Effectively construct and tune customized log anomaly detection fashions with Amazon SageMaker

On this publish, we stroll you thru the method to construct an automatic mechanism utilizing Amazon SageMaker to course of your log information, run coaching iterations over it to acquire the best-performing anomaly detection mannequin, and register it with the Amazon SageMaker Model Registry to your prospects to make use of it.
Log-based anomaly detection entails figuring out anomalous information factors in log datasets for locating execution anomalies, in addition to suspicious actions. It often contains parsing log information into vectors or machine-understandable tokens, which you’ll then use to coach customized machine studying (ML) algorithms for figuring out anomalies.
You may modify the inputs or hyperparameters for an ML algorithm to acquire a mixture that yields the best-performing mannequin. This course of known as hyperparameter tuning and is a necessary a part of machine studying. Selecting applicable hyperparameter values is essential for fulfillment, and it’s often carried out iteratively by specialists, which will be time-consuming. Added to this are the overall data-related processes resembling loading information from applicable sources, parsing and processing them with customized logic, storing the parsed information again to storage, and loading them once more for coaching customized fashions. Furthermore, these duties must be accomplished repetitively for every mixture of hyperparameters, which doesn’t scale effectively with rising information and new supplementary steps. You should utilize Amazon SageMaker Pipelines to automate all these steps right into a single execution circulation. On this publish, we show arrange this whole workflow.
Answer overview
Modern log anomaly detection strategies resembling Drain-based detection [1] or DeepLog [2] encompass the next common method: carry out customized processing on logs, practice their anomaly detection fashions utilizing customized fashions, and procure the best-performing mannequin with an optimum set of hyperparameters. To construct an anomaly detection system utilizing such strategies, it is advisable write customized scripts for processing as effectively for coaching. SageMaker offers assist for creating scripts by extending in-built algorithm containers, or by constructing your personal customized containers. Furthermore, you’ll be able to mix these steps as a sequence of interconnected phases utilizing SageMaker Pipelines. The next determine reveals an instance structure:
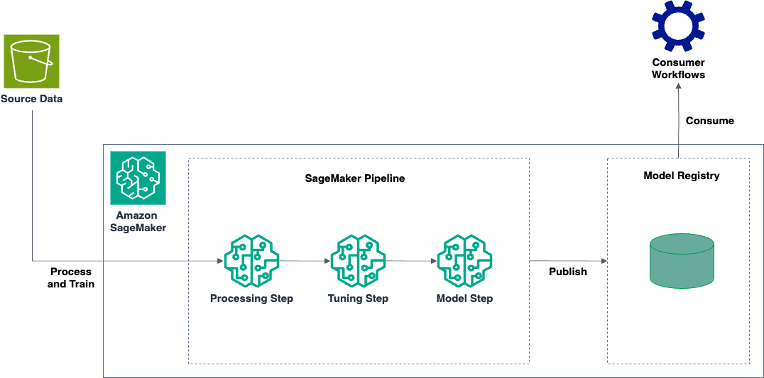
The workflow consists of the next steps:
- The log coaching information is initially saved in an Amazon Simple Storage Service (Amazon S3) bucket, from the place it’s picked up by the SageMaker processing step of the SageMaker pipeline.
- After the pipeline is began, the processing step hundreds the Amazon S3 information into SageMaker containers and runs customized processing scripts that parse and course of the logs earlier than importing them to a specified Amazon S3 vacation spot. This processing could possibly be both decentralized with a single script operating on a number of situations, or it could possibly be run in parallel over a number of situations utilizing a distributed framework like Apache Spark. We talk about each approaches on this publish.
- After processing, the info is routinely picked up by the SageMaker tuning step, the place a number of coaching iterations with distinctive hyperparameter combos are run for the customized coaching script.
- Lastly, the SageMaker model step creates a SageMaker mannequin utilizing the best-trained mannequin obtained from the tuning step and registers it to the SageMaker Mannequin Registry for shoppers to make use of. These shoppers, for instance, could possibly be testers, who use fashions skilled on completely different datasets by completely different pipelines to match their effectiveness and generality, earlier than deploying them to a public endpoint.
We stroll by way of implementing the answer with the next high-level steps:
- Carry out customized information processing, utilizing both a decentralized or distributed method.
- Write customized SageMaker coaching scripts that routinely tune the ensuing fashions with a variety of hyperparameters.
- Choose the best-tuned mannequin, create a customized SageMaker mannequin from it, and register it to the SageMaker Mannequin Registry.
- Mix all of the steps in a SageMaker pipeline and run it.
Conditions
You must have the next stipulations:
Course of the info
To begin, add the log dataset to an S3 bucket in your AWS account. You should utilize the AWS Command Line Interface (AWS CLI) utilizing Amazon S3 commands, or use the AWS Management Console. To course of the info, you employ a SageMaker processing step as the primary stage in your SageMaker pipeline. This step spins up a SageMaker container and runs a script that you just present for customized processing. There are two methods to do that: decentralized or distributed processing. SageMaker offers Processor courses for each approaches. You may select both method to your customized processing relying in your use case.
Decentralized processing with ScriptProcessor
Within the decentralized method, a single customized script runs on a number of standalone situations and processes the enter information. The SageMaker Python SDK offers the ScriptProcessor class, which you should use to run your customized processing script in a SageMaker processing step. For small datasets, a single occasion can often suffice for performing information processing. Growing the variety of situations is beneficial in case your dataset is giant and will be cut up into a number of impartial elements, which may all be processed individually (this may be accomplished utilizing the ShardedByS3Key parameter, which we talk about shortly).
If in case you have customized dependencies (which may typically be the case throughout R&D processes), you’ll be able to prolong an present container and customise it together with your dependencies earlier than offering it to the ScriptProcessor class. For instance, when you’re utilizing the Drain approach, you want the logparser Python library for log parsing, during which case you write a easy Dockerfile that installs it together with the same old Python ML libraries:
You should utilize a Python SageMaker pocket book occasion in your AWS account to create such a Dockerfile and put it aside to an applicable folder, resembling docker. To construct a container utilizing this Dockerfile, enter the next code right into a primary driver program in a Jupyter pocket book in your pocket book occasion:
This code creates an Amazon Elastic Container Registry (Amazon ECR) repository the place your customized container picture will probably be saved (the repository will probably be created if it’s not already current). The container picture is then constructed, tagged with the repository identify (and :newest), and pushed to the ECR repository.
The subsequent step is writing your precise processing script. For extra data on writing a processing script utilizing ScriptProcessor, confer with Amazon SageMaker Processing – Fully Managed Data Processing and Model Evaluation. The next are a number of key factors to recollect:
- A SageMaker processing step hundreds the info from an enter location (Amazon S3 or native developer workspace) to an enter path specified by you underneath the
/decide/ml/processinglisting of your container. It then runs your script within the container and uploads the output information out of your specified path underneath/decide/ml/processingto an Amazon S3 vacation spot you’ve specified. - Buyer log datasets can generally encompass a number of subsets with none inter-dependencies amongst them. For these circumstances, you’ll be able to parallelize your processing by making your processing script run over a number of situations in a single processing step, with every occasion processing certainly one of these impartial subsets. It’s a very good observe to maintain the script’s logic redundant so that every execution on each occasion occurs independently of the others. This avoids duplicative work.
When your script is prepared, you’ll be able to instantiate the SageMaker ScriptProcessor class for operating it in your customized container (created within the earlier step) by including the next code to your driver program:
Within the previous code, a ScriptProcessor class is being instantiated to run the python3 command for operating your customized Python script. You present the next data:
- You present the ECR URI of your customized container picture and provides SageMaker
PipelineSessioncredentials to the category. While you specify thePipelineSession, theScriptProcessordoesn’t really start the execution if you name itsrun()methodology—fairly, it defers till the SageMaker pipeline as a complete is invoked. - Within the run() methodology, you specify the preprocessing script together with the suitable
ProcessingInputandProcessingOutputThese specify the place the info will probably be mounted in your customized container from Amazon S3, and the place it will likely be later uploaded in Amazon S3 out of your container’s output folder. The output channel is known as coaching, and the ultimate Amazon output location will probably be situated ats3://<amzn-s3-demo-bucket-pca-detect>/<job-name>/output/<output-name>.
You may also specify an extra parameter in run() named distribution, and it may possibly both be ShardedByS3Key or FullyReplicated, relying on whether or not you’re splitting and sending your S3 dataset to a number of ScriptProcessor situations or not. You may specify the variety of situations within the instance_count parameter of your ScriptProcessor class.
As soon as instantiated, you’ll be able to go the ScriptProcessor class as an argument to the SageMaker processing step together with an applicable identify.
Distributed processing with PySparkProcessor
An alternative choice to the decentralized processing is distributed processing. Distributed processing is especially efficient when it is advisable course of giant quantities of log information. Apache Spark is a well-liked engine for distributed information processing. It makes use of in-memory caching and optimized question execution for quick analytic queries in opposition to datasets of all sizes. SageMaker offers the PySparkProcessor class throughout the SageMaker Python SDK for operating Spark jobs. For an instance of performing distributed processing with PySparkProcessor on SageMaker processing, see Distributed Data Processing using Apache Spark and SageMaker Processing. The next are a number of key factors to notice:
- To put in customized dependencies in your Spark container, you’ll be able to both construct a customized container picture (just like the decentralized processing instance) or use the
subprocessPython module to put in them utilizingpipat runtime. For instance, to run the anomaly detection approach on Spark, you want anargformatmodule, which you’ll set up together with different dependencies as follows:
- Spark transformations are highly effective operations to course of your information, and Spark actions are the operations that really carry out the requested transformations in your information. The
gather()methodology is a Spark motion that brings all the info from employee nodes to the principle driver node. It’s a very good observe to make use of it together with filter capabilities so that you don’t run into reminiscence points when working with giant log datasets. - You must also attempt to partition your enter information primarily based on the entire variety of cores you propose to have in your SageMaker cluster. The official Spark advice is to have roughly 2–3 occasions the variety of partitions as the entire variety of cores in your cluster.
When your Spark processing script is prepared, you’ll be able to instantiate the SageMaker PySparkProcessor class for operating it by including the next strains to your driver program:
The previous code instantiates a PySparkProcessor occasion with three nodes within the SageMaker cluster with Spark v3.1 put in in them. You submit your Spark processing code to it together with the Amazon S3 location the place your occasion logs can be uploaded. These logs will be helpful for debugging.
Within the run() methodology invocation, you don’t must specify your inputs and outputs, which will be the case if these are fastened Amazon S3 locations already identified to your processing code. In any other case, you’ll be able to specify them utilizing the ProcessingInput and ProcessingOutput parameters identical to within the decentralized instance.
Publish-instantiation, the PySparkProcessor class is handed to a SageMaker processing step with an applicable identify. Its execution gained’t be triggered till the pipeline is created.
Prepare and tune the mannequin
Now that your processing steps are full, you’ll be able to proceed to the mannequin coaching step. The coaching algorithm may both be a classical anomaly detection mannequin like Drain-based detection or a neural-network primarily based mannequin like DeepLog. Each mannequin takes in sure hyperparameters that affect how the mannequin is skilled. To acquire the best-performing mannequin, the mannequin is often executed and validated a number of occasions over a variety of hyperparameters. This could be a time-consuming guide course of and may as an alternative be automated utilizing SageMaker hyperparameter tuning jobs. Tuning jobs carry out hyperparameter optimization by operating your coaching script with a specified vary of hyperparameter values and acquiring the very best mannequin primarily based on the metrics you specify. You may predefine these metrics when you use built-in SageMaker algorithms or outline them to your customized coaching algorithm.
You first want to jot down your coaching script to your anomaly detection mannequin. Maintain the next in thoughts:
- SageMaker makes artifacts accessible to your container underneath the
/decide/mlcontainer listing. You must use this when fetching your artifacts. For extra particulars on the SageMaker container construction, see SageMaker AI Toolkits Containers Structure. - For utilizing a tuning job, it is advisable make it possible for your code doesn’t hardcode parameter hyperparameter values however as an alternative reads them from the
/decide/ml/enter/config/hyperparameters.jsonfile in your container the place SageMaker locations it. - When utilizing a customized coaching script, you additionally want so as to add a customized coaching metric to your script that can be utilized by the tuning job to search out the very best mannequin. For this, you need to print your required metrics in your coaching script utilizing a logger or print operate. For instance, you may print out
custom_metric_value: 91, which signifies that your customized metric’s worth is 91. We show later on this publish how SageMaker will be knowledgeable about this metric.
When your coaching script is prepared, you should use it inside a SageMaker container. SageMaker offers a variety of built-in algorithm containers that you should use to run your coaching code. Nevertheless, there could be circumstances when it is advisable construct your personal coaching containers. This could possibly be the case if you want customized libraries put in or when you plan to make use of a brand new algorithm not in-built by SageMaker. In such a case, you’ll be able to construct your personal containers in two methods:
After you create your coaching container picture, it is advisable outline the hyperparameter ranges to your tuning job. For instance, when you’re utilizing a customized adaptation of the PCA algorithm (like in Drain-based detection), you add the next strains to your driver program:
The previous code signifies that your hyperparameter max_components is an integer and it ranges from 1–30. The auto scaling sort signifies that SageMaker will select the very best scale for hyperparameter adjustments. For extra particulars on different scaling choices, see Hyperparameter scaling types.
Then you should use the next code to completely configure your coaching and tuning steps within the driver program:
Within the previous code, a SageMaker Estimator occasion is created utilizing your customized coaching picture’s ECR URI. SageMaker Estimators assist in coaching your fashions and orchestrating their coaching lifecycles. The Estimator is supplied with an appropriate function and the PipelineSession is designated as its SageMaker session.
You present the situation the place your skilled mannequin must be saved to the Estimator and provide it with customized metric definitions that you just created. For the instance metric custom_metric_value: 91, the definition to the Estimator consists of its identify together with its regex. The regex informs SageMaker choose up the metric’s values from coaching logs in Amazon CloudWatch. The tuning job makes use of these values to search out the best-performing mannequin. You additionally specify the place the output mannequin must be uploaded within the output_path parameter.
You then use this Estimator to instantiate your HyperparameterTuner. Its parameters embody the entire and most parallel variety of coaching jobs, search technique (for extra particulars on methods, see Understand the hyperparameter tuning strategies available in Amazon SageMaker AI), and whether or not you wish to use early stopping. Early stopping will be set to Auto in order that SageMaker routinely stops mannequin coaching when it doesn’t see enhancements in your customized logged metric.
After the HyperparameterTuner is instantiated, you’ll be able to name its match() methodology. In its enter parameter, you specify the output Amazon S3 URI from the processing step because the enter location for acquiring coaching information in your tuning step. This manner, you don’t must specify the Amazon S3 URI your self and it’s handed between steps implicitly. You may then specify your s3prefix and distribution relying on whether or not you’re utilizing a number of situations or not.
As soon as instantiated, the HyperparameterTuner is handed to the tuning step, the place it turns into a part of your SageMaker pipeline. The coaching configuration is now full!
Register the mannequin
Now you can select the very best mannequin from the tuning step to create a SageMaker model and publish it to the SageMaker Mannequin Registry. You should utilize the next driver program code:
The code instantiates a SageMaker mannequin utilizing the Amazon S3 URI of the very best mannequin obtained from the tuning step. The top_k attribute of the get_top_model_s3_uri() methodology signifies that you just’re taken with solely acquiring the best-trained mannequin.
After the mannequin is instantiated, you should use it to create a SageMaker PipelineModel in order that your pipeline can work immediately together with your mannequin. You then name the register() methodology of PipelineModel to register your mannequin to the SageMaker Mannequin Registry. Within the register() name, you specify the identify of the brand new model package group the place your mannequin will probably be registered and specify its enter and output request and response prediction sorts.
Lastly, a SageMaker ModelStep is invoked with the instantiated PipelineModel to hold out the mannequin registration course of.
Create and run a pipeline
You’ve now reached the ultimate step the place all of your steps will probably be tied collectively in a SageMaker pipeline. Add the next code to your driver program to finish your pipeline creation steps:
This code instantiates the SageMaker Pipeline assemble and offers it with all of the steps outlined till now—processing, tuning, and registering the mannequin. It’s supplied with a task after which invoked with the begin() methodology.
The pipeline invocation could possibly be on-demand utilizing code (utilizing pipeline.begin() as proven earlier) or it could possibly be event-driven utilizing Amazon EventBridge rules. For instance, you’ll be able to create an EventBridge rule that triggers when new coaching information is uploaded to your S3 buckets and specify your SageMaker pipeline because the goal for this rule. This makes certain that when new information is uploaded to your coaching bucket, your SageMaker pipeline is routinely invoked. For extra particulars on SageMaker and EventBridge integration, confer with Schedule Pipeline Runs.
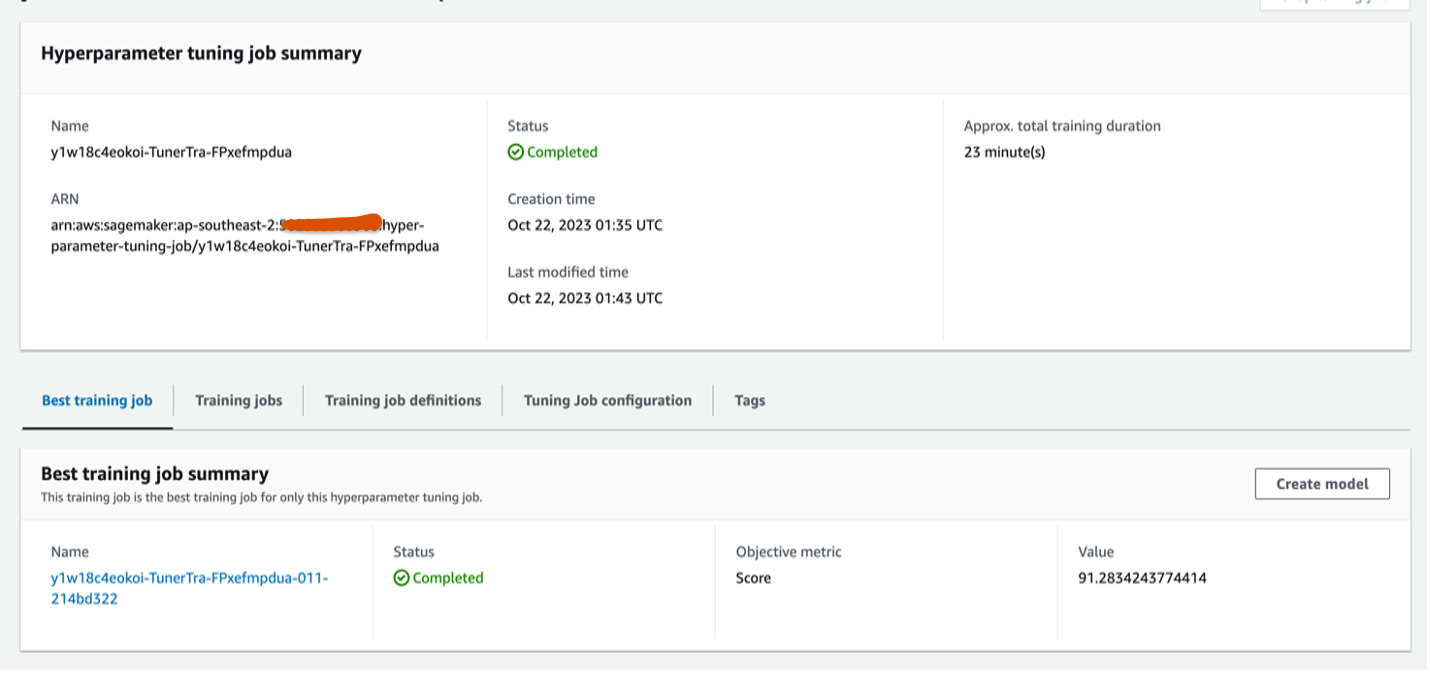
On invocation, your SageMaker pipeline runs your customized processing script within the processing step and uploads the processed information to your specified Amazon S3 vacation spot. It then begins a tuning job together with your customized coaching code and iteratively trains a number of fashions together with your equipped hyperparameters and selects the very best mannequin primarily based in your customized supplied metric. The next screenshot reveals that it chosen the very best mannequin when tuning was full:
Lastly, the very best mannequin is chosen and a mannequin package deal useful resource is created with it in your mannequin registry. Your prospects can use it to deploy your mannequin:
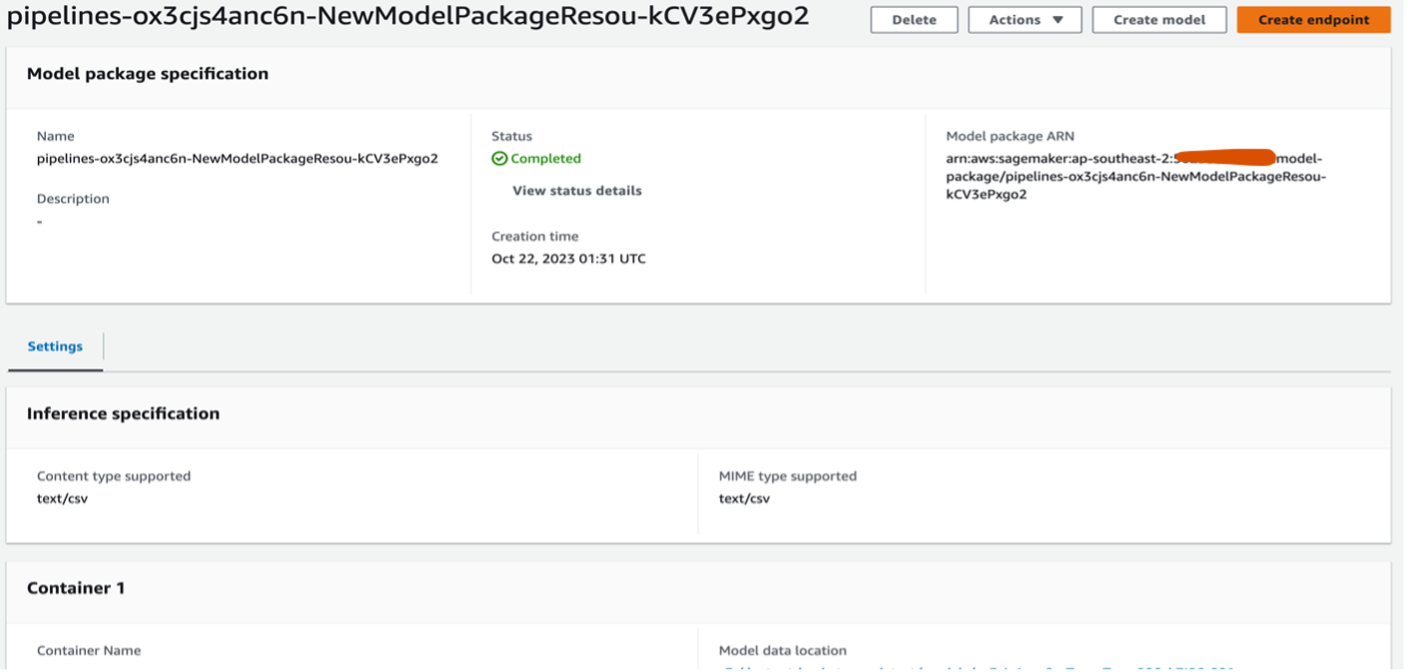
You might have now accomplished all of the steps in processing, coaching, tuning, and registering your customized anomaly detection mannequin routinely with assistance from a SageMaker pipeline that was initiated utilizing your driver program.
Clear up
To keep away from incurring future prices, full the next steps:
- Delete the SageMaker pocket book occasion used for this publish.
- Delete the mannequin package deal useful resource that was created utilizing the best-tuned mannequin.
- Delete any Amazon S3 information that was used for this publish.
Conclusion
On this publish, we demonstrated the constructing, coaching, tuning, and registering of an anomaly detection system with customized processing code, customized coaching code, and customized coaching metrics. We ran these steps routinely with assistance from a SageMaker pipeline, which was run by invoking a single primary driver program. We additionally mentioned the alternative ways of processing our information, and the way it could possibly be accomplished utilizing the varied constructs and instruments that SageMaker offers in a user-friendly and easy method.
Do that method for constructing your personal customized anomaly detection mannequin, and share your suggestions within the feedback.
References
[1] https://ieeexplore.ieee.org/document/8029742
[2] https://dl.acm.org/doi/pdf/10.1145/3133956.3134015
In regards to the Creator
 Nitesh Sehwani is an SDE with the EC2 Risk Detection group the place he’s concerned in constructing large-scale methods that present safety to our prospects. In his free time, he reads about artwork historical past and enjoys listening to thriller thrillers.
Nitesh Sehwani is an SDE with the EC2 Risk Detection group the place he’s concerned in constructing large-scale methods that present safety to our prospects. In his free time, he reads about artwork historical past and enjoys listening to thriller thrillers.





