Mitigating threat: AWS spine community visitors prediction utilizing GraphStorm

The AWS international spine community is the important basis enabling dependable and safe service supply throughout AWS Areas. It connects our 34 launched Areas (with 108 Availability Zones), our greater than 600 Amazon CloudFront POPs, and 41 Native Zones and 29 Wavelength Zones, offering high-performance, ultralow-latency connectivity for mission-critical providers throughout 245 nations and territories.
This community requires steady administration by means of planning, upkeep, and real-time operations. Though most adjustments happen with out incident, the dynamic nature and international scale of this technique introduce the potential for unexpected impacts on efficiency and availability. The complicated interdependencies between community parts make it difficult to foretell the total scope and timing of those potential impacts, necessitating superior threat evaluation and mitigation methods.
On this publish, we present how you should use our enterprise graph machine studying (GML) framework GraphStorm to unravel prediction challenges on large-scale complicated networks impressed by our practices of exploring GML to mitigate the AWS spine community congestion threat.
Drawback assertion
At its core, the issue we’re addressing is tips on how to safely handle and modify a posh, dynamic community whereas minimizing service disruptions (similar to the danger of congestion, web site isolation, or elevated latency). Particularly, we have to predict how adjustments to at least one a part of the AWS international spine community may have an effect on visitors patterns and efficiency throughout all the system. Within the case of congestive threat for instance, we need to decide whether or not taking a hyperlink out of service is protected underneath various calls for. Key questions embrace:
- Can the community deal with buyer visitors with remaining capability?
- How lengthy earlier than congestion seems?
- The place will congestion seemingly happen?
- How a lot visitors is susceptible to being dropped?
This problem of predicting and managing community disruptions just isn’t distinctive to telecommunication networks. Comparable issues come up in varied complicated networked techniques throughout completely different industries. As an illustration, provide chain networks face comparable challenges when a key provider or distribution middle goes offline, necessitating fast reconfiguration of logistics. In air visitors management techniques, the closure of an airport or airspace can result in complicated rerouting situations affecting a number of flight paths. In these circumstances, the elemental downside stays related: tips on how to predict and mitigate the ripple results of localized adjustments in a posh, interconnected system the place the relationships between parts should not all the time easy or instantly obvious.
In the present day, groups at AWS function a variety of security techniques that preserve a excessive operational readiness bar, and work relentlessly on bettering security mechanisms and threat evaluation processes. We conduct a rigorous planning course of on a recurring foundation to tell how we design and construct our community, and preserve resiliency underneath varied situations. We depend on simulations at a number of ranges of element to eradicate dangers and inefficiencies from our designs. As well as, each change (regardless of how small) is completely examined earlier than it’s deployed into the community.
Nonetheless, on the scale and complexity of the AWS spine community, simulation-based approaches face challenges in real-time operational settings (similar to costly and time-consuming computational course of), which impression the effectivity of community upkeep. To enrich simulations, we’re subsequently investing in data-driven methods that may scale to the dimensions of the AWS spine community with out a proportional enhance in computational time. On this publish, we share our progress alongside this journey of model-assisted community operations.
Strategy
In recent times, GML strategies have achieved state-of-the-art efficiency in traffic-related duties, similar to routing, load balancing, and useful resource allocation. Particularly, graph neural networks (GNNs) display a bonus over classical time sequence forecasting, as a consequence of their capability to seize construction info hidden in community topology and their capability to generalize to unseen topologies when networks are dynamic.
On this publish, we body the bodily community as a heterogeneous graph, the place nodes characterize entities within the networked system, and edges characterize each calls for between endpoints and precise visitors flowing by means of the community. We then apply GNN fashions to this heterogeneous graph for an edge regression job.
In contrast to frequent GML edge regression that predicts a single worth for an edge, we have to predict a time sequence of visitors on every edge. For this, we undertake the sliding-window prediction methodology. Throughout coaching, we begin from a time level T and use historic information in a time window of dimension W to foretell the worth at T+1. We then slide the window one step forward to foretell the worth at T+2, and so forth. Throughout inference, we use predicted values slightly than precise values to kind the inputs in a time window as we slide the window ahead, making the strategy an autoregressive sliding-window one. For a extra detailed rationalization of the rules behind this methodology, please discuss with this link.
We practice GNN fashions with historic demand and visitors information, together with different options (community incidents and upkeep occasions) by following the sliding-window methodology. We then use the educated mannequin to foretell future visitors on all hyperlinks of the spine community utilizing the autoregressive sliding-window methodology as a result of in an actual utility, we are able to solely use the anticipated values for next-step predictions.
Within the subsequent part, we present the results of adapting this methodology to AWS spine visitors forecasting, for bettering operational security.
Making use of GNN-based visitors prediction to the AWS spine community
For the spine community visitors prediction utility at AWS, we have to ingest a variety of information sources into the GraphStorm framework. First, we want the community topology (the graph). In our case, that is composed of gadgets and bodily interfaces which might be logically grouped into particular person websites. One web site might comprise dozens of gadgets and a whole bunch of interfaces. The perimeters of the graph characterize the fiber connections between bodily interfaces on the gadgets (these are the OSI layer 2 hyperlinks). For every interface, we measure the outgoing visitors utilization in bps and as a proportion of the hyperlink capability. Lastly, now we have a visitors matrix that holds the visitors calls for between any two pairs of web sites. That is obtained utilizing circulate telemetry.
The last word purpose of our utility is to enhance security on the community. For this goal, we measure the efficiency of visitors prediction alongside three dimensions:
- First, we have a look at absolutely the proportion error between the precise and predicted visitors on every hyperlink. We would like this error metric to be low to guarantee that our mannequin truly realized the routing sample of the community underneath various calls for and a dynamic topology.
- Second, we quantify the mannequin’s propensity for under-predicting visitors. It’s important to restrict this habits as a lot as doable as a result of predicting visitors under its precise worth can result in elevated operational threat.
- Third, we quantify the mannequin’s propensity for over-predicting visitors. Though this isn’t as important because the second metric, it’s nonetheless necessary to deal with over-predictions as a result of they decelerate upkeep operations.
We share a few of our outcomes for a take a look at performed on 85 spine segments, over a 2-week interval. Our visitors predictions are at a 5-minute time decision. We educated our mannequin on 2 weeks of knowledge and ran the inference on a 6-hour time window. Utilizing GraphStorm, coaching took lower than 1 hour on an m8g.12xlarge occasion for all the community, and inference took underneath 2 seconds per section, for all the 6-hour window. In distinction, simulation-based visitors prediction requires dozens of cases for the same community pattern, and every simulation takes greater than 100 seconds to undergo the assorted situations.
When it comes to absolutely the proportion error, we discover that our p90 (ninetieth percentile) to be on the order of 13%. Which means that 90% of the time, the mannequin’s prediction is lower than 13% away from the precise visitors. As a result of that is an absolute metric, the mannequin’s prediction could be both above or under the community visitors. In comparison with classical time sequence forecasting with XGBoost, our strategy yields a 35% enchancment.
Subsequent, we think about on a regular basis intervals wherein the mannequin under-predicted visitors. We discover the p90 on this case to be under 5%. Which means that, in 90% of the circumstances when the mannequin under-predicts visitors, the deviation from the precise visitors is lower than 5%.
Lastly, we have a look at on a regular basis intervals wherein the mannequin over-predicted visitors (once more, that is to judge permissiveness for upkeep operations). We discover the p90 on this case to be under 14%. Which means that, in 90% of the circumstances when the mannequin over-predicted visitors, the deviation from the precise visitors was lower than 14%.
These measurements display how we are able to tune the efficiency of the mannequin to worth security above the tempo of routine operations.
Lastly, on this part, we offer a visible illustration of the mannequin output round a upkeep operation. This operation consists of eradicating a section of the community out of service for upkeep. As proven within the following determine, the mannequin is ready to predict the altering nature of visitors on two completely different segments: one the place visitors will increase sharply on account of the operation (left) and the second referring to the section that was taken out of service and the place visitors drops to zero (proper).
 |
 |
An instance for GNN-based visitors prediction with artificial information
Sadly, we are able to’t share the small print concerning the AWS spine community together with the info we used to coach the mannequin. To nonetheless give you some code that makes it easy to get began fixing your community prediction issues, we share an artificial visitors prediction downside as a substitute. We now have created a Jupyter notebook that generates artificial airport visitors information. This dataset simulates a worldwide air transportation community utilizing main world airports, creating fictional airways and flights with predefined capacities. The next determine illustrates these main airports and the simulated flight routes derived from our artificial information.
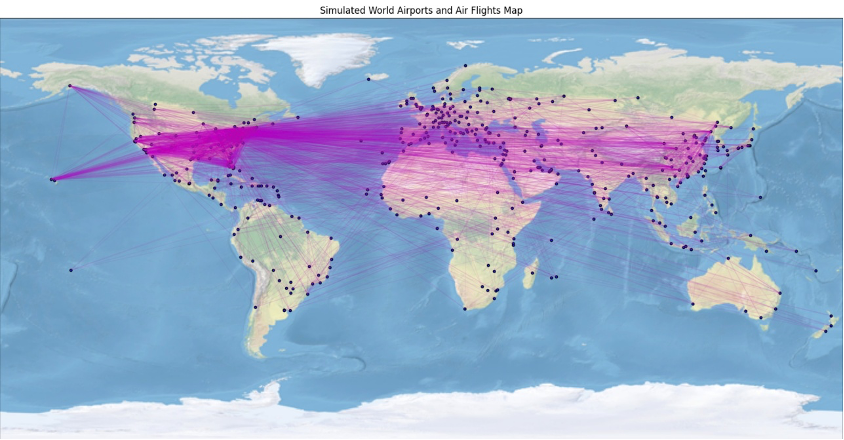
Our artificial information consists of: main world airports, simulated airways and flights with predefined capacities for cargo calls for, and generated air cargo calls for between airport pairs, which shall be delivered by simulated flights.
We make use of a easy routing coverage to distribute these calls for evenly throughout all shortest paths between two airports. This coverage is deliberately hidden from our mannequin, mimicking the real-world situations the place the precise routing mechanisms should not all the time identified. If flight capability is inadequate to fulfill incoming calls for, we simulate the surplus as stock saved on the airport. The overall stock at every airport serves as our prediction goal. In contrast to actual air transportation networks, we didn’t observe a hub-and-spoke topology. As an alternative, our artificial community makes use of a point-to-point construction. Utilizing this artificial air transportation dataset, we now display a node time sequence regression job, predicting the full stock at every airport daily. As illustrated within the following determine, the full stock quantity at an airport is influenced by its personal native calls for, the visitors passing by means of it, and the capability that it may possibly output. By design, the output capability of an airport is restricted to guarantee that most airport-to-airport calls for require multiple-hop success.
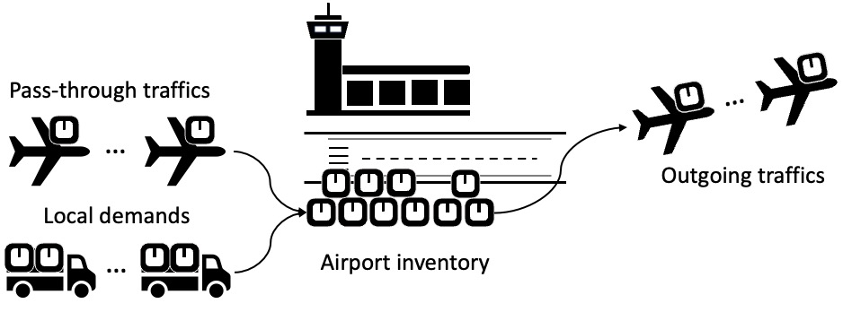
Within the the rest of this part, we cowl the info preprocessing steps obligatory for utilizing the GraphStorm framework, earlier than customizing a GNN mannequin for our utility. In the direction of the tip of the publish, we additionally present an structure for an operational security system constructed utilizing GraphStorm and in an surroundings of AWS providers.
Information preprocessing for graph time sequence forecasting
To make use of GraphStorm for node time sequence regression, we have to construction our artificial air visitors dataset in response to GraphStorm’s enter information format necessities. This entails making ready three key parts: a set of node tables, a set of edge tables, and a JSON file describing the dataset.
We summary the artificial air visitors community right into a graph with one node kind (airport) and two edge sorts. The primary edge kind, airport, demand, airport, represents demand between any pair of airports. The second, airport, visitors, airport, captures the quantity of visitors despatched between related airports.
The next diagram illustrates this graph construction.
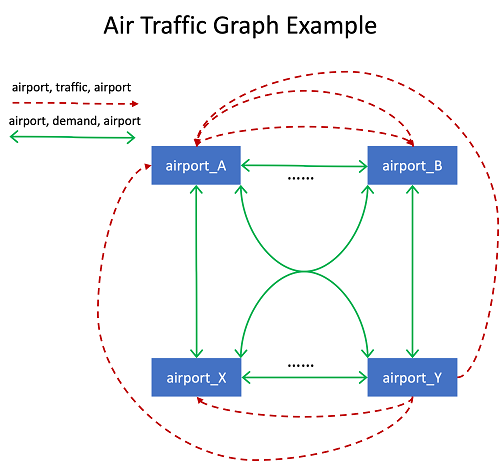
Our airport nodes have two varieties of related options: static options (longitude and latitude) and time sequence options (day by day complete stock quantity). For every edge, the src_code and dst_code seize the supply and vacation spot airport codes. The sting options additionally embrace a requirement and a visitors time sequence. Lastly, edges for related airports additionally maintain the capability as a static characteristic.
The artificial information era pocket book additionally creates a JSON file, which describes the air visitors information and supplies directions for GraphStorm’s graph development software to observe. Utilizing these artifacts, we are able to make use of the graph development software to transform the air visitors graph information right into a distributed DGL graph. On this format:
- Demand and visitors time sequence information is saved as E*T tensors in edges, the place E is the variety of edges of a given kind, and T is the variety of days in our dataset.
- Stock quantity time sequence information is saved as an N*T tensor in nodes, the place N is the variety of airport nodes.
This preprocessing step makes positive our information is optimally structured for time sequence forecasting utilizing GraphStorm.
Mannequin
To foretell the following complete stock quantity for every airport, we make use of GNN fashions, that are well-suited for capturing these complicated relationships. Particularly, we use GraphStorm’s Relational Graph Convolutional Community (RGCN) module as our GNN mannequin. This enables us to successfully move info (calls for and visitors) amongst airports in our community. To help the sliding-window prediction methodology we described earlier, we created a personalized RGCN mannequin.
The detailed implementation of the node time sequence regression mannequin could be discovered within the Python file. Within the following sections, we clarify a number of key implementation factors.
Custom-made RGCN mannequin
The GraphStorm v0.4 launch provides help for edge options. Which means that we are able to use a for-loop to iterate alongside the T dimensions within the time sequence tensor, thereby implementing the sliding-window methodology within the ahead() operate throughout mannequin coaching, as proven within the following pseudocode:
The precise code of the ahead() operate is within the following code snippet.
In distinction, as a result of the inference step wants to make use of the autoregressive sliding-window methodology, we implement a one-step prediction operate within the predict() routine:
The precise code of the predict() operate is within the following code snippet.
Custom-made node coach
GraphStorm’s default node coach (GSgnnNodePredctionTrainer), which handles the mannequin coaching loop, can’t course of the time sequence characteristic requirement. Subsequently, we implement a personalized node coach by inheriting the GSgnnNodePredctionTrainer and use our personal personalized node_mini_batch_gnn_predict() methodology. That is proven within the following code snippet.
Custom-made node_mini_batch_predict() methodology
The personalized node_mini_batch_predict() methodology calls the personalized mannequin’s predict() methodology, passing the 2 further arguments which might be particular to our use case. These are used to find out whether or not the autoregressive property is used or not, together with the present prediction step for applicable indexing (see the next code snippet).
Custom-made node predictor (inferrer)
Just like the node coach, GraphStorm’s default node inference class, which drives the inference pipeline (GSgnnNodePredictionInferrer), can’t deal with the time sequence characteristic processing we want on this utility. We subsequently create a personalized node inferrer by inheriting GSgnnNodePredictionInferrer, and add two particular arguments. On this personalized inferrer, we use a for-loop to iterate over the T dimensions of the time sequence characteristic tensor. In contrast to the for-loop we utilized in mannequin coaching, the inference loop makes use of the anticipated values in subsequent prediction steps (that is proven within the following code snippet).
To date, now we have targeted on the node prediction instance with our dataset and modeling. Nonetheless, our strategy permits for varied different prediction duties, similar to:
- Forecasting visitors between particular airport pairs.
- Extra complicated situations like predicting potential airport congestion or elevated utilization of different routes when lowering or eliminating flights between sure airports.
With the personalized mannequin and pipeline courses, we are able to use the next Jupyter notebook to run the general coaching and inference pipeline for our airport stock quantity prediction job. We encourage you to discover these prospects, adapt the offered instance to your particular use circumstances or analysis pursuits, and discuss with our Jupyter notebooks for a complete understanding of tips on how to use GraphStorm APIs for varied GML duties.
System structure for GNN-based community visitors prediction
On this part, we suggest a system structure for enhancing operational security inside a posh community, similar to those we mentioned earlier. Particularly, we make use of GraphStorm inside an AWS surroundings to construct, practice, and deploy graph fashions. The next diagram reveals the assorted parts we have to obtain the security performance.
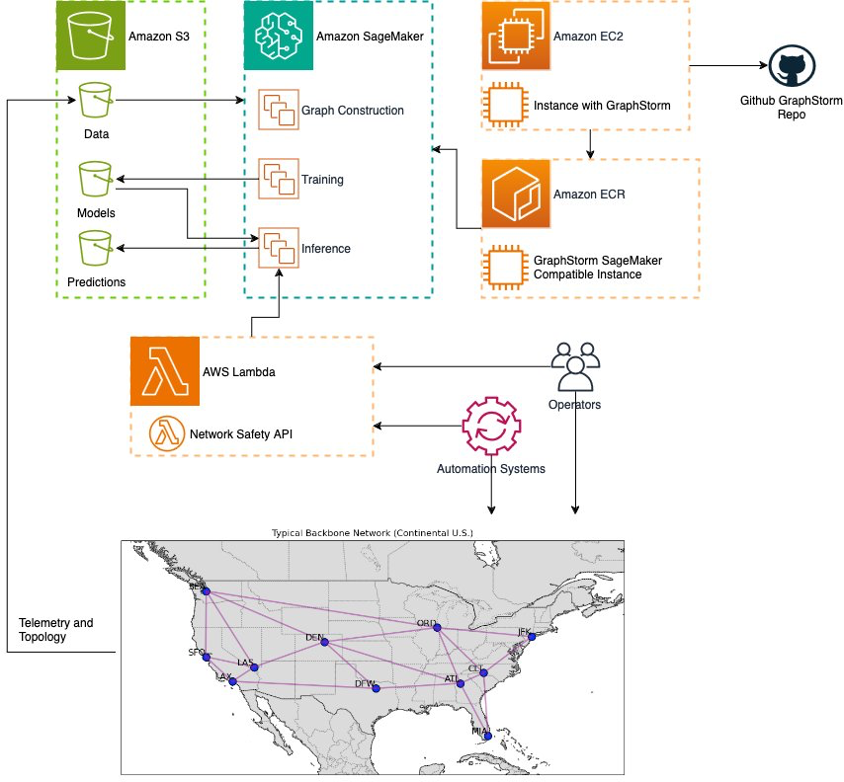
The complicated system in query is represented by the community proven on the backside of the diagram, overlaid on the map of the continental US. This community emits telemetry information that may be saved on Amazon Simple Storage Service (Amazon S3) in a devoted bucket. The evolving topology of the community must also be extracted and saved.
On the highest proper of the previous diagram, we present how Amazon Elastic Compute Cloud (Amazon EC2) cases could be configured with the mandatory GraphStorm dependencies utilizing direct entry to the challenge’s GitHub repository. After they’re configured, we are able to construct GraphStorm Docker photographs on them. These photographs then could be placed on Amazon Elastic Container Registry (Amazon ECR) and be made obtainable to different providers (for instance, Amazon SageMaker).
Throughout coaching, SageMaker jobs use these cases together with the community information to coach a visitors prediction mannequin such because the one we demonstrated on this publish. The educated mannequin can then be saved on Amazon S3. It is perhaps essential to repeat this coaching course of periodically, to guarantee that the mannequin’s efficiency retains up with adjustments to the community dynamics (similar to modifications to the routing schemes).
Above the community illustration, we present two doable actors: operators and automation techniques. These actors name on a community security API applied in AWS Lambda to guarantee that the actions they intend to take are protected for the anticipated time horizon (for instance, 1 hour, 6 hours, 24 hours). To offer a solution, the Lambda operate makes use of the on-demand inference capabilities of SageMaker. Throughout inference, SageMaker makes use of the pre-trained mannequin to supply the mandatory visitors predictions. These predictions can be saved on Amazon S3 to constantly monitor the mannequin’s efficiency over time, triggering coaching jobs when important drift is detected.
Conclusion
Sustaining operational security for the AWS spine community, whereas supporting the dynamic wants of our international buyer base, is a singular problem. On this publish, we demonstrated how the GML framework GraphStorm could be successfully utilized to foretell visitors patterns and potential congestion dangers in such complicated networks. By framing our community as a heterogeneous graph and utilizing GNNs, we’ve proven that it’s doable to seize the intricate interdependencies and dynamic nature of community visitors. Our strategy, examined on each artificial information and the precise AWS spine community, has demonstrated important enhancements over conventional time sequence forecasting strategies, with a 35% discount in prediction error in comparison with classical approaches like XGBoost.
The proposed system structure, integrating GraphStorm with varied AWS providers like Amazon S3, Amazon EC2, SageMaker, and Lambda, supplies a scalable and environment friendly framework for implementing this strategy in manufacturing environments. This setup permits for steady mannequin coaching, fast inference, and seamless integration with current operational workflows.
We’ll maintain you posted about our progress in taking our resolution to manufacturing, and share the profit for AWS prospects.
We encourage you to discover the offered Jupyter notebooks, adapt our strategy to your particular use circumstances, and contribute to the continuing improvement of graph-based ML methods for managing complicated networked techniques. To learn to use GraphStorm to unravel a broader class of ML issues on graphs, see the GitHub repo.
In regards to the Authors
 Jian Zhang is a Senior Utilized Scientist who has been utilizing machine studying methods to assist prospects clear up varied issues, similar to fraud detection, ornament picture era, and extra. He has efficiently developed graph-based machine studying, notably graph neural community, options for purchasers in China, the US, and Singapore. As an enlightener of AWS graph capabilities, Zhang has given many public displays about GraphStorm, the GNN, the Deep Graph Library (DGL), Amazon Neptune, and different AWS providers.
Jian Zhang is a Senior Utilized Scientist who has been utilizing machine studying methods to assist prospects clear up varied issues, similar to fraud detection, ornament picture era, and extra. He has efficiently developed graph-based machine studying, notably graph neural community, options for purchasers in China, the US, and Singapore. As an enlightener of AWS graph capabilities, Zhang has given many public displays about GraphStorm, the GNN, the Deep Graph Library (DGL), Amazon Neptune, and different AWS providers.
 Fabien Chraim is a Principal Analysis Scientist in AWS networking. Since 2017, he’s been researching all points of community automation, from telemetry and anomaly detection to root inflicting and actuation. Earlier than Amazon, he co-founded and led analysis and improvement at Civil Maps (acquired by Luminar). He holds a PhD in electrical engineering and laptop sciences from UC Berkeley.
Fabien Chraim is a Principal Analysis Scientist in AWS networking. Since 2017, he’s been researching all points of community automation, from telemetry and anomaly detection to root inflicting and actuation. Earlier than Amazon, he co-founded and led analysis and improvement at Civil Maps (acquired by Luminar). He holds a PhD in electrical engineering and laptop sciences from UC Berkeley.
 Patrick Taylor is a Senior Information Scientist in AWS networking. Since 2020, he has targeted on impression discount and threat administration in networking software program techniques and operations analysis in networking operations groups. Beforehand, Patrick was a knowledge scientist specializing in pure language processing and AI-driven insights at Hyper Anna (acquired by Alteryx) and holds a Bachelor’s diploma from the College of Sydney.
Patrick Taylor is a Senior Information Scientist in AWS networking. Since 2020, he has targeted on impression discount and threat administration in networking software program techniques and operations analysis in networking operations groups. Beforehand, Patrick was a knowledge scientist specializing in pure language processing and AI-driven insights at Hyper Anna (acquired by Alteryx) and holds a Bachelor’s diploma from the College of Sydney.
 Xiang Track is a Senior Utilized Scientist at AWS AI Analysis and Schooling (AIRE), the place he develops deep studying frameworks together with GraphStorm, DGL, and DGL-KE. He led the event of Amazon Neptune ML, a brand new functionality of Neptune that makes use of graph neural networks for graphs saved in graph database. He’s now main the event of GraphStorm, an open supply graph machine studying framework for enterprise use circumstances. He obtained his PhD in laptop techniques and structure on the Fudan College, Shanghai, in 2014.
Xiang Track is a Senior Utilized Scientist at AWS AI Analysis and Schooling (AIRE), the place he develops deep studying frameworks together with GraphStorm, DGL, and DGL-KE. He led the event of Amazon Neptune ML, a brand new functionality of Neptune that makes use of graph neural networks for graphs saved in graph database. He’s now main the event of GraphStorm, an open supply graph machine studying framework for enterprise use circumstances. He obtained his PhD in laptop techniques and structure on the Fudan College, Shanghai, in 2014.
 Florian Saupe is a Principal Technical Product Supervisor at AWS AI/ML analysis supporting science groups just like the graph machine studying group, and ML Programs groups engaged on giant scale distributed coaching, inference, and fault resilience. Earlier than becoming a member of AWS, Florian lead technical product administration for automated driving at Bosch, was a method marketing consultant at McKinsey & Firm, and labored as a management techniques and robotics scientist—a discipline wherein he holds a PhD.
Florian Saupe is a Principal Technical Product Supervisor at AWS AI/ML analysis supporting science groups just like the graph machine studying group, and ML Programs groups engaged on giant scale distributed coaching, inference, and fault resilience. Earlier than becoming a member of AWS, Florian lead technical product administration for automated driving at Bosch, was a method marketing consultant at McKinsey & Firm, and labored as a management techniques and robotics scientist—a discipline wherein he holds a PhD.