Constructing Generative AI immediate chaining workflows with human within the loop
Generative AI is a kind of synthetic intelligence (AI) that can be utilized to create new content material, together with conversations, tales, pictures, movies, and music. Like all AI, generative AI works through the use of machine studying fashions—very giant fashions which can be pretrained on huge quantities of knowledge known as foundation models (FMs). FMs are skilled on a broad spectrum of generalized and unlabeled information. They’re able to performing all kinds of common duties with a excessive diploma of accuracy primarily based on enter prompts. Large language models (LLMs) are one class of FMs. LLMs are particularly centered on language-based duties resembling summarization, textual content era, classification, open-ended dialog, and knowledge extraction.
FMs and LLMs, despite the fact that they’re pre-trained, can proceed to study from information inputs or prompts throughout inference. This implies that you may develop complete outputs by way of fastidiously curated prompts. A immediate is the data you cross into an LLM to elicit a response. This contains process context, information that you just cross to the mannequin, dialog and motion historical past, directions, and even examples. The method of designing and refining prompts to get particular responses from these fashions known as immediate engineering.
Whereas LLMs are good at following directions within the immediate, as a process will get complicated, they’re identified to drop duties or carry out a process not on the desired accuracy. LLMs can deal with complicated duties higher once you break them down into smaller subtasks. This method of breaking down a fancy process into subtasks known as prompt chaining. With immediate chaining, you assemble a set of smaller subtasks as particular person prompts. Collectively, these subtasks make up the general complicated process. To perform the general process, your software feeds every subtask immediate to the LLM in a pre-defined order or in keeping with a algorithm.
Whereas Generative AI can create extremely life like content material, together with textual content, pictures, and movies, it will probably additionally generate outputs that seem believable however are verifiably incorrect. Incorporating human judgment is essential, particularly in complicated and high-risk decision-making situations. This entails constructing a human-in-the-loop course of the place people play an lively function in determination making alongside the AI system.
On this weblog submit, you’ll study immediate chaining, learn how to break a fancy process into a number of duties to make use of immediate chaining with an LLM in a particular order, and learn how to contain a human to evaluate the response generated by the LLM.
Instance overview
For instance this instance, contemplate a retail firm that enables purchasers to submit product opinions on their web site. By responding promptly to these opinions, the corporate demonstrates its commitments to clients and strengthens buyer relationships.

Determine 1: Buyer evaluate and response
The instance software on this submit automates the method of responding to buyer opinions. For many opinions, the system auto-generates a reply utilizing an LLM. Nonetheless, if the evaluate or LLM-generated response incorporates uncertainty round toxicity or tone, the system flags it for a human reviewer. The human reviewer then assesses the flagged content material to make the ultimate determination in regards to the toxicity or tone.
The applying makes use of event-driven architecture (EDA), a strong software program design sample that you need to use to construct decoupled methods by speaking by way of occasions. As quickly because the product evaluate is created, the evaluate receiving system makes use of Amazon EventBridge to ship an occasion {that a} product evaluate is posted, together with the precise evaluate content material. The occasion begins an AWS Step Functions workflow. The workflow runs by way of a sequence of steps together with producing content material utilizing an LLM and involving human determination making.

Determine 2: Evaluate workflow
The method of producing a evaluate response contains evaluating the toxicity of the evaluate content material, figuring out sentiment, producing a response, and involving a human approver. This naturally suits right into a workflow sort of software as a result of it’s a single course of containing a number of sequential steps together with the necessity to handle state between steps. Therefore the instance makes use of Step Features for workflow orchestration. Listed below are the steps within the evaluate response workflow.
- Detect if the evaluate content material has any dangerous info utilizing the Amazon Comprehend DetectToxicContent API. The API responds with the toxicity rating that represents the general confidence rating of detection between 0 and 1 with rating nearer to 1 indicating excessive toxicity.
- If toxicity of the evaluate is within the vary of 0.4 – 0.6, ship the evaluate to a human reviewer to make the choice.
- If the toxicity of the evaluate is larger than 0.6 or the reviewer finds the evaluate dangerous, publish
HARMFUL_CONTENT_DETECTEDmessage. - If the toxicity of the evaluate is lower than 0.4 or reviewer approves the evaluate, discover the sentiment of the evaluate first after which generate the response to the evaluate remark. Each duties are achieved utilizing a generative AI mannequin.
- Repeat the toxicity detection by way of the Comprehend API for the LLM generated response.
- If the toxicity of the LLM generated response is within the vary of 0.4 – 0.6, ship the LLM generated response to a human reviewer.
- If the LLM generated response is discovered to be non-toxic, publish
NEW_REVIEW_RESPONSE_CREATEDoccasion. - If the LLM generated response is discovered to be poisonous, publish
RESPONSE_GENERATION_FAILEDoccasion.

Determine 3: product evaluate analysis and response workflow
Getting began
Use the directions within the GitHub repository to deploy and run the applying.
Immediate chaining
Immediate chaining simplifies the issue for the LLM by dividing single, detailed, and monolithic duties into smaller, extra manageable duties. Some, however not all, LLMs are good at following all of the directions in a single immediate. The simplification ends in writing centered prompts for the LLM, resulting in a extra constant and correct response. The next is a pattern ineffective single immediate.
Learn the beneath buyer evaluate, filter for dangerous content material and supply your ideas on the general sentiment in JSON format. Then assemble an e-mail response primarily based on the sentiment you identify and enclose the e-mail in JSON format. Primarily based on the sentiment, write a report on how the product may be improved.
To make it simpler, you possibly can cut up the immediate into a number of subtasks:
- Filter for dangerous content material
- Get the sentiment
- Generate the e-mail response
- Write a report
You may even run among the duties in parallel. By breaking right down to centered prompts, you obtain the next advantages:
- You velocity up the whole course of. You may deal with duties in parallel, use completely different fashions for various duties, and ship response again to the consumer relatively than ready for the mannequin to course of a bigger immediate for significantly longer time.
- Higher prompts present higher output. With centered prompts, you possibly can engineer the prompts by including further related context thus enhancing the general reliability of the output.
- You spend much less time creating. Immediate engineering is an iterative course of. Each debugging LLM requires detailed immediate and refining the bigger immediate for accuracy require vital effort and time. Smaller duties allow you to experiment and refine by way of successive iterations.
Step Features is a pure match to construct immediate chaining as a result of it affords a number of other ways to chain prompts: sequentially, in parallel, and iteratively by passing the state information from one state to a different. Take into account the scenario the place you’ve got constructed the product evaluate response immediate chaining workflow and now wish to consider the responses from completely different LLMs to seek out the perfect match utilizing an analysis take a look at suite. The analysis take a look at suite consists of a whole bunch of take a look at product opinions, a reference response to the evaluate, and a algorithm to guage the LLM response in opposition to the reference response. You may automate the analysis exercise utilizing a Step Features workflow. The primary process within the workflow asks the LLM to generate a evaluate response for the product evaluate. The second process then asks the LLM to match the generated response to the reference response utilizing the foundations and generate an analysis rating. Primarily based on the analysis rating for every evaluate, you possibly can resolve if the LLM passes your analysis standards or not. You should utilize the map state in Step Features to run the evaluations for every evaluate in your analysis take a look at suite in parallel. See this repository for extra immediate chaining examples.
Human within the loop
Involving human determination making within the instance permits you to enhance the accuracy of the system when the toxicity of the content material can’t be decided to be both secure or dangerous. You may implement human evaluate throughout the Step Features workflow utilizing Wait for a Callback with the Task Token integration. Once you use this integration with any supported AWS SDK API, the workflow process generates a singular token after which pauses till the token is returned. You should utilize this integration to incorporate human determination making, name a legacy on-premises system, await completion of lengthy operating duties, and so forth.
Within the pattern software, the ship e-mail for approval process features a await the callback token. It invokes an AWS Lambda perform with a token and waits for the token. The Lambda perform builds an e-mail message together with the hyperlink to an Amazon API Gateway URL. Lambda then makes use of Amazon Simple Notification Service (Amazon SNS) to ship an e-mail to a human reviewer. The reviewer opinions the content material and both accepts or rejects the message by deciding on the suitable hyperlink within the e-mail. This motion invokes the Step Features SendTaskSuccess API. The API sends again the duty token and a standing message of whether or not to simply accept or reject the evaluate. Step Features receives the token, resumes the ship e-mail for approval process after which passes management to the selection state. The selection state decides whether or not to undergo acceptance or rejection of the evaluate primarily based on the standing message.

Determine 4: Human-in-the-loop workflow
Occasion-driven structure
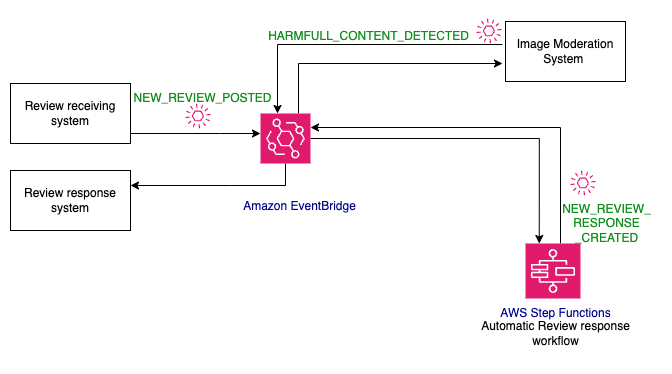
EDA allows constructing extensible architectures. You may add shoppers at any time by subscribing to the occasion. For instance, contemplate moderating pictures and movies hooked up to a product evaluate along with the textual content content material. You additionally want to write down code to delete the pictures and movies if they’re discovered dangerous. You may add a shopper, the picture moderation system, to the NEW_REVIEW_POSTED occasion with out making any code adjustments to the prevailing occasion shoppers or producers. Improvement of the picture moderation system and the evaluate response system to delete dangerous pictures can proceed in parallel which in flip improves growth velocity.
When the picture moderation workflow finds poisonous content material, it publishes a HARMFULL_CONTENT_DETECTED occasion. The occasion may be processed by a evaluate response system that decides what to do with the occasion. By decoupling methods by way of occasions, you achieve many benefits together with improved growth velocity, variable scaling, and fault tolerance.

Determine 5: Occasion-driven workflow
Cleanup
Use the directions within the GitHub repository to delete the pattern software.
Conclusion
On this weblog submit, you discovered learn how to construct a generative AI software with immediate chaining and a human-review course of. You discovered how each methods enhance the accuracy and security of a generative AI software. You additionally discovered how event-driven architectures together with workflows can combine present purposes with generative AI purposes.
Go to Serverless Land for extra Step Features workflows.
Concerning the authors
 Veda Raman is a Senior Specialist Options Architect for Generative AI and machine studying primarily based at AWS. Veda works with clients to assist them architect environment friendly, safe and scalable machine studying purposes. Veda focuses on generative AI companies like Amazon Bedrock and Amazon Sagemaker.
Veda Raman is a Senior Specialist Options Architect for Generative AI and machine studying primarily based at AWS. Veda works with clients to assist them architect environment friendly, safe and scalable machine studying purposes. Veda focuses on generative AI companies like Amazon Bedrock and Amazon Sagemaker.
 Uma Ramadoss is a Principal Options Architect at Amazon Net Companies, centered on the Serverless and Integration Companies. She is liable for serving to clients design and function event-driven cloud-native purposes utilizing companies like Lambda, API Gateway, EventBridge, Step Features, and SQS. Uma has a arms on expertise main enterprise-scale serverless supply initiatives and possesses robust working information of event-driven, micro service and cloud structure.
Uma Ramadoss is a Principal Options Architect at Amazon Net Companies, centered on the Serverless and Integration Companies. She is liable for serving to clients design and function event-driven cloud-native purposes utilizing companies like Lambda, API Gateway, EventBridge, Step Features, and SQS. Uma has a arms on expertise main enterprise-scale serverless supply initiatives and possesses robust working information of event-driven, micro service and cloud structure.





