Improve your media search expertise utilizing Amazon Q Enterprise and Amazon Transcribe
In right this moment’s digital panorama, the demand for audio and video content material is skyrocketing. Organizations are more and more utilizing media to have interaction with their audiences in progressive methods. From product documentation in video format to podcasts changing conventional weblog posts, content material creators are exploring numerous channels to succeed in a wider viewers. The rise of digital workplaces has additionally led to a surge in content material captured via recorded conferences, calls, and voicemails. Moreover, contact facilities generate a wealth of media content material, together with assist calls, screen-share recordings, and post-call surveys.
We’re excited to introduce Mediasearch Q Enterprise, an open supply answer powered by Amazon Q Business and Amazon Transcribe. Mediasearch Q Enterprise builds on the Mediasearch solution powered by Amazon Kendra and enhances the search expertise utilizing Amazon Q Enterprise. Mediasearch Q Enterprise supercharges the best way you devour media information by utilizing them as a part of the information base utilized by Amazon Q Enterprise to generate dependable solutions to person questions. The answer additionally options an enhanced Amazon Q Enterprise question utility that permits customers to play the related part of the unique media information or YouTube movies instantly from the search outcomes web page, offering a seamless and intuitive person expertise.
Resolution overview
Mediasearch Q Enterprise is easy to put in and check out.
The answer has two elements, as illustrated within the following diagram:
- A Mediasearch indexer that transcribes media information (audio and video) on an Amazon Simple Storage Service (Amazon S3) bucket or media from a YouTube playlist and ingests the transcriptions into both an Amazon Q Enterprise native index (configured as a part of the Amazon Q Enterprise utility) or an Amazon Kendra
- A Mediasearch finder, which supplies a UI and makes API calls to the Amazon Q Enterprise service APIs on behalf of the logged-in person. The response from API calls are exhibited to the end-user.

The Mediasearch indexer finds and transcribes audio and video information saved in an S3 bucket. The indexer can even index YouTube movies from a YouTube playlist as audio information and transcribe these audio information. It prepares the transcriptions by embedding time markers firstly of every sentence, and it indexes every ready transcription in an Amazon Q Business native retriever or an Amazon Kendra retriever. The indexer runs the primary time if you set up it, and subsequently runs on an interval that you simply specify, sustaining the index to mirror any new, modified, or deleted information.
The Mediasearch finder is an online search consumer that you simply use to seek for content material in your Amazon Q Enterprise utility. Moreover, the Mediasearch finder consists of in-line embedded media gamers within the search consequence, so you’ll be able to see the related part of the transcript, and play the corresponding part from the unique media (audio information and video information in your media bucket or a YouTube video) with out navigating away from the search web page.

Within the sections that comply with, we talk about the next subjects:
- The best way to deploy the answer to your AWS account
- The best way to use it to index and search pattern media information
- The best way to use the answer with your personal media information
- How the answer works
- The estimated prices concerned
- The best way to monitor utilization and troubleshoot issues
- Choices to customise and tune the answer
- The best way to uninstall and clear up if you’re achieved experimenting
Conditions
Be sure to have the next:
Deploy the Mediasearch Q Enterprise answer
On this part, we stroll via deploying the 2 answer elements: the indexer and the finder. We use a CloudFormation stack to deploy the required sources within the us-east-1 AWS Area.
Should you’re deploying the answer to a different Area, comply with the directions within the README obtainable within the Mediasearch Q Enterprise GitHub repository.
Deploy the Mediasearch Q Enterprise indexer part
To deploy the indexer part, full the next steps:
- Select Launch Stack.

- Within the Identification heart ARN and Retriever choice part, for IdentityCenterInstanceArn, enter the ARN to your IAM Identification Middle occasion.
You’ll find the ARN on the Settings web page of the IAM Identification Middle console. The ARN is a required subject.

- Use default values for all different parameters. We are going to customise these values later to fit your particular necessities.
- Acknowledge that the stack would possibly create IAM sources with customized names, then select Create stack.
The indexer stack takes round 10 minutes to deploy. Watch for the indexer to complete deploying earlier than you deploy the Mediasearch Q Enterprise finder.
Deploy the Mediasearch Q Enterprise finder part
The Mediasearch finder makes use of Amazon Cognito to authenticate customers to the answer. For an authenticated person to work together with an Amazon Q Enterprise utility, you need to configure an IAM Identification Middle customer managed application that both helps SAML 2.0 or OAuth 2.0.
On this publish, we create a buyer managed utility that helps OAuth 2.0, a safe manner for functions to speak and share person knowledge with out exposing passwords. We use a method referred to as trusted identification propagation, which permits the Mediasearch Q Enterprise finder app to entry the Amazon Q service securely with out sharing passwords between the 2 identification suppliers (Amazon Cognito and IAM Identification Middle in our instance).
As an alternative of sharing passwords, trusted identification propagation makes use of tokens. Tokens are like digital certificates that show who the person is and what they’re allowed to do. AWS managed functions that work with trusted identification propagation get tokens instantly from IAM Identification Middle. IAM Identification Middle can even alternate identification tokens and entry tokens from exterior authorization servers like Amazon Cognito. This lets an utility authenticate customers and acquire tokens exterior of AWS (like with Amazon Cognito, Microsoft Entra ID, or Okta), alternate that token for an IAM Identification Middle token, after which use the brand new token to request entry to AWS companies like Amazon Q Enterprise.
For extra data, see Using trusted identity propagation with customer managed applications.
When the IAM Identification Middle occasion is in the identical account the place you might be deploying the Mediasearch Q Enterprise answer, the finder stack permits you to routinely create the IAM Identification Middle buyer managed utility as a part of the stack deployment.
Should you use the group occasion of IAM Identification Middle enabled in your administration account, then you’ll be deploying the Mediasearch Q Enterprise finder stack in a special AWS account. On this case, comply with the steps within the README to create an IAM Identification Middle utility manually.
To deploy the finder part and create the IAM Identification Middle buyer managed utility, full the next steps:
- Select Launch Stack.
- For IdentityCenterInstanceArn, enter the ARN for the IAM Identification Middle occasion. This is similar worth you used whereas deploying the indexer stack.
- For CreateIdentityCenterApplication, select Sure to create the IAM Identification Middle utility for the Mediasearch finder utility.
- Beneath Mediasearch Indexer parameters, enter the Amazon Q Enterprise utility ID that was created by the indexer stack. You possibly can copy this from the
QBusinessApplicationIdoutput of the indexer stack. - Choose the retriever kind that was used to deploy the Mediasearch indexer. (Should you deployed an Amazon Kendra index, then choose Kendra, in any other case choose Native.
- Should you chosen Kendra, enter the Amazon Kendra index ID that was utilized by the indexer stack.
- For MediaBucketNames, use the
MediaBucketsUsedoutput from the indexer CloudFormation stack to permit the search web page to entry media information throughoutYTMediaBucketand Mediabucket. - Acknowledge that the stack would possibly create IAM sources with customized names, then select Create stack.
Configure person entry to Amazon Q Enterprise
To entry the Mediasearch Q Enterprise answer, add a person with an acceptable subscription to the Amazon Q Enterprise utility and to the IAM Identification Middle buyer managed utility.
Add a person to the Amazon Q Enterprise utility
To start out utilizing the Amazon Q Enterprise utility, you’ll be able to add customers or teams to the Amazon Q Enterprise utility out of your IAM Identification Middle occasion. Full the next steps so as to add a person to the appliance:
- Entry the Amazon Q Enterprise utility by selecting the hyperlink for
QBusinessApplicationwithin the indexer CloudFormation stack outputs.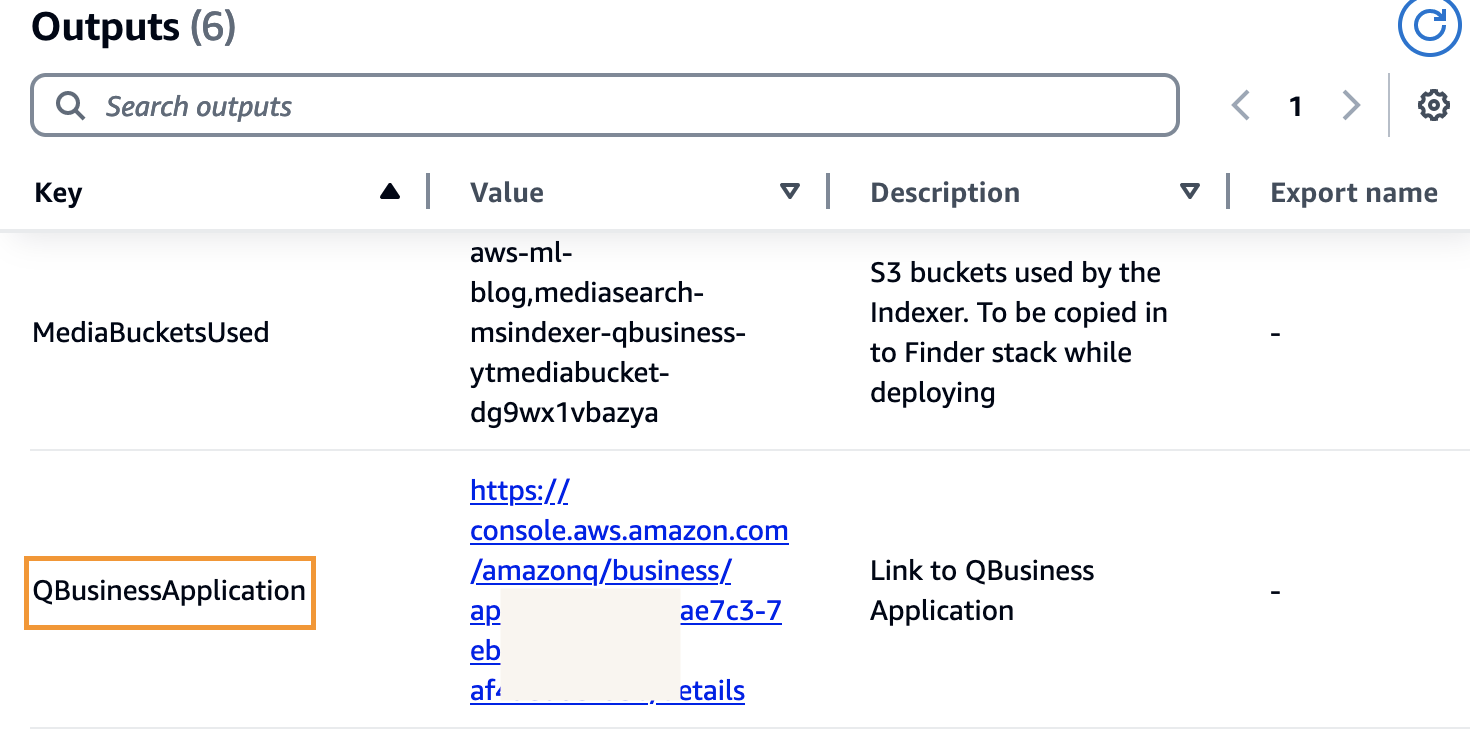
- Beneath Teams and customers, on the Customers tab, select Handle entry and subscription.
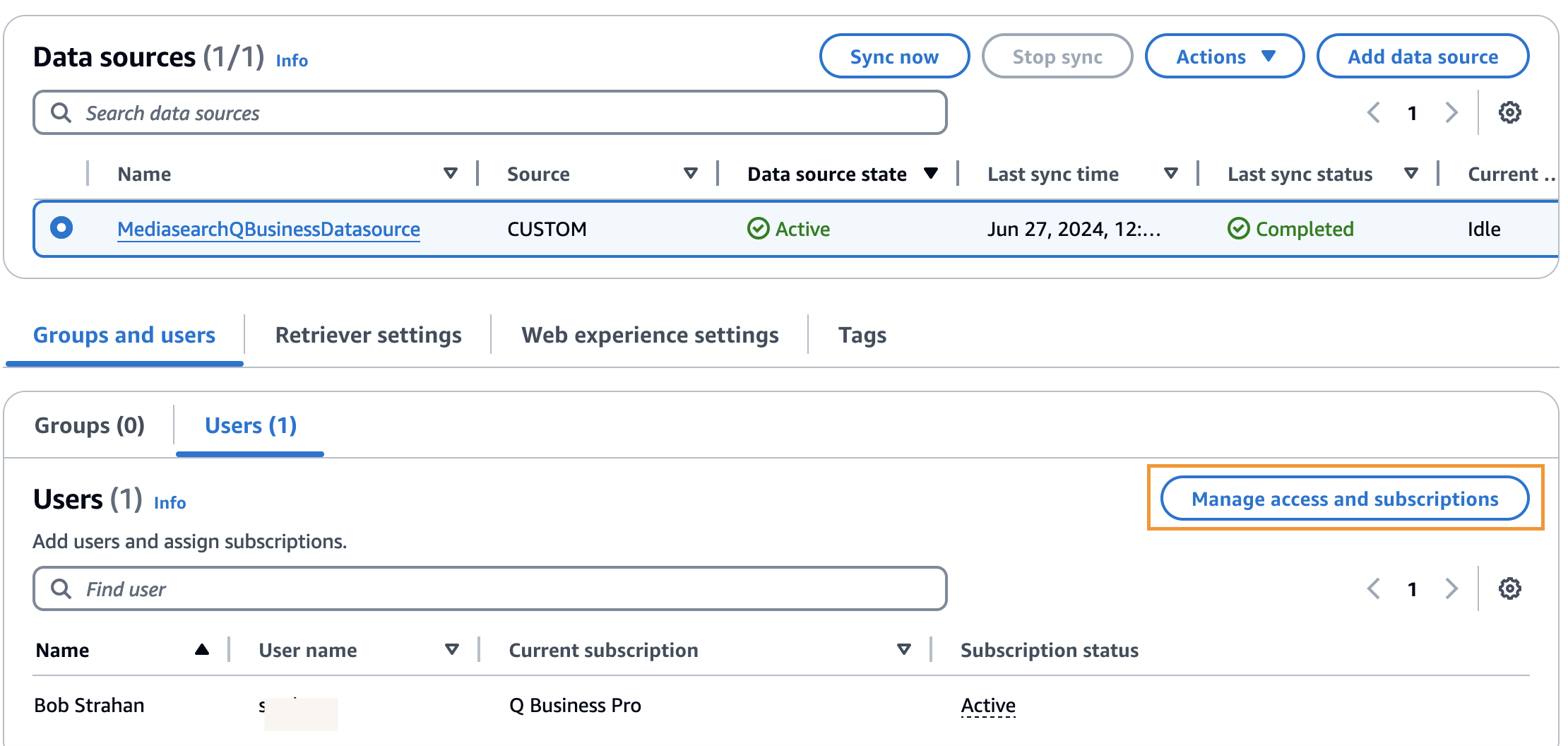
- Select Add teams and customers.
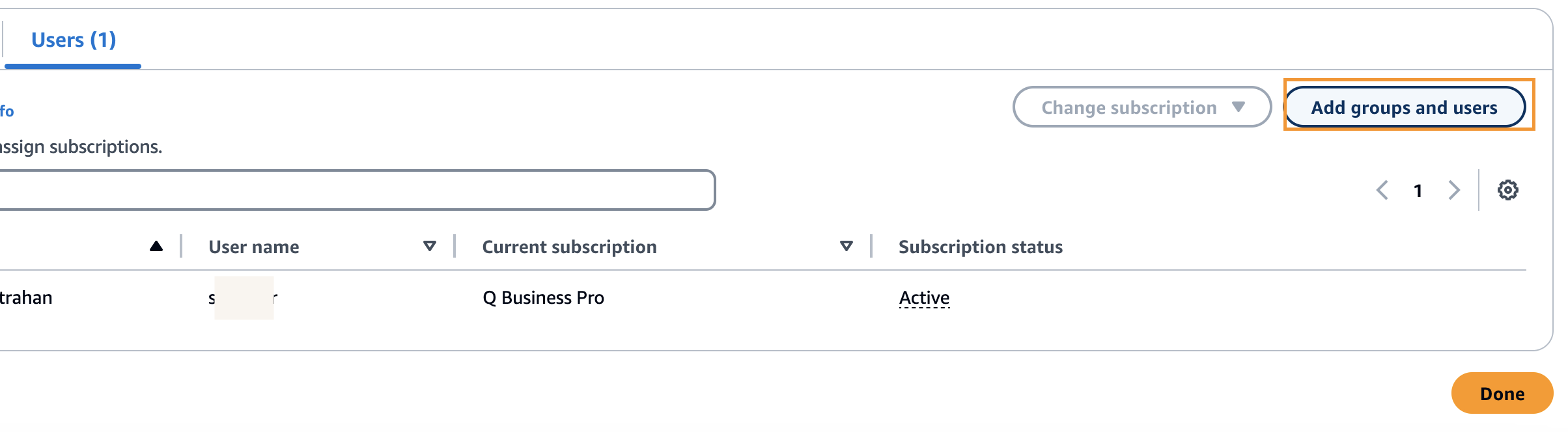
- Select Add current customers and teams.
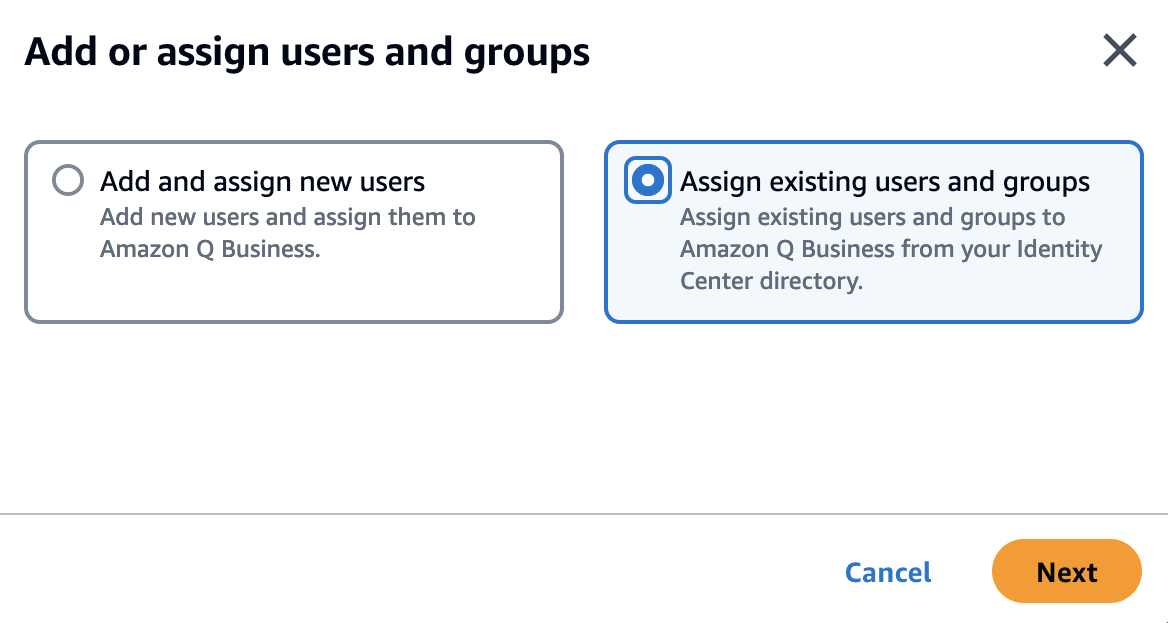
- Seek for an current person, select the person, and select Assign.
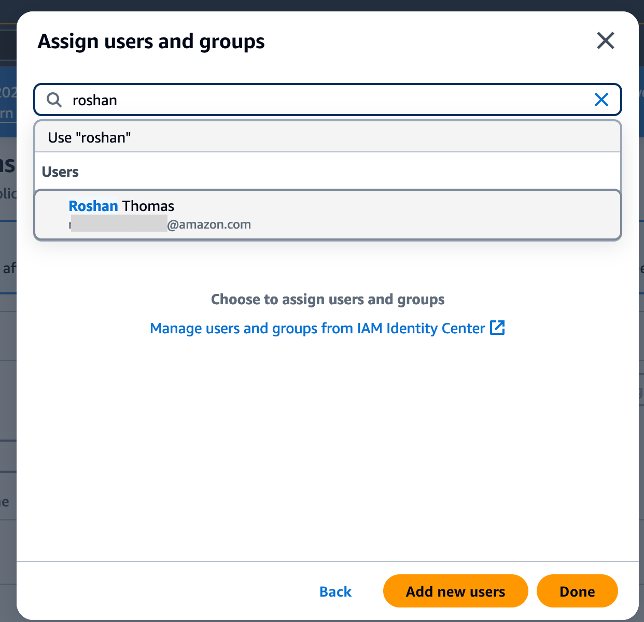
- Choose the added person and on the Change subscription menu, select Replace subscription tier.
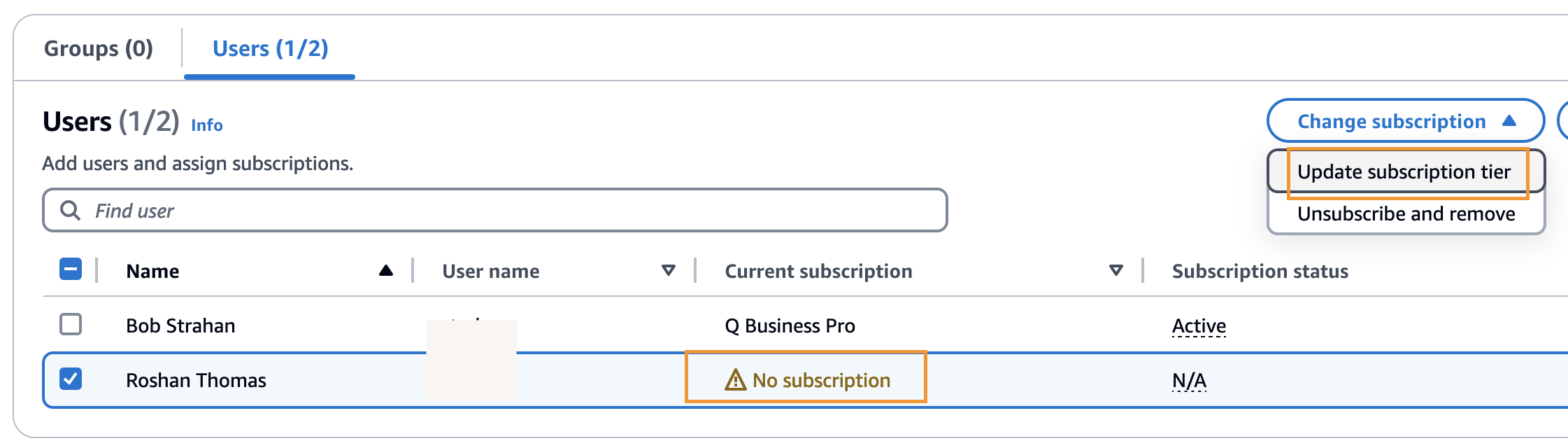
- Choose the suitable subscription tier and select Verify.
For particulars of every Amazon Q subscription, consult with Amazon Q Business pricing.
Assign customers to the IAM Identification Middle buyer managed utility
Now you’ll be able to assign customers or teams to the IAM Identification Middle buyer managed utility. Full the next steps so as to add a person:
- From the outputs part of the finder CloudFormation stack, select the URL for
IdentityCenterApplicationConsoleURLtonavigate to the client managed utility.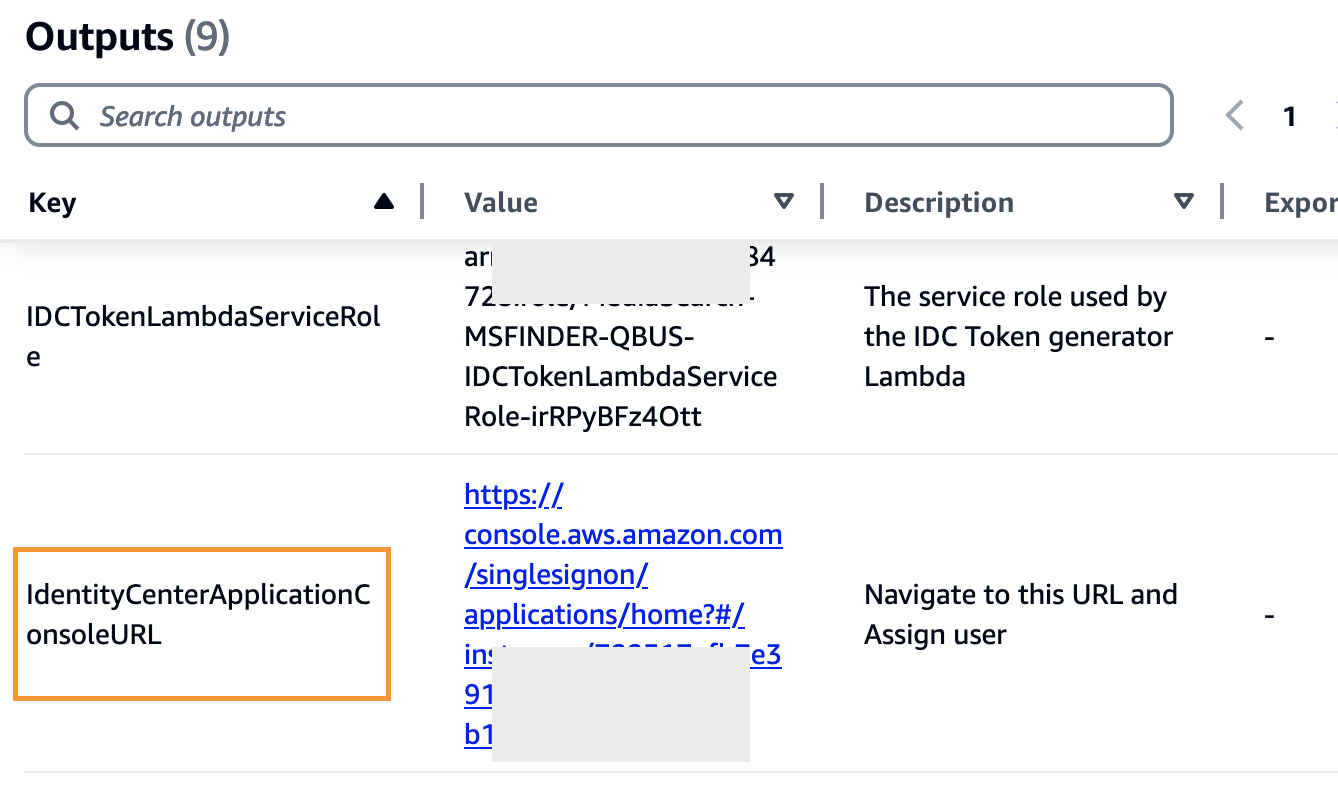
- Select Assign customers and teams.
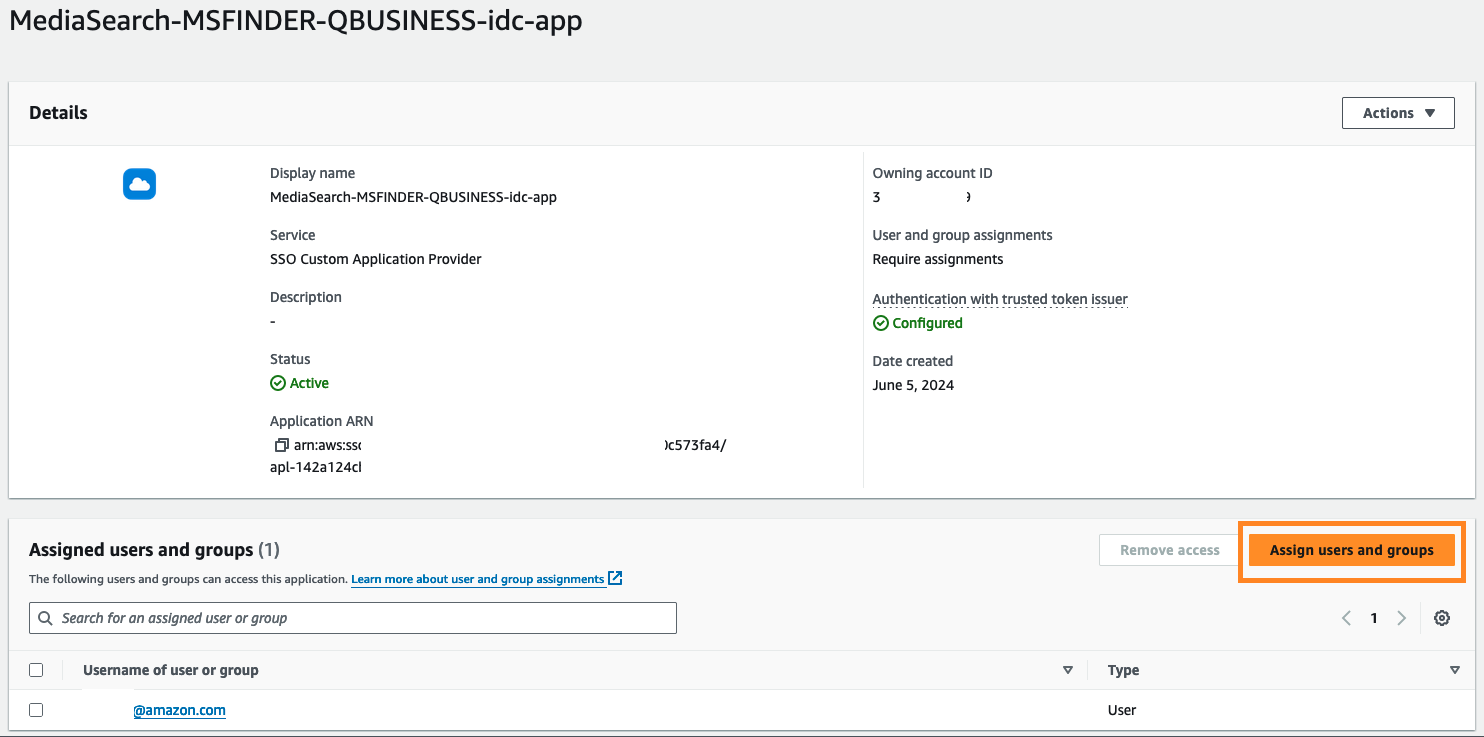
- Choose customers and select Assign customers.
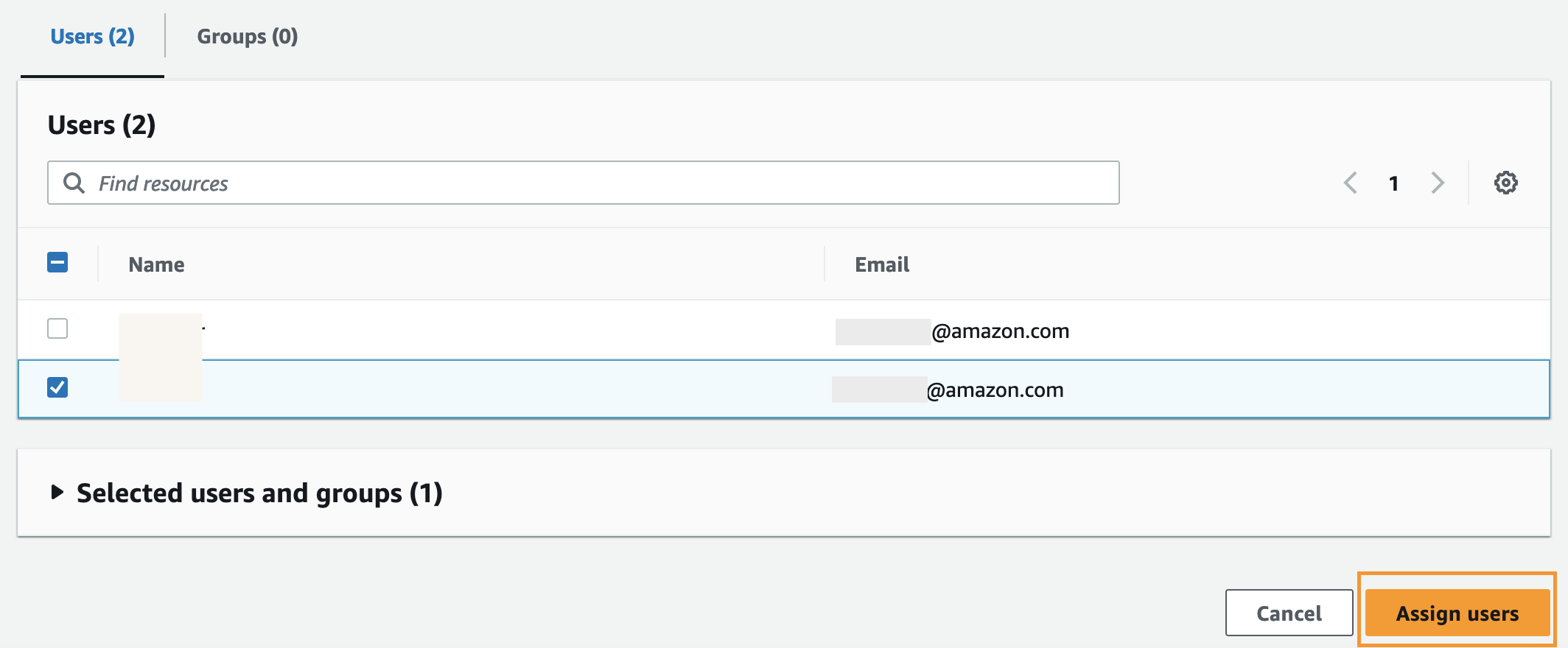
This concludes the person entry configuration to the Mediasearch Q Enterprise answer.
Take a look at with the pattern media information
When the Mediasearch indexer and finder stack are deployed, the indexer ought to have accomplished processing the audio (mp3) information for the YouTube movies and pattern media information (chosen AWS Podcast episodes and AWS Knowledge Center videos). Now you can run your first Mediasearch question.
- To log in to the Mediasearch finder utility, select the URL for
MediasearchFinderURLwithin the stack outputs.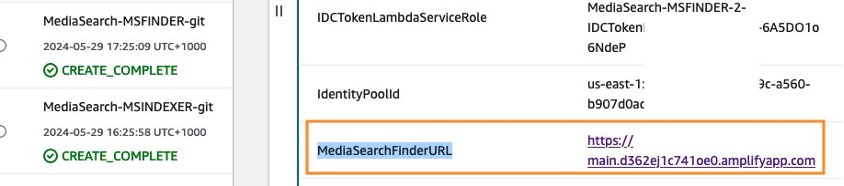
The Mediasearch finder utility in your browser will present a splash web page for Amazon Q Enterprise.
- Select Get Began to entry the Amazon Cognito web page.

To entry Mediasearch Q Enterprise, you want to log in to the appliance utilizing a person ID within the Amazon Cognito user pool created by the finder stack. The e-mail handle in Amazon Cognito should match the e-mail handle for the person in IAM Identification Middle. Alternatively, the Mediasearch answer permits you to create a person via the appliance.
- On the Create Account tab, enter your e mail (which matches the e-mail handle in IAM Identification Middle), adopted by a password and password affirmation, and select Create Account.
Amazon Cognito will ship an e mail with a affirmation code for e mail verification.
- Enter this affirmation code to finish your e mail verification.
- After e mail verification, you’ll now have the ability to log in to the Mediasearch Q Enterprise utility.
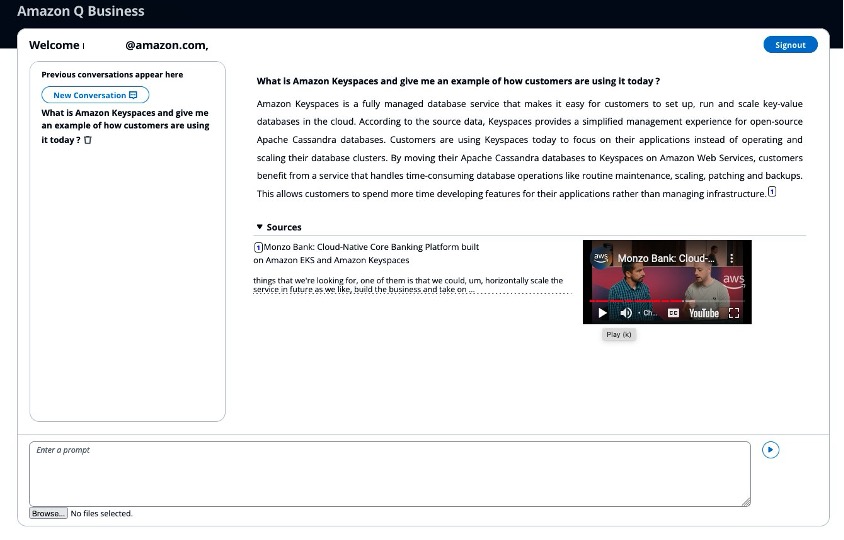
- After you’re logged in, within the Enter a immediate field, write a question, equivalent to “What’s AWS Fargate?”
The question returns a response from Amazon Q Enterprise based mostly on the media (pattern media information and YouTube audio sources) ingested into the index.

The response consists of citations, close to sources. Customers can confirm their reply from Amazon Q Enterprise by taking part in media information from their S3 buckets or YouTube beginning on the time marker the place the related data is discovered.
- Use the embedded video participant to play the unique video inline. Observe that the media playback begins on the related part of the video based mostly on the time marker.
- To play the video full display screen in a brand new browser tab, use the Full display screen menu choice within the participant, or select the media file hyperlink proven above the reply textual content.
- Select (right-click) the video file hyperlink, copy the URL, and enter it right into a textual content editor.
If the media is an audio file for a YouTube video, it seems one thing like the next:
https://www.youtube.com/watch?v=unFVfqj9cQ8&t=36.58s
If the media file is a non-YouTube audio file that resides in MediaBucket, the URL seems like the next:
https://mediasearchtest.s3.amazonaws.com/mediasamples/What_is_an_Interface_VPC_Endpoint_and_how_can_I_create_Interface_Endpoint_for_my_VPC_.mp4?AWSAccessKeyId=ASIAXMBGHMGZLSYWJHGD&Expires=1625526197&Signature=BYeOXOzT585ntoXLDoftkfS4dBUpercent3D&x-amz-security-token=.... #t=253.52
This can be a presigned S3 URL that gives your browser with momentary learn entry to the media file referenced within the search consequence. Utilizing presigned URLs means you don’t want to supply everlasting public entry to your whole listed media information.
- Experiment with extra queries, equivalent to “How has AWS helped prospects in constructing MLOps platform?” or “How can I exploit Generative AI to enhance buyer expertise?” or strive your personal questions.
Index and search your personal media information
To index media information saved in your personal S3 bucket, exchange the MediaBucket and MediaFolderPrefix parameters with your personal bucket title and prefix if you set up or replace the indexer part stack, and modify the MediaBucketName parameter with your personal bucket title if you set up or replace the finder part stack. Moreover, you’ll be able to exchange the YouTube playlist (PlayListURL) with your personal playlist URL and replace the indexer stack.
- When creating a brand new MediaSearch indexer stack, you’ll be able to select to make use of both a local retriever or an Amazon Kendra retriever. You can also make this choice utilizing the parameter
RetrieverType. When utilizing the Amazon Kendra retriever, you’ll be able to both let indexer stack create an Amazon Kendra index or use an current Amazon KendraIndexIdso as to add information saved within the new location. To deploy a brand new indexer, comply with the steps from earlier on this publish, however exchange the defaults to specify the media bucket title and prefix to your personal media information or exchange the YouTube playlist URL with your personal playlist URL. Just remember to adjust to the YouTube Terms of Service. - Alternatively, replace an current MediaSearch indexer stack to exchange the beforehand listed information with information from the brand new location or replace the YouTube playlist URL or the variety of movies to obtain from the playlist:
- Choose the stack on the AWS CloudFormation console, select Replace, then Use present template, then Subsequent.
- Modify the media bucket title and prefix parameter values as wanted.
- Modify the YouTube Playlist URL and Variety of YouTube Movies values as wanted.
- Select Subsequent twice, choose the acknowledgement examine field, and select Replace stack.
- Replace an current MediaSearch finder stack to alter bucket names or add extra bucket names to the
MediaBucketNames
When the MediaSearch indexer stack is efficiently created or up to date, the indexer routinely finds, transcribes, and indexes the media information saved in your S3 bucket. When it’s full, you’ll be able to submit queries and discover solutions from the audio tracks of your personal audio and video information.
You’ve got the choice to supply metadata for any or your whole media information. Use metadata to assign values to index attributes for sorting, filtering, and faceting your search outcomes, or to specify entry management lists to control entry to the information. Metadata information might be in the identical S3 folder as your media information (default), or in a parallel folder construction specified by the non-compulsory indexer parameter MetadataFolderPrefix. For extra details about tips on how to create metadata information, see Amazon S3 document metadata.
You may as well present personalized transcription choices for any or your whole media information. This lets you take full benefit of Amazon Transcribe options equivalent to custom vocabularies, automatic content redaction, and custom language models.
How the Mediasearch answer works
Let’s take a fast take a look at how the answer works, as illustrated within the following diagram.

The Mediasearch answer has an event-driven serverless computing structure with the next steps:
- You present an S3 bucket containing the audio and video information you wish to index and search. That is often known as the
MediaBucket. Go away this clean in the event you don’t wish to index media out of yourMediaBucket. - You additionally present your YouTube playlist URL and the variety of movies to index from the YouTube playlist. Just remember to adjust to the YouTube Terms of Service. The
YTIndexerwill index the most recent information from the YouTube playlist. For instance, if the variety of movies is about to five, then theYTIndexerwill index the 5 newest movies within the playlist. Any YouTube video listed prior is ignored from being listed. - An AWS Lambda operate fetches the YouTube movies from the playlist as audio (mp3 information) into the
YTMediaBucketand in addition creates a metadata file within theMetadataFolderPrefixlocation with metadata for the YouTube video. The YouTubevideoidtogether with the associated metadata are recorded in an Amazon DynamoDB desk (YTMediaDDBQueueTable). - Amazon EventBridge generates occasions on a repeating interval (each 2 hours, each 6 hours, and so forth) These occasions invoke the Lambda operate S3CrawlLambdaFunction.
- An AWS Lambda operate is invoked initially when the CloudFormation stack is first deployed, after which subsequently by the scheduled occasions from EventBridge. The S3CrawlLambdaFunction operate crawls via the
MediaBucketand theYTMediabucketand begins an Amazon Q Enterprise index (or Amazon Kendra) knowledge supply sync job. The Lambda operate lists all of the supported media information (FLAC, MP3, MP4, Ogg, WebM, AMR, or WAV) and related metadata and transcribe choices saved within the person offered S3 bucket. - Every new file is added to a different DynamoDB monitoring desk and submitted to be transcribed by an Amazon Transcribe job. Any file that has been beforehand transcribed is submitted for transcription once more provided that it has been modified because it was beforehand transcribed, or if related Amazon Transcribe choices have been up to date. The DynamoDB desk is up to date to mirror the transcription standing and final modified timestamp of every file. Any tracked information that now not exist within the S3 bucket are faraway from the DynamoDB desk and from the Amazon Q Enterprise index (or Amazon Kendra index). If no new or up to date information are found, the Amazon Q Enterprise index (or Amazon Kendra) knowledge supply sync job is instantly stopped. The DynamoDB desk holds a report for every media file with attributes to trace transcription job names and standing, and final modified timestamps.
- As every Amazon Transcribe job completes, EventBridge generates a job full occasion, which invokes one other Lambda operate (S3JobCompletionLambdaFunction).
- The Lambda operate processes the transcription job output, producing a modified transcription that has a time marker inserted firstly of every sentence. This modified transcription is listed in Amazon Q Enterprise (or Amazon Kendra), and the job standing for the file is up to date within the DynamoDB desk. When the final file has been transcribed and listed, the Amazon Q Enterprise (or Amazon Kendra) knowledge supply sync job is stopped.
- The index is populated and stored in sync with the transcriptions of all of the media information within the S3 bucket monitored by the Mediasearch indexer part, built-in with any extra content material from another provisioned knowledge sources. The media transcriptions are utilized by the Amazon Q Enterprise utility, which permits customers to search out content material and solutions to their questions.
- The pattern finder consumer utility enhances customers’ search expertise by embedding an inline media participant with every supply or quotation that’s based mostly on a transcribed media file. The consumer makes use of the time markers embedded within the transcript to start out media playback on the related part of the unique media file.
- An Amazon Cognito person pool is used to authenticate customers and is configured to alternate tokens from IAM Identification Middle to assist Amazon Q Enterprise service calls.
Estimated prices
Along with Amazon S3 prices related to storing your media, the Mediasearch answer incurs utilization prices from the Amazon Q, Amazon Kendra (if utilizing an Amazon Kendra index), Amazon Transcribe, and Amazon API Gateway. Extra minor prices are incurred by the opposite companies talked about after free tier allowances have been used. For extra data, see the pricing pages for Amazon Q Business, Amazon Kendra, Amazon Transcribe, Lambda, DynamoDB, and EventBridge.
Monitor and troubleshoot
To see the small print of every media file transcript job, navigate to the Transcription jobs web page on the Amazon Transcribe console.
Every media file is transcribed just one time, except the file is modified. Modified information are re-transcribed and re-indexed to mirror the modifications.
Select any transcription job to evaluation the transcription and look at extra job particulars.
![]()
You possibly can examine the standing of the information supply sync by navigating to the Amazon Q Enterprise utility deployed by the indexer stack (select the hyperlink on the indexer stack outputs web page for QApplication). Within the knowledge supply part, select the customized knowledge supply and examine the standing of the sync job.

On the DynamoDB console, select Tables within the navigation pane. Use your MediaSearch stack title as a filter to show the MediaSearch DynamoDB tables, and look at the gadgets displaying every listed media file and corresponding standing.
The desk MediaSearch-Indexer-YTMediaDDBQueueTable has one report for every YouTube videoid that’s downloaded as an audio (mp3) file together with the metadata for the video like writer, view rely, video title, and so forth.

The desk MediaSearch-Indexer-MediaDynamoTable has one report for every media file (together with YouTube movies), and incorporates attributes with details about the file and its processing standing.

On the Features web page of the Lambda console, use your indexer stack title as a filter to listing the Lambda features which might be a part of the answer:
- The
YouTubeVideoIndexeroperate indexes and downloads YouTube movies if the CloudFormation stack parameterPlayListURLis about to a legitimate YouTube playlist - The S3CrawlLambdaFunction operate crawls the
YTMediaBucketand theMediaBucketfor media information and initiates the transcription jobs for the media information
When the transcription job is full, a completion occasion invokes the S3JobCompletionLambdaFunction operate, which ingests the transcription into the Amazon Q Enterprise index (or Amazon Kendra index) with any associated metadata.

Select any of the features to look at the operate particulars, together with surroundings variables, supply code, and extra. Select Monitor and View logs in CloudWatch to look at the output of every operate invocation and troubleshoot any points.
On the Features web page of the Lambda console, use your finder stack title as a filter to listing the Lambda features which might be a part of the answer:
- The
BuildTriggerLambdaoperate runs the construct of the finder AWS Amplify utility after cloning the AWS CodeCommit repository with the finder ReactJS code. - The
IDCTokenCreateLambdaoperate makes use of the authorization header that incorporates a JWT token from a profitable authentication with Amazon Cognito to alternate bearer tokens from IAM Identification Middle. - The
IDCAppCreateLambdaoperate creates an OAuth 2.0 IAM Identification Middle utility to alternate tokens from IAM Identification Middle and a trusted token issuer for the Amazon Cognito person pool. - The
UserConversationLambdaoperate is known as from API Gateway to list or delete Amazon Q Enterprise conversations. - The
UserPromptsLambdaoperate is known as from API Gateway to name the chat_sync API of the Amazon Q Enterprise service. - The
PreSignedURLCreateLambdaoperate is known as from API Gateway to create a presigned URL for S3 buckets. The presigned URL is used to play the media information residing on theMediabucketthat serves because the supply for an Amazon Q Enterprise response.

Select any of the features to look at the operate particulars, together with surroundings variables, supply code, and extra. Select Monitor and View logs in CloudWatch to look at the output of every operate invocation and troubleshoot any points.
Customise and improve the answer
You possibly can fork the MediaSearch Q Enterprise GitHub repository, improve the code, and ship us pull requests so we are able to incorporate and share your enhancements.
The next are just a few ideas for options you would possibly wish to implement:
- Improve the indexer stack to permit the prevailing Amazon Q Enterprise utility IDs for use
- Prolong your search sources to incorporate different video streaming platforms related to your group
- Construct Amazon CloudWatch metrics and dashboards to enhance the manageability of MediaSearch
Clear up
Once you’re completed experimenting with this answer, clear up your sources by utilizing the AWS CloudFormation console to delete the indexer and finder stacks that you simply deployed. This deletes all of the sources that have been created by deploying the answer.
Preexisting Amazon Q Enterprise functions or indexes or IAM Identification Middle functions or trusted token issuers that have been created manually aren’t deleted.
Conclusion
The mixture of Amazon Q Enterprise and Amazon Transcribe permits a scalable, cost-effective answer to floor insights out of your media information. You need to use the content material of your media information to search out correct solutions to your customers’ questions, whether or not they’re from textual content paperwork or media information, and devour them of their native format. This answer enhances the general expertise of the previous Mediasearch solution by utilizing the highly effective generative synthetic intelligence (AI) capabilities of Amazon Q Enterprise.
The pattern MediaSearch Q Enterprise answer is offered as open supply—use it as a place to begin to your personal answer, and assist us make it higher by contributing again fixes and options via GitHub pull requests. For professional help, AWS Skilled Companies and different Amazon companions are right here to assist.
We’d love to listen to from you. Tell us what you suppose within the feedback part, or use the problems discussion board within the MediaSearch Q Enterprise GitHub repository.
Concerning the Authors
 Roshan Thomas is a Senior Options Architect at Amazon Internet Companies. He’s based mostly in Melbourne, Australia, and works intently with energy and utilities prospects to speed up their journey within the cloud. He’s obsessed with expertise and serving to prospects architect and construct options on AWS.
Roshan Thomas is a Senior Options Architect at Amazon Internet Companies. He’s based mostly in Melbourne, Australia, and works intently with energy and utilities prospects to speed up their journey within the cloud. He’s obsessed with expertise and serving to prospects architect and construct options on AWS.
 Anup Dutta is a Options Architect with AWS based mostly in Chennai, India. In his position at AWS, Anup works intently with startups to design and construct cloud-centered options on AWS.
Anup Dutta is a Options Architect with AWS based mostly in Chennai, India. In his position at AWS, Anup works intently with startups to design and construct cloud-centered options on AWS.
 Bob Strahan is a Principal Options Architect within the AWS Language AI Companies staff.
Bob Strahan is a Principal Options Architect within the AWS Language AI Companies staff.
 Abhinav Jawadekar is a Principal Options Architect within the Amazon Q Enterprise service staff at AWS. Abhinav works with AWS prospects and companions to assist them construct generative AI options on AWS.
Abhinav Jawadekar is a Principal Options Architect within the Amazon Q Enterprise service staff at AWS. Abhinav works with AWS prospects and companions to assist them construct generative AI options on AWS.





