Dynamic video content material moderation and coverage analysis utilizing AWS generative AI providers
Organizations throughout media and leisure, promoting, social media, training, and different sectors require environment friendly options to extract data from movies and apply versatile evaluations based mostly on their insurance policies. Generative artificial intelligence (AI) has unlocked contemporary alternatives for these use circumstances. On this submit, we introduce the Media Analysis and Policy Evaluation answer, which makes use of AWS AI and generative AI providers to offer a framework to streamline video extraction and analysis processes.
Widespread use circumstances
Promoting tech corporations personal video content material like advert creatives. Relating to video evaluation, priorities embrace model security, regulatory compliance, and fascinating content material. This answer, powered by AWS AI and generative AI providers, meets these wants. Superior content material moderation makes certain advertisements seem alongside secure, compliant content material, constructing belief with customers. You should utilize the answer to judge movies towards content material compliance insurance policies. You may as well use it to create compelling headlines and summaries, boosting consumer engagement and advert efficiency.
Instructional tech corporations handle giant inventories of coaching movies. An environment friendly option to analyze movies will assist them consider content material towards business insurance policies, index movies for environment friendly search, and carry out dynamic detection and redaction duties, similar to blurring scholar faces in a Zoom recording.
The answer is on the market on the GitHub repository and may be deployed to your AWS account utilizing an AWS Cloud Development Kit (AWS CDK) package.
Resolution overview
- Media extraction – After a video uploaded, the app begins preprocessing by extracting picture frames from a video. Every body will probably be analyzed utilizing Amazon Rekognition and Amazon Bedrock for metadata extraction. In parallel, the system extracts audio transcription from the uploaded content material utilizing Amazon Transcribe.
- Coverage analysis – Utilizing the extracted metadata from the video, the system conducts LLM analysis. This lets you reap the benefits of the pliability of LLMs to judge video towards dynamic insurance policies.
The next diagram illustrates the answer workflow and structure.

The answer adopts microservice design ideas, with loosely coupled parts that may be deployed collectively to serve the video evaluation and coverage analysis workflow, or independently to combine into current pipelines. The next diagram illustrates the microservice structure.

The microservice workflow consists of the next steps:
- Customers entry the frontend static web site by way of Amazon CloudFront distribution. The static content material is hosted on Amazon Simple Storage Service (Amazon S3).
- Customers log in to the frontend internet utility and are authenticated by an Amazon Cognito consumer pool.
- Customers add movies to Amazon S3 instantly from their browser utilizing multi-part pre-signed Amazon S3 URLs.
- The frontend UI interacts with the extract microservice via a RESTful interface supplied by Amazon API Gateway. This interface presents CRUD (create, learn, replace, delete) options for video activity extraction administration.
- An AWS Step Functions state machine oversees the evaluation course of. It transcribes audio utilizing Amazon Transcribe, samples picture frames from video utilizing moviepy, and analyzes every picture utilizing Anthropic Claude Sonnet picture summarization. It additionally generates textual content embedding and multimodal embedding on the body degree utilizing Amazon Titan fashions.
- An Amazon OpenSearch Service cluster shops the extracted video metadata and facilitates customers’ search and discovery wants. The UI constructs analysis prompts and sends them to Amazon Bedrock LLMs, retrieving analysis outcomes synchronously.
- Utilizing the answer UI, consumer selects current template prompts, customise them and begin the coverage analysis using Amazon Bedrock. The answer runs the analysis workflow and show the outcomes again to the consumer.
Within the following sections, we talk about the important thing parts and microservices of the answer in additional element.
Web site UI
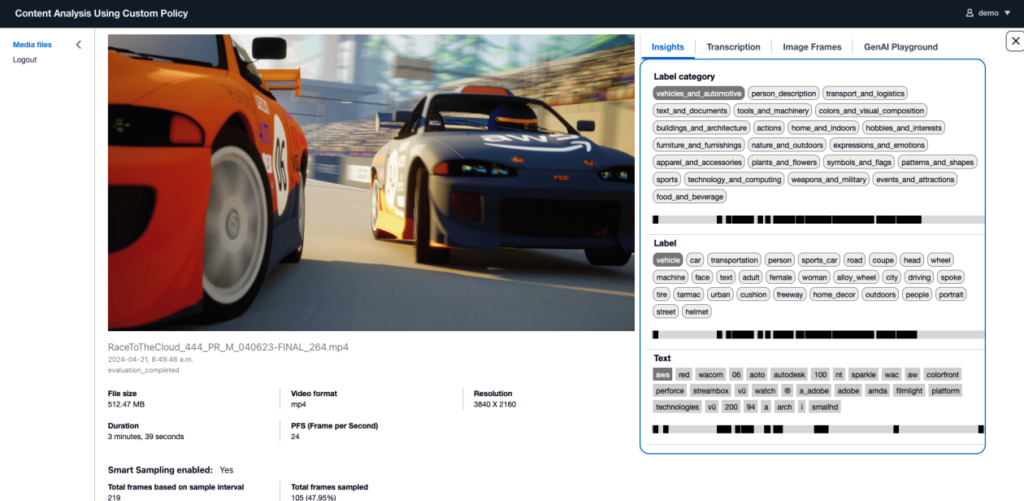
The answer incorporates a web site that lets customers browse movies and handle the importing course of via a user-friendly interface. It presents particulars of the extracted video data and features a light-weight analytics UI for dynamic LLM evaluation. The next screenshots present some examples.


Extract data from movies
The answer features a backend extraction service to handle video metadata extraction asynchronously. This entails extracting data from each the visible and audio parts, together with figuring out objects, scenes, textual content, and human faces. The audio element is especially necessary for movies with energetic narratives and conversations, as a result of it typically accommodates helpful data.
Constructing a strong answer to extract data from movies poses challenges from each machine studying (ML) and engineering views. From the ML standpoint, our purpose is to attain generic extraction of data to function factual knowledge for downstream evaluation. On the engineering aspect, managing video sampling with concurrency, offering excessive availability, and versatile configuration choices, in addition to having an extendable structure to help extra ML mannequin plugins requires intensive effort.
The extraction service makes use of Amazon Transcribe to transform the audio portion of the video into textual content in subtitle codecs. For visible extraction, there are a couple of main strategies concerned:
- Body sampling – The basic methodology for analyzing the visible side of a video makes use of a sampling approach. This entails capturing screenshots at particular intervals after which making use of ML fashions to extract data from every picture body. Our answer makes use of sampling with the next concerns:
- The answer helps a configurable interval for the fastened sampling charge.
- It additionally presents a sophisticated good sampling choice, which makes use of the Amazon Titan Multimodal Embeddings mannequin to conduct similarity search towards frames sampled from the identical video. This course of identifies comparable pictures and discards redundant ones to optimize efficiency and price.
- Extract data from picture frames – The answer will iterate via pictures sampled from a video and course of them concurrently. For every picture, it’ll apply the next ML options to extract data:
The next diagram illustrates how the extraction service is applied.

The extraction service makes use of Amazon Simple Queue Service (Amazon SQS) and Step Features to handle concurrent video processing, permitting configurable settings. You’ll be able to specify what number of movies may be processed in parallel and what number of frames for every video may be processed concurrently, based mostly in your account’s service quota limits and efficiency necessities.
Search the movies
Effectively figuring out movies inside your stock is a precedence, and an efficient search functionality is crucial for video evaluation duties. Conventional video search strategies depend on full-text key phrase searches. With the introduction of textual content embedding and multimodal embedding, new search strategies based mostly on semantics and pictures have emerged.
The answer presents search performance by way of the extraction service, out there as a UI characteristic. It generates vector embeddings on the picture body degree as a part of the extraction course of to serve video search. You’ll be able to search movies and their underlying frames both via the built-in internet UI or by way of the RESTful API interface instantly. There are three search choices you may select from:
- Full textual content search – Powered by OpenSearch Service, it makes use of a search index generated by text analyzers that’s excellent for key phrase search.
- Semantic search – Powered by the Amazon Titan Text Embeddings model, generated based mostly on transcription and picture metadata extracted on the body degree.
- Picture search – Powered by the Amazon Titan Multimodal Embeddings model, generated utilizing the identical textual content message used for textual content embedding together with the picture body. This characteristic is appropriate for picture search, permitting you to offer a picture and discover comparable frames in movies.
The next screenshot of the UI showcases the usage of multimodal embedding to seek for movies containing the AWS emblem. The net UI shows three movies with frames which have a excessive similarity rating compared with the supplied AWS emblem picture. You may as well discover the opposite two textual content search choices on the dropdown menu, supplying you with the pliability to change amongst search choices.

Analyze the movies
After gathering wealthy insights from the movies, you may analyze the information. The answer incorporates a light-weight UI, applied as a static React internet utility, powered by a backend microservice known as the analysis service. This service acts as a proxy atop the Amazon Bedrock LLMs to offer real-time analysis. You should utilize this as a sandbox characteristic to check out LLMs prompts for dynamic video evaluation. The net UI accommodates a couple of pattern immediate templates to indicate how one can analyze video for various use circumstances, together with the next:
- Content material moderation – Flag unsafe scenes, textual content, or speech that violate your belief and security coverage
- Video summarization – Summarize the video right into a concise description based mostly on its audio or visible content material cues
- IAB classification – Classify the video content material into promoting IAB classes for higher group and understanding
You may as well select from a group of LLMs fashions supplied by Amazon Bedrock to check the analysis outcomes and discover probably the most appropriate one to your workload. LLMs can use the extraction knowledge and carry out evaluation based mostly in your directions, making them versatile and extendable analytics instruments that may help varied use circumstances. The next are some examples of the immediate templates for video evaluation. The placeholders inside #### will probably be changed by the corresponding video-extracted knowledge at runtime.
The primary instance reveals learn how to reasonable a video based mostly on audio transcription and object and moderation labels detected by Amazon Rekognition. This pattern features a fundamental inline coverage. You’ll be able to lengthen this part so as to add extra guidelines. You’ll be able to combine longer belief and security coverage paperwork and runbooks in an Retrieval Augmented Era (RAG) sample utilizing Knowledge Bases for Amazon Bedrock.
Classifying movies into IAB classes was once difficult earlier than generative AI turned widespread. It usually concerned custom-trained textual content and picture classification ML fashions, which frequently confronted accuracy challenges. The next pattern immediate makes use of the Amazon Bedrock Anthropic Claude V3 Sonnet mannequin, which has built-in data of the IAB taxonomy. Subsequently, you don’t even want to incorporate the taxonomy definitions as a part of the LLM immediate.
Abstract
Video evaluation presents challenges that span technical difficulties in each ML and engineering. This answer offers a user-friendly UI to streamline the video evaluation and coverage analysis processes. The backend parts can function constructing blocks for integration into your current evaluation workflow, permitting you to deal with analytics duties with better enterprise influence.
You’ll be able to deploy the answer into your AWS account utilizing the AWS CDK package deal out there on the GitHub repo. For deployment particulars, seek advice from the step-by-step instructions.
In regards to the Authors

Lana Zhang is a Senior Options Architect at AWS World Broad Specialist Group AI Providers crew, specializing in AI and generative AI with a deal with use circumstances together with content material moderation and media evaluation. Along with her experience, she is devoted to selling AWS AI and generative AI options, demonstrating how generative AI can rework basic use circumstances with superior enterprise worth. She assists clients in remodeling their enterprise options throughout various industries, together with social media, gaming, e-commerce, media, promoting, and advertising and marketing.
 Negin Rouhanizadeh is a Options Architect at AWS specializing in AI/ML in Promoting and Advertising and marketing. Past crafting options for her clients, Negin enjoys portray, coding, spending time with household and her furry boys, Simba and Huchi.
Negin Rouhanizadeh is a Options Architect at AWS specializing in AI/ML in Promoting and Advertising and marketing. Past crafting options for her clients, Negin enjoys portray, coding, spending time with household and her furry boys, Simba and Huchi.





