Speed up your ML lifecycle utilizing the brand new and improved Amazon SageMaker Python SDK – Half 1: ModelTrainer

Amazon SageMaker has redesigned its Python SDK to supply a unified object-oriented interface that makes it simple to work together with SageMaker providers. The brand new SDK is designed with a tiered consumer expertise in thoughts, the place the brand new lower-level SDK (SageMaker Core) supplies entry to full breadth of SageMaker options and configurations, permitting for better flexibility and management for ML engineers. The upper-level abstracted layer is designed for knowledge scientists with restricted AWS experience, providing a simplified interface that hides complicated infrastructure particulars.
On this two-part sequence, we introduce the abstracted layer of the SageMaker Python SDK that means that you can prepare and deploy machine studying (ML) fashions by utilizing the brand new ModelTrainer and the improved ModelBuilder lessons.
On this submit, we concentrate on the ModelTrainer class for simplifying the coaching expertise. The ModelTrainer class supplies important enhancements over the present Estimator class, that are mentioned intimately on this submit. We present you the best way to use the ModelTrainer class to coach your ML fashions, which incorporates executing distributed coaching utilizing a customized script or container. In Part 2, we present you the best way to construct a mannequin and deploy to a SageMaker endpoint utilizing the improved ModelBuilder class.
Advantages of the ModelTrainer class
The brand new ModelTrainer class has been designed to handle usability challenges related to Estimator class. Shifting ahead, ModelTrainer would be the most popular method for mannequin coaching, bringing important enhancements that vastly enhance the consumer expertise. This evolution marks a step in direction of reaching a best-in-class developer expertise for mannequin coaching. The next are the important thing advantages:
- Improved intuitiveness – The ModelTrainer class reduces complexity by consolidating configurations into simply few core parameters. This streamlining minimizes cognitive overload, permitting customers to concentrate on mannequin coaching somewhat than configuration intricacies. Moreover, it employs intuitive config lessons for simple platform interactions.
- Simplified script mode and BYOC – Transitioning from native growth to cloud coaching is now seamless. The ModelTrainer robotically maps supply code, knowledge paths, and parameter specs to the distant execution surroundings, eliminating the necessity for particular handshakes or complicated setup processes.
- Simplified distributed coaching – The ModelTrainer class supplies enhanced flexibility for customers to specify customized instructions and distributed coaching methods, permitting you to immediately present the precise command you need to run in your container via the
commandparameter within theSourceCodeThis method decouples distributed coaching methods from the coaching toolkit and framework-specific estimators. - Improved hyperparameter contracts – The ModelTrainer class passes the coaching job’s hyperparameters as a single surroundings variable, permitting the you to load the hyperparameters utilizing a single
SM_HPSvariable.
To additional clarify every of those advantages, we exhibit with examples within the following sections, and eventually present you the best way to arrange and run distributed coaching for the Meta Llama 3.1 8B mannequin utilizing the brand new ModelTrainer class.
Launch a coaching job utilizing the ModelTrainer class
The ModelTrainer class simplifies the expertise by letting you customise the coaching job, together with offering a customized script, immediately offering a command to run the coaching job, supporting native mode, and far more. Nevertheless, you possibly can spin up a SageMaker coaching job in script mode by offering minimal parameters—the SourceCode and the coaching picture URI.
The next instance illustrates how one can launch a coaching job with your individual customized script by offering simply the script and the coaching picture URI (on this case, PyTorch), and an non-obligatory necessities file. Extra parameters such because the occasion sort and occasion dimension are robotically set by the SDK to preset defaults, and parameters such because the AWS Identity and Access Management (IAM) function and SageMaker session are robotically detected from the present session and consumer’s credentials. Admins and customers can even overwrite the defaults utilizing the SDK defaults configuration file. For the detailed record of pre-set values, discuss with the SDK documentation.
With purpose-built configurations, now you can reuse these objects to create a number of coaching jobs with totally different hyperparameters, for instance, with out having to re-define all of the parameters.
Run the job regionally for experimentation
To run the previous coaching job regionally, you possibly can merely set the training_mode parameter as proven within the following code:
The coaching job runs remotely as a result of training_mode is ready to Mode.LOCAL_CONTAINER. If not explicitly set, the ModelTrainer runs a distant SageMaker coaching job by default. This habits can be enforced by altering the worth to Mode.SAGEMAKER_TRAINING_JOB. For a full record of the obtainable configs, together with compute and networking, discuss with the SDK documentation.
Learn hyperparameters in your customized script
The ModelTrainer helps a number of methods to learn the hyperparameters which might be handed to a coaching job. Along with the present assist to learn the hyperparameters as command line arguments in your customized script, ModelTrainer additionally helps studying the hyperparameters as particular person surroundings variables, prefixed with SM_HPS_<hyperparameter-key>, or as a single surroundings variable dictionary, SM_HPS.
Suppose the next hyperparameters are handed to the coaching job:
You may have the next choices:
- Possibility 1 – Load the hyperparameters right into a single JSON dictionary utilizing the
SM_HPSsurroundings variable in your customized script:
- Possibility 2 – Learn the hyperparameters as particular person surroundings variables, prefixed by
SM_HPas proven within the following code (it is advisable explicitly specify the right enter sort for these variables):
- Possibility 3 – Learn the hyperparameters as AWS CLI arguments utilizing
parse.args:
Run distributed coaching jobs
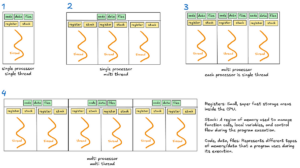
SageMaker helps distributed coaching to assist coaching for deep studying duties corresponding to pure language processing and laptop imaginative and prescient, to run safe and scalable knowledge parallel and mannequin parallel jobs. That is normally achieved by offering the suitable set of parameters when utilizing an Estimator. For instance, to make use of torchrun, you’ll outline the distribution parameter within the PyTorch Estimator and set it to "torch_distributed": {"enabled": True}.
The ModelTrainer class supplies enhanced flexibility for customers to specify customized instructions immediately via the command parameter within the SourceCode class, and helps torchrun, torchrun smp, and the MPI methods. This functionality is especially helpful when it is advisable launch a job with a customized launcher command that’s not supported by the coaching toolkit.
Within the following instance, we present the best way to fine-tune the most recent Meta Llama 3.1 8B mannequin utilizing the default launcher script utilizing Torchrun on a customized dataset that’s preprocessed and saved in an Amazon Simple Storage Service (Amazon S3) location:
Should you wished to customise your torchrun launcher script, you may also immediately present the instructions utilizing the command parameter:
For extra examples and end-to-end ML workflows utilizing the SageMaker ModelTrainer, discuss with the GitHub repo.
Conclusion
The newly launched SageMaker ModelTrainer class simplifies the consumer expertise by decreasing the variety of parameters, introducing intuitive configurations, and supporting complicated setups like bringing your individual container and working distributed coaching. Knowledge scientists can even seamlessly transition from native coaching to distant coaching and coaching on a number of nodes utilizing the ModelTrainer.
We encourage you to check out the ModelTrainer class by referring to the SDK documentation and pattern notebooks on the GitHub repo. The ModelTrainer class is on the market from the SageMaker SDK v2.x onwards, at no further cost. In Part 2 of this sequence, we present you the best way to construct a mannequin and deploy to a SageMaker endpoint utilizing the improved ModelBuilder class.
Concerning the Authors
 Durga Sury is a Senior Options Architect on the Amazon SageMaker staff. Over the previous 5 years, she has labored with a number of enterprise prospects to arrange a safe, scalable AI/ML platform constructed on SageMaker.
Durga Sury is a Senior Options Architect on the Amazon SageMaker staff. Over the previous 5 years, she has labored with a number of enterprise prospects to arrange a safe, scalable AI/ML platform constructed on SageMaker.
 Shweta Singh is a Senior Product Supervisor within the Amazon SageMaker Machine Studying (ML) platform staff at AWS, main SageMaker Python SDK. She has labored in a number of product roles in Amazon for over 5 years. She has a Bachelor of Science diploma in Laptop Engineering and a Masters of Science in Monetary Engineering, each from New York College.
Shweta Singh is a Senior Product Supervisor within the Amazon SageMaker Machine Studying (ML) platform staff at AWS, main SageMaker Python SDK. She has labored in a number of product roles in Amazon for over 5 years. She has a Bachelor of Science diploma in Laptop Engineering and a Masters of Science in Monetary Engineering, each from New York College.