Speed up NLP inference with ONNX Runtime on AWS Graviton processors
ONNX is an open supply machine studying (ML) framework that gives interoperability throughout a variety of frameworks, working techniques, and {hardware} platforms. ONNX Runtime is the runtime engine used for mannequin inference and coaching with ONNX.
AWS Graviton3 processors are optimized for ML workloads, together with help for bfloat16, Scalable Vector Extension (SVE), and Matrix Multiplication (MMLA) directions. Bfloat16 accelerated SGEMM kernels and int8 MMLA accelerated Quantized GEMM (QGEMM) kernels in ONNX have improved inference efficiency by as much as 65% for fp32 inference and as much as 30% for int8 quantized inference for a number of pure language processing (NLP) fashions on AWS Graviton3-based Amazon Elastic Compute Cloud (Amazon EC2) situations. Beginning model v1.17.0, the ONNX Runtime helps these optimized kernels.
On this put up, we present find out how to run ONNX Runtime inference on AWS Graviton3-based EC2 situations and find out how to configure them to make use of optimized GEMM kernels. We additionally display the ensuing speedup by way of benchmarking.
Optimized GEMM kernels
ONNX Runtime helps the Microsoft Linear Algebra Subroutine (MLAS) backend because the default Execution Supplier (EP) for deep studying operators. AWS Graviton3-based EC2 situations (c7g, m7g, r7g, c7gn, and Hpc7g situations) help bfloat16 format and MMLA directions for the deep studying operator acceleration. These directions enhance the SIMD {hardware} utilization and cut back the end-to-end inference latency by as much as 1.65 occasions in comparison with the armv8 DOT product instruction-based kernels.
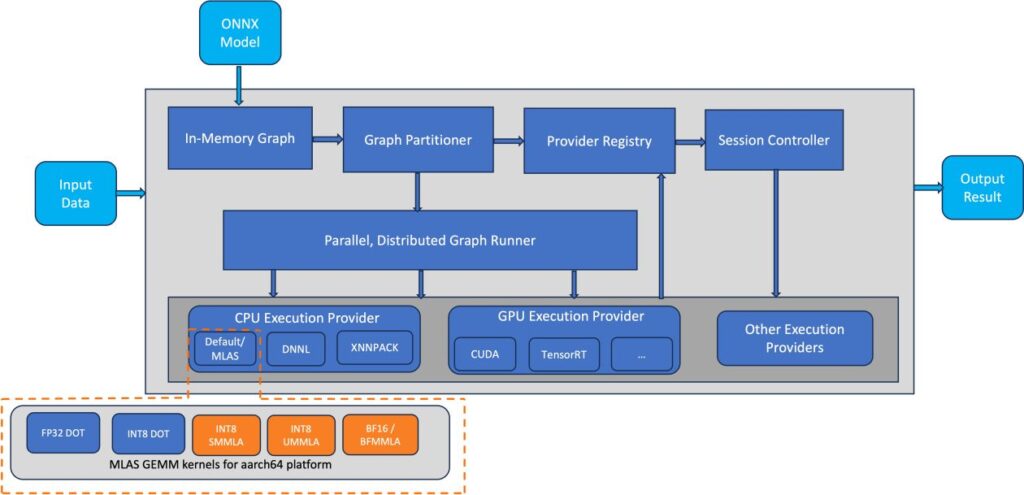
The AWS group applied MLAS kernels for bfloat16 quick math and int8 quantized Normal Matrix Multiply (GEMM) utilizing BFMMLA, SMMLA, and UMMLA directions, which have larger matrix multiplication throughput in comparison with DOT directions. The bfloat16 help permits environment friendly deployment of fashions educated utilizing bfloat16, fp32, and computerized blended precision (AMP) with out the necessity for quantization. As proven within the following diagrams, the optimized GEMM kernels are built-in into the ONNX Runtime CPU EP as MLAS kernels.
The primary determine illustrates the ONNX software program stack, highlighting (in orange) the elements optimized for inference efficiency enchancment on the AWS Graviton3 platform.

The next diagram illustrates the ONNX Runtime EP circulation, highlighting (in orange) the elements optimized for inference efficiency enchancment on the AWS Graviton3 platform.

Allow the optimizations
The optimizations are a part of the ONNX Runtime 1.17.0 launch, and can be found beginning with onnxruntime-1.17.0 python wheels and conda-1.17.0 packages. Optimized int8 kernels are enabled by default, and can be picked up robotically for AWS Graviton3 Processors. Bfloat16 quick math kernels, alternatively, should not enabled by default and wish the next session choices in ONNX Runtime to allow them:
# For C++ purposes
# For Python purposes
Benchmark outcomes
We began with measuring the inference throughput, in queries per second, for the fp32 mannequin with none of our optimizations (utilizing ONNX Runtime 1.16.0), which is marked at 1.0 with the crimson dotted line within the following graph. Then we in contrast the enhancements from bfloat16 quick math kernels from ONNX Runtime 1.17.1 for a similar fp32 mannequin inference. The normalized outcomes are plotted within the graph. You possibly can see that for the BERT, RoBERTa, and GPT2 fashions, the throughput enchancment is as much as 65%. Related enhancements are noticed for the inference latency.

Just like the previous fp32 inference comparability graph, we began with measuring the inference throughput, in queries per second, for the int8 quantized mannequin with none of our optimizations (utilizing ONNX Runtime 1.16.0), which is marked at 1.0 with the crimson dotted line within the following graph. Then we in contrast the enhancements from the optimized MMLA kernels from ONNX Runtime 1.17.1 for a similar mannequin inference. The normalized outcomes are plotted within the graph. You possibly can see that for the BERT, RoBERTa, and GPT2 fashions, the throughput enchancment is as much as 30%. Related enhancements are noticed for the inference latency.

Benchmark setup
We used an AWS Graviton3-based c7g.4xl EC2 occasion with Ubuntu 22.04 based mostly AMI to display the efficiency enhancements with the optimized GEMM kernels from ONNX Runtime. The occasion and the AMI particulars are talked about within the following snippet:
The ONNX Runtime repo gives inference benchmarking scripts for transformers-based language fashions. The scripts help a variety of fashions, frameworks, and codecs. We picked PyTorch-based BERT, RoBERTa, and GPT fashions to cowl the widespread language duties like textual content classification, sentiment evaluation, and predicting the masked phrase. The fashions cowl each encoder and decoder transformers structure.
The next code lists the steps to run inference for the fp32 mannequin with bfloat16 quick math mode and int8 quantized mode utilizing the ONNX Runtime benchmarking script. The script downloads the fashions, exports them to ONNX format, quantizes them into int8 for int8 inference, and runs inference for various sequence lengths and batch sizes. Upon profitable completion of the script, it should print the inference throughput in queries/sec (QPS) and latency in msec together with the system configuration. Consult with the ONNX Runtime Benchmarking script for extra particulars.
Conclusion
On this put up, we mentioned find out how to run ONNX Runtime inference on an AWS Graviton3-based EC2 occasion and find out how to configure the occasion to make use of optimized GEMM kernels. We additionally demonstrated the ensuing speedups. We hope that you’ll give it a attempt!
For those who discover use circumstances the place comparable efficiency beneficial properties should not noticed on AWS Graviton, please open a difficulty on the AWS Graviton Technical Information GitHub to tell us about it.
Concerning the Creator
 Sunita Nadampalli is a Software program Improvement Supervisor at AWS. She leads Graviton software program efficiency optimizations for Machine Studying and HPC workloads. She is keen about open supply software program improvement and delivering high-performance and sustainable software program options with Arm SoCs.
Sunita Nadampalli is a Software program Improvement Supervisor at AWS. She leads Graviton software program efficiency optimizations for Machine Studying and HPC workloads. She is keen about open supply software program improvement and delivering high-performance and sustainable software program options with Arm SoCs.