kendra index and have listed your personal dataset, you should use that. Launching the stack requires about half-hour adopted by about quarter-hour to synchronize it and ingest the information within the index. Due to this fact, anticipate about 45 minutes after launching the stack. Be aware the index ID and AWS Area on the stack’s Outputs tab.
- For an improved GenAI expertise, we advocate requesting an Amazon Kendra service quota increase for optimum
DocumentExcerptmeasurement, in order that Amazon Kendra supplies bigger doc excerpts to enhance semantic context for the LLM. - Set up the AWS SDK for Python on the command line interface of your selection.
- If you wish to use the pattern internet apps constructed utilizing Streamlit, you first have to install Streamlit. This step is non-compulsory if you wish to solely run the command line variations of the pattern functions.
- Install LangChain.
- The pattern functions used on this tutorial require you to have entry to a number of LLMs from Flan-T5-XL, Flan-T5-XXL, Anthropic Claud-V1, and OpenAI-text-davinci-003.
- If you wish to use Flan-T5-XL or Flan-T5-XXL, deploy them to an endpoint for inference utilizing Amazon SageMaker Studio Jumpstart.

- If you wish to work with Anthropic Claud-V1 or OpenAI-da-vinci-003, purchase the API keys on your LLMs of your curiosity from https://www.anthropic.com/ and https://openai.com/, respectively.
- If you wish to use Flan-T5-XL or Flan-T5-XXL, deploy them to an endpoint for inference utilizing Amazon SageMaker Studio Jumpstart.
- Comply with the directions within the GitHub repo to put in the
KendraIndexRetrieverinterface and pattern functions. - Earlier than you run the pattern functions, it’s essential to set setting variables with the Amazon Kendra index particulars and API keys of your most popular LLM or the SageMaker endpoints of your deployments for Flan-T5-XL or Flan-T5-XXL. The next is a pattern script to set the setting variables:
- In a command line window, change to the
samplessubdirectory of the place you have got cloned the GitHub repository. You’ll be able to run the command line apps from the command line aspython <sample-file-name.py>. You’ll be able to run the streamlit internet app by altering the listing tosamplesand workingstreamlit run app.py <anthropic|flanxl|flanxxl|openai>. - Open the pattern file
kendra_retriever_flan_xxl.pyin an editor of your selection.
Observe the assertion consequence = run_chain(chain, "What's SageMaker?"). That is the consumer question (“What’s SageMaker?”) that’s being run via the chain that makes use of Flan-T-XXL because the LLM and Amazon Kendra because the retriever. When this file is run, you may observe the output as follows. The chain despatched the consumer question to the Amazon Kendra index, retrieved the highest three consequence excerpts, and despatched them because the context in a immediate together with the question, to which the LLM responded with a succinct reply. It has additionally offered the sources, (the URLs to the paperwork utilized in producing the reply).
- Now let’s run the net app
app.pyasstreamlit run app.py flanxxl. For this particular run, we’re utilizing a Flan-T-XXL mannequin because the LLM.
It opens a browser window with the net interface. You’ll be able to enter a question, which on this case is “What’s Amazon Lex?” As seen within the following screenshot, the appliance responds with a solution, and the Sources part supplies the URLs to the paperwork from which the excerpts have been retrieved from the Amazon Kendra index and despatched to the LLM within the immediate because the context together with the question.

- Now let’s run
app.pyonce more and get a really feel of the conversational expertise utilizingstreamlit run app.py anthropic. Right here the underlying LLM used is Anthropic Claud-V1.
As you may see within the following video, the LLM supplies an in depth reply to the consumer’s question based mostly on the paperwork it retrieved from the Amazon Kendra index after which helps the reply with the URLs to the supply paperwork that have been used to generate the reply. Be aware that the following queries don’t explicitly point out Amazon Kendra; nonetheless, the ConversationalRetrievalChain (a kind of chain that’s a part of the LangChain framework and supplies a simple mechanism to develop conversational application-based info retrieved from retriever situations, used on this LangChain software), manages the chat historical past and the context to get an applicable response.
Additionally observe that within the following screenshot, Amazon Kendra finds the extractive reply to the question and shortlists the highest paperwork with excerpts. Then the LLM is ready to generate a extra succinct reply based mostly on these retrieved excerpts.

Within the following sections, we discover two use circumstances for utilizing Generative AI with Amazon Kendra.
Use case 1: Generative AI for monetary service firms
Monetary organizations create and retailer information throughout numerous information repositories, together with monetary stories, authorized paperwork, and whitepapers. They need to adhere to strict authorities rules and oversight, which suggests workers want to search out related, correct, and reliable info rapidly. Moreover, looking and aggregating insights throughout numerous information sources is cumbersome and error inclined. With Generative AI on AWS, customers can rapidly generate solutions from numerous information sources and kinds, synthesizing correct solutions at enterprise scale.
We selected an answer utilizing Amazon Kendra and AI21 Lab’s Jurassic-2 Jumbo Instruct LLM. With Amazon Kendra, you may simply ingest information from a number of information sources comparable to Amazon S3, web sites, and ServiceNow. Then Amazon Kendra makes use of AI21 Lab’s Jurassic-2 Jumbo Instruct LLM to hold out inference actions on enterprise information comparable to information summarization, report technology, and extra. Amazon Kendra augments LLMs to offer correct and verifiable info to the end-users, which reduces hallucination points with LLMs. With the proposed resolution, monetary analysts could make sooner choices utilizing correct information to rapidly construct detailed and complete portfolios. We plan to make this resolution accessible as an open-source challenge in close to future.
Instance
Utilizing the Kendra Chatbot resolution, monetary analysts and auditors can work together with their enterprise information (monetary stories and agreements) to search out dependable solutions to audit-related questions. Kendra ChatBot supplies solutions together with supply hyperlinks and has the potential to summarize longer solutions. The next screenshot exhibits an instance dialog with Kendra ChatBot.

Structure overview
The next diagram illustrates the answer structure.

The workflow consists of the next steps:
- Monetary paperwork and agreements are saved on Amazon S3, and ingested to an Amazon Kendra index utilizing the S3 information supply connector.
- The LLM is hosted on a SageMaker endpoint.
- An Amazon Lex chatbot is used to work together with the consumer by way of the Amazon Lex web UI.
- The answer makes use of an AWS Lambda operate with LangChain to orchestrate between Amazon Kendra, Amazon Lex, and the LLM.
- When customers ask the Amazon Lex chatbot for solutions from a monetary doc, Amazon Lex calls the LangChain orchestrator to satisfy the request.
- Based mostly on the question, the LangChain orchestrator pulls the related monetary data and paragraphs from Amazon Kendra.
- The LangChain orchestrator supplies these related data to the LLM together with the question and related immediate to hold out the required exercise.
- The LLM processes the request from the LangChain orchestrator and returns the consequence.
- The LangChain orchestrator will get the consequence from the LLM and sends it to the end-user via the Amazon Lex chatbot.
Use case 2: Generative AI for healthcare researchers and clinicians
Clinicians and researchers typically analyze 1000’s of articles from medical journals or authorities well being web sites as a part of their analysis. Extra importantly, they need reliable information sources they will use to validate and substantiate their findings. The method requires hours of intensive analysis, evaluation, and information synthesis, lengthening the time to worth and innovation. With Generative AI on AWS, you may hook up with trusted information sources and run pure language queries to generate insights throughout these trusted information sources in seconds. You can even assessment the sources used to generate the response and validate its accuracy.
We selected an answer utilizing Amazon Kendra and Flan-T5-XXL from Hugging Face. First, we use Amazon Kendra to determine textual content snippets from semantically related paperwork in the complete corpus. Then we use the ability of an LLM comparable to Flan-T5-XXL to make use of the textual content snippets from Amazon Kendra as context and acquire a succinct pure language reply. On this strategy, the Amazon Kendra index features because the passage retriever element within the RAG mechanism. Lastly, we use Amazon Lex to energy the entrance finish, offering a seamless and responsive expertise to end-users. We plan to make this resolution accessible as an open-source challenge within the close to future.
Instance
The next screenshot is from an online UI constructed for the answer utilizing the template accessible on GitHub. The textual content in pink are responses from the Amazon Kendra LLM system, and the textual content in blue are the consumer questions.

Structure overview
The structure and resolution workflow for this resolution are just like that of use case 1.
Clear up
To save lots of prices, delete all of the assets you deployed as a part of the tutorial. When you launched the CloudFormation stack, you may delete it by way of the AWS CloudFormation console. Equally, you may delete any SageMaker endpoints you could have created by way of the SageMaker console.
Conclusion
Generative AI powered by massive language fashions is altering how individuals purchase and apply insights from info. Nevertheless, for enterprise use circumstances, the insights have to be generated based mostly on enterprise content material to maintain the solutions in-domain and mitigate hallucinations, utilizing the Retrieval Augmented Era strategy. Within the RAG strategy, the standard of the insights generated by the LLM will depend on the semantic relevance of the retrieved info on which it’s based mostly, making it more and more crucial to make use of options comparable to Amazon Kendra that present high-accuracy semantic search outcomes out of the field. With its complete ecosystem of information supply connectors, help for widespread file codecs, and safety, you may rapidly begin utilizing Generative AI options for enterprise use circumstances with Amazon Kendra because the retrieval mechanism.
For extra info on working with Generative AI on AWS, seek advice from Announcing New Tools for Building with Generative AI on AWS. You can begin experimenting and constructing RAG proofs of idea (POCs) on your enterprise GenAI apps, utilizing the strategy outlined on this weblog. As talked about earlier, as soon as Amazon Bedrock is offered, we are going to publish a observe up weblog exhibiting how one can construct RAG utilizing Amazon Bedrock.
Concerning the authors
 Abhinav Jawadekar is a Principal Options Architect centered on Amazon Kendra within the AI/ML language companies crew at AWS. Abhinav works with AWS prospects and companions to assist them construct clever search options on AWS.
Abhinav Jawadekar is a Principal Options Architect centered on Amazon Kendra within the AI/ML language companies crew at AWS. Abhinav works with AWS prospects and companions to assist them construct clever search options on AWS.
 Jean-Pierre Dodel is the Principal Product Supervisor for Amazon Kendra and leads key strategic product capabilities and roadmap prioritization. He brings in depth Enterprise Search and ML/AI expertise to the crew, with prior main roles at Autonomy, HP, and search startups previous to becoming a member of Amazon 7 years in the past.
Jean-Pierre Dodel is the Principal Product Supervisor for Amazon Kendra and leads key strategic product capabilities and roadmap prioritization. He brings in depth Enterprise Search and ML/AI expertise to the crew, with prior main roles at Autonomy, HP, and search startups previous to becoming a member of Amazon 7 years in the past.
 Mithil Shah is an ML/AI Specialist at AWS. Presently he helps public sector prospects enhance lives of residents by constructing Machine Studying options on AWS.
Mithil Shah is an ML/AI Specialist at AWS. Presently he helps public sector prospects enhance lives of residents by constructing Machine Studying options on AWS.
 Firaz Akmal is a Sr. Product Supervisor for Amazon Kendra at AWS. He’s a buyer advocate, serving to prospects perceive their search and generative AI use-cases with Kendra on AWS. Exterior of labor Firaz enjoys spending time within the mountains of the PNW or experiencing the world via his daughter’s perspective.
Firaz Akmal is a Sr. Product Supervisor for Amazon Kendra at AWS. He’s a buyer advocate, serving to prospects perceive their search and generative AI use-cases with Kendra on AWS. Exterior of labor Firaz enjoys spending time within the mountains of the PNW or experiencing the world via his daughter’s perspective.
 Abhishek Maligehalli Shivalingaiah is a Senior AI Companies Resolution Architect at AWS with give attention to Amazon Kendra. He’s captivated with constructing functions utilizing Amazon Kendra ,Generative AI and NLP. He has round 10 years of expertise in constructing Knowledge & AI options to create worth for patrons and enterprises. He has constructed a (private) chatbot for enjoyable to solutions questions on his profession {and professional} journey. Exterior of labor he enjoys making portraits of household & pals, and loves creating artworks.
Abhishek Maligehalli Shivalingaiah is a Senior AI Companies Resolution Architect at AWS with give attention to Amazon Kendra. He’s captivated with constructing functions utilizing Amazon Kendra ,Generative AI and NLP. He has round 10 years of expertise in constructing Knowledge & AI options to create worth for patrons and enterprises. He has constructed a (private) chatbot for enjoyable to solutions questions on his profession {and professional} journey. Exterior of labor he enjoys making portraits of household & pals, and loves creating artworks.





