A information to Amazon Bedrock Mannequin Distillation (preview)

When utilizing generative AI, attaining excessive efficiency with low latency fashions which are cost-efficient is commonly a problem, as a result of these targets can conflict with one another. With the newly launched Amazon Bedrock Mannequin Distillation characteristic, you should utilize smaller, sooner, and cost-efficient fashions that ship use-case particular accuracy that’s corresponding to the most important and most succesful fashions in Amazon Bedrock for these particular use instances.
Mannequin distillation is the method of transferring information from a extra succesful superior mannequin (trainer) to a smaller mannequin (scholar), which is quicker and extra value environment friendly to make the coed mannequin as performant because the trainer for a selected use-case. To switch information, your use-case particular prompts are used to first generate responses from the trainer mannequin, after which the trainer responses are used to fine-tune the coed mannequin.
Amazon Bedrock is a completely managed service that provides a alternative of high-performing foundation models (FMs) together with a broad set of capabilities to construct generative AI functions, simplifying improvement with safety, privateness, and accountable AI. With Amazon Bedrock Mannequin Distillation, now you can customise fashions in your use case utilizing artificial information generated by extremely succesful fashions. At preview, Amazon Bedrock Mannequin Distillation affords help for 3 mannequin suppliers: Amazon, Anthropic, and Meta. The trainer and scholar fashions ought to be from the identical mannequin supplier.
This publish introduces the workflow of Amazon Bedrock Mannequin Distillation. We first introduce the overall idea of mannequin distillation in Amazon Bedrock, after which deal with the vital steps in mannequin distillation, together with organising permissions, deciding on the fashions, offering enter dataset, commencing the mannequin distillation jobs, and conducting analysis and deployment of the coed fashions after mannequin distillation.
Key advantages of Amazon Bedrock Mannequin Distillation
- Effectivity: Distilled fashions present excessive use-case particular accuracy corresponding to essentially the most succesful fashions whereas being as quick as among the smallest fashions.
- Value optimization: Inference from distilled fashions is cheaper in comparison with bigger superior fashions.
- Superior customization: Amazon Bedrock Mannequin Distillation removes the necessity to create a labeled dataset for fine-tuning. Amazon Bedrock automates the advanced means of producing high-quality trainer responses to create a various and high-volume coaching dataset to make use of for fine-tuning the coed mannequin, by including information synthesis (as much as 15 thousand prompt-response pairs) and augmentation methods behind the scenes that robotically adapt to your use case, optimizing the distilled mannequin’s efficiency.
- Ease of use: Amazon Bedrock Mannequin Distillation affords a single workflow that automates the technology of trainer responses, provides information synthesis to enhance trainer responses, and fine-tunes the coed mannequin with optimized hyperparameter tuning.
Use instances for Amazon Bedrock Mannequin Distillation
By distilling information from bigger fashions into smaller, extra agile ones, organizations are empowered to develop optimized AI options to realize the next return on their investments. Listed below are some functions the place a distilled mannequin could make a big impression:
- Retrieval Augmented Technology (RAG): Allow enterprise vast search and information retrieval techniques that may deal with 1000’s of concurrent queries at a fraction of the price of bigger fashions, making widespread deployment extra possible.
- Doc summarization: Course of huge quantities of enterprise content material in actual time, reminiscent of summarizing 1000’s of buyer name transcripts every day, enabling insights at a scale beforehand restricted by latency constraints.
- Chatbot deployments: Energy customer support chatbots that may deal with 1000’s of concurrent real-time conversations with constantly low latency, delivering the standard of a bigger mannequin however at considerably decrease operational prices.
- Textual content classification: Construct sooner fashions for categorizing excessive volumes of concurrent help tickets, emails, or buyer suggestions at scale; or for effectively routing requests to bigger fashions when crucial. This method can considerably scale back processing prices whereas sustaining classification accuracy, enabling real-time responsiveness to buyer wants.
Amazon Bedrock Mannequin Distillation workflow
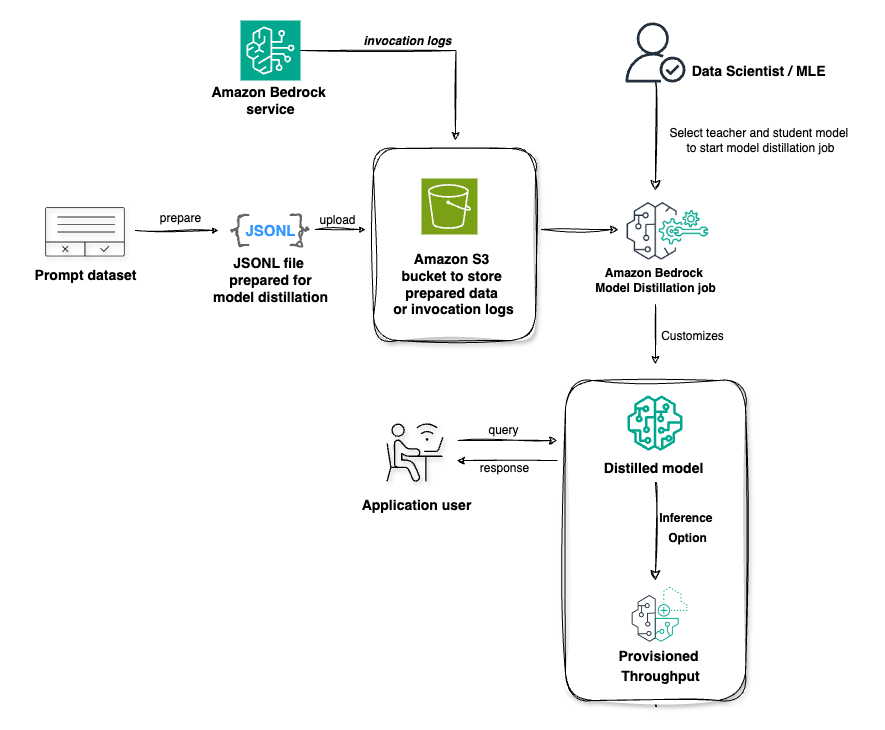
Amazon Bedrock affords two choices for utilizing Amazon Bedrock Mannequin Distillation. Within the first choice, you possibly can create a distilled mannequin by offering your manufacturing information utilizing historic invocation logs out of your earlier interactions inside Amazon Bedrock. In a manufacturing surroundings, you proceed to make use of the prevailing Amazon Bedrock Inference APIs, such because the InvokeModel or Converse API, and activate invocation logs that retailer mannequin enter information (prompts) and mannequin output information (responses). You possibly can optionally add request metadata to those inference requests to filter your invocation logs for particular use instances. By default, Amazon Bedrock reads solely the prompts from the invocation logs and can generate responses from the trainer mannequin chosen in your distillation job. On this state of affairs, Amazon Bedrock would possibly apply proprietary information synthesis methods to generate numerous and high-quality responses from the trainer mannequin to enhance the fine-tuning dataset, doubtlessly enhancing the efficiency of the distilled scholar mannequin. The scholar mannequin is then fine-tuned utilizing the immediate and trainer response pairs. Optionally, you possibly can configure Amazon Bedrock to extract each the immediate and response from the invocation logs. On this state of affairs, the trainer mannequin chosen within the distillation job should match the trainer mannequin within the invocation log. No information synthesis methods are utilized. The prompt-response pairs are taken as is from the invocation logs and the coed mannequin is fine-tuned.
Within the second choice, you possibly can add your use-case particular prompts by immediately importing a JSONL file to Amazon Simple Storage Service (Amazon S3) containing your use-case particular prompts or labelled prompt-completion pairs. Amazon Bedrock generates responses from the trainer mannequin for the offered prompts. For those who present a human-generated labeled dataset representing the bottom reality, Amazon Bedrock can use these prompt-response pairs as golden examples to generate higher trainer responses. The scholar mannequin is then fine-tuned utilizing the prompt-response pairs generated by the trainer mannequin.
Stipulations
To make use of the mannequin distillation characteristic, just be sure you have glad the next necessities:
- An lively AWS account.
- Chosen trainer and scholar fashions enabled in Amazon Bedrock. You possibly can affirm that the fashions are enabled on the Mannequin entry web page of the Amazon Bedrock console.
- Verify the AWS Regions the place the mannequin is out there and quotas.
- To create a mannequin distillation job utilizing Amazon Bedrock, you might want to create an AWS Identity and Access Management (IAM) function with the next permissions:
- A trust relationship that permits Amazon Bedrock to imagine the function
- Permissions to entry enter information and historic invocation logs in Amazon S3
- Permissions to write down output information to Amazon S3
- Optionally, permissions to decrypt an AWS Key Management Service (AWS KMS) key you probably have encrypted assets with a KMS key
- An S3 bucket the place your distillation job output metrics are saved.
- For those who present an enter dataset for distillation, use Amazon S3 to retailer your enter information
- Alternatively, in case you use a historic invocation log for mannequin distillation, ensure to allow the invocation log within the AWS Administration Console and that the historic invocation logging is saved in an S3 location. To take action, go to the Amazon Bedrock console and select Settings on the backside of left nook, as proven within the screenshot:
- On the subsequent web page, be sure that Mannequin invocation logging is enabled and choose S3 solely because the logging vacation spot. (Optionally, you possibly can choose Each S3 and CloudWatch Logs because the vacation spot.)
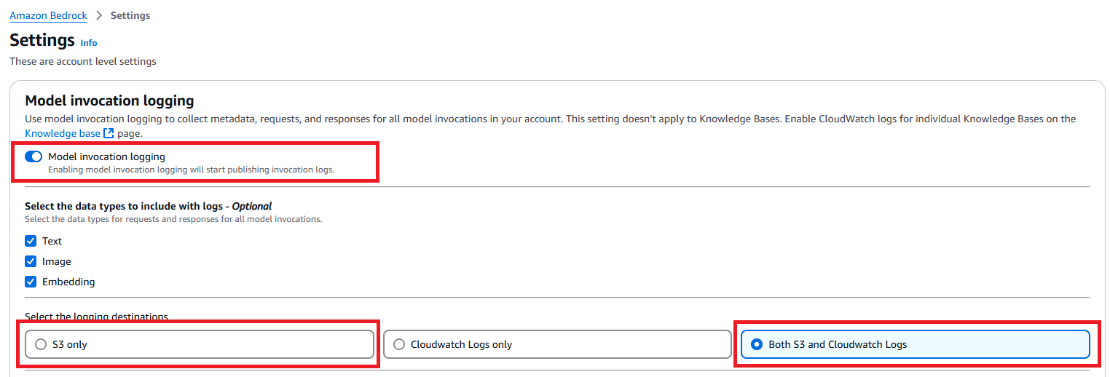
- Alternatively, in case you use a historic invocation log for mannequin distillation, ensure to allow the invocation log within the AWS Administration Console and that the historic invocation logging is saved in an S3 location. To take action, go to the Amazon Bedrock console and select Settings on the backside of left nook, as proven within the screenshot:
- Guarantee that you’ve got enough quota for working a Provisioned Throughput throughout inference. Go to the AWS Service Quotas console, and test the next quotas:
- Mannequin items no-commitment Provisioned Throughputs throughout customized fashions
- Mannequin items per provisioned mannequin for [student model name]
Each of those fields must have sufficient quota to help your Provisioned Throughput mannequin unit. Request a quota improve if essential to accommodate your anticipated inference workload.
Mannequin choice
At the moment, Amazon Bedrock Mannequin Distillation helps student-teacher combos inside the identical mannequin suppliers (for instance, Amazon, Anthropic, or Meta).
Deciding on the best fashions for distillation is essential. The method entails selecting a trainer mannequin for artificial information technology and a scholar mannequin to study from the trainer’s output. The trainer mannequin is usually bigger and extra succesful, whereas the coed mannequin is smaller, sooner, and extra cost-efficient.
When deciding on fashions, contemplate three key dimensions: efficiency, latency and value. These elements are interconnected and adjusting one can have an effect on the others.
- Efficiency: Set up clear efficiency targets in your use case, reminiscent of accuracy, consistency, or harmlessness. Choose a trainer mannequin that meets or exceeds your required efficiency degree. The expectation from distillation is to extend the coed mannequin’s efficiency to method that of the trainer mannequin.
- Latency: Select a scholar mannequin that meets your latency necessities. The ultimate distilled mannequin can have the identical latency profile as the coed mannequin that you choose.
- Value: Think about the entire value of possession (TCO) throughout the mannequin’s lifecycle, together with trainer mannequin inference for artificial information technology, scholar mannequin fine-tuning, inference value for the distilled mannequin, and customized mannequin storage.
Distillation enter dataset
There are two principal methods to organize use-case particular enter information for distillation in Amazon Bedrock:
- Importing a JSONL file to Amazon S3
- Utilizing historic invocation logs
Importing a JSONL file to S3
In case you have a dataset within the JSON Strains (JSONL) format, you possibly can add it to an S3 bucket. Every file on this JSONL file use the next construction:
Particularly, every file has a compulsory area, schemaVersion, that will need to have the worth bedrock-conversation-2024 at this launch. The file can optionally embody a system immediate that signifies the function assigned to the mannequin. Within the messages area, the person function is required, containing the enter immediate offered to the mannequin, whereas the assistant function, containing the specified response, is non-compulsory.
At preview, Anthropic and Meta fashions solely settle for single-turn dialog prompts, which means you possibly can solely have one person immediate. The Amazon (Nova) fashions help multi-turn conversations, permitting you to offer a number of person and assistant exchanges inside one file.
Utilizing historic invocation logs
Alternatively, you should utilize your historic invocation logs saved in Amazon S3 for mannequin distillation. These logs seize the prompts, responses, and metadata out of your earlier mannequin interactions, making them a priceless supply of information. To make use of this methodology:
- Allow invocation logging: Just be sure you’ve enabled invocation logging in your account. For those who haven’t achieved this but, see to the stipulations part for directions.
- Add metadata to mannequin invocations: When invoking fashions utilizing the InvokeModel or Converse API, embody a
requestMetadataarea with key worthparis. This lets you categorize and filter your interactions later. An instance for utilizing theConverseAPI could be:
A particular instance for the requestMetadata area for a pattern use case might be:
- Choose logs for distillation: When making a mannequin customization job, you possibly can specify filters to pick which invocation logs to make use of. The API helps varied filtering choices:
- Embody particular logs:
- Exclude particular logs:
- Mix a number of situations:
- Use
ORlogic:
By following these steps, you possibly can exactly management which information out of your invocation logs ought to be used for distillation, enabling you to focus on particular use instances, initiatives, or workflows.
Deciding on the best information
When deciding on information for distillation, whether or not by a brand new coaching JSONL file or historic invocation logs, it’s essential to decide on prompts and responses which are related to your use case. The standard and variety of the information will immediately impression the efficiency of the distilled mannequin.
Typically, you must purpose to incorporate prompts that cowl a variety of matters and situations related to your use case, extra importantly, a very good method additionally consists of optimizing prompts for the trainer mannequin to get higher responses so distillation can carry out prime quality information switch from trainer to scholar. Particularly, to be used instances like RAG, ensure to incorporate prompts that include related context for use by the mannequin. For duties that require a selected response fashion or format, it’s vital to incorporate examples that adhere to the specified fashion or format.
Be conscious when curating the information used for distillation to assist be sure that the distilled mannequin learns essentially the most related and priceless information from the trainer mannequin, optimizing its efficiency in your particular use case.
Run the mannequin distillation
You can begin a distillation job both by the Amazon Bedrock console or programmatically utilizing the Amazon Bedrock API. The distillation course of requires coaching information, both by importing coaching information in JSONL format to Amazon S3, or by utilizing historic mannequin invocation logs, as we ready within the prior part.
Earlier than beginning a mannequin distillation job, just be sure you’re working inside the boundaries of Amazon Bedrock distillation service quotas.
Let’s discover learn how to begin distillation jobs utilizing completely different approaches. Within the following instance, we use Llama 3.1 70B because the trainer mannequin and Llama 3.1 8B as scholar mannequin.
Begin a distillation job utilizing the console
Amazon Bedrock Mannequin Distillation gives you with an choice to run a distillation job by a guided person interface within the console. To start out a distillation job by the console, observe these steps:
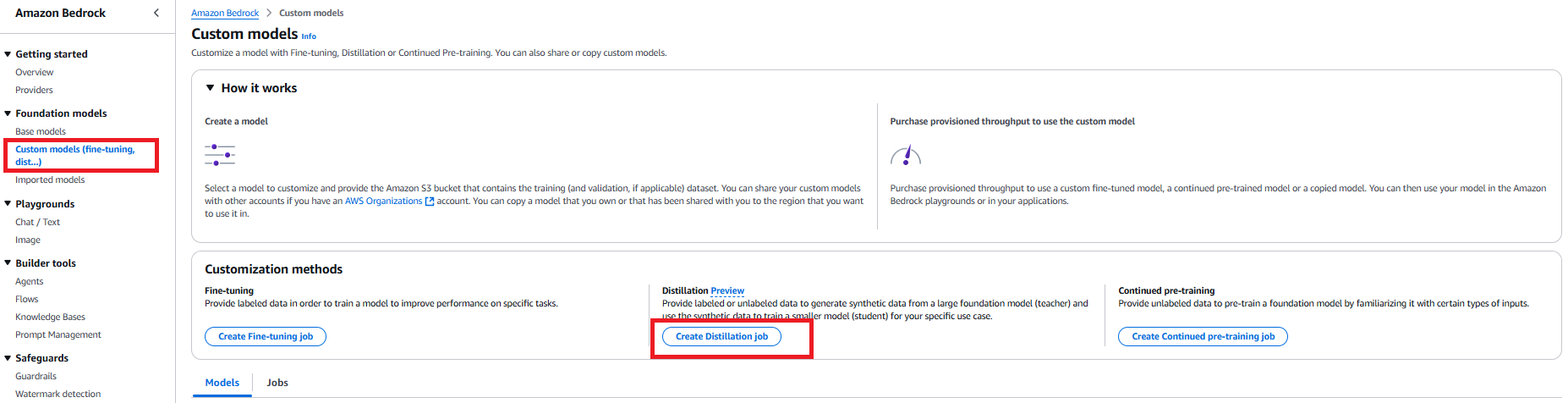
- Go to the Amazon Bedrock console. Select Basis fashions within the navigation pane, then select Customized fashions. Within the Customization strategies part, select Create Distillation job.
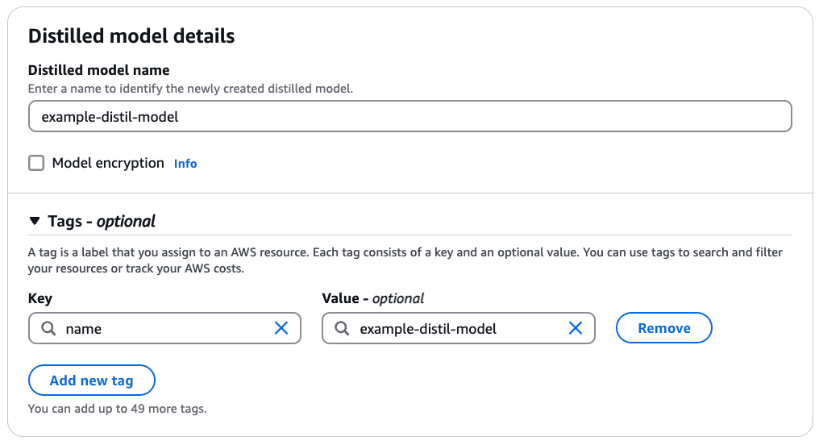
- For Distilled mannequin identify, enter a reputation for the mannequin. Choose Mannequin encryption so as to add a KMS key. Optionally, broaden the Tags part so as to add tags for monitoring.
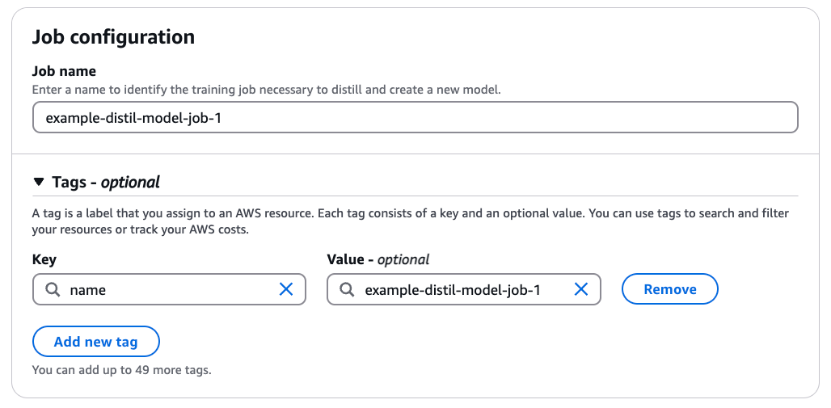
- For Job identify, enter a reputation for the coaching job. Optionally, broaden the Tags part so as to add tags for monitoring.
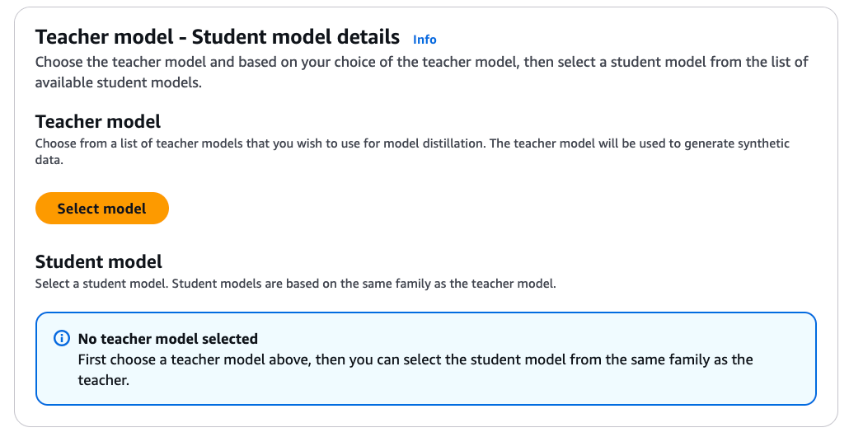
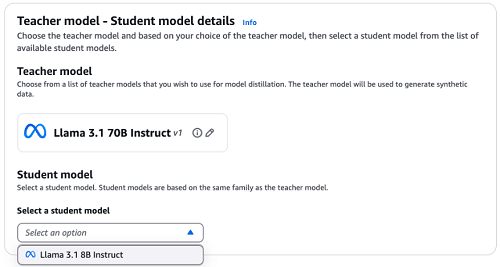
- Select Choose mannequin to choose the trainer mannequin of your alternative.
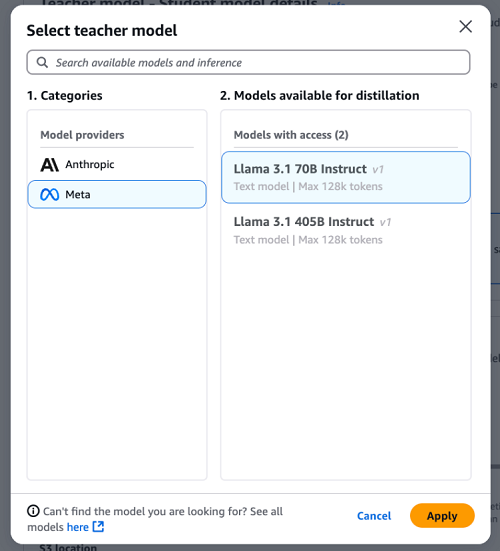
- For Classes, select Meta mannequin household. For Fashions accessible for distillation, choose Llama 3.1 70B Instruct. Select Apply.
- Open the drop down below Choose a scholar mannequin. For this instance, choose Llama 3.1 8B Instruct.
- Specify the Max response size by the slider or immediately within the enter area. This configuration can be used as an inference parameter for the artificial information technology by the trainer mannequin.
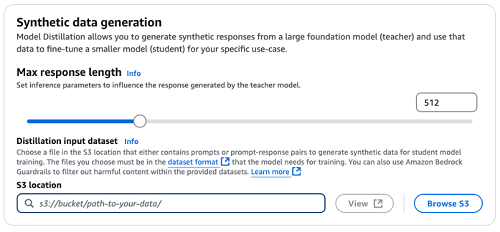
- As mentioned within the prior part, there are two approaches to offer a distillation enter dataset.

- For those who plan to immediately add JSONL file to S3, add your coaching dataset to the S3 bucket you ready in prerequisite part. Beneath Distillation enter dataset, specify the Amazon S3 location in your coaching dataset.
- For those who plan to make use of historic invocation logs, choose Present entry to invocation logs first, then specify the S3 location in your saved invocation logs. You possibly can add several types of metadata filters to pick solely the invocation logs related to the use case.
You may also configure Amazon Bedrock to solely learn your prompts or use the prompt-response pairs. For those who selected to solely learn the prompts, Amazon Bedrock will regenerate responses from the trainer mannequin; or in case you select to make use of prompt-response pairs, Amazon Bedrock will use the accessible response in logs with out regenerating it.
Be sure that the trainer mannequin chosen for distillation and the mannequin used within the invocation logs is identical in order for you Amazon Bedrock to re-use the responses from invocation logs.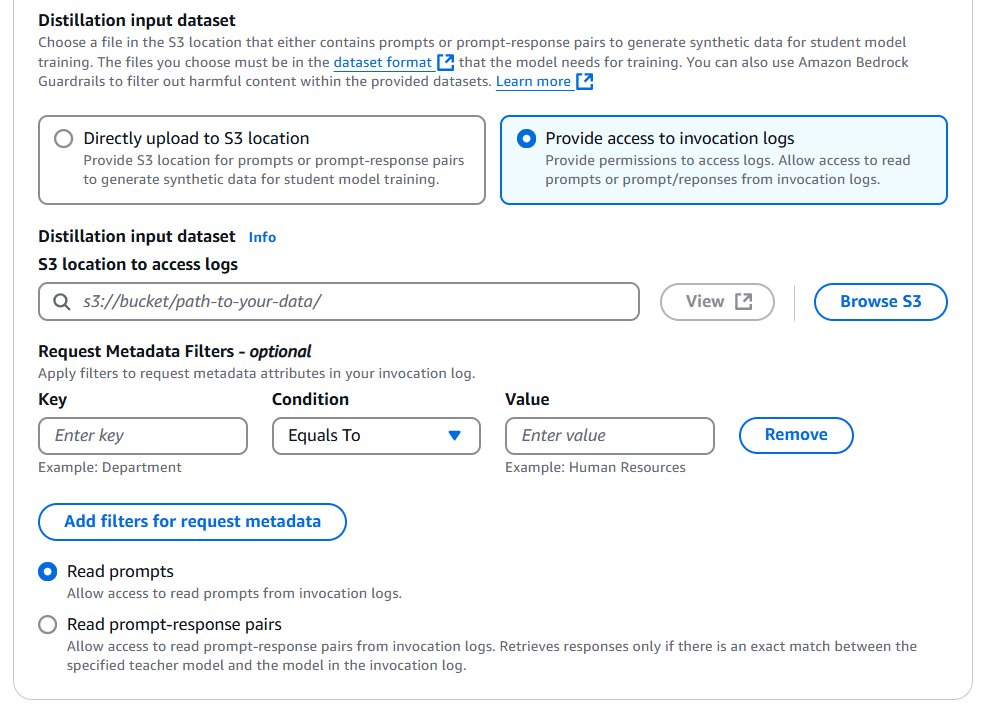
- Optionally, broaden the VPC settings part to specify a VPC that defines the digital networking surroundings for this distillation job.
- Beneath Distillation output metrics information, for S3 location, enter the S3 path for the bucket the place you need the coaching output metrics of the distilled mannequin to be saved.

- Beneath Service entry, choose a way to offer Amazon Bedrock with the required IAM permissions to carry out the distillation. This occurs by task of a service function. You possibly can choose Use an present service function you probably have already outlined a job with fine-grained IAM insurance policies. In order for you a brand new function to be created, choose Create and use a brand new service function and specify a Service function identify. View permission particulars gives you with a complete overview of IAM permissions required.
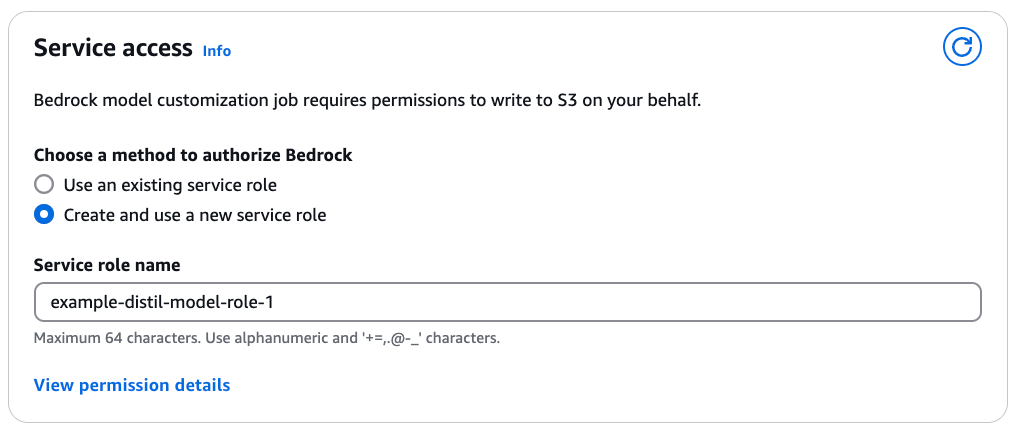
- After you’ve added all of the required configurations for the Amazon Bedrock Mannequin Distillation job, select Create Distillation job.

- When the distillation job begins, you possibly can see the standing of the job (Coaching, Full, or e) below Jobs.
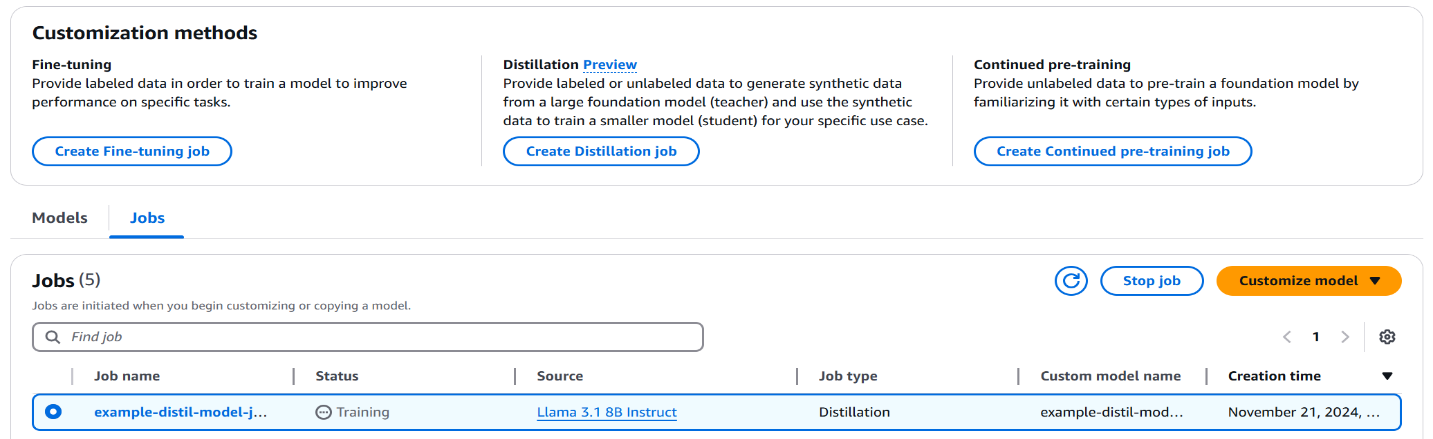
- Now choose your distillation job. Because the distillation job progresses, yow will discover extra details about the job, together with job creation time, standing, job period, teacher-student configuration and the distillation enter dataset.
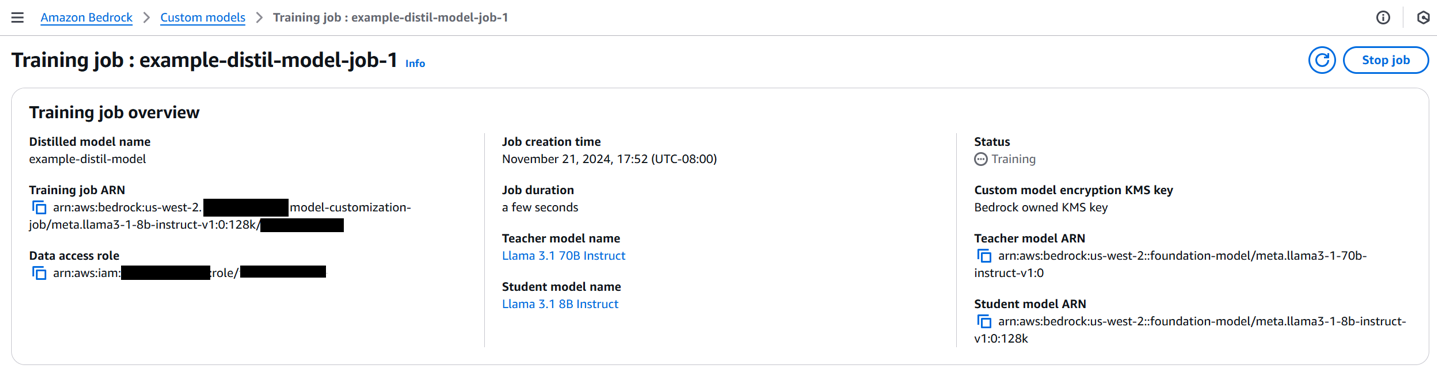
Begin a distillation job with S3 JSONL information utilizing an API
To make use of an API to begin a distillation job utilizing coaching information saved in an S3 bucket, observe these steps:
- First, create and configure an Amazon Bedrock consumer:
- Create the distillation job utilizing
create_model_customization_job: - You possibly can monitor the progress of distillation job by offering the
job_arnof your mannequin distillation job:
Begin a distillation job with an invocation log utilizing an API
To make use of mannequin invocation logs as coaching information, just be sure you have collected sufficient invocation logs in your S3 bucket. First, outline the log filter primarily based on the supporting logic referred to within the information preparation part:
The invocationLogsConfig means that you can specify the Amazon S3 location the place your invocation logs are saved, whether or not to make use of prompt-response pairs from the logs or generate new responses from the trainer mannequin, and filters to pick particular logs primarily based on request metadata.
Then, create the distillation job utilizing the identical create_model_customization_job API (configuration parameters are outlined as was achieved within the prior part):
Deploy and consider the mannequin distillation
After distilling the mannequin, you possibly can consider the distillation metrics recorded in the course of the course of. These metrics are saved within the specified S3 bucket for analysis functions, which incorporates step-wise coaching metrics with columns step_number, epoch_number and training_loss.
If you’re glad with the distillation metrics, you should buy a Provisioned Throughput to deploy your fine-tuned mannequin, permitting you to reap the benefits of the improved efficiency and specialised capabilities of the distilled mannequin in your functions. Provisioned throughput refers back to the quantity and fee of inputs and outputs {that a} mannequin processes and returns. To make use of a distilled mannequin, you will need to buy a Provisioned Throughput, which is billed hourly. The pricing for a Provisioned Throughput relies on the next elements:
- The chosen scholar mannequin.
- The variety of mannequin items (MUs) specified for the Provisioned Throughput. An MU is a unit that specifies the throughput capability for a given mannequin; every MU defines the variety of enter tokens it will possibly course of and output tokens it will possibly generate throughout all requests inside 1 minute.
- The dedication period, which could be no dedication, 1 month, or 6 months. Longer commitments supply extra discounted hourly charges.
After the Provisioned Throughput is ready up, you should utilize the InvokeModel or Converse API to invoke the distilled mannequin, much like how the bottom mannequin is invoked. This gives a seamless transition and maintains compatibility with present functions or workflows.
It’s essential to guage the efficiency of the distilled mannequin to be sure that it meets the specified standards and outperforms in particular duties. You possibly can conduct varied evaluations, together with evaluating the distilled mannequin with the trainer mannequin to validate its efficiency.
Deploy the distilled mannequin utilizing the Amazon Bedrock console
To deploy the distilled mannequin utilizing the Amazon Bedrock console, full the next steps:
- On the Amazon Bedrock console, select Customized fashions within the navigation pane.
- Choose the distilled mannequin and select Buy provisioned throughput.
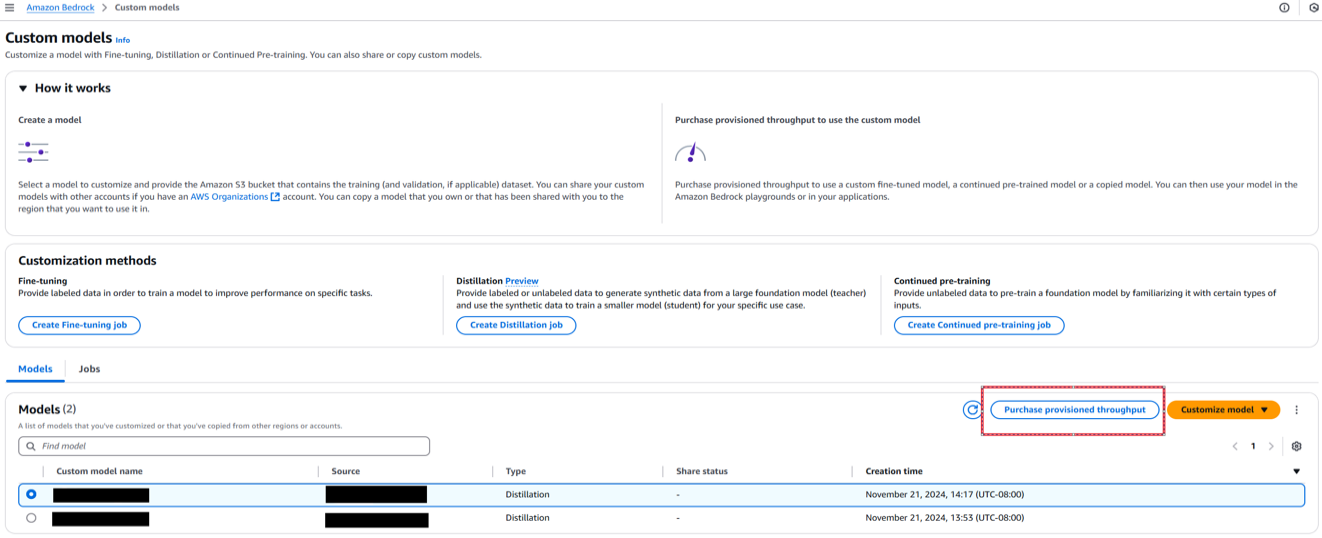
- For Provisioned throughput identify, enter a reputation.
- Select the mannequin that you just need to deploy.
- For Dedication time period, choose your degree of dedication (for this publish, we select No dedication).
- Select Buy provisioned throughput.
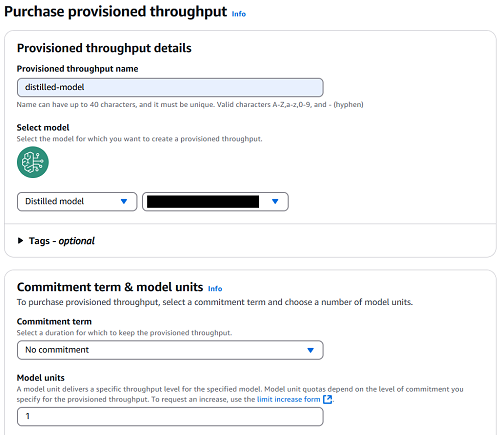
After the distilled mannequin has been deployed utilizing a Provisioned Throughput, you possibly can see the mannequin standing as In Service if you go to the Provisioned throughput web page on the Amazon Bedrock console.

You possibly can work together with this distilled mannequin in Amazon Bedrock playground, choose Chat/textual content, then choose the distilled mannequin in Customized & Managed endpoints.
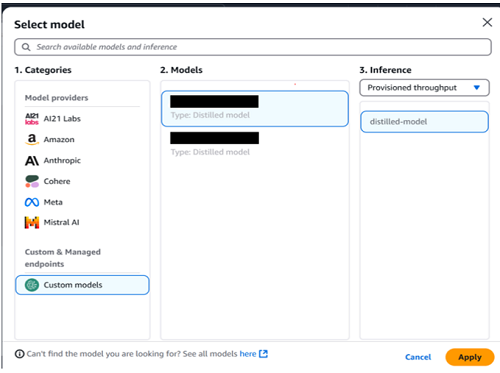
Deploy the distilled mannequin utilizing the Amazon Bedrock API
To deploy the distilled mannequin utilizing the Amazon Bedrock API, full the next steps:
- Retrieve the distilled mannequin ID from the job’s output, and create a Provisioned Throughput mannequin occasion with the specified mannequin items:
- Test the standing of your Provisioned Throughput mannequin by working:
- When the Provisioned Throughput mannequin is prepared, you possibly can name the mannequin by utilizing the
InvokeModelorConverseAPI to generate textual content utilizing the distilled mannequin:
By following these steps, you possibly can deploy and use your distilled mannequin by Amazon Bedrock API, permitting you to generate an environment friendly and high-performing scholar mannequin tailor-made to your use instances. After deploying the distilled mannequin, you should utilize it for inference in varied Amazon Bedrock companies, together with Knowledge Base inference, Playground, and every other service the place customized fashions can be utilized for inference.
Conclusion
Amazon Bedrock Mannequin Distillation allows you to create environment friendly, cost-optimized scholar fashions that intently match the efficiency of bigger trainer fashions for particular use instances. By automating the advanced course of of information switch from superior fashions to smaller fashions, Amazon Bedrock simplifies the deployment of sooner and cheaper AI options with out sacrificing accuracy. Clients can profit from effectivity features, ease of use, science innovation, and unique entry to distill fashions throughout suppliers reminiscent of Anthropic and Amazon. With Amazon Bedrock Mannequin Distillation, enterprises can use the ability of basis fashions whereas optimizing for latency, value, and useful resource constraints to drive AI innovation throughout industries reminiscent of monetary companies, content material moderation, healthcare, and customer support.
We encourage you to begin your journey in the direction of cost-effective AI innovation by visiting the Amazon Bedrock console and discovering how mannequin distillation can remodel your small business.
For extra assets, see the next:
In regards to the authors
 Yanyan Zhang is a Senior Generative AI Information Scientist at Amazon Net Providers, the place she has been engaged on cutting-edge AI/ML applied sciences as a Generative AI Specialist, serving to clients use generative AI to realize their desired outcomes. Yanyan graduated from Texas A&M College with a PhD in Electrical Engineering. Exterior of labor, she loves touring, figuring out, and exploring new issues.
Yanyan Zhang is a Senior Generative AI Information Scientist at Amazon Net Providers, the place she has been engaged on cutting-edge AI/ML applied sciences as a Generative AI Specialist, serving to clients use generative AI to realize their desired outcomes. Yanyan graduated from Texas A&M College with a PhD in Electrical Engineering. Exterior of labor, she loves touring, figuring out, and exploring new issues.
 Ishan Singh is a Generative AI Information Scientist at Amazon Net Providers, the place he helps clients construct progressive and accountable generative AI options and merchandise. With a robust background in AI/ML, Ishan focuses on constructing Generative AI options that drive enterprise worth. Exterior of labor, he enjoys taking part in volleyball, exploring native bike trails, and spending time together with his spouse and canine, Beau.
Ishan Singh is a Generative AI Information Scientist at Amazon Net Providers, the place he helps clients construct progressive and accountable generative AI options and merchandise. With a robust background in AI/ML, Ishan focuses on constructing Generative AI options that drive enterprise worth. Exterior of labor, he enjoys taking part in volleyball, exploring native bike trails, and spending time together with his spouse and canine, Beau.
 Aris Tsakpinis is a Specialist Options Architect for AI & Machine Studying with a particular deal with pure language processing (NLP), massive language fashions (LLMs), and generative AI. In his free time he’s pursuing a PhD in ML Engineering at College of Regensburg, focussing on utilized NLP within the science area.
Aris Tsakpinis is a Specialist Options Architect for AI & Machine Studying with a particular deal with pure language processing (NLP), massive language fashions (LLMs), and generative AI. In his free time he’s pursuing a PhD in ML Engineering at College of Regensburg, focussing on utilized NLP within the science area.
 Shreeya Sharma is a Senior Technical Product Supervisor at AWS, the place she has been engaged on leveraging the ability of Generative AI to ship progressive and customer-centric merchandise. Shreeya holds a grasp’s diploma from Duke College. Exterior of labor, she loves touring, dancing, and singing.
Shreeya Sharma is a Senior Technical Product Supervisor at AWS, the place she has been engaged on leveraging the ability of Generative AI to ship progressive and customer-centric merchandise. Shreeya holds a grasp’s diploma from Duke College. Exterior of labor, she loves touring, dancing, and singing.
 Sovik Kumar Nath is an AI/ML and Generative AI Senior Options Architect with AWS. He has intensive expertise designing end-to-end machine studying and enterprise analytics options in finance, operations, advertising and marketing, healthcare, provide chain administration, and IoT. He has double grasp’s levels from the College of South Florida and College of Fribourg, Switzerland, and a bachelor’s diploma from the Indian Institute of Expertise, Kharagpur. Exterior of labor, Sovik enjoys touring, and adventures.
Sovik Kumar Nath is an AI/ML and Generative AI Senior Options Architect with AWS. He has intensive expertise designing end-to-end machine studying and enterprise analytics options in finance, operations, advertising and marketing, healthcare, provide chain administration, and IoT. He has double grasp’s levels from the College of South Florida and College of Fribourg, Switzerland, and a bachelor’s diploma from the Indian Institute of Expertise, Kharagpur. Exterior of labor, Sovik enjoys touring, and adventures.





