Accelerating ML experimentation with enhanced safety: AWS PrivateLink assist for Amazon SageMaker with MLflow
With entry to a variety of generative AI basis fashions (FM) and the flexibility to construct and prepare their very own machine studying (ML) fashions in Amazon SageMaker, customers desire a seamless and safe technique to experiment with and choose the fashions that ship probably the most worth for his or her enterprise. Within the preliminary levels of an ML challenge, knowledge scientists collaborate intently, sharing experimental outcomes to deal with enterprise challenges. Nevertheless, conserving observe of quite a few experiments, their parameters, metrics, and outcomes will be tough, particularly when engaged on complicated initiatives concurrently. MLflow, a well-liked open-source instrument, helps knowledge scientists arrange, observe, and analyze ML and generative AI experiments, making it simpler to breed and evaluate outcomes.
SageMaker is a complete, totally managed ML service designed to supply knowledge scientists and ML engineers with the instruments they should deal with your entire ML workflow. Amazon SageMaker with MLflow is a functionality in SageMaker that permits customers to create, handle, analyze, and evaluate their ML experiments seamlessly. It simplifies the customarily complicated and time-consuming duties concerned in organising and managing an MLflow atmosphere, permitting ML directors to shortly set up safe and scalable MLflow environments on AWS. See Fully managed MLFlow on Amazon SageMaker for extra particulars.
Enhanced safety: AWS VPC and AWS PrivateLink
When working with SageMaker, you’ll be able to resolve the extent of web entry to supply to your customers. For instance, you may give customers entry permission to obtain in style packages and customise the event atmosphere. Nevertheless, this may additionally introduce potential dangers of unauthorized entry to your knowledge. To mitigate these dangers, you’ll be able to additional prohibit which visitors can entry the web by launching your ML atmosphere in an Amazon Virtual Private Cloud (Amazon VPC). With an Amazon VPC, you’ll be able to management the community entry and web connectivity of your SageMaker atmosphere, and even take away direct web entry so as to add one other layer of safety. See Connect to SageMaker through a VPC interface endpoint to grasp the implications of operating SageMaker inside a VPC and the variations when utilizing community isolation.
SageMaker with MLflow now helps AWS PrivateLink, which lets you switch vital knowledge out of your VPC to MLflow Monitoring Servers by way of a VPC endpoint. This functionality enhances the safety of delicate data by ensuring that knowledge despatched to the MLflow Monitoring Servers is transferred inside the AWS community, avoiding publicity to the general public web. This functionality is obtainable in all AWS Areas the place SageMaker is at present accessible, excluding China Areas and GovCloud (US) Areas. To be taught extra, see Connect to an MLflow tracking server through an Interface VPC Endpoint.
On this blogpost, we display a use case to arrange a SageMaker atmosphere in a non-public VPC (with out web entry), whereas utilizing MLflow capabilities to speed up ML experimentation.
Answer overview
Yow will discover the reference code for this pattern in GitHub. The high-level steps are as follows:
- Deploy infrastructure with the AWS Cloud Development Kit (AWS CDK) together with:
- Run ML experimentation with MLflow utilizing the @remote decorator from the open-source SageMaker Python SDK.
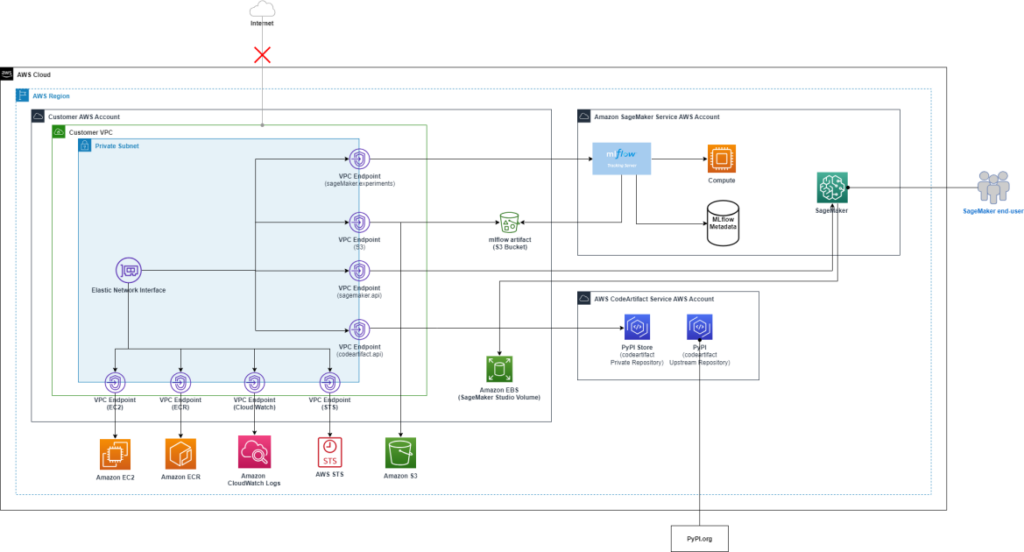
The general answer structure is proven within the following determine.

In your reference, this blog post demonstrates an answer to create a VPC with no web connection utilizing an AWS CloudFormation template.
Stipulations
You want an AWS account with an AWS Identity and Access Management (IAM) role with permissions to handle sources created as a part of the answer. For particulars, see Creating an AWS account.
Deploy infrastructure with AWS CDK
Step one is to create the infrastructure utilizing this CDK stack. You may observe the deployment directions from the README.
Let’s first have a better have a look at the CDK stack itself.
It defines a number of VPC endpoints, together with the MLflow endpoint as proven within the following pattern:
vpc.add_interface_endpoint(
"mlflow-experiments",
service=ec2.InterfaceVpcEndpointAwsService.SAGEMAKER_EXPERIMENTS,
private_dns_enabled=True,
subnets=ec2.SubnetSelection(subnets=subnets),
security_groups=[studio_security_group]
)We additionally attempt to prohibit the SageMaker execution IAM role with the intention to use SageMaker MLflow solely while you’re in the proper VPC.
You may additional prohibit the VPC endpoint for MLflow by attaching a VPC endpoint policy.
Customers exterior the VPC can doubtlessly hook up with Sagemaker MLflow by way of the VPC endpoint to MLflow. You may add restrictions in order that user access to SageMaker MLflow is only allowed from your VPC.
studio_execution_role.attach_inline_policy(
iam.Coverage(self, "mlflow-policy",
statements=[
iam.PolicyStatement(
effect=iam.Effect.ALLOW,
actions=["sagemaker-mlflow:*"],
sources=["*"],
circumstances={"StringEquals": {"aws:SourceVpc": vpc.vpc_id } }
)
]
)
)After profitable deployment, it is best to be capable to see the brand new VPC within the AWS Administration Console for Amazon VPC with out web entry, as proven within the following screenshot.

A CodeArtifact area and a CodeArtifact repository with exterior connection to PyPI must also be created, as proven within the following determine, so that SageMaker can use it to obtain crucial packages with out web entry. You may confirm the creation of the area and the repository by going to the CodeArtifact console. Select “Repositories” beneath “Artifacts” from the navigation pane and you will notice the repository “pip”.

ML experimentation with MLflow
Setup
After the CDK stack creation, a brand new SageMaker area with a person profile must also be created. Launch Amazon SageMaker Studio and create a JupyterLab Space. Within the JupyterLab Area, select an occasion kind of ml.t3.medium, and choose a picture with SageMaker Distribution 2.1.0.
To test that the SageMaker atmosphere has no web connection, open the JupyterLab area and test the web connection by operating the curl command in a terminal.

SageMaker with MLflow now helps MLflow model 2.16.2 to speed up generative AI and ML workflows from experimentation to manufacturing. An MLflow 2.16.2 monitoring server is created together with the CDK stack.
Yow will discover the MLflow monitoring server Amazon Useful resource Title (ARN) both from the CDK output or from the SageMaker Studio UI by clicking “MLFlow” icon, as proven within the following determine. You may click on the “copy” button subsequent to the “mlflow-server” to repeat the MLflow monitoring server ARN.

For instance dataset to coach the mannequin, obtain the reference dataset from the general public UC Irvine ML repository to your native PC, and title it predictive_maintenance_raw_data_header.csv.
Add the reference dataset out of your native PC to your JupyterLab Area as proven within the following determine.

To check your non-public connectivity to the MLflow monitoring server, you’ll be able to obtain the pattern pocket book that has been uploaded robotically through the creation of the stack in a bucket inside your AWS account. Yow will discover the an S3 bucket title within the CDK output, as proven within the following determine.

From the JupyterLab app terminal, run the next command:
aws s3 cp --recursive <YOUR-BUCKET-URI> ./Now you can open the private-mlflow.ipynb pocket book.
Within the first cell, fetch credentials for the CodeArtifact PyPI repository in order that SageMaker can use pip from the non-public AWS CodeArtifact repository. The credentials will expire in 12 hours. Be sure that to go online once more once they expire.
%%bash
AWS_ACCOUNT=$(aws sts get-caller-identity --output textual content --query 'Account')
aws codeartifact login --tool pip --repository pip --domain code-artifact-domain --domain-owner ${AWS_ACCOUNT} --region ${AWS_DEFAULT_REGION}Experimentation
After setup, begin the experimentation. The situation is utilizing the XGBoost algorithm to coach a binary classification mannequin. Each the information processing job and mannequin coaching job use @remote decorator in order that the roles are operating within the SageMaker-associated non-public subnets and safety group out of your non-public VPC.
On this case, the @distant decorator seems up the parameter values from the SageMaker configuration file (config.yaml). These parameters are used for knowledge processing and coaching jobs. We outline the SageMaker-associated non-public subnets and safety group within the configuration file. For the complete checklist of supported configurations for the @distant decorator, see Configuration file in the SageMaker Developer Guide.
Word that we specify in PreExecutionCommands the aws codeartifact login command to level SageMaker to the non-public CodeAritifact repository. That is wanted to guarantee that the dependencies will be put in at runtime. Alternatively, you’ll be able to move a reference to a container in your Amazon ECR by way of ImageUri, which accommodates all put in dependencies.
We specify the safety group and subnets data in VpcConfig.
config_yaml = f"""
SchemaVersion: '1.0'
SageMaker:
PythonSDK:
Modules:
TelemetryOptOut: true
RemoteFunction:
# function arn isn't required if in SageMaker Pocket book occasion or SageMaker Studio
# Uncomment the next line and exchange with the proper execution function if in an area IDE
# RoleArn: <exchange the function arn right here>
# ImageUri: <exchange together with your picture if you wish to keep away from putting in dependencies at run time>
S3RootUri: s3://{bucket_prefix}
InstanceType: ml.m5.xlarge
Dependencies: ./necessities.txt
IncludeLocalWorkDir: true
PreExecutionCommands:
- "aws codeartifact login --tool pip --repository pip --domain code-artifact-domain --domain-owner {account_id} --region {area}"
CustomFileFilter:
IgnoreNamePatterns:
- "knowledge/*"
- "fashions/*"
- "*.ipynb"
- "__pycache__"
VpcConfig:
SecurityGroupIds:
- {security_group_id}
Subnets:
- {private_subnet_id_1}
- {private_subnet_id_2}
"""Right here’s how one can setup an MLflow experiment much like this.
from time import gmtime, strftime
# Mlflow (exchange these values with your individual, if wanted)
project_prefix = project_prefix
tracking_server_arn = mlflow_arn
experiment_name = f"{project_prefix}-sm-private-experiment"
run_name=f"run-{strftime('%d-%H-%M-%S', gmtime())}"Information preprocessing
In the course of the knowledge processing, we use the @distant decorator to hyperlink parameters in config.yaml to your preprocess operate.
Word that MLflow monitoring begins from the mlflow.start_run() API.
The mlflow.autolog() API can robotically log data comparable to metrics, parameters, and artifacts.
You should use log_input() technique to log a dataset to the MLflow artifact retailer.
@distant(keep_alive_period_in_seconds=3600, job_name_prefix=f"{project_prefix}-sm-private-preprocess")
def preprocess(df, df_source: str, experiment_name: str):
mlflow.set_tracking_uri(tracking_server_arn)
mlflow.set_experiment(experiment_name)
with mlflow.start_run(run_name=f"Preprocessing") as run:
mlflow.autolog()
columns = ['Type', 'Air temperature [K]', 'Course of temperature [K]', 'Rotational pace [rpm]', 'Torque [Nm]', 'Device put on [min]', 'Machine failure']
cat_columns = ['Type']
num_columns = ['Air temperature [K]', 'Course of temperature [K]', 'Rotational pace [rpm]', 'Torque [Nm]', 'Device put on [min]']
target_column = 'Machine failure'
df = df[columns]
mlflow.log_input(
mlflow.knowledge.from_pandas(df, df_source, targets=target_column),
context="DataPreprocessing",
)
...
model_file_path="/decide/ml/mannequin/sklearn_model.joblib"
os.makedirs(os.path.dirname(model_file_path), exist_ok=True)
joblib.dump(featurizer_model, model_file_path)
return X_train, y_train, X_val, y_val, X_test, y_test, featurizer_modelRun the preprocessing job, then go to the MLflow UI (proven within the following determine) to see the tracked preprocessing job with the enter dataset.
X_train, y_train, X_val, y_val, X_test, y_test, featurizer_model = preprocess(df=df,
df_source=input_data_path,
experiment_name=experiment_name)You may open an MLflow UI from SageMaker Studio as the next determine. Click on “Experiments” from the navigation pane and choose your experiment.

From the MLflow UI, you’ll be able to see the processing job that simply run.

You may also see safety particulars within the SageMaker Studio console within the corresponding coaching job as proven within the following determine.

Mannequin coaching
Much like the information processing job, you may also use @distant decorator with the coaching job.
Word that the log_metrics() technique sends your outlined metrics to the MLflow monitoring server.
@distant(keep_alive_period_in_seconds=3600, job_name_prefix=f"{project_prefix}-sm-private-train")
def prepare(X_train, y_train, X_val, y_val,
eta=0.1,
max_depth=2,
gamma=0.0,
min_child_weight=1,
verbosity=0,
goal="binary:logistic",
eval_metric="auc",
num_boost_round=5):
mlflow.set_tracking_uri(tracking_server_arn)
mlflow.set_experiment(experiment_name)
with mlflow.start_run(run_name=f"Coaching") as run:
mlflow.autolog()
# Creating DMatrix(es)
dtrain = xgboost.DMatrix(X_train, label=y_train)
dval = xgboost.DMatrix(X_val, label=y_val)
watchlist = [(dtrain, "train"), (dval, "validation")]
print('')
print (f'===Beginning coaching with max_depth {max_depth}===')
param_dist = {
"max_depth": max_depth,
"eta": eta,
"gamma": gamma,
"min_child_weight": min_child_weight,
"verbosity": verbosity,
"goal": goal,
"eval_metric": eval_metric
}
xgb = xgboost.prepare(
params=param_dist,
dtrain=dtrain,
evals=watchlist,
num_boost_round=num_boost_round)
predictions = xgb.predict(dval)
print ("Metrics for validation set")
print('')
print (pd.crosstab(index=y_val, columns=np.spherical(predictions),
rownames=['Actuals'], colnames=['Predictions'], margins=True))
rounded_predict = np.spherical(predictions)
val_accuracy = accuracy_score(y_val, rounded_predict)
val_precision = precision_score(y_val, rounded_predict)
val_recall = recall_score(y_val, rounded_predict)
# Log further metrics, subsequent to the default ones logged robotically
mlflow.log_metric("Accuracy Mannequin A", val_accuracy * 100.0)
mlflow.log_metric("Precision Mannequin A", val_precision)
mlflow.log_metric("Recall Mannequin A", val_recall)
from sklearn.metrics import roc_auc_score
val_auc = roc_auc_score(y_val, predictions)
mlflow.log_metric("Validation AUC A", val_auc)
model_file_path="/decide/ml/mannequin/xgboost_model.bin"
os.makedirs(os.path.dirname(model_file_path), exist_ok=True)
xgb.save_model(model_file_path)
return xgbOutline hyperparameters and run the coaching job.
eta=0.3
max_depth=10
booster = prepare(X_train, y_train, X_val, y_val,
eta=eta,
max_depth=max_depth)Within the MLflow UI you’ll be able to see the monitoring metrics as proven within the determine under. Beneath “Experiments” tab, go to “Coaching” job of your experiment process. It’s beneath “Overview” tab.

You may also view the metrics as graphs. Beneath “Mannequin metrics” tab, you’ll be able to see the mannequin efficiency metrics that configured as a part of the coaching job log.

With MLflow, you’ll be able to log your dataset data alongside different key metrics, comparable to hyperparameters and mannequin analysis. Discover extra particulars within the blogpost LLM experimentation with MLFlow.
Clear up
To scrub up, first delete all areas and functions created inside the SageMaker Studio area. Then destroy the infrastructure created by operating the next code.
cdk destroyConclusion
SageMaker with MLflow permits ML practitioners to create, handle, analyze, and evaluate ML experiments on AWS. To reinforce safety, SageMaker with MLflow now helps AWS PrivateLink. All MLflow Monitoring Server variations together with 2.16.2 combine seamlessly with this characteristic, enabling safe communication between your ML environments and AWS providers with out exposing knowledge to the general public web.
For an additional layer of safety, you’ll be able to arrange SageMaker Studio inside your non-public VPC with out Web entry and execute your ML experiments on this atmosphere.
SageMaker with MLflow now helps MLflow 2.16.2. Establishing a contemporary set up offers the perfect expertise and full compatibility with the most recent options.
Concerning the Authors
 Xiaoyu Xing is a Options Architect at AWS. She is pushed by a profound ardour for Synthetic Intelligence (AI) and Machine Studying (ML). She strives to bridge the hole between these cutting-edge applied sciences and a broader viewers, empowering people from numerous backgrounds to be taught and leverage AI and ML with ease. She helps clients to undertake AI and ML options on AWS in a safe and accountable means.
Xiaoyu Xing is a Options Architect at AWS. She is pushed by a profound ardour for Synthetic Intelligence (AI) and Machine Studying (ML). She strives to bridge the hole between these cutting-edge applied sciences and a broader viewers, empowering people from numerous backgrounds to be taught and leverage AI and ML with ease. She helps clients to undertake AI and ML options on AWS in a safe and accountable means.
 Paolo Di Francesco is a Senior Options Architect at Amazon Net Companies (AWS). He holds a PhD in Telecommunications Engineering and has expertise in software program engineering. He’s keen about machine studying and is at present specializing in utilizing his expertise to assist clients attain their objectives on AWS, specifically in discussions round MLOps. Outdoors of labor, he enjoys enjoying soccer and studying.
Paolo Di Francesco is a Senior Options Architect at Amazon Net Companies (AWS). He holds a PhD in Telecommunications Engineering and has expertise in software program engineering. He’s keen about machine studying and is at present specializing in utilizing his expertise to assist clients attain their objectives on AWS, specifically in discussions round MLOps. Outdoors of labor, he enjoys enjoying soccer and studying.
 Tomer Shenhar is a Product Supervisor at AWS. He focuses on accountable AI, pushed by a ardour to develop ethically sound and clear AI options.
Tomer Shenhar is a Product Supervisor at AWS. He focuses on accountable AI, pushed by a ardour to develop ethically sound and clear AI options.





