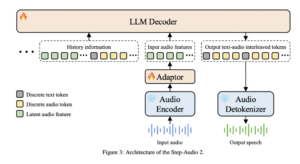
A sparklyr extension for analyzing geospatial information

sparklyr.sedona is now accessible
because the sparklyr-based R interface for Apache Sedona.
To put in sparklyr.sedona from GitHub utilizing
the remotes bundle
, run
remotes::install_github(repo = "apache/incubator-sedona", subdir = "R/sparklyr.sedona")On this weblog publish, we’ll present a fast introduction to sparklyr.sedona, outlining the motivation behind
this sparklyr extension, and presenting some instance sparklyr.sedona use instances involving Spark spatial RDDs,
Spark dataframes, and visualizations.
Motivation for sparklyr.sedona
A suggestion from the
mlverse survey results earlier
this 12 months talked about the necessity for up-to-date R interfaces for Spark-based GIS frameworks.
Whereas trying into this suggestion, we discovered about
Apache Sedona, a geospatial information system powered by Spark
that’s trendy, environment friendly, and straightforward to make use of. We additionally realized that whereas our mates from the
Spark open-source neighborhood had developed a
sparklyr extension for GeoSpark, the
predecessor of Apache Sedona, there was no related extension making more moderen Sedona
functionalities simply accessible from R but.
We subsequently determined to work on sparklyr.sedona, which goals to bridge the hole between
Sedona and R.
The lay of the land
We hope you’re prepared for a fast tour by means of a number of the RDD-based and
Spark-dataframe-based functionalities in sparklyr.sedona, and in addition, some bedazzling
visualizations derived from geospatial information in Spark.
In Apache Sedona,
Spatial Resilient Distributed Datasets(SRDDs)
are fundamental constructing blocks of distributed spatial information encapsulating
“vanilla” RDDs of
geometrical objects and indexes. SRDDs help low-level operations reminiscent of Coordinate Reference System (CRS)
transformations, spatial partitioning, and spatial indexing. For instance, with sparklyr.sedona, SRDD-based operations we will carry out embrace the next:
- Importing some exterior information supply right into a SRDD:
library(sparklyr)
library(sparklyr.sedona)
sedona_git_repo <- normalizePath("~/incubator-sedona")
data_dir <- file.path(sedona_git_repo, "core", "src", "take a look at", "sources")
sc <- spark_connect(grasp = "native")
pt_rdd <- sedona_read_dsv_to_typed_rdd(
sc,
location = file.path(data_dir, "arealm.csv"),
kind = "level"
)- Making use of spatial partitioning to all information factors:
sedona_apply_spatial_partitioner(pt_rdd, partitioner = "kdbtree")- Constructing spatial index on every partition:
sedona_build_index(pt_rdd, kind = "quadtree")- Becoming a member of one spatial information set with one other utilizing “include” or “overlap” because the be part of predicate:
polygon_rdd <- sedona_read_dsv_to_typed_rdd(
sc,
location = file.path(data_dir, "primaryroads-polygon.csv"),
kind = "polygon"
)
pts_per_region_rdd <- sedona_spatial_join_count_by_key(
pt_rdd,
polygon_rdd,
join_type = "include",
partitioner = "kdbtree"
)It’s price mentioning that sedona_spatial_join() will carry out spatial partitioning
and indexing on the inputs utilizing the partitioner and index_type provided that the inputs
usually are not partitioned or listed as specified already.
From the examples above, one can see that SRDDs are nice for spatial operations requiring
fine-grained management, e.g., for making certain a spatial be part of question is executed as effectively
as doable with the appropriate kinds of spatial partitioning and indexing.
Lastly, we will attempt visualizing the be part of consequence above, utilizing a choropleth map:
which provides us the next:

Wait, however one thing appears amiss. To make the visualization above look nicer, we will
overlay it with the contour of every polygonal area:
contours <- sedona_render_scatter_plot(
polygon_rdd,
resolution_x = 1000,
resolution_y = 600,
output_location = tempfile("scatter-plot-"),
boundary = c(-126.790180, -64.630926, 24.863836, 50.000),
base_color = c(255, 0, 0),
browse = FALSE
)
sedona_render_choropleth_map(
pts_per_region_rdd,
resolution_x = 1000,
resolution_y = 600,
output_location = tempfile("choropleth-map-"),
boundary = c(-126.790180, -64.630926, 24.863836, 50.000),
base_color = c(63, 127, 255),
overlay = contours
)which provides us the next:

With some low-level spatial operations taken care of utilizing the SRDD API and
the appropriate spatial partitioning and indexing information constructions, we will then
import the outcomes from SRDDs to Spark dataframes. When working with spatial
objects inside Spark dataframes, we will write high-level, declarative queries
on these objects utilizing dplyr verbs at the side of Sedona
spatial UDFs, e.g.
, the
following question tells us whether or not every of the 8 nearest polygons to the
question level incorporates that time, and in addition, the convex hull of every polygon.
tbl <- DBI::dbGetQuery(
sc, "SELECT ST_GeomFromText("POINT(-66.3 18)") AS `pt`"
)
pt <- tbl$pt[[1]]
knn_rdd <- sedona_knn_query(
polygon_rdd, x = pt, ok = 8, index_type = "rtree"
)
knn_sdf <- knn_rdd %>%
sdf_register() %>%
dplyr::mutate(
contains_pt = ST_contains(geometry, ST_Point(-66.3, 18)),
convex_hull = ST_ConvexHull(geometry)
)
knn_sdf %>% print()# Supply: spark<?> [?? x 3]
geometry contains_pt convex_hull
<record> <lgl> <record>
1 <POLYGON ((-66.335674 17.986328… TRUE <POLYGON ((-66.335674 17.986328,…
2 <POLYGON ((-66.335432 17.986626… TRUE <POLYGON ((-66.335432 17.986626,…
3 <POLYGON ((-66.335432 17.986626… TRUE <POLYGON ((-66.335432 17.986626,…
4 <POLYGON ((-66.335674 17.986328… TRUE <POLYGON ((-66.335674 17.986328,…
5 <POLYGON ((-66.242489 17.988637… FALSE <POLYGON ((-66.242489 17.988637,…
6 <POLYGON ((-66.242489 17.988637… FALSE <POLYGON ((-66.242489 17.988637,…
7 <POLYGON ((-66.24221 17.988799,… FALSE <POLYGON ((-66.24221 17.988799, …
8 <POLYGON ((-66.24221 17.988799,… FALSE <POLYGON ((-66.24221 17.988799, …Acknowledgements
The writer of this weblog publish wish to thank Jia Yu,
the creator of Apache Sedona, and Lorenz Walthert for
their suggestion to contribute sparklyr.sedona to the upstream
incubator-sedona repository. Jia has supplied
in depth code-review suggestions to make sure sparklyr.sedona complies with coding requirements
and greatest practices of the Apache Sedona challenge, and has additionally been very useful within the
instrumentation of CI workflows verifying sparklyr.sedona works as anticipated with snapshot
variations of Sedona libraries from growth branches.
The writer can be grateful for his colleague Sigrid Keydana
for helpful editorial strategies on this weblog publish.
That’s all. Thanks for studying!