Remodeling credit score selections utilizing generative AI with Wealthy Knowledge Co and AWS
This submit is co-written with Gordon Campbell, Charles Guan, and Hendra Suryanto from RDC.
The mission of Rich Data Co (RDC) is to broaden entry to sustainable credit score globally. Its software-as-a-service (SaaS) answer empowers main banks and lenders with deep buyer insights and AI-driven decision-making capabilities.
Making credit score selections utilizing AI will be difficult, requiring knowledge science and portfolio groups to synthesize complicated subject material data and collaborate productively. To unravel this problem, RDC used generative AI, enabling groups to make use of its answer extra successfully:
- Knowledge science assistant – Designed for knowledge science groups, this agent assists groups in growing, constructing, and deploying AI fashions inside a regulated surroundings. It goals to spice up group effectivity by answering complicated technical queries throughout the machine studying operations (MLOps) lifecycle, drawing from a complete data base that features surroundings documentation, AI and knowledge science experience, and Python code technology.
- Portfolio assistant – Designed for portfolio managers and analysts, this agent facilitates pure language inquiries about mortgage portfolios. It offers important insights on efficiency, danger exposures, and credit score coverage alignment, enabling knowledgeable industrial selections with out requiring in-depth evaluation abilities. The assistant is adept at high-level questions (resembling figuring out high-risk segments or potential development alternatives) and one-time queries, permitting the portfolio to be diversified.
On this submit, we talk about how RDC makes use of generative AI on Amazon Bedrock to construct these assistants and speed up its total mission of democratizing entry to sustainable credit score.
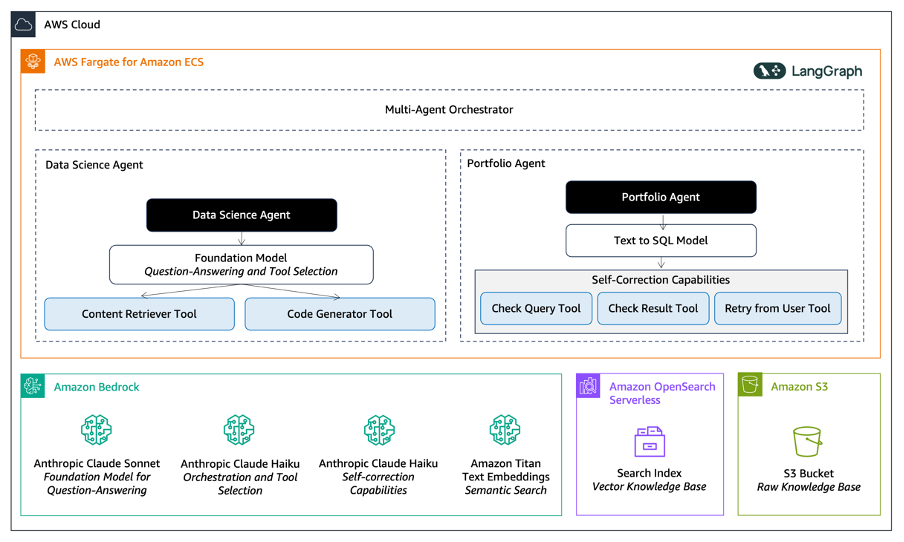
Resolution overview: Constructing a multi-agent generative AI answer
We started with a fastidiously crafted analysis set of over 200 prompts, anticipating widespread consumer questions. Our preliminary strategy mixed immediate engineering and conventional Retrieval Augmented Generation (RAG). Nonetheless, we encountered a problem: accuracy fell beneath 90%, particularly for extra complicated questions.
To beat the problem, we adopted an agentic strategy, breaking down the issue into specialised use instances. This technique outfitted us to align every activity with essentially the most appropriate foundation model (FM) and instruments. Our multi-agent framework is orchestrated utilizing LangGraph, and it consisted of:
- Orchestrator – The orchestrator is answerable for routing consumer inquiries to the suitable agent. On this instance, we begin with the info science or portfolio agent. Nonetheless, we envision many extra brokers sooner or later. The orchestrator may also use consumer context, such because the consumer’s function, to find out routing to the suitable agent.
- Agent – The agent is designed for a specialised activity. It’s outfitted with the suitable FM for the duty and the required instruments to carry out actions and entry data. It could additionally deal with multiturn conversations and orchestrate a number of calls to the FM to achieve an answer.
- Instruments – Instruments lengthen agent capabilities past the FM. They supply entry to exterior knowledge and APIs or allow particular actions and computation. To effectively use the mannequin’s context window, we assemble a software selector that retrieves solely the related instruments based mostly on the data within the agent state. This helps simplify debugging within the case of errors, finally making the agent more practical and cost-efficient.
This strategy offers us the correct software for the correct job. It enhances our capacity to deal with complicated queries effectively and precisely whereas offering flexibility for future enhancements and brokers.
The next picture is a high-level structure diagram of the answer.

Knowledge science agent: RAG and code technology
To spice up productiveness of information science groups, we targeted on speedy comprehension of superior data, together with industry-specific fashions from a curated data base. Right here, RDC offers an built-in growth surroundings (IDE) for Python coding, catering to numerous group roles. One function is mannequin validator, who rigorously assesses whether or not a mannequin aligns with financial institution or lender insurance policies. To assist the evaluation course of, we designed an agent with two instruments:
- Content material retriever software – Amazon Bedrock Knowledge Bases powers our clever content material retrieval by way of a streamlined RAG implementation. The service robotically converts textual content paperwork to their vector illustration utilizing Amazon Titan Text Embeddings and shops them in Amazon OpenSearch Serverless. As a result of the data is huge, it performs semantic chunking, ensuring that the data is organized by subject and may match throughout the FM’s context window. When customers work together with the agent, Amazon Bedrock Knowledge Bases utilizing OpenSearch Serverless offers quick, in-memory semantic search, enabling the agent to retrieve essentially the most related chunks of information for related and contextual responses to customers.
- Code generator software – With code technology, we chosen Anthropic’s Claude model on Amazon Bedrock as a result of its inherent capacity to grasp and generate code. This software is grounded to reply queries associated to knowledge science and may generate Python code for fast implementation. It’s additionally adept at troubleshooting coding errors.
Portfolio agent: Textual content-to-SQL and self-correction
To spice up the productiveness of credit score portfolio groups, we targeted on two key areas. For portfolio managers, we prioritized high-level industrial insights. For analysts, we enabled deep-dive knowledge exploration. This strategy empowered each roles with speedy understanding and actionable insights, streamlining decision-making processes throughout groups.
Our answer required pure language understanding of structured portfolio knowledge saved in Amazon Aurora. This led us to base our answer on a text-to-SQL mannequin to effectively bridge the hole between pure language and SQL.
To scale back errors and sort out complicated queries past the mannequin’s capabilities, we developed three instruments utilizing Anthropic’s Claude mannequin on Amazon Bedrock for self-correction:
- Examine question software – Verifies and corrects SQL queries, addressing widespread points resembling knowledge kind mismatches or incorrect operate utilization
- Examine outcome software – Validates question outcomes, offering relevance and prompting retries or consumer clarification when wanted
- Retry from consumer software – Engages customers for added data when queries are too broad or lack element, guiding the interplay based mostly on database data and consumer enter
These instruments function in an agentic system, enabling correct database interactions and improved question outcomes by way of iterative refinement and consumer engagement.
To enhance accuracy, we examined mannequin fine-tuning, coaching the mannequin on widespread queries and context (resembling database schemas and their definitions). This strategy reduces inference prices and improves response instances in comparison with prompting at every name. Utilizing Amazon SageMaker JumpStart, we fine-tuned Meta’s Llama model by offering a set of anticipated prompts, meant solutions, and related context. Amazon SageMaker Jumpstart presents an economical different to third-party fashions, offering a viable pathway for future purposes. Nonetheless, we didn’t find yourself deploying the fine-tuned mannequin as a result of we experimentally noticed that prompting with Anthropic’s Claude mannequin offered higher generalization, particularly for complicated questions. To scale back operational overhead, we may even consider structured data retrieval on Amazon Bedrock Knowledge Bases.
Conclusion and subsequent steps with RDC
To expedite growth, RDC collaborated with AWS Startups and the AWS Generative AI Innovation Center. Via an iterative strategy, RDC quickly enhanced its generative AI capabilities, deploying the preliminary model to manufacturing in simply 3 months. The answer efficiently met the stringent safety requirements required in regulated banking environments, offering each innovation and compliance.
“The mixing of generative AI into our answer marks a pivotal second in our mission to revolutionize credit score decision-making. By empowering each knowledge scientists and portfolio managers with AI assistants, we’re not simply bettering effectivity—we’re remodeling how monetary establishments strategy lending.”
–Gordon Campbell, Co-Founder & Chief Buyer Officer at RDC
RDC envisions generative AI enjoying a big function in boosting the productiveness of the banking and credit score {industry}. By utilizing this know-how, RDC can present key insights to prospects, enhance answer adoption, speed up the mannequin lifecycle, and cut back the client assist burden. Trying forward, RDC plans to additional refine and broaden its AI capabilities, exploring new use instances and integrations because the {industry} evolves.
For extra details about how one can work with RDC and AWS and to grasp how we’re supporting banking prospects around the globe to make use of AI in credit score selections, contact your AWS Account Supervisor or go to Rich Data Co.
For extra details about generative AI on AWS, check with the next assets:
Concerning the Authors
 Daniel Wirjo is a Options Architect at AWS, targeted on FinTech and SaaS startups. As a former startup CTO, he enjoys collaborating with founders and engineering leaders to drive development and innovation on AWS. Outdoors of labor, Daniel enjoys taking walks with a espresso in hand, appreciating nature, and studying new concepts.
Daniel Wirjo is a Options Architect at AWS, targeted on FinTech and SaaS startups. As a former startup CTO, he enjoys collaborating with founders and engineering leaders to drive development and innovation on AWS. Outdoors of labor, Daniel enjoys taking walks with a espresso in hand, appreciating nature, and studying new concepts.
 Xuefeng Liu leads a science group on the AWS Generative AI Innovation Heart within the Asia Pacific areas. His group companions with AWS prospects on generative AI tasks, with the objective of accelerating prospects’ adoption of generative AI.
Xuefeng Liu leads a science group on the AWS Generative AI Innovation Heart within the Asia Pacific areas. His group companions with AWS prospects on generative AI tasks, with the objective of accelerating prospects’ adoption of generative AI.
 Iman Abbasnejad is a pc scientist on the Generative AI Innovation Heart at Amazon Internet Companies (AWS) engaged on Generative AI and complicated multi-agents techniques.
Iman Abbasnejad is a pc scientist on the Generative AI Innovation Heart at Amazon Internet Companies (AWS) engaged on Generative AI and complicated multi-agents techniques.
 Gordon Campbell is the Chief Buyer Officer and Co-Founding father of RDC, the place he leverages over 30 years in enterprise software program to drive RDC’s main AI Decisioning platform for enterprise and industrial lenders. With a confirmed observe file in product technique and growth throughout three world software program corporations, Gordon is dedicated to buyer success, advocacy, and advancing monetary inclusion by way of knowledge and AI.
Gordon Campbell is the Chief Buyer Officer and Co-Founding father of RDC, the place he leverages over 30 years in enterprise software program to drive RDC’s main AI Decisioning platform for enterprise and industrial lenders. With a confirmed observe file in product technique and growth throughout three world software program corporations, Gordon is dedicated to buyer success, advocacy, and advancing monetary inclusion by way of knowledge and AI.
 Charles Guan is the Chief Know-how Officer and Co-founder of RDC. With greater than 20 years of expertise in knowledge analytics and enterprise purposes, he has pushed technological innovation throughout each the private and non-private sectors. At RDC, Charles leads analysis, growth, and product development—collaborating with universities to leverage superior analytics and AI. He’s devoted to selling monetary inclusion and delivering optimistic group affect worldwide.
Charles Guan is the Chief Know-how Officer and Co-founder of RDC. With greater than 20 years of expertise in knowledge analytics and enterprise purposes, he has pushed technological innovation throughout each the private and non-private sectors. At RDC, Charles leads analysis, growth, and product development—collaborating with universities to leverage superior analytics and AI. He’s devoted to selling monetary inclusion and delivering optimistic group affect worldwide.
 Hendra Suryanto is the Chief Knowledge Scientist at RDC with greater than 20 years of expertise in knowledge science, massive knowledge, and enterprise intelligence. Earlier than becoming a member of RDC, he served as a Lead Knowledge Scientist at KPMG, advising shoppers globally. At RDC, Hendra designs end-to-end analytics options inside an Agile DevOps framework. He holds a PhD in Synthetic Intelligence and has accomplished postdoctoral analysis in machine studying.
Hendra Suryanto is the Chief Knowledge Scientist at RDC with greater than 20 years of expertise in knowledge science, massive knowledge, and enterprise intelligence. Earlier than becoming a member of RDC, he served as a Lead Knowledge Scientist at KPMG, advising shoppers globally. At RDC, Hendra designs end-to-end analytics options inside an Agile DevOps framework. He holds a PhD in Synthetic Intelligence and has accomplished postdoctoral analysis in machine studying.






