Newbie’s Information to Subqueries in SQL


Picture by Creator | Canva
Subqueries in SQL are nothing legendary or not possible to grasp, as you’ll see on this tutorial. They’re a really great tool for simplifying advanced knowledge duties, enhancing advanced queries’ readability, and doing superior knowledge manipulation operations.
Subqueries are a necessity should you don’t need to stay caught on essentially the most fundamental degree of SQL, knowledge manipulation, and evaluation.
What Is a Subquery in SQL?
A subquery – or an inside question – is a SELECT assertion inside one other SQL assertion generally known as the outer or fundamental question.
In SQL, subqueries are utilized in these statements/clauses:
- SELECT
- INSERT
- UPDATE
- DELETE
- WHERE
- HAVING
- FROM
- SET
Forms of SQL Subqueries
Subqueries are usually categorized into 4 sorts. Typically, subqueries are used for filtering knowledge (in WHERE or HAVING) or for creating derived tables in FROM.
Right here’s a extra detailed overview of the 4 subquery sorts and their frequent use circumstances.

SQL Subqueries in Motion
Let’s now undergo one sensible instance for every subquery sort.
Filtering Knowledge With Single-Row Subqueries
The question by Yelp asks you to seek out the overview textual content with the best variety of ‘cool’ votes. The output ought to include the enterprise title and the overview textual content.
The answer may be written utilizing a single-row subquery. That subquery is used to calculate the utmost variety of cool votes (a single worth; that’s why it’s a single-row subquery) and can be positioned within the WHERE clause of the principle question to output solely companies (and the overview texts) with the best variety of ‘cool’ votes.
SELECT business_name,
review_text
FROM yelp_reviews
WHERE cool =
(SELECT MAX(cool)
FROM yelp_reviews);
Right here’s the output.

Filtering Knowledge Multi-Row Subqueries
Twitter and Asana’s interview question requires you to seek out the worker with the best wage per division. The output ought to include the division, worker’s title, and wage.
We will remedy this drawback utilizing a multi-row subquery.
First, we write the outer question that can output the required column after which use the subquery to filter knowledge. The information is filtered utilizing WHERE and IN to seek out the division and wage within the subquery’s output.
The subquery makes use of MAX() to seek out the best wage. For this most to be proven on a division degree, you want to checklist the division column in SELECT and GROUP BY. The subquery’s output will include one knowledge row for every division; that’s why it’s a multi-row subquery.
SELECT division AS division,
first_name AS employee_name,
wage
FROM worker
WHERE (division, wage) IN
(SELECT division,
MAX(wage)
FROM worker
GROUP BY division
);
Right here’s the output.

Filtering Knowledge With Correlated Question
We’ll rewrite the code from the earlier instance utilizing the correlated question.
SELECT division AS division,
first_name AS employee_name,
wage
FROM worker AS oq
WHERE wage = (
SELECT MAX(sq.wage)
FROM worker AS sq
WHERE sq.division = oq.division
);
The outer a part of the question is identical, besides that we’ve given the desk worker an alias oq (as in ‘outer question’). That is so we are able to distinguish between the desk used right here and in a subquery.
Within the WHERE clause, we’re evaluating the wage with the results of the subquery.
Within the subquery, we once more fetch the information from the worker desk, however this time, we give it an alias sq (as in ‘subquery’). We use MAX() to calculate the best wage. To verify the utmost is calculated for every division output by the outer question, we set the situation in WHERE that the column division from the desk utilized in an inside question is identical as within the desk used within the outer question.
The output is identical as within the earlier instance.

Creating Derived Tables With Nested Queries
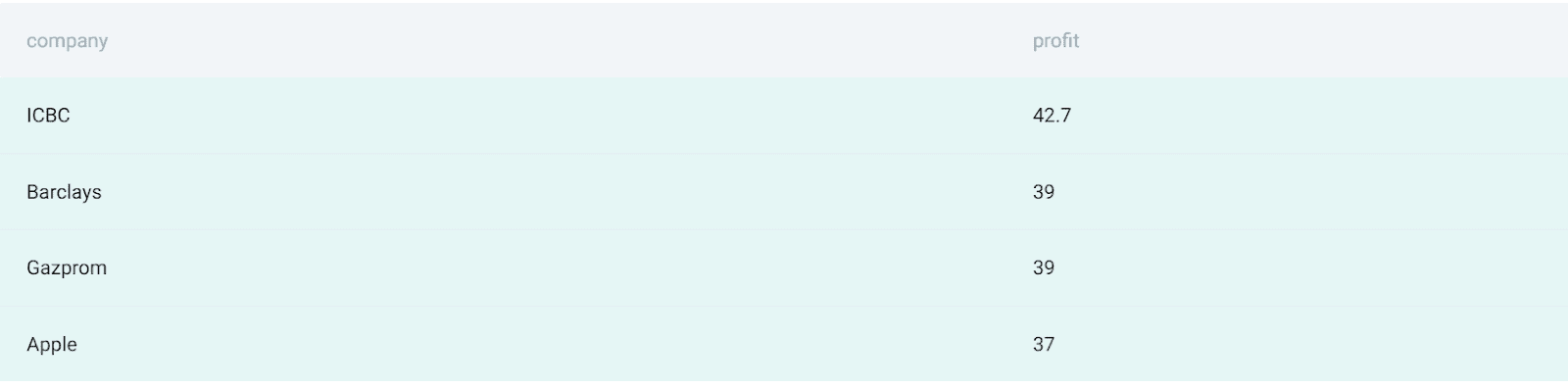
In this question by Forbes, we’re requested to seek out the three most worthwhile firms on the planet.
There are additionally extra necessities:
- The output must be sorted by revenue in descending order.
- The businesses with the identical revenue ranges ought to get the identical rank, and all must be included within the output.
- The output ought to include the corporate title and the revenue quantity.
Our resolution comprises two subqueries. Let’s begin the reason from the second subquery after which construct the answer as much as the outer question.
The second subquery is proven under. It aggregates knowledge to calculate income by firm.
SELECT firm,
SUM(income) AS revenue
FROM forbes_global_2010_2014
GROUP BY firm
We’ll now embed this subquery into the FROM clause of one other SELECT assertion like this. The subqueries in FROM need to be named, so we give it a reputation sq.
SELECT *,
DENSE_RANK() OVER (ORDER BY revenue DESC) AS rank
FROM
(SELECT firm,
SUM(income) AS revenue
FROM forbes_global_2010_2014
GROUP BY firm) sq
The subquery is used as a desk by this ‘outer’ question to rank the businesses by their revenue descendingly. We use the DENSE_RANK() window operate as a result of it would assign the identical rank to the businesses with the identical revenue ranges.
Nonetheless, the ‘outer’ question will not be truly an actual outer question as a result of it would, too, be embedded within the FROM clause of one more SELECT assertion. (Now why these are known as nested subqueries.)
The outer question on this ultimate resolution makes use of the rating subquery merely to output the required knowledge: firm and revenue columns, with the situation in WHERE for exhibiting solely firms ranked from 1 to three.
SELECT firm,
revenue
FROM
(SELECT *,
DENSE_RANK() OVER (ORDER BY revenue DESC) AS rank
FROM
(SELECT firm,
SUM(income) AS revenue
FROM forbes_global_2010_2014
GROUP BY firm) sq) sq2
WHERE rank <=3;
Right here’s the output.
Conclusion
That is simply an introduction to SQL subqueries, however I feel it’ll offer you begin as a newbie. We’ve lined the 4 fundamental subquery sorts and seen a sensible instance for every one.
Take the basics you bought right here to write down your individual SQL subqueries and recommendations on how to learn SQL to enhance your knowledge manipulation abilities.
Nate Rosidi is an information scientist and in product technique. He is additionally an adjunct professor instructing analytics, and is the founding father of StrataScratch, a platform serving to knowledge scientists put together for his or her interviews with actual interview questions from high firms. Nate writes on the newest traits within the profession market, offers interview recommendation, shares knowledge science tasks, and covers every part SQL.





