LLM Analysis Metrics Made Straightforward


LLM Analysis Metrics Made Straightforward
Picture by Writer | Ideogram
Metrics are a cornerstone factor in evaluating any AI system, and within the case of enormous language fashions (LLMs), that is no exception. This text demystifies how some in style metrics for evaluating language duties carried out by LLMs work from inside, supported by Python code examples that illustrate methods to leverage them with Hugging Face libraries simply.
Whereas the article focuses on understanding LLM metrics from a sensible viewpoint, we advocate you try additionally this supplementary reading that conceptually examines components, pointers, and greatest practices for LLM analysis.
Pre-requisite code for putting in and importing essential libraries:
|
!pip set up consider rouge_score transformers torch import consider import numpy as np |
Analysis Metrics From Inside
The analysis metrics we’ll discover are summarized on this visible diagram, together with some language duties the place they’re sometimes utilized.
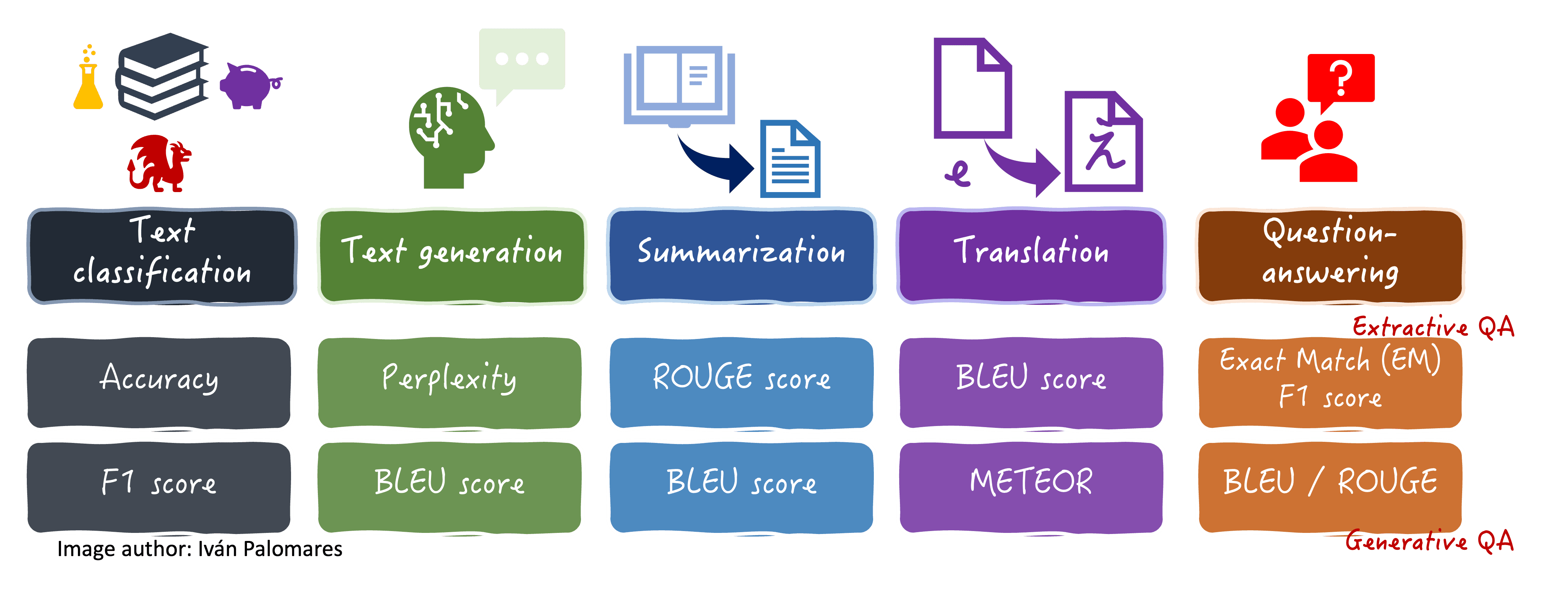
Analysis metrics for various language duties
Accuracy and F1 Rating
Accuracy measures the general correctness of predictions (usually classifications) by computing the proportion of appropriate predictions out of whole predictions. The F1 rating supplies a extra nuanced strategy, particularly for evaluating categorical predictions within the face of imbalanced datasets, combining precision and recall. Inside the LLM panorama, they’re used each in textual content classification duties like sentiment evaluation, and different non-generative duties like extracting solutions or summaries from enter texts.
Suppose you’re analyzing sentiment in Japanese anime opinions. Whereas accuracy would describe the general proportion of appropriate classifications, F1 could be significantly helpful if most opinions had been typically constructive (or, quite the opposite, principally detrimental), thus capturing extra of how the mannequin performs throughout each lessons. It additionally helps reveal any bias within the predictions.
This instance code reveals each metrics in motion, utilizing Hugging Face libraries, pre-trained LLMs, and the aforesaid metrics to judge the classification of a number of texts into associated vs non-related to the Japanese Tea Ceremony or 茶の湯 (Cha no Yu). For now, no precise LLM is loaded and we suppose we have already got its classification outputs in an inventory referred to as pred_labels. Strive it out in a Python pocket book!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# Pattern dataset about Japanese tea ceremony references = [ “The Japanese tea ceremony is a profound cultural practice emphasizing harmony and respect.”, “Matcha is carefully prepared using traditional methods in a tea ceremony.”, “The tea master meticulously follows precise steps during the ritual.” ]
predictions = [ “Japanese tea ceremony is a cultural practice of harmony and respect.”, “Matcha is prepared using traditional methods in tea ceremonies.”, “The tea master follows precise steps during the ritual.” ]
# Accuracy and F1 Rating accuracy_metric = consider.load(“accuracy”) f1_metric = consider.load(“f1”)
# Simulate binary classification (e.g., ceremony vs. non-ceremony) labels = [1, 1, 1] # All are about tea ceremony pred_labels = [1, 1, 1] # Mannequin predicts all appropriately
accuracy = accuracy_metric.compute(predictions=pred_labels, references=labels) f1 = f1_metric.compute(predictions=pred_labels, references=labels, common=‘weighted’)
print(“Accuracy:”, accuracy) print(“F1 Rating:”, f1) |
Be at liberty to play with the binary values within the labels and pred_labels lists above to see how this impacts the metrics computation. The under code excerpts will think about the identical instance textual content information.
Perplexity
Perplexity measures how effectively an LLM predicts a sample-generated textual content by taking a look at every generated phrase’s chance of being the chosen one as subsequent within the sequence. In different phrases, this metric quantifies the mannequin’s uncertainty. Decrease perplexity signifies higher efficiency, i.e. the mannequin did a greater job at predicting the following phrase within the sequence. As an illustration, in a sentence about making ready matcha tea, a low perplexity would imply the mannequin can constantly predict acceptable subsequent phrases with minimal shock, like ‘inexperienced’ adopted by ‘tea’, adopted by ‘powder’, and so forth.
Right here’s the follow-up code exhibiting methods to use perplexity:
|
# Perplexity (utilizing a small GPT2 language mannequin) perplexity_metric = consider.load(“perplexity”, module_type=“metric”) perplexity = perplexity_metric.compute( predictions=predictions, model_id=‘gpt2’ # Utilizing a small pre-trained mannequin ) print(“Perplexity:”, perplexity) |
ROUGE, BLEU and METEOR
BLEU, ROUGE, and METEOR are significantly utilized in translation and summarization duties the place each language understanding and language era efforts are equally wanted: they assess the similarity between generated and reference texts (e.g. supplied by human annotators). BLEU focuses on precision by counting matching n-grams, being principally used to judge translations, whereas ROUGE measures recall by analyzing overlapping language items, usually used to judge summaries. METEOR provides sophistication by contemplating further points like synonyms, phrase stems, and extra.
For translating a haiku (Japanese poem) about cherry blossoms or summarizing giant Chinese language novels like Journey to the West, these metrics would assist quantify how carefully the LLM-generated textual content captures the unique’s that means, phrases chosen, and linguistic nuances.
Instance code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# ROUGE Rating (no LLM loaded, utilizing pre-defined lists of texts as LLM outputs (predictions) and references) rouge_metric = consider.load(‘rouge’) rouge_results = rouge_metric.compute( predictions=predictions, references=references ) print(“ROUGE Scores:”, rouge_results)
# BLEU Rating (no LLM loaded, utilizing pre-defined lists of texts as LLM outputs (predictions) and references) bleu_metric = consider.load(“bleu”) bleu_results = bleu_metric.compute( predictions=predictions, references=references ) print(“BLEU Rating:”, bleu_results)
# METEOR (requires references to be an inventory of lists) meteor_metric = consider.load(“meteor”) meteor_results = meteor_metric.compute( predictions=predictions, references=[[ref] for ref in references] ) print(“METEOR Rating:”, meteor_results) |
Actual Match
A fairly simple, but drastic-behaving metric, actual match (EM) is utilized in extractive question-answering use circumstances to test whether or not a mannequin’s generated reply utterly matches a “gold commonplace” reference reply. It’s usually used along with the F1 rating to judge these duties.
In a QA context about East Asian historical past, an EM rating would solely rely as 1 (match) if the LLM’s whole response exactly matches the reference reply. For instance, if requested “Who was the primary Shogun of the Tokugawa Shogunate?“, solely a word-for-word match with “Tokugawa Ieyasu” would yield an EM of 1, being 0 in any other case.
Code (once more, simplified by assuming the LLM outputs are already collected in an inventory):
|
# 6. Actual Match def exact_match_compute(predictions, references): return sum(pred.strip() == ref.strip() for pred, ref in zip(predictions, references)) / len(predictions)
em_score = exact_match_compute(predictions, references) print(“Actual Match Rating:”, em_score) |
Wrapping Up
This text aimed toward simplifying the sensible understanding of analysis metrics normally utilized for assessing LLMs’ efficiency in a wide range of language use circumstances. By combining example-driven explanations with illustrative code-based examples of their use by way of Hugging Face libraries, we hope you gained a greater understanding of those intriguing metrics not generally seen within the analysis of different AI and machine studying fashions.





