Implement serverless semantic search of picture and stay video with Amazon Titan Multimodal Embeddings
In in the present day’s data-driven world, industries throughout varied sectors are accumulating large quantities of video information via cameras put in of their warehouses, clinics, roads, metro stations, shops, factories, and even personal amenities. This video information holds immense potential for evaluation and monitoring of incidents which will happen in these areas. From hearth hazards to damaged tools, theft, or accidents, the power to investigate and perceive this video information can result in vital enhancements in security, effectivity, and profitability for companies and people.
This information permits for the derivation of precious insights when mixed with a searchable index. Nevertheless,conventional video evaluation strategies usually depend on guide, labor-intensive processes, making it difficult to scale and environment friendly. On this put up, we introduce semantic search, a method to seek out incidents in movies based mostly on pure language descriptions of occasions that occurred within the video. For instance, you may seek for “hearth within the warehouse” or “damaged glass on the ground.” That is the place multi-modal embeddings come into play. We introduce the usage of the Amazon Titan Multimodal Embeddings mannequin, which may map visible in addition to textual information into the identical semantic house, permitting you to make use of textual description and discover photographs containing that semantic that means. This semantic search approach permits you to analyze and perceive frames from video information extra successfully.
We stroll you thru developing a scalable, serverless, end-to-end semantic search pipeline for surveillance footage with Amazon Kinesis Video Streams, Amazon Titan Multimodal Embeddings on Amazon Bedrock, and Amazon OpenSearch Service. Kinesis Video Streams makes it easy to securely stream video from related units to AWS for analytics, machine studying (ML), playback, and different processing. It permits real-time video ingestion, storage, encoding, and streaming throughout units. Amazon Bedrock is a totally managed service that gives entry to a spread of high-performing basis fashions from main AI firms via a single API. It provides the capabilities wanted to construct generative AI functions with safety, privateness, and accountable AI. Amazon Titan Multimodal Embeddings, accessible via Amazon Bedrock, permits extra correct and contextually related multimodal search. It processes and generates data from distinct information varieties like textual content and pictures. You’ll be able to submit textual content, photographs, or a mix of each as enter to make use of the mannequin’s understanding of multimodal content material. OpenSearch Service is a totally managed service that makes it easy to deploy, scale, and function OpenSearch. OpenSearch Service permits you to retailer vectors and different information varieties in an index, and provides sub second question latency even when looking out billions of vectors and measuring the semantical relatedness, which we use on this put up.
We talk about learn how to steadiness performance, accuracy, and price range. We embody pattern code snippets and a GitHub repo so you can begin experimenting with constructing your individual prototype semantic search answer.
Overview of answer
The answer consists of three parts:
- First, you extract frames of a stay stream with the assistance of Kinesis Video Streams (you possibly can optionally extract frames of an uploaded video file as properly utilizing an AWS Lambda perform). These frames will be saved in an Amazon Simple Storage Service (Amazon S3) bucket as information for later processing, retrieval, and evaluation.
- Within the second element, you generate an embedding of the body utilizing Amazon Titan Multimodal Embeddings. You retailer the reference (an S3 URI) to the precise body and video file, and the vector embedding of the body in OpenSearch Service.
- Third, you settle for a textual enter from the consumer to create an embedding utilizing the identical mannequin and use the API supplied to question your OpenSearch Service index for photographs utilizing OpenSearch’s clever vector search capabilities to seek out photographs which might be semantically much like your textual content based mostly on the embeddings generated by the Amazon Titan Multimodal Embeddings mannequin.
This answer makes use of Kinesis Video Streams to deal with any quantity of streaming video information with out customers provisioning or managing any servers. Kinesis Video Streams mechanically extracts images from video data in real time and delivers the photographs to a specified S3 bucket. Alternatively, you should utilize a serverless Lambda perform to extract frames of a saved video file with the Python OpenCV library.
The second element converts these extracted frames into vector embeddings immediately by calling the Amazon Bedrock API with Amazon Titan Multimodal Embeddings.
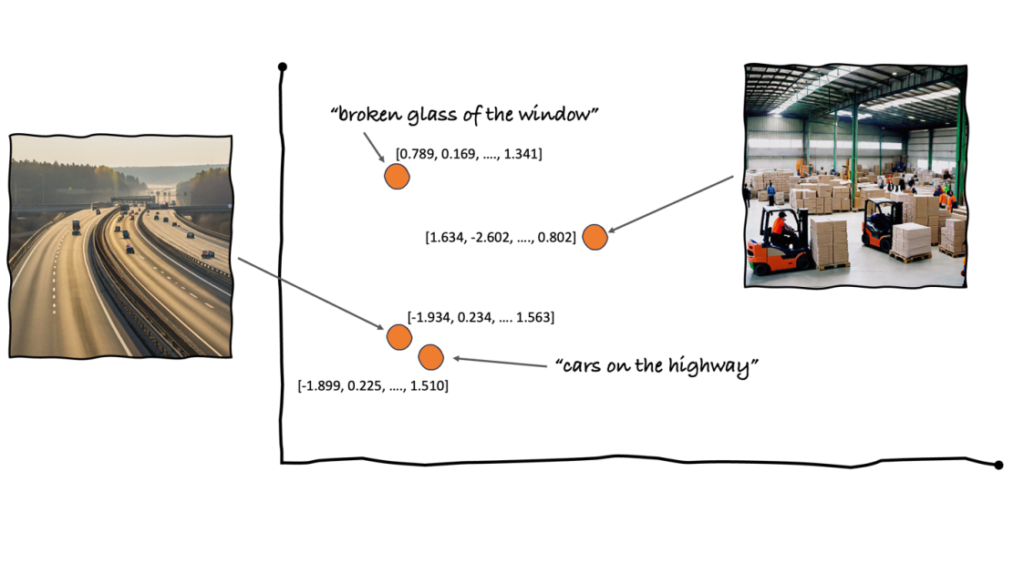
Embeddings are a vector illustration of your information that seize semantic that means. Producing embeddings of textual content and pictures utilizing the identical mannequin helps you measure the space between vectors to seek out semantic similarities. For instance, you possibly can embed all picture metadata and extra textual content descriptions into the identical vector house. Shut vectors point out that the photographs and textual content are semantically associated. This permits for semantic picture search—given a textual content description, you’ll find related photographs by retrieving these with probably the most comparable embeddings, as represented within the following visualization.

Beginning December 2023, you should utilize the Amazon Titan Multimodal Embeddings mannequin to be used instances like looking out photographs by textual content, picture, or a mix of textual content and picture. It produces 1,024-dimension vectors (by default), enabling extremely correct and quick search capabilities. You can too configure smaller vector sizes to optimize for value vs. accuracy. For extra data, seek advice from Amazon Titan Multimodal Embeddings G1 model.
The next diagram visualizes the conversion of an image to a vector illustration. You break up the video information into frames and save them in a S3 bucket (Step 1). The Amazon Titan Multimodal Embeddings mannequin converts these frames into vector embeddings (Step 2). You retailer the embeddings of the video body as a k-nearest neighbors (k-NN) vector in your OpenSearch Service index with the reference to the video clip and the body within the S3 bucket itself (Step 3). You’ll be able to add extra descriptions in a further area.

The next diagram visualizes the semantic search with pure language processing (NLP). The third element permits you to submit a question in pure language (Step 1) for particular moments or actions in a video, returning an inventory of references to frames which might be semantically much like the question. The Amazon Titan MultimodalEmbeddings mannequin (Step 2) converts the submitted textual content question right into a vector embedding (Step 3). You employ this embedding to search for probably the most comparable embeddings (Step 4). The saved references within the returned outcomes are used to retrieve the frames and video clip to the UI for replay (Step 5).

The next diagram reveals our answer structure.

The workflow consists of the next steps:
- You stream stay video to Kinesis Video Streams. Alternatively, add current video clips to an S3 bucket.
- Kinesis Video Streams extracts frames from the stay video to an S3 bucket. Alternatively, a Lambda perform extracts frames of the uploaded video clips.
- One other Lambda perform collects the frames and generates an embedding with Amazon Bedrock.
- The Lambda perform inserts the reference to the picture and video clip along with the embedding as a k-NN vector into an OpenSearch Service index.
- You submit a question immediate to the UI.
- A brand new Lambda perform converts the question to a vector embedding with Amazon Bedrock.
- The Lambda perform searches the OpenSearch Service picture index for any frames matching the question and the k-NN for the vector utilizing cosine similarity and returns an inventory of frames.
- The UI shows the frames and video clips by retrieving the property from Kinesis Video Streams utilizing the saved references of the returned outcomes. Alternatively, the video clips are retrieved from the S3 bucket.
This answer was created with AWS Amplify. Amplify is a improvement framework and internet hosting service that assists frontend net and cell builders in constructing safe and scalable functions with AWS instruments rapidly and effectively.
Optimize for performance, accuracy, and price
Let’s conduct an evaluation of this proposed answer structure to find out alternatives for enhancing performance, bettering accuracy, and decreasing prices.
Beginning with the ingestion layer, seek advice from Design considerations for cost-effective video surveillance platforms with AWS IoT for Smart Homes to be taught extra about cost-effective ingestion into Kinesis Video Streams.
The extraction of video frames on this answer is configured utilizing Amazon S3 supply with Kinesis Video Streams. A key trade-off to judge is figuring out the optimum body fee and backbone to satisfy the use case necessities balanced with total system useful resource utilization. The body extraction fee can vary from as excessive as five frames per second to as low as one frame every 20 seconds. The selection of body fee will be pushed by the enterprise use case, which immediately impacts embedding era and storage in downstream companies like Amazon Bedrock, Lambda, Amazon S3, and the Amazon S3 supply characteristic, in addition to looking out throughout the vector database. Even when importing pre-recorded movies to Amazon S3, considerate consideration ought to nonetheless be given to choosing an applicable body extraction fee and backbone. Tuning these parameters permits you to steadiness your use case accuracy wants with consumption of the talked about AWS companies.
The Amazon Titan Multimodal Embeddings mannequin outputs a vector illustration with an default embedding length of 1,024 from the enter information. This illustration carries the semantic that means of the enter and is greatest to match with different vectors for optimum similarity. For greatest efficiency, it’s beneficial to make use of the default embedding size, however it will probably have direct impression on efficiency and storage prices. To extend efficiency and scale back prices in your manufacturing setting, alternate embedding lengths will be explored, equivalent to 256 and 384. Lowering the embedding size additionally means dropping a few of the semantic context, which has a direct impression on accuracy, however improves the general pace and optimizes the storage prices.
OpenSearch Service provides on-demand, reserved, and serverless pricing choices with normal function or storage optimized machine varieties to suit totally different workloads. To optimize prices, it is best to choose reserved cases to cowl your manufacturing workload base, and use on-demand, serverless, and convertible reservations to deal with spikes and non-production masses. For lower-demand manufacturing workloads, a cost-friendly alternate choice is utilizing pgvector with Amazon Aurora PostgreSQL Serverless, which provides decrease base consumption items as in comparison with Amazon OpenSearch Serverless, thereby reducing the price.
Figuring out the optimum worth of Okay within the k-NN algorithm for vector similarity search is important for balancing accuracy, efficiency, and price. A bigger Okay worth usually will increase accuracy by contemplating extra neighboring vectors, however comes on the expense of upper computational complexity and price. Conversely, a smaller Okay results in quicker search instances and decrease prices, however could decrease outcome high quality. When utilizing the k-NN algorithm with OpenSearch Service, it’s important to rigorously consider the Okay parameter based mostly in your software’s priorities—beginning with smaller values like Okay=5 or 10, then iteratively growing Okay if greater accuracy is required.
As a part of the answer, we suggest Lambda because the serverless compute choice to course of frames. With Lambda, you possibly can run code for just about any sort of software or backend service—all with zero administration. Lambda takes care of all the things required to run and scale your code with excessive availability.
With excessive quantities of video information, it is best to consider binpacking your frame processing tasks and working a batch computing job to entry a considerable amount of compute assets. The mixture of AWS Batch and Amazon Elastic Container Service (Amazon ECS) can effectively provision assets in response to jobs submitted with the intention to get rid of capability constraints, scale back compute prices, and ship outcomes rapidly.
You’ll incur prices when deploying the GitHub repo in your account. If you end up completed inspecting the instance, observe the steps within the Clear up part later on this put up to delete the infrastructure and cease incurring costs.
Check with the README file in the repository to know the constructing blocks of the answer intimately.
Conditions
For this walkthrough, it is best to have the next stipulations:
Deploy the Amplify software
Full the next steps to deploy the Amplify software:
- Clone the repository to your native disk with the next command:
- Change the listing to the cloned repository.
- Initialize the Amplify software:
- Clear set up the dependencies of the online software:
- Create the infrastructure in your AWS account:
- Run the online software in your native setting:
Create an software account
Full the next steps to create an account within the software:
- Open the online software with the said URL in your terminal.
- Enter a consumer identify, password, and e-mail deal with.
- Affirm your e-mail deal with with the code despatched to it.
Add information out of your pc
Full the next steps to add picture and video information saved domestically:
- Select File Add within the navigation pane.
- Select Select information.
- Choose the photographs or movies out of your native drive.
- Select Add Information.
Add information from a webcam
Full the next steps to add photographs and movies from a webcam:
- Select Webcam Add within the navigation pane.
- Select Permit when requested for permissions to entry your webcam.
- Select to both add a single captured picture or a captured video:
- Select Seize Picture and Add Picture to add a single picture out of your webcam.
- Select Begin Video Seize, Cease Video Seize, and eventually
Add Video to add a video out of your webcam.
Search movies
Full the next steps to look the information and movies you uploaded.
- Select Search within the navigation pane.
- Enter your immediate within the Search Movies textual content area. For instance, we ask “Present me an individual with a golden ring.”
- Decrease the arrogance parameter nearer to 0 in the event you see fewer outcomes than you had been initially anticipating.
The next screenshot reveals an instance of our outcomes.

Clear up
Full the next steps to wash up your assets:
- Open a terminal within the listing of your domestically cloned repository.
- Run the next command to delete the cloud and native assets:
Conclusion
A multi-modal embeddings mannequin has the potential to revolutionize the best way industries analyze incidents captured with movies. AWS companies and instruments can assist industries unlock the total potential of their video information and enhance their security, effectivity, and profitability. As the quantity of video information continues to develop, the usage of multi-modal embeddings will develop into more and more essential for industries trying to keep forward of the curve. As improvements like Amazon Titan basis fashions proceed maturing, they’ll scale back the boundaries to make use of superior ML and simplify the method of understanding information in context. To remain up to date with state-of-the-art performance and use instances, seek advice from the next assets:
Concerning the Authors
 Thorben Sanktjohanser is a Options Architect at Amazon Internet Companies supporting media and leisure firms on their cloud journey together with his experience. He’s captivated with IoT, AI/ML and constructing sensible residence units. Virtually each a part of his house is automated, from mild bulbs and blinds to hoover cleansing and mopping.
Thorben Sanktjohanser is a Options Architect at Amazon Internet Companies supporting media and leisure firms on their cloud journey together with his experience. He’s captivated with IoT, AI/ML and constructing sensible residence units. Virtually each a part of his house is automated, from mild bulbs and blinds to hoover cleansing and mopping.
 Talha Chattha is an AI/ML Specialist Options Architect at Amazon Internet Companies, based mostly in Stockholm, serving key prospects throughout EMEA. Talha holds a deep ardour for generative AI applied sciences. He works tirelessly to ship revolutionary, scalable, and precious ML options within the house of huge language fashions and basis fashions for his prospects. When not shaping the way forward for AI, he explores scenic European landscapes and scrumptious cuisines.
Talha Chattha is an AI/ML Specialist Options Architect at Amazon Internet Companies, based mostly in Stockholm, serving key prospects throughout EMEA. Talha holds a deep ardour for generative AI applied sciences. He works tirelessly to ship revolutionary, scalable, and precious ML options within the house of huge language fashions and basis fashions for his prospects. When not shaping the way forward for AI, he explores scenic European landscapes and scrumptious cuisines.
 Victor Wang is a Sr. Options Architect at Amazon Internet Companies, based mostly in San Francisco, CA, supporting revolutionary healthcare startups. Victor has spent 6 years at Amazon; earlier roles embody software program developer for AWS Website-to-Website VPN, AWS ProServe Advisor for Public Sector Companions, and Technical Program Supervisor for Amazon RDS for MySQL. His ardour is studying new applied sciences and touring the world. Victor has flown over one million miles and plans to proceed his everlasting journey of exploration.
Victor Wang is a Sr. Options Architect at Amazon Internet Companies, based mostly in San Francisco, CA, supporting revolutionary healthcare startups. Victor has spent 6 years at Amazon; earlier roles embody software program developer for AWS Website-to-Website VPN, AWS ProServe Advisor for Public Sector Companions, and Technical Program Supervisor for Amazon RDS for MySQL. His ardour is studying new applied sciences and touring the world. Victor has flown over one million miles and plans to proceed his everlasting journey of exploration.
 Akshay Singhal is a Sr. Technical Account Supervisor at Amazon Internet Companies, based mostly in San Francisco Bay Space, supporting enterprise assist prospects specializing in the safety ISV section. He offers technical steering for patrons to implement AWS options, with experience spanning serverless architectures and cost-optimization. Exterior of labor, Akshay enjoys touring, Method 1, making quick films, and exploring new cuisines.
Akshay Singhal is a Sr. Technical Account Supervisor at Amazon Internet Companies, based mostly in San Francisco Bay Space, supporting enterprise assist prospects specializing in the safety ISV section. He offers technical steering for patrons to implement AWS options, with experience spanning serverless architectures and cost-optimization. Exterior of labor, Akshay enjoys touring, Method 1, making quick films, and exploring new cuisines.





