From Practice-Check to Cross-Validation: Advancing Your Mannequin’s Analysis

Many learners will initially depend on the train-test technique to guage their fashions. This technique is simple and appears to present a transparent indication of how properly a mannequin performs on unseen knowledge. Nonetheless, this method can typically result in an incomplete understanding of a mannequin’s capabilities. On this weblog, we’ll focus on why it’s necessary to transcend the essential train-test cut up and the way cross-validation can provide a extra thorough analysis of mannequin efficiency. Be a part of us as we information you thru the important steps to attain a deeper and extra correct evaluation of your machine studying fashions.
Let’s get began.

From Practice-Check to Cross-Validation: Advancing Your Mannequin’s Analysis
Photograph by Belinda Fewings. Some rights reserved.
Overview
This submit is split into three elements; they’re:
- Mannequin Analysis: Practice-Check vs. Cross-Validation
- The “Why” of Cross-Validation
- Delving Deeper with Okay-Fold Cross-Validation
Mannequin Analysis: Practice-Check vs. Cross-Validation
A machine studying mannequin is decided by its design (akin to a linear vs. non-linear mannequin) and its parameters (such because the coefficients in a linear regression mannequin). It’s essential be certain the mannequin is appropriate for the information earlier than contemplating find out how to match the mannequin.
The efficiency of a machine studying mannequin is gauged by how properly it performs on beforehand unseen (or take a look at) knowledge. In an ordinary train-test cut up, we divide the dataset into two elements: a bigger portion for coaching our mannequin and a smaller portion for testing its efficiency. The mannequin is appropriate if the examined efficiency is suitable. This method is simple however doesn’t all the time make the most of our knowledge most successfully.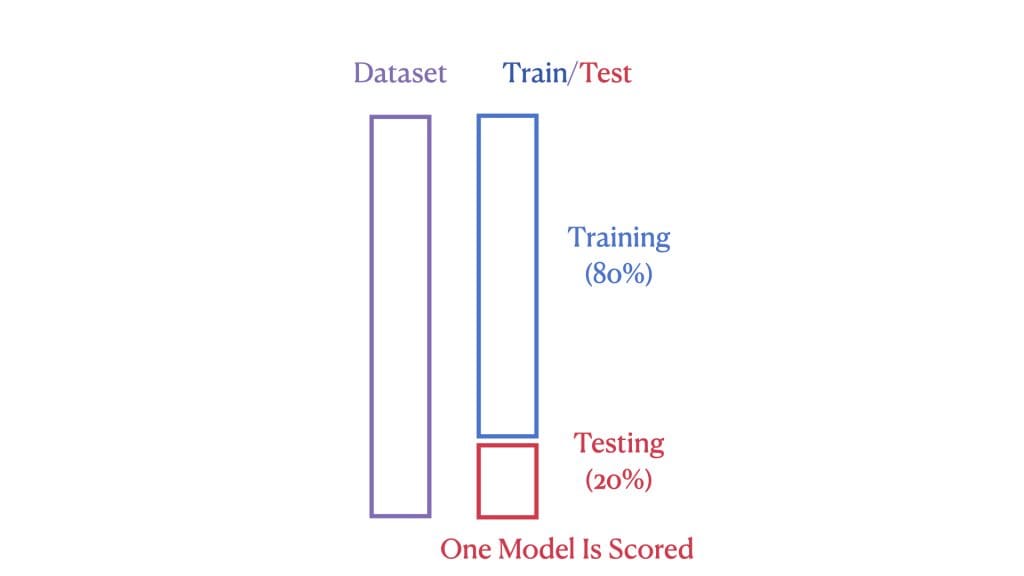
Nonetheless, with cross-validation, we go a step additional. The second picture exhibits a 5-Fold Cross-Validation, the place the dataset is cut up into 5 “folds.” In every spherical of validation, a unique fold is used because the take a look at set whereas the remaining kind the coaching set. This course of is repeated 5 instances, guaranteeing every knowledge level is used for coaching and testing.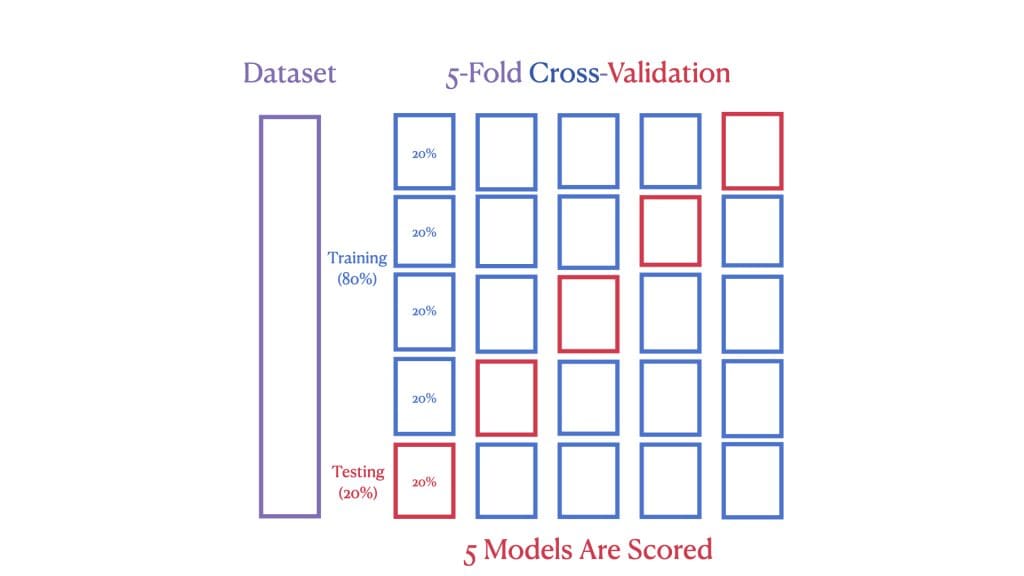
Right here is an instance as an instance the above:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# Load the Ames dataset import pandas as pd Ames = pd.read_csv(‘Ames.csv’)
# Import Linear Regression, Practice-Check, Cross-Validation from scikit-learn from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split, cross_val_rating
# Choose options and goal X = Ames[[‘GrLivArea’]] # Function: GrLivArea, a 2D matrix y = Ames[‘SalePrice’] # Goal: SalePrice, a 1D vector
# Cut up knowledge into coaching and testing units X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Linear Regression mannequin utilizing Practice-Check mannequin = LinearRegression() mannequin.match(X_train, y_train) train_test_score = spherical(mannequin.rating(X_test, y_test), 4) print(f“Practice-Check R^2 Rating: {train_test_score}”)
# Carry out 5-Fold Cross-Validation cv_scores = cross_val_score(mannequin, X, y, cv=5) cv_scores_rounded = [round(score, 4) for score in cv_scores] print(f“Cross-Validation R^2 Scores: {cv_scores_rounded}”) |
Whereas the train-test technique yields a single R² rating, cross-validation gives us with a spectrum of 5 totally different R² scores, one from every fold of the information, providing a extra complete view of the mannequin’s efficiency:
|
Practice-Check R^2 Rating: 0.4789 Cross-Validation R^2 Scores: [0.4884, 0.5412, 0.5214, 0.5454, 0.4673] |
The roughly equal R² scores among the many 5 means the mannequin is steady. You’ll be able to then resolve whether or not this mannequin (i.e., linear regression) gives an appropriate prediction energy.
The “Why” of Cross-Validation
Understanding the variability of our mannequin’s efficiency throughout totally different subsets of knowledge is essential in machine studying. The train-test cut up technique, whereas helpful, solely offers us a snapshot of how our mannequin may carry out on one specific set of unseen knowledge.
Cross-validation, by systematically utilizing a number of folds of knowledge for each coaching and testing, affords a extra sturdy and complete analysis of the mannequin’s efficiency. Every fold acts as an impartial take a look at, offering insights into how the mannequin is anticipated to carry out throughout diversified knowledge samples. This multiplicity not solely helps establish potential overfitting but additionally ensures that the efficiency metric (on this case, R² rating) is just not overly optimistic or pessimistic, however relatively a extra dependable indicator of how the mannequin will generalize to unseen knowledge.
To visually reveal this, let’s contemplate the R² scores from each a train-test cut up and a 5-fold cross-validation course of:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# Import Seaborn and Matplotlib import seaborn as sns import matplotlib.pyplot as plt
# Assuming cv_scores_rounded incorporates your cross-validation scores # And train_test_score is your single train-test R^2 rating
# Plot the field plot for cross-validation scores cv_scores_df = pd.DataFrame(cv_scores_rounded, columns=[‘Cross-Validation Scores’]) sns.boxplot(knowledge=cv_scores_df, y=‘Cross-Validation Scores’, width=0.3, shade=‘lightblue’, fliersize=0)
# Overlay particular person scores as factors plt.scatter([0] * len(cv_scores_rounded), cv_scores_rounded, shade=‘blue’, label=‘Cross-Validation Scores’) plt.scatter(0, train_test_score, shade=‘crimson’, zorder=5, label=‘Practice-Check Rating’)
# Plot the visible plt.title(‘Mannequin Analysis: Cross-Validation vs. Practice-Check’) plt.ylabel(‘R^2 Rating’) plt.xticks([0], [‘Evaluation Scores’]) plt.legend(loc=‘decrease left’, bbox_to_anchor=(0, +0.1)) plt.present() |
This visualization underscores the distinction in insights gained from a single train-test analysis versus the broader perspective supplied by cross-validation:

Via cross-validation, we acquire a deeper understanding of our mannequin’s efficiency, shifting us nearer to creating machine studying options which can be each efficient and dependable.
Delving Deeper with Okay-Fold Cross-Validation
Cross-validation is a cornerstone of dependable machine studying mannequin analysis, with cross_val_score() offering a fast and automatic option to carry out this activity. Now, we flip our consideration to the KFold class, a element of scikit-learn that provides a deeper dive into the folds of cross-validation. The KFold class gives not only a rating however a window into the mannequin’s efficiency throughout totally different segments of our knowledge. We reveal this by replicating the instance above:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# Import Okay-Fold and essential libraries from sklearn.model_selection import KFold from sklearn.linear_model import LinearRegression from sklearn.metrics import r2_rating
# Choose options and goal X = Ames[[‘GrLivArea’]].values # Convert to numpy array for KFold y = Ames[‘SalePrice’].values # Convert to numpy array for KFold
# Initialize Linear Regression and Okay-Fold mannequin = LinearRegression() kf = KFold(n_splits=5)
# Manually carry out Okay-Fold Cross-Validation for fold, (train_index, test_index) in enumerate(kf.cut up(X), begin=1): # Cut up the information into coaching and testing units X_train, X_test = X[train_index], X[test_index] y_train, y_test = y[train_index], y[test_index]
# Match the mannequin and predict mannequin.match(X_train, y_train) y_pred = mannequin.predict(X_test)
# Calculate and print the R^2 rating for the present fold print(f“Fold {fold}:”) print(f“TRAIN set dimension: {len(train_index)}”) print(f“TEST set dimension: {len(test_index)}”) print(f“R^2 rating: {spherical(r2_score(y_test, y_pred), 4)}n”) |
This code block will present us the dimensions of every coaching and testing set and the corresponding R² rating for every fold:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
Fold 1: TRAIN set dimension: 2063 TEST set dimension: 516 R^2 rating: 0.4884
Fold 2: TRAIN set dimension: 2063 TEST set dimension: 516 R^2 rating: 0.5412
Fold 3: TRAIN set dimension: 2063 TEST set dimension: 516 R^2 rating: 0.5214
Fold 4: TRAIN set dimension: 2063 TEST set dimension: 516 R^2 rating: 0.5454
Fold 5: TRAIN set dimension: 2064 TEST set dimension: 515 R^2 rating: 0.4673 |
The KFold class shines in its transparency and management over the cross-validation course of. Whereas cross_val_score() simplifies the method into one line, KFold opens it up, permitting us to view the precise splits of our knowledge. That is extremely invaluable when that you must:
- Perceive how your knowledge is being divided.
- Implement customized preprocessing earlier than every fold.
- Acquire insights into the consistency of your mannequin’s efficiency.
Through the use of the KFold class, you may manually iterate over every cut up and apply the mannequin coaching and testing course of. This not solely helps in guaranteeing that you simply’re totally knowledgeable concerning the knowledge getting used at every stage but additionally affords the chance to switch the method to go well with complicated wants.
Additional Studying
APIs
Tutorials
Ames Housing Dataset & Knowledge Dictionary
Abstract
On this submit, we explored the significance of thorough mannequin analysis by way of cross-validation and the KFold technique. Each methods meticulously keep away from the pitfall of knowledge leakage by conserving coaching and testing knowledge distinct, thereby guaranteeing the mannequin’s efficiency is precisely measured. Furthermore, by validating every knowledge level precisely as soon as and utilizing it for coaching Okay-1 instances, these strategies present an in depth view of the mannequin’s potential to generalize, boosting confidence in its real-world applicability. Via sensible examples, we’ve demonstrated how integrating these methods into your analysis course of results in extra dependable and sturdy machine studying fashions, prepared for the challenges of latest and unseen knowledge.
Particularly, you discovered:
- The effectivity of
cross_val_score()in automating the cross-validation course of. - How
KFoldaffords detailed management over knowledge splits for tailor-made mannequin analysis. - How each strategies guarantee full knowledge utilization and stop knowledge leakage.
Do you could have any questions? Please ask your questions within the feedback beneath, and I’ll do my greatest to reply.
Get Began on The Newbie’s Information to Knowledge Science!

Be taught the mindset to grow to be profitable in knowledge science initiatives
…utilizing solely minimal math and statistics, purchase your ability by way of brief examples in Python
Uncover how in my new Book:
The Beginner’s Guide to Data Science
It gives self-study tutorials with all working code in Python to show you from a novice to an knowledgeable. It exhibits you find out how to discover outliers, verify the normality of knowledge, discover correlated options, deal with skewness, examine hypotheses, and rather more…all to help you in making a narrative from a dataset.
Kick-start your knowledge science journey with hands-on workout routines
About Vinod Chugani
Born in India and nurtured in Japan, I’m a Third Tradition Child with a worldwide perspective. My educational journey at Duke College included majoring in Economics, with the distinction of being inducted into Phi Beta Kappa in my junior yr. Over time, I’ve gained numerous skilled experiences, spending a decade navigating Wall Road’s intricate Mounted Earnings sector, adopted by main a worldwide distribution enterprise on Predominant Road.
At present, I channel my ardour for knowledge science, machine studying, and AI as a Mentor on the New York Metropolis Knowledge Science Academy. I worth the chance to ignite curiosity and share data, whether or not by way of Stay Studying classes or in-depth 1-on-1 interactions.
With a basis in finance/entrepreneurship and my present immersion within the knowledge realm, I method the long run with a way of function and assurance. I anticipate additional exploration, steady studying, and the chance to contribute meaningfully to the ever-evolving fields of knowledge science and machine studying, particularly right here at MLM.