Methods to Run A number of LLMs Regionally Utilizing Llama-Swap on a Single Server


Picture by Creator | Ideogram
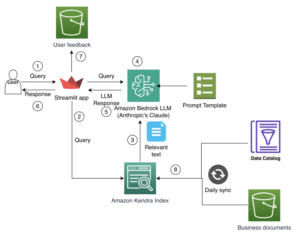
Operating a number of giant language fashions may be helpful, whether or not for evaluating mannequin outputs, establishing a fallback in case one fails, or customizing conduct (like utilizing one mannequin for coding and one other for technical writing). That is how we regularly use LLMs in follow. There are apps like poe.com that provide this type of setup. It’s a single platform the place you may run a number of LLMs. However what if you wish to do all of it regionally, save on API prices, and preserve your knowledge personal?
Nicely, that’s the place the true drawback exhibits up. Setting this up normally means juggling completely different ports, working separate processes, and switching between them manually. Not supreme.
That’s precisely the ache Llama-Swap solves. It’s an open-source proxy server that’s tremendous light-weight (only a single binary), and it helps you to change between a number of native LLMs simply. In easy phrases, it listens for OpenAI-style API calls in your machine and robotically begins or stops the suitable mannequin server primarily based on the mannequin you request. Let’s break down the way it works and stroll by means of a step-by-step setup to get it working in your native machine.
# How Llama-Swap Works
Conceptually, Llama-Swap sits in entrance of your LLM servers as a wise router. When an API request arrives (e.g., a POST /v1/chat/completions name), it appears to be like on the "mannequin" subject within the JSON payload. It then hundreds the suitable server course of for that mannequin, shutting down every other mannequin if wanted. For instance, when you first request mannequin "A" after which request mannequin "B", Llama-Swap will robotically cease the server for “A” and begin the server for “B” so that every request is served by the proper mannequin. This dynamic swapping occurs transparently, so shoppers see the anticipated response with out worrying concerning the underlying processes.
By default, Llama-Swap permits just one mannequin to run at a time (it unloads others when switching). Nevertheless, its Teams function helps you to change this conduct. A gaggle can listing a number of fashions and management their swap conduct. For instance, setting swap: false in a gaggle means all group members can run collectively with out unloading. In follow, you would possibly use one group for heavyweight fashions (just one lively at a time) and one other “parallel” group for small fashions you need working concurrently. This offers you full management over useful resource utilization and concurrency on a single server.
# Stipulations
Earlier than getting began, guarantee your system has the next:
- Python 3 (>=3.8): Wanted for primary scripting and tooling.
- Homebrew (on macOS): Makes putting in LLM runtimes straightforward. For instance, you may set up the llama.cpp server with:
This gives the llama-server binary for internet hosting fashions regionally.
- llama.cpp (
llama-server): The OpenAI-compatible server binary (put in by way of Homebrew above, or constructed from supply) that truly runs the LLM mannequin. - Hugging Face CLI: For downloading fashions on to your native machine with out logging into the positioning or manually navigating mannequin pages. Set up it utilizing:
pip set up -U "huggingface_hub[cli]"
- {Hardware}: Any trendy CPU will work. For quicker inference, a GPU is helpful. (On Apple Silicon Macs, you may run on the CPU or attempt PyTorch’s MPS backend for supported fashions. On Linux/Home windows with NVIDIA GPUs, you need to use Docker/CUDA containers for acceleration.)
- Docker (Non-compulsory): To run the pre-built Docker photos. Nevertheless, I selected to not use this for this information as a result of these photos are designed primarily for x86 (Intel/AMD) techniques and don’t work reliably on Apple Silicon (M1/M2) Macs. As an alternative, I used the bare-metal set up methodology, which works instantly on macOS with none container overhead.
In abstract, you’ll want a Python atmosphere and an area LLM server (just like the `llama.cpp` server). We’ll use these to host two instance fashions on one machine.
# Step-by-Step Directions
// 1. Putting in Llama-Swap
Obtain the newest Llama-Swap launch on your OS from the GitHub releases page. For instance, I may see v126 as the newest launch. Run the next instructions:
# Step 1: Obtain the proper file
curl -L -o llama-swap.tar.gz
https://github.com/mostlygeek/llama-swap/releases/obtain/v126/llama-swap_126_darwin_arm64.tar.gz
Output:
% Whole % Acquired % Xferd Common Pace Time Time Time Present
Dload Add Whole Spent Left Pace
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 3445k 100 3445k 0 0 1283k 0 0:00:02 0:00:02 --:--:-- 5417k
Now, extract the file, make it executable, and check it by checking the model:
# Step 2: Extract it
tar -xzf llama-swap.tar.gz
# Step 3: Make it executable
chmod +x llama-swap
# Step 4: Check it
./llama-swap --version
Output:
model: 126 (591a9cdf4d3314fe4b3906e939a17e76402e1655), constructed at 2025-06-16T23:53:50Z
// 2. Downloading and Making ready Two or Extra LLMs
Select two instance fashions to run. We’ll use Qwen2.5-0.5B and SmolLM2-135M (small fashions) from Hugging Face. You want the mannequin information (in GGUF or related format) in your machine. For instance, utilizing the Hugging Face CLI:
mkdir -p ~/llm-models
huggingface-cli obtain bartowski/SmolLM2-135M-Instruct-GGUF
--include "SmolLM2-135M-Instruct-Q4_K_M.gguf" --local-dir ~/llm-models
huggingface-cli obtain bartowski/Qwen2.5-0.5B-Instruct-GGUF
--include "Qwen2.5-0.5B-Instruct-Q4_K_M.gguf" --local-dir ~/llm-models
It will:
- Create the listing
llm-modelsin your consumer’s house folder - Obtain the GGUF mannequin information safely into that folder. After obtain, you may verify it’s there:
Output:
SmolLM2-135M-Instruct-Q4_K_M.gguf
Qwen2.5-0.5B-Instruct-Q4_K_M.gguf
// 3. Making a Llama-Swap Configuration
Llama-Swap makes use of a single YAML file to outline fashions and server instructions. Create a config.yaml file with contents like this:
fashions:
"smollm2":
cmd: |
llama-server
--model /path/to/fashions/llm-models/SmolLM2-135M-Instruct-Q4_K_M.gguf
--port ${PORT}
"qwen2.5":
cmd: |
llama-server
--model /path/to/fashions/llm-models/Qwen2.5-0.5B-Instruct-Q4_K_M.gguf
--port ${PORT}
Exchange /path/to/fashions/ together with your precise native path. Every entry below fashions: provides an ID (like "qwen2.5") and a shell cmd: to run its server. We use llama-server (from llama.cpp) with --model pointing to the GGUF file and --port ${PORT}. The ${PORT} macro tells Llama-Swap to assign a free port to every mannequin robotically. The teams part is non-obligatory. I’ve omitted it for this instance, so by default, Llama-Swap will solely run one mannequin at a time. You possibly can customise many choices per mannequin (aliases, timeouts, and so forth.) on this configuration. For extra particulars on obtainable choices, see the Full Configuration Example File.
// 4. Operating Llama-Swap
With the binary and config.yaml prepared, begin Llama-Swap pointing to your config:
./llama-swap --config config.yaml --listen 127.0.0.1:8080
This launches the proxy server on localhost:8080. It would learn config.yaml and (at first) load no fashions till the primary request arrives. Llama-Swap will now deal with API requests on port 8080, forwarding them to the suitable underlying llama-server course of primarily based on the "mannequin" parameter.
// 5. Interacting with Your Fashions
Now you can also make OpenAI-style API calls to check every mannequin. Set up jq when you don’t have it earlier than working the instructions under:
// Utilizing Qwen2.5
curl -s http://localhost:8080/v1/completions
-H "Content material-Kind: utility/json"
-H "Authorization: Bearer no-key"
-d '{
"mannequin": "qwen2.5",
"immediate": "Person: What's Python?nAssistant:",
"max_tokens": 100
}' | jq '.selections[0].textual content'
Output:
"Python is a well-liked general-purpose programming language. It's straightforward to be taught, has a big normal library, and is suitable with many working techniques. Python is used for net growth, knowledge evaluation, scientific computing, and machine studying.nPython is a language that's common for net growth because of its simplicity, versatility and its use of contemporary options. It's utilized in a variety of functions together with net growth, knowledge evaluation, scientific computing, machine studying and extra. Python is a well-liked language within the"
// Utilizing SmolLM2
curl -s http://localhost:8080/v1/completions
-H "Content material-Kind: utility/json"
-H "Authorization: Bearer no-key"
-d '{
"mannequin": "smollm2",
"immediate": "Person: What's Python?nAssistant:",
"max_tokens": 100
}' | jq '.selections[0].textual content'
Output:
"Python is a high-level programming language designed for simplicity and effectivity. It is recognized for its readability, syntax, and flexibility, making it a preferred alternative for inexperienced persons and builders alike.nnWhat is Python?"
Every mannequin will reply based on its coaching. The fantastic thing about Llama-Swap is you don’t should restart something manually — simply change the "mannequin" subject, and it handles the remaining. As proven within the examples above, you may see:
qwen2.5: a extra verbose, technical responsesmollm2: an easier, extra concise reply
That confirms Llama-Swap is routing requests to the proper mannequin!
# Conclusion
Congratulations! You have arrange Llama-Swap to run two LLMs on one machine, and now you can change between them on the fly by way of API calls. We put in a proxy, ready a YAML configuration with two fashions, and noticed how Llama-Swap routes requests to the proper backend.
Subsequent steps: You possibly can increase this to incorporate:
- Bigger fashions (like
TinyLlama,Phi-2,Mistral) - Teams for concurrent serving
- Integration with LangChain, FastAPI, or different frontends
Have enjoyable exploring completely different fashions and configurations!
Kanwal Mehreen is a machine studying engineer and a technical author with a profound ardour for knowledge science and the intersection of AI with medication. She co-authored the book “Maximizing Productiveness with ChatGPT”. As a Google Technology Scholar 2022 for APAC, she champions range and educational excellence. She’s additionally acknowledged as a Teradata Variety in Tech Scholar, Mitacs Globalink Analysis Scholar, and Harvard WeCode Scholar. Kanwal is an ardent advocate for change, having based FEMCodes to empower girls in STEM fields.