How Amazon trains sequential ensemble fashions at scale with Amazon SageMaker Pipelines
Amazon SageMaker Pipelines consists of options that will let you streamline and automate machine studying (ML) workflows. This enables scientists and mannequin builders to give attention to mannequin improvement and fast experimentation reasonably than infrastructure administration
Pipelines provides the flexibility to orchestrate advanced ML workflows with a easy Python SDK with the flexibility to visualise these workflows by means of SageMaker Studio. This helps with information preparation and have engineering duties and mannequin coaching and deployment automation. Pipelines additionally integrates with Amazon SageMaker Automated Mannequin Tuning which may robotically discover the hyperparameter values that lead to the very best performing mannequin, as decided by your chosen metric.
Ensemble fashions have gotten well-liked inside the ML communities. They generate extra correct predictions by means of combining the predictions of a number of fashions. Pipelines can shortly be used to create and end-to-end ML pipeline for ensemble fashions. This permits builders to construct extremely correct fashions whereas sustaining effectivity, and reproducibility.
On this submit, we offer an instance of an ensemble mannequin that was educated and deployed utilizing Pipelines.
Use case overview
Gross sales representatives generate new leads and create alternatives inside Salesforce to trace them. The next utility is a ML method utilizing unsupervised studying to robotically determine use circumstances in every alternative primarily based on varied textual content info, similar to identify, description, particulars, and product service group.
Preliminary evaluation confirmed that use circumstances fluctuate by trade and completely different use circumstances have a really completely different distribution of annualized income and can assist with segmentation. Therefore, a use case is a vital predictive characteristic that may optimize analytics and enhance gross sales advice fashions.
We will deal with the use case identification as a subject identification downside and we discover completely different subject identification fashions similar to Latent Semantic Evaluation (LSA), Latent Dirichlet Allocation (LDA), and BERTopic. In each LSA and LDA, every doc is handled as a group of phrases solely and the order of the phrases or grammatical function doesn’t matter, which can trigger some info loss in figuring out the subject. Furthermore, they require a pre-determined variety of subjects, which was exhausting to find out in our information set. Since, BERTopic overcame the above downside, it was used as a way to determine the use case.
The method makes use of three sequential BERTopic fashions to generate the ultimate clustering in a hierarchical methodology.
Every BERTopic mannequin consists of 4 components:
- Embedding – Totally different embedding strategies can be utilized in BERTopic. On this situation, enter information comes from varied areas and is normally inputted manually. Consequently, we use sentence embedding to make sure scalability and quick processing.
- Dimension discount – We use Uniform Manifold Approximation and Projection (UMAP), which is an unsupervised and nonlinear dimension discount methodology, to cut back excessive dimension textual content vectors.
- Clustering – We use the Balanced Iterative Lowering and Clustering utilizing Hierarchies (BIRCH) methodology to kind completely different use case clusters.
- Key phrase identification – We use class-based TF-IDF to extract probably the most consultant phrases from every cluster.
Sequential ensemble mannequin
There is no such thing as a predetermined variety of subjects, so we set an enter for the variety of clusters to be 15–25 subjects. Upon commentary, a few of the subjects are large and common. Due to this fact, one other layer of the BERTopic mannequin is utilized individually to them. After combining all the newly recognized subjects within the second-layer mannequin and along with the unique subjects from first-layer outcomes, postprocessing is carried out manually to finalize subject identification. Lastly, a 3rd layer is used for a few of the clusters to create sub-topics.
To allow the second- and third-layer fashions to work successfully, you want a mapping file to map outcomes from earlier fashions to particular phrases or phrases. This helps guarantee that the clustering is correct and related.
We’re utilizing Bayesian optimization for hyperparameter tuning and cross-validation to cut back overfitting. The information set incorporates options like alternative identify, alternative particulars, wants, related product identify, product particulars, product teams. The fashions are evaluated utilizing a personalized loss perform, and the very best embedding mannequin is chosen.
Challenges and issues
Listed below are a few of the challenges and issues of this resolution:
- The pipeline’s information preprocessing functionality is essential for enhancing mannequin efficiency. With the flexibility to preprocess incoming information previous to coaching, we are able to guarantee that our fashions are fed with high-quality information. A number of the preprocessing and information cleansing steps embrace changing all textual content column to decrease case, eradicating template components, contractions, URLs, emails, and many others. eradicating non-relevant NER labels, and lemmatizing mixed textual content. The result’s extra correct and dependable predictions.
- We’d like a compute setting that’s extremely scalable in order that we are able to effortlessly deal with and prepare hundreds of thousands of rows of information. This enables us to carry out large-scale information processing and modeling duties with ease and reduces improvement time and prices.
- As a result of each step of the ML workflow requires various useful resource necessities, a versatile and adaptable pipeline is crucial for environment friendly useful resource allocation. We will cut back the general processing time, leading to sooner mannequin improvement and deployment, by optimizing useful resource utilization for every step.
- Working customized scripts for information processing and mannequin coaching requires the supply of required frameworks and dependencies.
- Coordinating the coaching of a number of fashions could be difficult, particularly when every subsequent mannequin will depend on the output of the earlier one. The method of orchestrating the workflow between these fashions could be advanced and time-consuming.
- Following every coaching layer, it’s essential to revise a mapping that displays the subjects produced by the mannequin and use it as an enter for the following mannequin layer.
Resolution overview
On this resolution, the entry level is Amazon SageMaker Studio, which is a web-based built-in improvement setting (IDE) offered by AWS that allows information scientists and ML builders to construct, prepare, and deploy ML fashions at scale in a collaborative and environment friendly method.
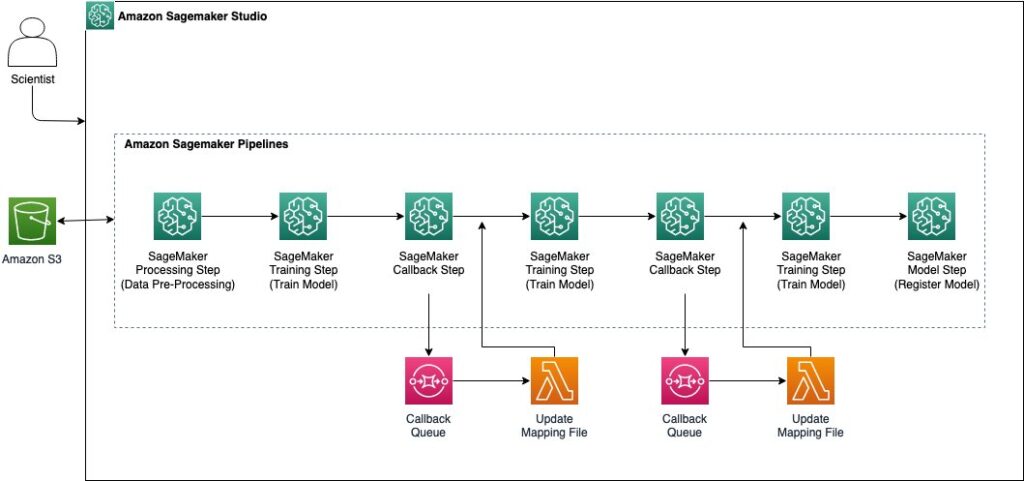
The next diagrams illustrates the high-level structure of the answer.

As a part of the structure, we’re utilizing the next SageMaker pipeline steps:
- SageMaker Processing – This step means that you can preprocess and rework information earlier than coaching. One good thing about this step is the flexibility to make use of built-in algorithms for widespread information transformations and automated scaling of sources. You can even use customized code for advanced information preprocessing, and it means that you can use customized container photographs.
- SageMaker Coaching – This step means that you can prepare ML fashions utilizing SageMaker-built-in algorithms or customized code. You should use distributed coaching to speed up mannequin coaching.
- SageMaker Callback – This step means that you can run customized code throughout the ML workflow, similar to sending notifications or triggering further processing steps. You’ll be able to run exterior processes and resume the pipeline workflow on completion on this step.
- SageMaker Mannequin – This step means that you can create or register mannequin to Amazon SageMaker
Implementation Walkthrough
First, we arrange the Sagemaker pipeline:
import boto3
import sagemaker
# create a Session with customized area (e.g. us-east-1), can be None if not specified
area = "<your-region-name>"
# allocate default S3 bucket for SageMaker session, can be None if not specified
default_bucket = "<your-s3-bucket>"
boto_session = boto3.Session(region_name=area
sagemaker_client = boto_session.shopper("sagemaker")
Initialize a SageMaker Session
sagemaker_session = sagemaker.session.Session(boto_session=boto_session, sagemaker_client=sagemaker_client, default_bucket= default_bucket,)
Set Sagemaker execution function for the session
function = sagemaker.session.get_execution_role(sagemaker_session)
Handle interactions underneath Pipeline Context
pipeline_session = sagemaker.workflow.pipeline_context.PipelineSession(boto_session=boto_session, sagemaker_client=sagemaker_client, default_bucket=default_bucket,)
Outline base picture for scripts to run on
account_id = function.cut up(":")[4]
# create a base picture that deal with dependencies
ecr_repository_name = "<your-base-image-to-run-script>".
tag = "newest"
container_image_uri = "{0}.dkr.ecr.{1}.amazonaws.com/{2}:{3}".format(account_id, area, ecr_repository_name, tag)
The next is an in depth rationalization of the workflow steps:
- Preprocess the information – This includes cleansing and making ready the information for characteristic engineering and splitting the information into prepare, take a look at, and validation units.
import os
BASE_DIR = os.path.dirname(os.path.realpath(__file__))
from sagemaker.workflow.parameters import ParameterString
from sagemaker.workflow.steps import ProcessingStep
from sagemaker.processing import (
ProcessingInput,
ProcessingOutput,
ScriptProcessor,
)
processing_instance_type = ParameterString(
identify="ProcessingInstanceType",
# select an occasion sort appropriate for the job
default_value="ml.m5.4xlarge"
)
script_processor = ScriptProcessor(
image_uri=container_image_uri,
command=["python"],
instance_type=processing_instance_type,
instance_count=1,
function=function,
)
# outline the information preprocess job
step_preprocess = ProcessingStep(
identify="DataPreprocessing",
processor=script_processor,
inputs=[
ProcessingInput(source=BASE_DIR, destination="/opt/ml/processing/input/code/")
],
outputs=[
ProcessingOutput(output_name="data_train", source="/opt/ml/processing/data_train"), # output data and dictionaries etc for later steps
]
code=os.path.be part of(BASE_DIR, "preprocess.py"),
)- Prepare layer 1 BERTopic mannequin – A SageMaker coaching step is used to coach the primary layer of the BERTopic mannequin utilizing an Amazon Elastic Container Registry (Amazon ECR) picture and a customized coaching script.
base_job_prefix="OppUseCase"
from sagemaker.workflow.steps import TrainingStep
from sagemaker.estimator import Estimator
from sagemaker.inputs import TrainingInput
training_instance_type = ParameterString(
identify="TrainingInstanceType",
default_value="ml.m5.4xlarge"
)
# create an estimator for coaching job
estimator_first_layer = Estimator(
image_uri=container_image_uri,
instance_type=training_instance_type,
instance_count=1,
output_path= f"s3://{default_bucket}/{base_job_prefix}/train_first_layer", # S3 bucket the place the coaching output be saved
function=function,
entry_point = "train_first_layer.py"
)
# create coaching job for the estimator primarily based on inputs from data-preprocess step
step_train_first_layer = TrainingStep(
identify="TrainFirstLayerModel",
estimator = estimator_first_layer,
inputs={
TrainingInput(
s3_data=step_preprocess.properties.ProcessingOutputConfig.Outputs[ "data_train" ].S3Output.S3Uri,
),
},
)from sagemaker.workflow.callback_step import CallbackStep, CallbackOutput, CallbackOutputTypeEnum
first_sqs_queue_to_use = ParameterString(
identify="FirstSQSQueue",
default_value= <first_queue_url>, # add queue url
)
first_callback_output = CallbackOutput(output_name="s3_mapping_first_update", output_type=CallbackOutputTypeEnum.String)
step_first_mapping_update = CallbackStep(
identify="FirstMappingUpdate",
sqs_queue_url= first_sqs_queue_to_use,
# Enter arguments that can be offered within the SQS message
inputs={
"input_location": f"s3://{default_bucket}/{base_job_prefix}/mapping",
"output_location": f"s3://{default_bucket}/{base_job_prefix}/ mapping_first_update "
},
outputs=[
first_callback_output,
],
)
step_first_mapping_update.add_depends_on([step_train_first_layer]) # name again is run after the step_train_first_layer
- Prepare layer 2 BERTopic mannequin – One other SageMaker TrainingStep is used to coach the second layer of the BERTopic mannequin utilizing an ECR picture and a customized coaching script.
estimator_second_layer = Estimator(
image_uri=container_image_uri,
instance_type=training_instance_type, # identical sort as of first prepare layer
instance_count=1,
output_path=f"s3://{bucket}/{base_job_prefix}/train_second_layer", # S3 bucket the place the coaching output be saved
function=function,
entry_point = "train_second_layer.py"
)
# create coaching job for the estimator primarily based on inputs from preprocessing, output of earlier name again step and first prepare layer step
step_train_second_layer = TrainingStep(
identify="TrainSecondLayerModel",
estimator = estimator_second_layer,
inputs={
TrainingInput(
s3_data=step_preprocess.properties.ProcessingOutputConfig.Outputs[ "data_train"].S3Output.S3Uri,
),
TrainingInput(
# Output of the earlier name again step
s3_data= step_first_mapping_update.properties.Outputs["s3_mapping_first_update"],
),
TrainingInput(
s3_data=f"s3://{bucket}/{base_job_prefix}/train_first_layer"
),
}
)
- Use a callback step – Much like Step 3, this includes sending a message to an SQS queue which triggers a Lambda perform. The Lambda perform updates the mapping file in Amazon S3 and sends a hit token again to the pipeline to renew its run.
second_sqs_queue_to_use = ParameterString(
identify="SecondSQSQueue",
default_value= <second_queue_url>, # add queue url
)
second_callback_output = CallbackOutput(output_name="s3_mapping_second_update", output_type=CallbackOutputTypeEnum.String)
step_second_mapping_update = CallbackStep(
identify="SecondMappingUpdate",
sqs_queue_url= second_sqs_queue_to_use,
# Enter arguments that can be offered within the SQS message
inputs={
"input_location": f"s3://{default_bucket}/{base_job_prefix}/mapping_first_update ",
"output_location": f"s3://{default_bucket}/{base_job_prefix}/mapping_second_update "
},
outputs=[
second_callback_output,
],
)
step_second_mapping_update.add_depends_on([step_train_second_layer]) # name again is run after the step_train_second_layer
- Prepare layer 3 BERTopic mannequin – This includes fetching the mapping file from Amazon S3 and coaching the third layer of the BERTopic mannequin utilizing an ECR picture and a customized coaching script.
estimator_third_layer = Estimator(
image_uri=container_image_uri,
instance_type=training_instance_type, # identical sort as of prvious two prepare layers
instance_count=1,
output_path=f"s3://{default_bucket}/{base_job_prefix}/train_third_layer", # S3 bucket the place the coaching output be saved
function=function,
entry_point = "train_third_layer.py"
)
# create coaching job for the estimator primarily based on inputs from preprocess step, second callback step and outputs of earlier two prepare layers
step_train_third_layer = TrainingStep(
identify="TrainThirdLayerModel",
estimator = estimator_third_layer,
inputs={
TrainingInput(
s3_data=step_preprocess.properties.ProcessingOutputConfig.Outputs["data_train"].S3Output.S3Uri,
),
TrainingInput(
# s3_data = Output of the earlier name again step
s3_data= step_second_mapping_update.properties.Outputs[' s3_mapping_second_update’],
),
TrainingInput(
s3_data=f"s3://{default_bucket}/{base_job_prefix}/train_first_layer"
),
TrainingInput(
s3_data=f"s3://{default_bucket}/{base_job_prefix}/train_second_layer"
),
}
)
- Register the mannequin – A SageMaker mannequin step is used to register the mannequin within the SageMaker mannequin registry. When the mannequin is registered, you should utilize the mannequin by means of a SageMaker inference pipeline.
from sagemaker.mannequin import Mannequin
from sagemaker.workflow.model_step import ModelStep
mannequin = Mannequin(
image_uri=container_image_uri,
model_data=step_train_third_layer.properties.ModelArtifacts.S3ModelArtifacts,
sagemaker_session=sagemaker_session,
function=function,
)
register_args = mannequin.register(
content_types=["text/csv"],
response_types=["text/csv"],
inference_instances=["ml.c5.9xlarge", "ml.m5.xlarge"],
model_package_group_name=model_package_group_name,
approval_status=model_approval_status,
)
step_register = ModelStep(identify="OppUseCaseRegisterModel", step_args=register_args)
To successfully prepare a BERTopic mannequin and BIRCH and UMAP strategies, you want a customized coaching picture which may present further dependencies and framework required to run the algorithm. For a working pattern of a customized docker picture, discuss with Create a custom Docker container Image for SageMaker
Conclusion
On this submit, we defined how you should utilize big selection of steps provided by SageMaker Pipelines with customized photographs to coach an ensemble mannequin. For extra info on the right way to get began with Pipelines utilizing an present ML Operations (MLOps) template, discuss with Building, automating, managing, and scaling ML workflows using Amazon SageMaker Pipelines.
Concerning the Authors
 Bikramjeet Singh is a Utilized Scientist at AWS Gross sales Insights, Analytics and Information Science (SIADS) Staff, liable for constructing GenAI platform and AI/ML Infrastructure options for ML scientists inside SIADS. Previous to working as an AS, Bikram labored as a Software program Growth Engineer inside SIADS and Alexa AI.
Bikramjeet Singh is a Utilized Scientist at AWS Gross sales Insights, Analytics and Information Science (SIADS) Staff, liable for constructing GenAI platform and AI/ML Infrastructure options for ML scientists inside SIADS. Previous to working as an AS, Bikram labored as a Software program Growth Engineer inside SIADS and Alexa AI.
 Rahul Sharma is a Senior Specialist Options Architect at AWS, serving to AWS clients construct ML and Generative AI options. Previous to becoming a member of AWS, Rahul has spent a number of years within the finance and insurance coverage industries, serving to clients construct information and analytics platforms.
Rahul Sharma is a Senior Specialist Options Architect at AWS, serving to AWS clients construct ML and Generative AI options. Previous to becoming a member of AWS, Rahul has spent a number of years within the finance and insurance coverage industries, serving to clients construct information and analytics platforms.
 Sachin Mishra is a seasoned skilled with 16 years of trade expertise in know-how consulting and software program management roles. Sachin lead the Gross sales Technique Science and Engineering perform at AWS. On this function, he was liable for scaling cognitive analytics for gross sales technique, leveraging superior AI/ML applied sciences to drive insights and optimize enterprise outcomes.
Sachin Mishra is a seasoned skilled with 16 years of trade expertise in know-how consulting and software program management roles. Sachin lead the Gross sales Technique Science and Engineering perform at AWS. On this function, he was liable for scaling cognitive analytics for gross sales technique, leveraging superior AI/ML applied sciences to drive insights and optimize enterprise outcomes.
 Nada Abdalla is a analysis scientist at AWS. Her work and experience span a number of science areas in statistics and ML together with textual content analytics, advice techniques, Bayesian modeling and forecasting. She beforehand labored in academia and obtained her M.Sc and PhD from UCLA in Biostatistics. By her work in academia and trade she printed a number of papers at esteemed statistics journals and utilized ML conferences. In her spare time she enjoys operating and spending time together with her household.
Nada Abdalla is a analysis scientist at AWS. Her work and experience span a number of science areas in statistics and ML together with textual content analytics, advice techniques, Bayesian modeling and forecasting. She beforehand labored in academia and obtained her M.Sc and PhD from UCLA in Biostatistics. By her work in academia and trade she printed a number of papers at esteemed statistics journals and utilized ML conferences. In her spare time she enjoys operating and spending time together with her household.