Use streaming ingestion with Amazon SageMaker Function Retailer and Amazon MSK to make ML-backed selections in near-real time
Companies are more and more utilizing machine studying (ML) to make near-real-time selections, akin to inserting an advert, assigning a driver, recommending a product, and even dynamically pricing services and products. ML fashions make predictions given a set of enter knowledge often called options, and knowledge scientists simply spend greater than 60% of their time designing and constructing these options. Moreover, extremely correct predictions rely on well timed entry to function values that change rapidly over time, including much more complexity to the job of constructing a extremely obtainable and correct resolution. For instance, a mannequin for a ride-sharing app can select the most effective worth for a ride from the airport, however provided that it is aware of the variety of trip requests acquired previously 10 minutes and the variety of passengers projected to land within the subsequent 10 minutes. A routing mannequin in a name middle app can choose the most effective obtainable agent for an incoming name, nevertheless it’s solely efficient if it is aware of the client’s newest internet session clicks.
Though the enterprise worth of near-real-time ML predictions is big, the structure required to ship them reliably, securely, and with good efficiency is difficult. Options want high-throughput updates and low-latency retrieval of the latest function values in milliseconds, one thing most knowledge scientists aren’t ready to ship. In consequence, some enterprises have spent hundreds of thousands of {dollars} inventing their very own proprietary infrastructure for function administration. Different corporations have restricted their ML purposes to easier patterns like batch scoring till ML distributors present extra complete off-the-shelf options for on-line function shops.
To deal with these challenges, Amazon SageMaker Feature Store offers a totally managed central repository for ML options, making it straightforward to securely retailer and retrieve options with out having to construct and keep your individual infrastructure. Function Retailer allows you to outline teams of options, use batch ingestion and streaming ingestion, retrieve the newest function values with single-digit millisecond latency for extremely correct on-line predictions, and extract point-in-time right datasets for coaching. As a substitute of constructing and sustaining these infrastructure capabilities, you get a totally managed service that scales as your knowledge grows, permits sharing options throughout groups, and lets your knowledge scientists give attention to constructing nice ML fashions geared toward game-changing enterprise use instances. Groups can now ship sturdy options as soon as and reuse them many occasions in a wide range of fashions which may be constructed by completely different groups.
This publish walks by means of an entire instance of how one can couple streaming function engineering with Function Retailer to make ML-backed selections in near-real time. We present a bank card fraud detection use case that updates mixture options from a stay stream of transactions and makes use of low-latency function retrievals to assist detect fraudulent transactions. Strive it out for your self by visiting our GitHub repo.
Bank card fraud use case
Stolen bank card numbers may be purchased in bulk on the darkish internet from earlier leaks or hacks of organizations that retailer this delicate knowledge. Fraudsters purchase these card lists and try to make as many transactions as doable with the stolen numbers till the cardboard is blocked. These fraud assaults usually occur in a short while body, and this may be simply noticed in historic transactions as a result of the rate of transactions through the assault differs considerably from the cardholder’s standard spending sample.
The next desk exhibits a sequence of transactions from one bank card the place the cardholder first has a real spending sample, after which experiences a fraud assault beginning on November 4.
| cc_num | trans_time | quantity | fraud_label |
| …1248 | Nov-01 14:50:01 | 10.15 | 0 |
| … 1248 | Nov-02 12:14:31 | 32.45 | 0 |
| … 1248 | Nov-02 16:23:12 | 3.12 | 0 |
| … 1248 | Nov-04 02:12:10 | 1.01 | 1 |
| … 1248 | Nov-04 02:13:34 | 22.55 | 1 |
| … 1248 | Nov-04 02:14:05 | 90.55 | 1 |
| … 1248 | Nov-04 02:15:10 | 60.75 | 1 |
| … 1248 | Nov-04 13:30:55 | 12.75 | 0 |
For this publish, we practice an ML mannequin to identify this type of conduct by engineering options that describe a person card’s spending sample, such because the variety of transactions or the common transaction quantity from that card in a sure time window. This mannequin protects cardholders from fraud on the level of sale by detecting and blocking suspicious transactions earlier than the cost can full. The mannequin makes predictions in a low-latency, real-time context and depends on receiving up-to-the-minute function calculations so it might probably reply to an ongoing fraud assault. In a real-world state of affairs, options associated to cardholder spending patterns would solely kind a part of the mannequin’s function set, and we will embrace details about the service provider, the cardholder, the machine used to make the cost, and some other knowledge which may be related to detecting fraud.
As a result of our use case depends on profiling a person card’s spending patterns, it’s essential that we will establish bank cards in a transaction stream. Most publicly obtainable fraud detection datasets don’t present this info, so we use the Python Faker library to generate a set of transactions overlaying a 5-month interval. This dataset incorporates 5.4 million transactions unfold throughout 10,000 distinctive (and faux) bank card numbers, and is deliberately imbalanced to match the fact of bank card fraud (solely 0.25% of the transactions are fraudulent). We differ the variety of transactions per day per card, in addition to the transaction quantities. See our GitHub repo for extra particulars.
Overview of the answer
We would like our fraud detection mannequin to categorise bank card transactions by noticing a burst of latest transactions that differs considerably from the cardholder’s standard spending sample. Sounds easy sufficient, however how can we construct it?
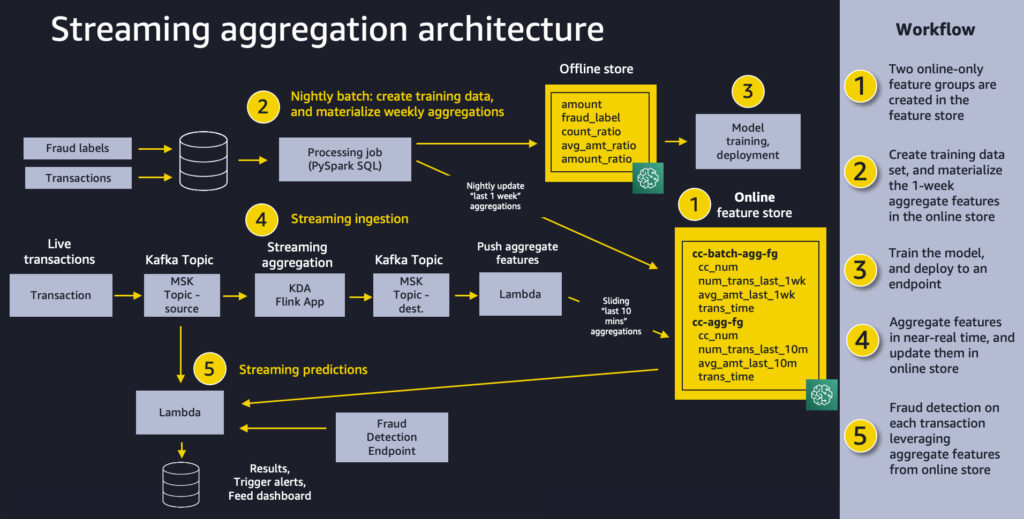
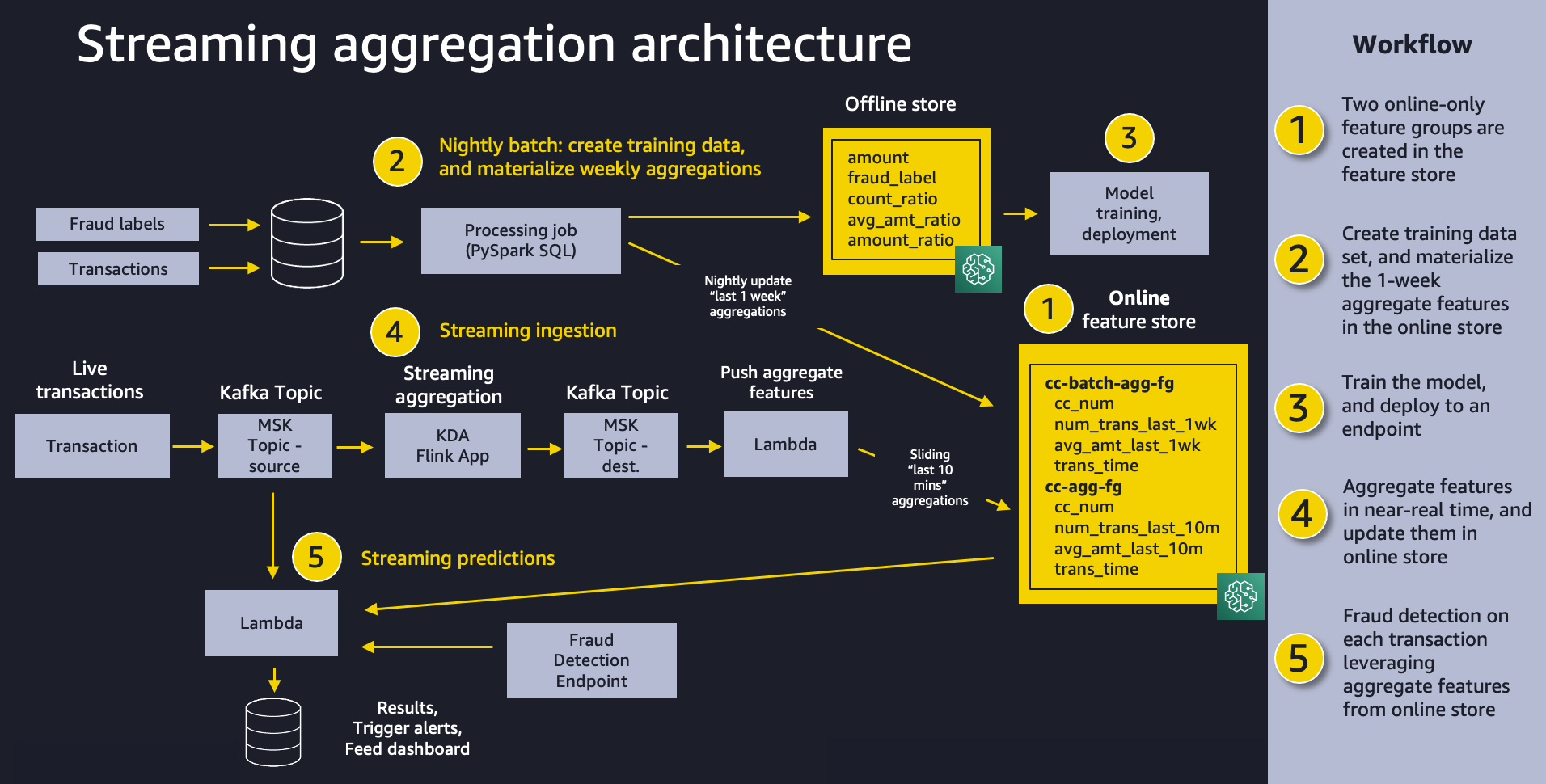
The next diagram exhibits our general resolution structure. We really feel that this identical sample will work effectively for a wide range of streaming aggregation use instances. At a excessive stage, the sample includes the next 5 items:
- Function retailer – We use Function Retailer to supply a repository of options with high-throughput writes and safe low-latency reads, utilizing function values which might be organized into a number of function teams.
- Batch ingestion – Batch ingestion takes labeled historic bank card transactions and creates the combination options and ratios wanted for coaching the fraud detection mannequin. We use an Amazon SageMaker Processing job and the built-in Spark container to calculate mixture weekly counts and transaction quantity averages and ingest them into the function retailer to be used in on-line inference.
- Mannequin coaching and deployment – This side of our resolution is easy. We use Amazon SageMaker to coach a mannequin utilizing the built-in XGBoost algorithm on aggregated options created from historic transactions. The mannequin is deployed to a SageMaker endpoint, the place it handles fraud detection requests on stay transactions.
- Streaming ingestion – An Amazon Kinesis Data Analytics for Apache Flink utility backed by Apache Kafka subjects in Amazon Managed Streaming for Apache Kafka (MSK) (Amazon MSK) calculates aggregated options from a transaction stream, and an AWS Lambda operate updates the web function retailer. Apache Flink is a well-liked framework and engine for processing knowledge streams.
- Streaming predictions – Lastly, we make fraud predictions on a stream of transactions, utilizing Lambda to tug mixture options from the web function retailer. We use the newest function knowledge to calculate transaction ratios after which name the fraud detection endpoint.
Conditions
We offer an AWS CloudFormation template to create the prerequisite sources for this resolution. The next desk lists the stacks obtainable for various Areas.
Within the following sections, we discover every element of our resolution in additional element.
Function retailer
ML fashions depend on well-engineered options coming from a wide range of knowledge sources, with transformations so simple as calculations or as difficult as a multi-step pipeline that takes hours of compute time and complicated coding. Function Retailer permits the reuse of those options throughout groups and fashions, which improves knowledge scientist productiveness, accelerates time to market, and ensures consistency of mannequin enter.
Every function inside Function Retailer is organized right into a logical grouping referred to as a function group. You determine which function teams you want to your fashions. Every one can have dozens, a whole lot, and even hundreds of options. Function teams are managed and scaled independently, however they’re all obtainable for search and discovery throughout groups of information scientists liable for many unbiased ML fashions and use instances.
ML fashions typically require options from a number of function teams. A key side of a function group is how typically its function values have to be up to date or materialized for downstream coaching or inference. You refresh some options hourly, nightly, or weekly, and a subset of options should be streamed to the function retailer in near-real time. Streaming all function updates would result in pointless complexity, and will even decrease the standard of information distributions by not providing you with the prospect to take away outliers.
In our use case, we create a function group referred to as cc-agg-batch-fg for aggregated bank card options up to date in batch, and one referred to as cc-agg-fg for streaming options.
The cc-agg-batch-fg function group is up to date nightly, and offers mixture options trying again over a 1-week time window. Recalculating 1-week aggregations on streaming transactions don’t provide significant indicators, and could be a waste of sources.
Conversely, our cc-agg-fg function group should be up to date in a streaming style, as a result of it gives the newest transaction counts and common transaction quantities trying again over a 10-minute time window. With out streaming aggregation, we couldn’t spot the standard fraud assault sample of a fast sequence of purchases.
By isolating options which might be recalculated nightly, we will enhance ingestion throughput for our streaming options. Separation lets us optimize the ingestion for every group independently. When designing to your use instances, remember that fashions requiring options from numerous function teams might wish to make a number of retrievals from the function retailer in parallel to keep away from including extreme latency to a real-time prediction workflow.
The function teams for our use case are proven within the following desk.
| cc-agg-fg | cc-agg-batch-fg |
| cc_num (file id) | cc_num (file id) |
| trans_time | trans_time |
| num_trans_last_10m | num_trans_last_1w |
| avg_amt_last_10m | avg_amt_last_1w |
Every function group will need to have one function used as a file identifier (for this publish, the bank card quantity). The file identifier acts as a main key for the function group, enabling quick lookups in addition to joins throughout function teams. An occasion time function can also be required, which permits the function retailer to trace the historical past of function values over time. This turns into vital when trying again on the state of options at a selected cut-off date.
In every function group, we monitor the variety of transactions per distinctive bank card and its common transaction quantity. The one distinction between our two teams is the time window used for aggregation. We use a 10-minute window for streaming aggregation, and a 1-week window for batch aggregation.
With Function Retailer, you could have the flexibleness to create function teams which might be offline solely, on-line solely, or each on-line and offline. A web-based retailer offers high-throughput writes and low-latency retrievals of function values, which is good for on-line inference. An offline retailer is supplied utilizing Amazon Simple Storage Service (Amazon S3), giving corporations a extremely scalable repository, with a full historical past of function values, partitioned by function group. The offline retailer is good for coaching and batch scoring use instances.
Once you allow a function group to supply each on-line and offline shops, SageMaker routinely synchronizes function values to an offline retailer, repeatedly appending the newest values to present you a full historical past of values over time. One other good thing about function teams which might be each on-line and offline is that they assist keep away from the issue of coaching and inference skew. SageMaker allows you to feed each coaching and inference with the identical remodeled function values, making certain consistency to drive extra correct predictions. The main focus in our publish is to show on-line function streaming, so we applied online-only function teams.
Batch ingestion
To materialize our batch options, we create a function pipeline that runs as a SageMaker Processing job on a nightly foundation. The job has two duties: producing the dataset for coaching our mannequin, and populating the batch function group with essentially the most up-to-date values for mixture 1-week options, as proven within the following diagram.

Every historic transaction used within the coaching set is enriched with aggregated options for the precise bank card concerned within the transaction. We glance again over two separate sliding time home windows: 1 week again, and the previous 10 minutes. The precise options used to coach the mannequin embrace the next ratios of those aggregated values:
- amt_ratio1 =
avg_amt_last_10m / avg_amt_last_1w - amt_ratio2 =
transaction_amount / avg_amt_last_1w - count_ratio =
num_trans_last_10m / num_trans_last_1w
For instance, count_ratio is the transaction depend from the prior 10 minutes divided by the transaction depend from the final week.
Our ML mannequin can study patterns of regular exercise vs. fraudulent exercise from these ratios, reasonably than counting on uncooked counts and transaction quantities. Spending patterns on completely different playing cards differ significantly, so normalized ratios present a greater sign to the mannequin than the aggregated quantities themselves.
You might be questioning why our batch job is computing options with a 10-minute lookback. Isn’t that solely related for on-line inference? We want the 10-minute window on historic transactions to create an correct coaching dataset. That is important for making certain consistency with the 10-minute streaming window that might be utilized in near-real time to assist on-line inference.
The ensuing coaching dataset from the processing job may be saved immediately as a CSV for mannequin coaching, or it may be bulk ingested into an offline function group that can be utilized for different fashions and by different knowledge science groups to handle all kinds of different use instances. For instance, we will create and populate a function group referred to as cc-transactions-fg. Our coaching job can then pull a selected coaching dataset primarily based on the wants for our particular mannequin, deciding on particular date ranges and a subset of options of curiosity. This strategy permits a number of groups to reuse function teams and keep fewer function pipelines, resulting in vital price financial savings and productiveness enhancements over time. This example notebook demonstrates the sample of utilizing Function Retailer as a central repository from which knowledge scientists can extract coaching datasets.
Along with making a coaching dataset, we use the PutRecord API to place the 1-week function aggregations into the web function retailer nightly. The next code demonstrates placing a file into a web-based function group given particular function values, together with a file identifier and an occasion time:
ML engineers typically construct a separate model of function engineering code for on-line options primarily based on the unique code written by knowledge scientists for mannequin coaching. This will ship the specified efficiency, however is an additional growth step, and introduces extra likelihood for coaching and inference skew. In our use case, we present how utilizing SQL for aggregations can allow an information scientist to supply the identical code for each batch and streaming.
Streaming ingestion
Function Retailer delivers single-digit millisecond retrieval of pre-calculated options, and it might probably additionally play an efficient function in options requiring streaming ingestion. Our use case demonstrates each. Weekly lookback is dealt with as a pre-calculated function group, materialized nightly as proven earlier. Now let’s dive into how we calculate options aggregated on the fly over a 10-minute window and ingest them into the function retailer for later on-line inference.
In our use case, we ingest stay bank card transactions to a supply MSK matter, and use a Kinesis Knowledge Analytics for Apache Flink utility to create mixture options in a vacation spot MSK matter. The appliance is written utilizing Apache Flink SQL. Flink SQL makes it easy to develop streaming purposes utilizing commonplace SQL. It’s straightforward to study Flink if in case you have ever labored with a database or SQL-like system by remaining ANSI-SQL 2011 compliant. Aside from SQL, we will construct Java and Scala purposes in Amazon Kinesis Data Analytics utilizing open-source libraries primarily based on Apache Flink. We then use a Lambda operate to learn the vacation spot MSK matter and ingest the combination options right into a SageMaker function group for inference. Creating the Apache Flink utility utilizing Flink’s SQL API is easy. We use Flink SQL to mixture the streaming knowledge within the supply MSK matter and retailer it in a vacation spot MSK matter.
To supply mixture counts and common quantities trying again over a 10-minute window, we use the next Flink SQL question on the enter matter and pipe the outcomes to the vacation spot matter:
| cc_num | quantity | datetime | num_trans_last_10m | avg_amt_last_10m |
| …1248 | 50.00 | Nov-01,22:01:00 | 1 | 74.99 |
| …9843 | 99.50 | Nov-01,22:02:30 | 1 | 99.50 |
| …7403 | 100.00 | Nov-01,22:03:48 | 1 | 100.00 |
| …1248 | 200.00 | Nov-01,22:03:59 | 2 | 125.00 |
| …0732 | 26.99 | Nov01, 22:04:15 | 1 | 26.99 |
| …1248 | 50.00 | Nov-01,22:04:28 | 3 | 100.00 |
| …1248 | 500.00 | Nov-01,22:05:05 | 4 | 200.00 |
On this instance, discover that the ultimate row has a depend of 4 transactions within the final 10 minutes from the bank card ending with 1248, and a corresponding common transaction quantity of $200.00. The SQL question is in keeping with the one used to drive creation of our coaching dataset, serving to to keep away from coaching and inference skew.
As transactions stream into the Kinesis Knowledge Analytics for Apache Flink aggregation app, the app sends the combination outcomes to our Lambda operate, as proven within the following diagram. The Lambda operate takes these options and populates the cc-agg-fg function group.

We ship the newest function values to the function retailer from Lambda utilizing a easy name to the PutRecord API. The next is the core piece of Python code for storing the combination options:
We put together the file as a listing of named worth pairs, together with the present time because the occasion time. The Function Retailer API ensures that this new file follows the schema that we recognized after we created the function group. If a file for this main key already existed, it’s now overwritten within the on-line retailer.
Streaming predictions
Now that we have now streaming ingestion holding the function retailer updated with the newest function values, let’s have a look at how we make fraud predictions.
We create a second Lambda operate that makes use of the supply MSK matter as a set off. For every new transaction occasion, the Lambda operate first retrieves the batch and streaming options from Function Retailer. To detect anomalies in bank card conduct, our mannequin appears for spikes in latest buy quantities or buy frequency. The Lambda operate computes easy ratios between the 1-week aggregations and the 10-minute aggregations. It then invokes the SageMaker mannequin endpoint utilizing these ratios to make the fraud prediction, as proven within the following diagram.

We use the next code to retrieve function values on demand from the function retailer earlier than calling the SageMaker mannequin endpoint:
SageMaker additionally helps retrieving a number of function data with a single call, even when they’re from completely different function teams.
Lastly, with the mannequin enter function vector assembled, we name the mannequin endpoint to foretell if a selected bank card transaction is fraudulent. SageMaker additionally helps retrieving a number of function data with a single name, even when they’re from completely different function teams.
sagemaker_runtime =
boto3.consumer(service_name="runtime.sagemaker")
request_body = ','.be a part of(options)
response = sagemaker_runtime.invoke_endpoint(
EndpointName=ENDPOINT_NAME,
ContentType="textual content/csv",
Physique=request_body)
chance = json.masses(response['Body'].learn().decode('utf-8'))On this instance, the mannequin got here again with a chance of 98% that the precise transaction was fraudulent, and it was ready to make use of near-real-time aggregated enter options primarily based on the latest 10 minutes of transactions on that bank card.
Check the end-to-end resolution
To show the complete end-to-end workflow of our resolution, we merely ship bank card transactions into our MSK supply matter. Our automated Kinesis Knowledge Analytics for Apache Flink aggregation takes over from there, sustaining a near-real-time view of transaction counts and quantities in Function Retailer, with a sliding 10-minute lookback window. These options are mixed with the 1-week mixture options that have been already ingested to the function retailer in batch, letting us make fraud predictions on every transaction.
We ship a single transaction from three completely different bank cards. We then simulate a fraud assault on a fourth bank card by sending many back-to-back transactions in seconds. The output from our Lambda operate is proven within the following screenshot. As anticipated, the primary three one-off transactions are predicted as NOT FRAUD. Of the ten fraudulent transactions, the primary is predicted as NOT FRAUD, and the remainder are all appropriately recognized as FRAUD. Discover how the combination options are saved present, serving to drive extra correct predictions.

Conclusion
We’ve proven how Function Retailer can play a key function within the resolution structure for important operational workflows that want streaming aggregation and low-latency inference. With an enterprise-ready function retailer in place, you should use each batch ingestion and streaming ingestion to feed function teams, and entry function values on demand to carry out on-line predictions for vital enterprise worth. ML options can now be shared at scale throughout many groups of information scientists and hundreds of ML fashions, enhancing knowledge consistency, mannequin accuracy, and knowledge scientist productiveness. Function Retailer is offered now, and you may check out this entire example. Tell us what you assume.
Particular due to everybody who contributed to the previous blog post with an analogous structure: Paul Hargis, James Leoni and Arunprasath Shankar.
In regards to the Authors
 Mark Roy is a Principal Machine Studying Architect for AWS, serving to prospects design and construct AI/ML options. Mark’s work covers a variety of ML use instances, with a main curiosity in function shops, pc imaginative and prescient, deep studying, and scaling ML throughout the enterprise. He has helped corporations in lots of industries, together with insurance coverage, monetary companies, media and leisure, healthcare, utilities, and manufacturing. Mark holds six AWS certifications, together with the ML Specialty Certification. Previous to becoming a member of AWS, Mark was an architect, developer, and know-how chief for over 25 years, together with 19 years in monetary companies.
Mark Roy is a Principal Machine Studying Architect for AWS, serving to prospects design and construct AI/ML options. Mark’s work covers a variety of ML use instances, with a main curiosity in function shops, pc imaginative and prescient, deep studying, and scaling ML throughout the enterprise. He has helped corporations in lots of industries, together with insurance coverage, monetary companies, media and leisure, healthcare, utilities, and manufacturing. Mark holds six AWS certifications, together with the ML Specialty Certification. Previous to becoming a member of AWS, Mark was an architect, developer, and know-how chief for over 25 years, together with 19 years in monetary companies.
 Raj Ramasubbu is a Senior Analytics Specialist Options Architect targeted on massive knowledge and analytics and AI/ML with Amazon Internet Companies. He helps prospects architect and construct extremely scalable, performant, and safe cloud-based options on AWS. Raj supplied technical experience and management in constructing knowledge engineering, massive knowledge analytics, enterprise intelligence, and knowledge science options for over 18 years previous to becoming a member of AWS. He helped prospects in varied trade verticals like healthcare, medical gadgets, life science, retail, asset administration, automobile insurance coverage, residential REIT, agriculture, title insurance coverage, provide chain, doc administration, and actual property.
Raj Ramasubbu is a Senior Analytics Specialist Options Architect targeted on massive knowledge and analytics and AI/ML with Amazon Internet Companies. He helps prospects architect and construct extremely scalable, performant, and safe cloud-based options on AWS. Raj supplied technical experience and management in constructing knowledge engineering, massive knowledge analytics, enterprise intelligence, and knowledge science options for over 18 years previous to becoming a member of AWS. He helped prospects in varied trade verticals like healthcare, medical gadgets, life science, retail, asset administration, automobile insurance coverage, residential REIT, agriculture, title insurance coverage, provide chain, doc administration, and actual property.
 Prabhakar Chandrasekaran is a Senior Technical Account Supervisor with AWS Enterprise Help. Prabhakar enjoys serving to prospects construct cutting-edge AI/ML options on the cloud. He additionally works with enterprise prospects offering proactive steerage and operational help, serving to them enhance the worth of their options when utilizing AWS. Prabhakar holds six AWS and 6 different skilled certifications. With over 20 years {of professional} expertise, Prabhakar was an information engineer and a program chief within the monetary companies area previous to becoming a member of AWS.
Prabhakar Chandrasekaran is a Senior Technical Account Supervisor with AWS Enterprise Help. Prabhakar enjoys serving to prospects construct cutting-edge AI/ML options on the cloud. He additionally works with enterprise prospects offering proactive steerage and operational help, serving to them enhance the worth of their options when utilizing AWS. Prabhakar holds six AWS and 6 different skilled certifications. With over 20 years {of professional} expertise, Prabhakar was an information engineer and a program chief within the monetary companies area previous to becoming a member of AWS.




