Inductive biases of neural community modularity in spatial navigation – Machine Studying Weblog | ML@CMU
TL;DR: The mind might have developed a modular structure for day by day duties, with circuits that includes functionally specialised modules that match the duty construction. We hypothesize that this structure permits higher studying and generalization than architectures with much less specialised modules. To check this, we skilled reinforcement studying brokers with numerous neural architectures on a naturalistic navigation job. We discovered that the modular agent, with an structure that segregates computations of state illustration, worth, and motion into specialised modules, achieved higher studying and generalization. Our outcomes make clear the attainable rationale for the mind’s modularity and counsel that synthetic techniques can use this perception from neuroscience to enhance studying and generalization in pure duties.
Motivation
Regardless of the great success of AI in recent times, it stays true that even when skilled on the identical information, the mind outperforms AI in lots of duties, significantly by way of quick in-distribution studying and zero-shot generalization to unseen information. Within the rising subject of neuroAI (Zador et al., 2023), we’re significantly concerned about uncovering the rules underlying the mind’s extraordinary capabilities in order that these rules could be leveraged to develop extra versatile and general-purpose AI techniques.
Given the identical coaching information, the differing talents of studying techniques—organic or synthetic—stem from their distinct assumptions concerning the information, generally known as inductive biases. As an illustration, if the underlying information distribution is linear, a linear mannequin that assumes linearity can study in a short time—by observing only some factors with no need to suit the complete dataset—and generalize successfully to unseen information. In distinction, one other mannequin with a special assumption, comparable to quadratic, can not obtain the identical efficiency. Even when it have been a robust common operate approximator, it will not obtain the identical effectivity. The mind might have developed inductive biases that align with the underlying construction of pure duties, which explains its excessive effectivity and generalization talents in such duties.
What are the mind’s helpful inductive biases? One perspective means that the mind might have developed an inductive bias for a modular structure that includes functionally specialised modules (Bertolero et al., 2015). Every module focuses on a particular side or a subset of job variables, collectively masking all demanding computations of the duty. We hypothesize that this structure permits increased effectivity in studying the construction of pure duties and higher generalization in duties with an analogous construction than these with much less specialised modules.
Earlier works (Goyal et al., 2022; Mittal et al., 2022) have outlined the potential rationale for this structure: Information generated from pure duties sometimes stem from the latent distribution of a number of job variables. Decomposing the duty and studying these variables in distinct modules enable a greater understanding of the relationships amongst these variables and due to this fact the information technology course of. This modularization additionally promotes hierarchical computation, the place impartial variables are initially computed after which forwarded to different modules specialised in computing dependent variables. Word that “modular” might tackle completely different meanings in numerous contexts. Right here, it particularly refers to architectures with a number of modules, every specializing in a single or a subset of the specified job variables. Architectures with a number of modules missing enforced specialization in computing variables don’t meet the standards for modular in our context.
To check our speculation, it’s important to pick out a pure job and evaluate a modular structure designed for the duty with various architectures.
Job
We selected a naturalistic digital navigation job (Determine 1) beforehand used to analyze the neural computations underlying animals’ versatile behaviors (Lakshminarasimhan et al., 2020). In the beginning of every trial, the topic is located on the middle of the bottom airplane going through ahead; a goal is introduced at a random location throughout the subject of view (distance: (100) to (400) cm, angle: (-35) to (+35^{circ})) on the bottom airplane and disappears after (300) ms. The topic can freely management its linear and angular velocities with a joystick (most: (200) cm/s and (90^{circ})/s, known as the joystick achieve) to maneuver alongside its heading within the digital surroundings. The target is to navigate towards the memorized goal location, then cease contained in the reward zone, a round area centered on the goal location with a radius of (65) cm. A reward is given provided that the topic stops contained in the reward zone.

The topic’s self-location will not be straight observable as a result of there are not any secure landmarks; as an alternative, the topic wants to make use of optic move cues on the bottom airplane to understand self-motion and carry out path integration. Every textural factor of the optic move, an isosceles triangle, seems at random areas and orientations, disappearing after solely a brief lifetime ((sim 250) ms), making it unimaginable to make use of as a secure landmark. A brand new trial begins after the topic stops shifting.
Job modeling
We formulate this job as a Partially Observable Markov Choice Course of (POMDP; Kaelbling et al., 1998) in discrete time, with steady state and motion areas (Determine 2). At every time step (t), the surroundings is within the state (boldsymbol{s}_t) (together with the agent’s place and velocity, and the goal’s place). The agent takes an motion (boldsymbol{a}_t) (controlling its linear and angular velocities) to replace (boldsymbol{s}_t) to the subsequent state (boldsymbol{s}_{t+1}) following the environmental dynamics given by the transition likelihood (T(boldsymbol{s}_{t+1}|boldsymbol{s}_{t},boldsymbol{a}_{t})), and receives a reward (r_t) from the surroundings following the reward operate (R(boldsymbol{s}_t,boldsymbol{a}_t)) ((1) if the agent stops contained in the reward zone in any other case (0)).
We use a model-free actor-critic method to studying, with the actor and critic carried out utilizing distinct neural networks. At every (t), the actor receives two sources of inputs (boldsymbol{i}_t) concerning the state: commentary (boldsymbol{o}_t) and final motion (boldsymbol{a}_{t-1}). It then outputs an motion (boldsymbol{a}_t), aiming to maximise the state-action worth (Q_t). This worth is a operate of the state and motion, representing the anticipated discounted rewards when an motion is taken at a state, and future rewards are then amassed from (t) till the trial’s final step. For the reason that floor fact worth is unknown, the critic is used to approximate the worth. Along with receiving the identical inputs (boldsymbol{i}_t) because the actor to deduce the state, the critic additionally takes as inputs the motion (boldsymbol{a}_t) taken by the actor on this state. It then outputs the estimated (Q_t) for this motion, skilled by way of the temporal-difference error (TD error) after receiving the reward (r_t) ((|r_t+gamma Q_{t+1}-Q_{t}|), the place (gamma) denotes the temporal low cost issue). In follow, our algorithm is off-policy and incorporates mechanisms comparable to two critic networks and goal networks as in TD3 (fujimoto et al., 2018) to boost coaching (see Supplies and Strategies in Zhang et al., 2024).

The state (boldsymbol{s}_t) will not be totally observable, so the agent should keep an inside state illustration (perception (b_t)) for deciding (boldsymbol{a}_t) and (Q_t). Each actor and critic endure end-to-end coaching by way of back-propagation with out express goals for shaping (b_t). Consequently, networks are free to study numerous types of (b_t) encoded of their neural actions that support them in reaching their studying goals. Ideally, networks might develop an efficient perception replace rule, e.g., recursive Bayesian estimation, utilizing the 2 sources of proof within the inputs (boldsymbol{i}_t={boldsymbol{o}_t, boldsymbol{a}_{t-1}}). They might predict the state (boldsymbol{s}_t) based mostly on its inside mannequin of the dynamics, its earlier perception (b_{t-1}), and the final self-action (boldsymbol{a}_{t-1}). The second supply is a partial and noisy commentary (boldsymbol{o}_t) of (boldsymbol{s}_t) drawn from the commentary likelihood (O(boldsymbol{o}_t|boldsymbol{s}_t)). Word that the precise (O) within the mind for this job is unknown. For simplicity, we mannequin (boldsymbol{o}_t) as a low-dimensional vector, together with the goal’s location when seen (the primary (300) ms, (Delta t=0.1) s), and the agent’s commentary of its velocities by way of optic move, with velocities topic to Gaussian additive noise.
Actor-critic RL agent
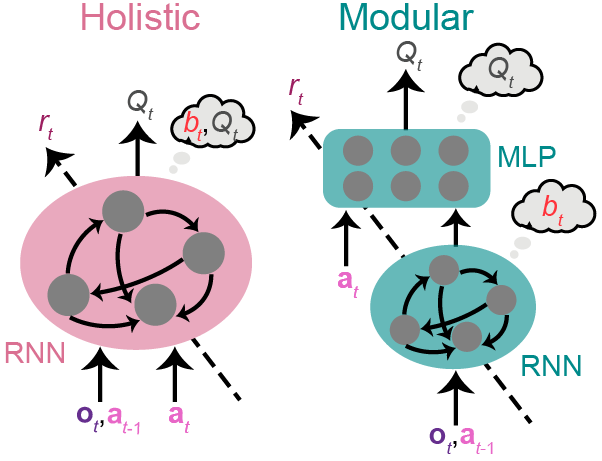
Every RL agent requires an actor and a critic community, and actor and critic networks can have a wide range of architectures. Our aim right here is to analyze whether or not functionally specialised modules present benefits for our job. Subsequently, we designed architectures incorporating modules with distinct ranges of specialization for comparability. The primary structure is a holistic actor/critic, comprising a single module the place all neurons collectively compute the assumption (b_t) and the motion (boldsymbol{a}_t)/worth (Q_t). In distinction, the second structure is a modular actor/critic, that includes modules specialised in computing completely different variables (Determine 3).

The specialization of every module is set as follows.
First, we are able to confine the computation of beliefs. Since computing beliefs concerning the evolving state requires integrating proof over time, a community able to computing perception should possess some type of reminiscence. Recurrent neural networks (RNNs) fulfill this requirement by utilizing a hidden state that evolves over time. In distinction, computations of worth and motion don’t want further reminiscence when the assumption is offered, making memoryless multi-layer perceptrons (MLPs) adequate. Consequently, adopting an structure with an RNN adopted by a memoryless MLP (modular actor/critic in Determine 3) ensures that the computation of perception is completely confined to the RNN.
Second, we are able to confine the computation of the state-action worth (Q_t) for the critic. Since a critic is skilled end-to-end to compute (Q_t), stacking two modules between all inputs and outputs doesn’t restrict the computation of (Q_t) to a particular module. Nevertheless, since (Q_t) is a operate of the motion (boldsymbol{a}_t), we are able to confine the computation of (Q_t) to the second module of the modular critic in Determine 3 by supplying (boldsymbol{a}_t) solely to the second module. This ensures that the primary module, missing entry to the motion, can not precisely compute (Q_t). Subsequently, the modular critic’s RNN is devoted to computing (b_t) and sends it to the MLP devoted to computing (Q_t). This structure enforces modularity.
In addition to the critic, the modular actor has increased specialization than the holistic actor, which lacks confined (b_t) computation. Thought bubbles in Determine 3 denote the variables that may be computed inside every module enforced by way of structure moderately than indicating they’re encoded in every module. For instance, (b_t) in modular architectures is handed to the second module, however an correct (b_t) computation can solely be accomplished within the first RNN module.
Behavioral accuracy
We skilled brokers utilizing all 4 mixtures of those two actor and critic architectures. We seek advice from an agent whose actor and critic are each holistic or each modular as a holistic agent or a modular agent, respectively. Brokers with modular critics demonstrated better consistency throughout numerous random seeds and achieved near-perfect accuracy extra effectively than brokers with holistic critics (Determine 4).

Brokers’ habits was in contrast with that of two monkeys (Determine 5 left) for a consultant set of targets uniformly sampled on the bottom airplane (Determine 5 proper).

We used a Receiver Working Attribute (ROC) evaluation (Lakshminarasimhan et al., 2020) to systematically quantify behavioral accuracy. A psychometric curve for stopping accuracy is constructed from a big consultant dataset by counting the fraction of rewarded trials as a operate of a hypothetical reward boundary measurement (Determine 6 left, strong; radius (65) cm is the true measurement; infinitely small/giant reward boundary results in no/all rewarded trials). A shuffled curve is constructed equally after shuffling targets throughout trials (Determine 6 left, dashed). Then, an ROC curve is obtained by plotting the psychometric curve in opposition to the shuffled curve (Determine 6 proper). An ROC curve with a slope of (1) denotes an opportunity stage (true(=)shuffled) with the realm underneath the curve (AUC) equal to (0.5). Excessive AUC values point out that each one brokers reached good accuracy after coaching (Determine 6 proper, inset).

Though all brokers exhibited excessive cease location accuracy, we’ve got seen distinct traits of their trajectories (Determine 5 left). To quantify these variations, we examined two essential trajectory properties: curvature and size. When examined on the identical sequence of targets because the monkeys skilled, the distinction between trajectories generated by brokers with modular critics and people of monkey B was similar to the variation between trajectories of two monkeys (Determine 7). In distinction, when brokers used holistic critics, the distinction in trajectories from monkey B was a lot bigger, suggesting that modular critics facilitated extra animal-like behaviors.

Behavioral effectivity
Brokers are anticipated to develop environment friendly behaviors, as the worth of their actions will get discounted over time. Subsequently, we assess their effectivity all through the coaching course of by measuring the reward fee, which refers back to the variety of rewarded trials per second. We discovered that brokers with modular critics achieved a lot increased reward charges, which explains their extra animal-like environment friendly trajectories (Determine 8).

Collectively, these outcomes counsel that modular critics present a superior coaching sign in comparison with holistic critics, permitting actors to study extra optimum beliefs and actions. With a poor coaching sign from the holistic critic, the modularization of actors might not improve efficiency. Subsequent, we’ll consider the generalization capabilities of the skilled brokers.
An unseen job
One essential side of sensorimotor mapping is the joystick achieve, which linearly maps motor actions on the joystick (dimensionless, bounded in ([-1,1])) to corresponding velocities within the surroundings. Throughout coaching, the achieve stays fastened at (200) cm/s and (90^{circ})/s for linear and angular parts, known as the (1times) achieve. By growing the achieve to values that weren’t beforehand skilled, we create a achieve job manipulation.
To evaluate generalization talents, monkeys and brokers have been examined with novel features of (1.5times) and (2times) (Determine 9).

Blindly following the identical motion sequence as within the coaching job would trigger the brokers to overshoot (no-generalization speculation: Determine 10 dashed traces). As an alternative, the brokers displayed various levels of adaptive habits (Determine 10 strong traces).

To quantitatively consider behavioral accuracy whereas additionally contemplating over-/under-shooting results, we outlined radial error because the Euclidean distance between the cease and goal areas in every trial, with constructive/unfavorable signal denoting over-/under-shooting. Below the novel features, brokers with modular critics constantly exhibited smaller radial errors than brokers with holistic critics (Determine 11), with the modular agent demonstrating the smallest errors, similar to these noticed in monkeys.

Neural evaluation
Though we’ve got confirmed that brokers with distinct neural architectures exhibit various ranges of generalization within the achieve job, the underlying mechanism stays unclear. We hypothesized that brokers with superior generalization talents ought to generate actions based mostly on extra correct inside beliefs inside their actor networks. Subsequently, the aim subsequent is to quantify the accuracy of beliefs throughout brokers examined on novel features, and to look at the affect of this accuracy on their generalization efficiency.
In the course of the achieve job, we recorded the actions of RNN neurons within the brokers’ actors, as these neurons are answerable for computing the beliefs that underlie actions. To systematically quantify the accuracy of those beliefs, we used linear regression (with (ell_2) regularization) to decode brokers’ areas from the recorded RNN actions for every achieve situation (Determine 12).

We outlined the decoding error, which represents the Euclidean distance between the true and decoded areas, as an indicator of perception accuracy. Whereas all brokers demonstrated small decoding errors underneath the coaching achieve, we discovered that extra holistic brokers battling generalization underneath elevated features additionally displayed diminished accuracy in figuring out their very own location (Determine 13 left). In truth, brokers’ behavioral efficiency correlates with their perception accuracy (Determine 13 proper).

Conclusion
The mind has developed advantageous modular architectures for mastering day by day duties. Right here, we investigated the affect of architectural inductive biases on studying and generalization utilizing deep RL brokers. We posited that an structure with functionally specialised modules would enable brokers to extra effectively study important job variables and their dependencies throughout coaching, after which use this data to assist generalization in novel duties with an analogous construction. To check this, we skilled brokers with architectures that includes distinct module specializations on {a partially} observable navigation job. We discovered that the agent utilizing a modular structure exhibited superior studying of perception and management actions in comparison with brokers with weaker modular specialization.
Moreover, for readers within the full paper, we additionally demonstrated that the modular agent’s beliefs carefully resemble an Prolonged Kalman Filter, appropriately weighting data sources based mostly on their relative reliability. Moreover, we introduced a number of extra architectures with various ranges of modularity and confirmed that better modularity results in higher efficiency.





