Incorporate offline and on-line human – machine workflows into your generative AI purposes on AWS
Current advances in synthetic intelligence have led to the emergence of generative AI that may produce human-like novel content material akin to photographs, textual content, and audio. These fashions are pre-trained on huge datasets and, to typically fine-tuned with smaller units of extra job particular knowledge. An essential side of growing efficient generative AI utility is Reinforcement Studying from Human Suggestions (RLHF). RLHF is a method that mixes rewards and comparisons, with human suggestions to pre-train or fine-tune a machine studying (ML) mannequin. Utilizing evaluations and critiques of its outputs, a generative mannequin can proceed to refine and enhance its efficiency. The interaction between Generative AI and human enter paves the best way for extra correct and accountable purposes. You possibly can learn to enhance your LLMs with RLHF on Amazon SageMaker, see Improving your LLMs with RLHF on Amazon SageMaker.
Athough RLHF is the predominant method for incorporating human involvement, it’s not the one obtainable human within the loop method. RLHF is an offline, asynchronous method, the place people present suggestions on the generated outputs, primarily based on enter prompts. People may also add worth by intervening into an present communication occurring between generative AI and customers. As an illustration, as determined by AI or desired by the person, a human will be referred to as into an present dialog and take over the dialogue.
On this submit, we introduce an answer for integrating a “near-real-time human workflow” the place people are prompted by the generative AI system to take motion when a state of affairs or problem arises. This can be a ruled-based methodology that may decide the place, when and the way your skilled groups will be a part of generative AI – person conversations. Your complete dialog on this use case, beginning with generative AI after which bringing in human brokers who take over, is logged in order that the interplay can be utilized as a part of the information base. Along with RLHF, near-real-time human-in-the-loop strategies allow the event of accountable and efficient generative AI purposes.
This weblog submit makes use of RLHF as an offline human-in-the-loop method and the near-real-time human intervention as a web-based method. We current the answer and supply an instance by simulating a case the place the tier one AWS specialists are notified to assist clients utilizing a chat-bot. We use an Amazon Titan mannequin on Amazon Bedrock to search out the sentiment of the client utilizing a Q&A bot after which notifying about detrimental sentiment to a human to take the suitable actions. We even have one other skilled group offering suggestions utilizing Amazon SageMaker GroundTruth on completion high quality for the RLHF primarily based coaching. We used this suggestions to finetune the mannequin deployed on Amazon Bedrock to energy the chat-bot. We offer LangChain and AWS SDK code-snippets, structure and discussions to information you on this essential subject.
SageMaker GroudTruth
SageMaker Floor Reality affords essentially the most complete set of human-in-the-loop capabilities, permitting you to harness the facility of human suggestions throughout the ML lifecycle to enhance the accuracy and relevancy of fashions. You possibly can full a wide range of human-in-the-loop duties with SageMaker Floor Reality, from knowledge technology and annotation to mannequin assessment, customization, and analysis, by means of both a self-service or an AWS-managed providing.
Amazon Bedrock
Amazon Bedrock is a totally managed service that gives a selection of high-performing basis fashions (FMs) from main AI corporations like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon with a single API, together with a broad set of capabilities it’s good to construct generative AI purposes with safety, privateness, and accountable AI. With Amazon Bedrock, you’ll be able to simply experiment with and consider high FMs in your use case, privately customise them together with your knowledge utilizing methods akin to fine-tuning and Retrieval Augmented Technology (RAG), and construct brokers that run duties utilizing your enterprise methods and knowledge sources. As a result of Amazon Bedrock is serverless, you don’t must handle any infrastructure, and you’ll securely combine and deploy generative AI capabilities into your purposes utilizing the AWS providers you’re already aware of.
Instance use-case
On this use case, we work with a generative AI powered Q&A bot, which solutions questions on SageMaker. We constructed the RAG answer as detailed within the following GitHub repo and used SageMaker documentation because the information base. You possibly can construct such chatbots following the identical course of. The interface of the Q&A appears to be like like the next screenshot. Amazon SageMaker Sample and used Amazon SageMaker documentation because the information base. You possibly can simply construct such chatbots following the identical course of. Finally, the interface of the Q&A appears to be like like in Determine 1.

Determine 1. UI and the Chatbot instance utility to check human-workflow situation.
On this situation, we incorporate two human workflows to extend buyer satisfaction. The primary is to ship the interactions to human specialists to evaluate and supply scores. That is an offline course of that’s a part of the RLHF. A second real-time human workflow is initiated as determined by the LLM. We use a easy notification workflow on this submit, however you should utilize any real-time human workflow to take over the AI-human dialog.
Resolution overview
The answer consists of three important modules:
- Close to real-time human engagement workflow
- Offline human suggestions workflow for RLHF
- Nice-tuning and deployment for RLHF
The RLHF and real-time human engagement workflows are impartial. Due to this fact, you should utilize both or each primarily based in your wants. In each eventualities, fine-tuning is a typical last step to include these learnings into LLMs. Within the following sections, we offer the small print about incorporating these steps one after the other and divide the answer into associated sections so that you can select and deploy.
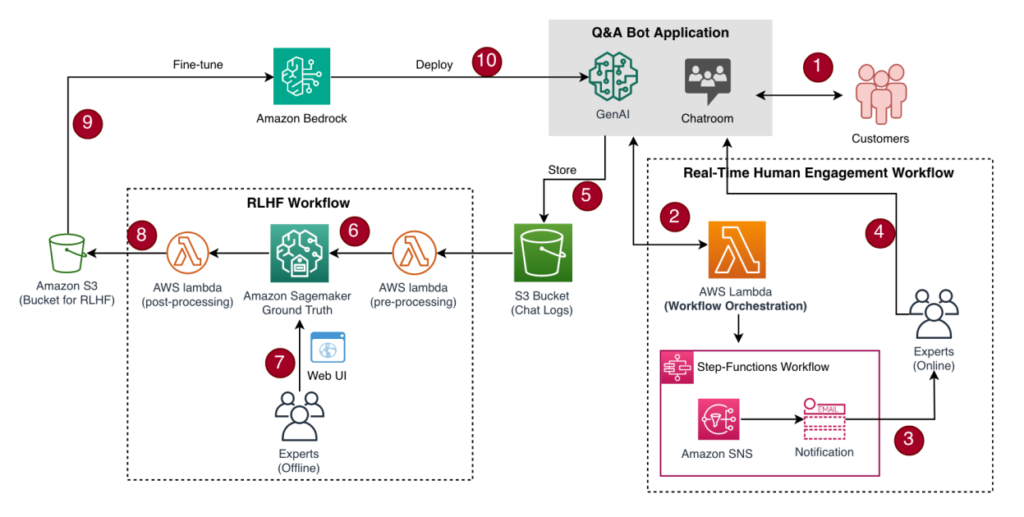
The next diagram illustrates the answer structure and workflow.

Determine 2. Options structure for human-machine workflow modules
Implementation
Stipulations
Our answer is an add-on to an present Generative AI utility. In our instance, we used a Q&A chatbot for SageMaker as defined within the earlier part. Nevertheless, you may also deliver your individual utility. The weblog submit assumes that you’ve got skilled groups or workforce who performs evaluations or be part of workflows.
Construct a close to real-time human engagement workflow workflow
This part presents how an LLM can invoke a human workflow to carry out a predefined exercise. We use AWS Step Capabilities which is a serverless workflow orchestration service that you should utilize for human-machine workflows. In our case, we name the human specialists into motion, in actual time, however you’ll be able to construct any workflow following the tutorial Deploying an Example Human Approval Project.
Choice workflow to set off actual time human engagement
On this situation, the client interacts with the Q&A bot (Step-1 within the earlier structure diagram), and if the interplay exhibits robust detrimental sentiment, it would invoke a pre-existing human workflow (Step-2 in Determine 2). In our case, it’s a easy e-mail notification (Step-3 in Determine 2) however you’ll be able to prolong this interplay akin to together with the specialists into the chat-zone to take over the dialog and extra (Step-4 in Determine 2).
Earlier than we dive deep into the answer, it is very important talk about the workflow logic. The next determine exhibits the small print of the choice workflow. The interplay begins with a buyer communication. Right here, earlier than the LLM gives a solution to the client request, the prompt-chain begins with an inside immediate asking the LLM to go over the client response and search for clear detrimental sentiment. This immediate and inside sentiment evaluation should not seen to buyer. That is an inside chain earlier than continuing with the subsequent steps of which responses could also be mirrored to the client primarily based in your desire. If the sentiment is detrimental, the subsequent step is to set off a pre-built engagement human-workflow whereas the chatbot informs the client concerning the further help coming to assist. In any other case, if the sentiment is impartial or constructive, the traditional response to the client request shall be supplied.
This workflow is a demonstrative instance and you’ll add to or modify it as you like. For instance, you may make every other determination verify, not restricted to sentiment. You can too put together your individual response to the client with the proper prompting the chain in an effort to implement your designed buyer expertise. Right here, our easy instance demonstrates how one can simply construct such immediate in chains and interact exterior present workflows, in our case, it’s a human-workflow utilizing Amazon Bedrock. We additionally use the identical LLM to reply to this inside sentiment immediate verify for simplicity. Nevertheless, you’ll be able to embrace totally different LLMs, which could have been fine-tuned for particular duties, akin to sentiment evaluation, so that you simply depend on a distinct LLM for the Q&A chatbot expertise. Including extra serial steps into chains will increase the latency as a result of now the client question or request is being processed greater than as soon as.

Determine 3. Actual-time (on-line) human workflow triggered by LLM.
Implementing the choice workflow with Amazon Bedrock
To implement the choice workflow, we used Amazon Bedrock and its LangChain integrations. The immediate chain is run by means of SequentialChain from LangChain. As a result of our human workflow is orchestrated with Step Capabilities, we additionally use LangChain’s StepFunction library.
- First, outline the LLM and immediate template:
- Then you definately feed the response from the primary LLM to the subsequent LLM by means of an LLM chain, the place the second instruct is to search out the sentiment of the response. We additionally instruct the LLM to supply 0 as constructive and 1 as detrimental response.
- Run a sequential chain to search out the sentiment:
- If the sentiment is detrimental, the mannequin doesn’t present the response again to buyer, as a substitute it invokes a workflow that can notify a human in loop:
In the event you select to have your human specialists be part of a chat with the customers, you’ll be able to add these interactions of your skilled groups to your information base. This manner, when the identical or comparable problem is raised, the chatbot can use these of their solutions. On this submit, we didn’t present this methodology, however you’ll be able to create a information base in Amazon Bedrock to make use of these human-to-human interactions for future conversations in your chatbot.
Construct an offline human suggestions workflow
On this situation, we assume that the chat transcripts are saved in an Amazon Easy Storage Service (Amazon S3) bucket in JSON format, a typical chat transcript format, for the human specialists to supply annotations and labels on every LLM response. The transcripts are despatched for a labeling task carried out by a labeling workforce utilizing Amazon SageMaker Ground Truth. Nevertheless, in some circumstances, it’s not possible to label all of the transcripts because of useful resource limitations. In these circumstances, it’s possible you’ll wish to randomly pattern the transcripts or use a sample that may be despatched to the labeling workforce primarily based on your corporation case.
Pre-annotation Lambda operate
The method begins with an AWS Lambda operate. The pre-annotation Lambda function is invoked primarily based on chron job or primarily based on an occasion or on-demand. Right here, we use the on-demand possibility. SageMaker Floor Reality sends the Lambda operate a JSON-formatted request to supply particulars concerning the labeling job and the information object. Extra data will be discovered here. Following is the code snippet for the pre-processing Lambda operate:
Customized workflow for SageMaker Floor Reality
The remaining a part of sending the examples, UI, and storing the outcomes of the suggestions are carried out by SageMaker Floor Reality and invoked by the pre-annotation Lambda operate. We use the labeling job with the {custom} template possibility in SageMaker Floor Reality. The workflow permits labelers to fee the relevance of a solution to a query from 1–5, with 5 being essentially the most related. Right here, we assumed a traditional RLHF workflow the place the labeling workforce gives the rating primarily based on their expectation from the LLM on this state of affairs. The next code exhibits an instance:
In our situation, we used the next UI for our labeling employees to attain the entire response given for the immediate. This gives suggestions on the reply to a query given by the chatbot, marking it as 1–5, with 5 being most the related reply to the query.


Determine 4. Two examples from RLHF suggestions UI.
Put up annotation Lambda operate
When all employees full the labeling job, SageMaker Floor Reality invokes the post-annotation Lambda operate with a pointer to the dataset object and the employees’ annotations. This post-processing Lambda operate is mostly used for annotation consolidation, which has SageMaker Floor Reality create a manifest file and uploads it to an S3 bucket for persistently storing consolidated annotations. The next code exhibits the postprocessing Lambda operate:
You should use the output manifest file to additional fine-tune your LLM mannequin, as detailed within the subsequent part. The next code is a snippet of the created manifest file:
Nice-tune the LLM utilizing RLHF
To show RLHF in each close to real-time and offline workflows, we collected 50 human-annotated samples utilizing SageMaker Floor Reality. The information is used for RLHF coaching on a Flan-T5 XL mannequin by PEFT/LoRA with 8-bit quantization:
The coaching makes use of the training fee 1e-5 for 10 epochs, and the batch dimension = 1 to make use of one pattern at a time.
As a result of there are solely 50 human-annotated samples collected from SageMaker Floor Reality, it’s not ample to coach a reward mannequin for reinforcement studying. Due to this fact, we determined to take the annotated analysis rating for every pattern and use them because the reward worth within the reinforcement studying course of. This must be shut sufficient to the reward worth generated from a reward mannequin. Our experiment confirmed that this methodology is efficient for a small coaching set. You possibly can see the curve of the coaching course of within the following chart.

Determine 5. Reward/imply chart
After the coaching, we changed the Flan-T5 basis mannequin within the AWS help chatbot with the RLHF skilled mannequin. Within the following examples, you’ll be able to observe that the response high quality after RLHF is improved and the solutions are extra complete and comprise extra helpful data:
- Query: How does SageMaker shield my knowledge?
Response earlier than RLHF: SageMaker shops code in ML storage volumes
Response after RLHF: SageMaker shops code in ML storage volumes, secured by safety teams and optionally encrypted at relaxation. - Query: What’s Amazon SageMaker?
Response earlier than RLHF: AWS SageMaker is a machine studying service that permits you to prepare and deploy machine studying fashions within the cloud.
Response after RLHF: A totally managed service to arrange knowledge and construct, prepare, and deploy machine studying (ML) fashions for any use case with totally managed infrastructure, instruments, and workflows.
Clear up
To scrub up your assets, first begin by stopping and deactivating any lively human workflow or fine-tuning jobs. Eradicating the immediate chaining is an effective begin for de-coupling the workflows out of your present utility. Then, proceed by deleting the assets for the real-time human workflow manually. Lastly, delete the RLHF assets. In the event you created a brand new Q&A chatbot utility, then first cease after which delete the assets used for the Q&A chatbot a part of the blogpost.
Conclusion
This submit introduced options for incorporating each offline and on-line human workflows into generative AI purposes on AWS. The offline human suggestions workflow makes use of SageMaker Floor Reality to gather human evaluations on chatbot responses. These evaluations are used to supply reward indicators for fine-tuning the chatbot’s underlying language mannequin with RLHF. The net human workflow makes use of LangChain and Step Capabilities to invoke real-time human intervention primarily based on sentiment evaluation of the chatbot responses. This permits human specialists to seamlessly take over or step into conversations when the AI reaches its limits. This functionality is essential for implementations that require utilizing your present skilled groups in crucial, delicate, or decided matters and themes. Collectively, these human-in-the-loop methods, offline RLHF workflows, and on-line real-time workflows allow you to develop accountable and strong generative AI purposes.
The supplied options combine a number of AWS providers, like Amazon Bedrock, SageMaker, SageMaker Floor Reality, Lambda, Amazon S3, and Step Capabilities. By following the architectures, code snippets, and examples mentioned on this submit, you can begin incorporating human oversight into your individual generative AI purposes on AWS. This paves the best way in direction of higher-quality completions and constructing reliable AI options that complement and collaborate with human intelligence.
Constructing generative AI purposes is easy with Amazon Bedrock. We advocate beginning your experiments following this Quick Start with Bedrock.
Concerning the Authors
 Tulip Gupta is a Senior Options Architect at Amazon Net Providers. She works with Amazon media and leisure (M&E) clients to design, construct, and deploy know-how options on AWS, and has a specific curiosity in Gen AI and machine studying focussed on M&E. She assists clients in adopting greatest practices whereas deploying options in AWS. Linkedin
Tulip Gupta is a Senior Options Architect at Amazon Net Providers. She works with Amazon media and leisure (M&E) clients to design, construct, and deploy know-how options on AWS, and has a specific curiosity in Gen AI and machine studying focussed on M&E. She assists clients in adopting greatest practices whereas deploying options in AWS. Linkedin
 Burak Gozluku is a Principal AI/ML Specialist Options Architect situated in Boston, MA. He helps strategic clients undertake AWS applied sciences and particularly Generative AI options to realize their enterprise targets. Burak has a PhD in Aerospace Engineering from METU, an MS in Methods Engineering, and a post-doc in system dynamics from MIT in Cambridge, MA. Burak remains to be a analysis affiliate in MIT. Burak is keen about yoga and meditation.
Burak Gozluku is a Principal AI/ML Specialist Options Architect situated in Boston, MA. He helps strategic clients undertake AWS applied sciences and particularly Generative AI options to realize their enterprise targets. Burak has a PhD in Aerospace Engineering from METU, an MS in Methods Engineering, and a post-doc in system dynamics from MIT in Cambridge, MA. Burak remains to be a analysis affiliate in MIT. Burak is keen about yoga and meditation.
 Yunfei bai is a Senior Options Architect at AWS. With a background in AI/ML, knowledge science, and analytics, Yunfei helps clients undertake AWS providers to ship enterprise outcomes. He designs AI/ML and knowledge analytics options that overcome advanced technical challenges and drive strategic targets. Yunfei has a PhD in Digital and Electrical Engineering. Outdoors of labor, Yunfei enjoys studying and music.
Yunfei bai is a Senior Options Architect at AWS. With a background in AI/ML, knowledge science, and analytics, Yunfei helps clients undertake AWS providers to ship enterprise outcomes. He designs AI/ML and knowledge analytics options that overcome advanced technical challenges and drive strategic targets. Yunfei has a PhD in Digital and Electrical Engineering. Outdoors of labor, Yunfei enjoys studying and music.
 Rachna Chadha is a Principal Resolution Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that moral and accountable use of AI can enhance society in future and produce economical and social prosperity. In her spare time, Rachna likes spending time together with her household, mountaineering and listening to music.
Rachna Chadha is a Principal Resolution Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that moral and accountable use of AI can enhance society in future and produce economical and social prosperity. In her spare time, Rachna likes spending time together with her household, mountaineering and listening to music.





