Utilizing LLMs to fortify cyber defenses: Sophos’s perception on methods for utilizing LLMs with Amazon Bedrock and Amazon SageMaker

This publish is co-written with Adarsh Kyadige and Salma Taoufiq from Sophos.
As a pacesetter in cutting-edge cybersecurity, Sophos is devoted to safeguarding over 500,000 organizations and hundreds of thousands of consumers throughout greater than 150 international locations. By harnessing the facility of risk intelligence, machine studying (ML), and synthetic intelligence (AI), Sophos delivers a complete vary of superior services. These options are designed to guard and defend customers, networks, and endpoints in opposition to a big selection of cyber threats together with phishing, ransomware, and malware. The Sophos Artificial Intelligence (AI) group (SophosAI) oversees the event and upkeep of Sophos’s main ML safety know-how.
Giant language fashions (LLMs) have demonstrated spectacular capabilities in pure language understanding and era throughout numerous domains as showcased in quite a few leaderboards (e.g., HELM, Hugging Face Open LLM leaderboard) that consider them on a myriad of generic duties. Nonetheless, their effectiveness in specialised fields like cybersecurity depends closely on domain-specific information. On this context, fine-tuning emerges as a vital method to adapt these general-purpose fashions to the intricacies of cybersecurity. For instance, we may use Instruction fine-tuning to extend the mannequin efficiency on an incident classification or summarization. Nonetheless, earlier than fine-tuning, it’s essential to find out an out-of-the-box mannequin’s potential by testing its talents on a set of duties primarily based on the area. We’ve outlined three specialised duties which are coated later within the weblog. These similar duties can be used to measure the good points in efficiency obtained by means of fine-tuning, Retrieval-Augmented Generation (RAG), or information distillation.
On this publish, SophosAI shares insights in utilizing and evaluating an out-of-the-box LLM for the enhancement of a safety operations middle’s (SOC) productiveness utilizing Amazon Bedrock and Amazon SageMaker. We use Anthropic’s Claude 3 Sonnet on Amazon Bedrock for instance the use circumstances.
Amazon Bedrock is a totally managed service that gives a selection of high-performing basis fashions (FMs) from main AI firms like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon by means of a single API, together with a broad set of capabilities it’s essential construct generative AI purposes with safety, privateness, and accountable AI.
Duties
We’ll showcase three instance duties to delve into utilizing LLMs within the context of an SOC. An SOC is an organizational unit answerable for monitoring, detecting, analyzing, and responding to cybersecurity threats and incidents. It employs a mix of know-how, processes, and expert personnel to take care of the confidentiality, integrity, and availability of knowledge methods and information. SOC analysts repeatedly monitor safety occasions, examine potential threats, and take acceptable motion to mitigate dangers. Identified challenges confronted by SOCs are the excessive quantity of alerts generated by detection instruments and the next alert fatigue amongst analysts. These challenges are sometimes coupled with staffing shortages. To handle these challenges and improve operational effectivity and scalability, many SOCs are more and more turning to automation applied sciences to streamline repetitive duties, prioritize alerts, and speed up incident response. Contemplating the character of duties analysts have to carry out, LLMs are good instruments to reinforce the extent of automation in SOCs and empower safety groups.
For this work, we concentrate on three important SOC use circumstances the place LLMs have the potential of enormously aiding analysts, specifically:
- SQL Question era from pure language to simplify information extraction
- Incident severity prediction to prioritize which incidents analysts ought to concentrate on
- Incident summarization primarily based on its constituent alert information to extend analyst productiveness
Primarily based on the token consumption of those duties, significantly the summarization element, we’d like a mannequin with a context window of at the least 4000 tokens. Whereas the duties have been examined in English, Anthropic’s Claude 3 Sonnet mannequin can carry out in different languages. Nonetheless, we advocate evaluating the efficiency in your particular language of curiosity.
Let’s dive into the main points of every job.
Process 1: Question era from pure language
This job’s goal is to evaluate a mannequin’s capability to translate pure language questions into SQL queries, utilizing contextual information of the underlying information schema. This ability simplifies the information extraction course of, permitting safety analysts to conduct investigations extra effectively with out requiring deep technical information. We used prompt engineering guidelines to tailor our prompts to generate higher responses from the LLM.
A 3-shot prompting technique is used for this job. Given a database schema, the mannequin is supplied with three examples pairing a natural-language query with its corresponding SQL question. Following these examples, the mannequin is then prompted to generate the SQL question for a query of curiosity.
The immediate beneath is a three-shot immediate instance for question era from pure language. Empirically, now we have obtained higher outcomes with few-shot prompting versus one-shot (the place the mannequin is supplied with just one instance query and corresponding question earlier than the precise query of curiosity) or zero-shot (the place the mannequin is instantly prompted to generate a desired question with none examples).
To guage a mannequin’s efficiency on this job, we depend on a proprietary information set of about 100 goal queries primarily based on a check database schema. To find out the accuracy of the queries generated by the mannequin, a multi-step analysis is adopted. First, we confirm whether or not the mannequin’s output is an actual match to the anticipated SQL assertion. Precise matches are then recorded as profitable outcomes. If there’s a mismatch, we then run each the mannequin’s question and the anticipated question in opposition to our mock database to check their outcomes. Nonetheless, this technique will be vulnerable to false positives and false negatives. To mitigate this, we additional carry out a question equivalence evaluation utilizing a unique stronger LLM on this job. This technique is called LLM-as-a-judge.
Anthropic’s Claude 3 Sonnet mannequin achieved a superb accuracy charge of 88 p.c on the chosen dataset, suggesting that this natural-language-to-SQL job is sort of easy for LLMs. With primary few-shot prompting, an LLM can due to this fact be used out-of-the-box with out fine-tuning by safety analysts to help them in retrieving key info whereas investigating threats. The above mannequin efficiency relies on our dataset and our experiment. This implies you could carry out your individual check utilizing the technique defined above.
Process 2: Incident severity prediction
For the second job, we assess a mannequin’s potential to acknowledge the severity of noticed occasions as indicators of an incident. Particularly, we attempt to decide whether or not an LLM can evaluate a safety incident and precisely gauge its significance. Armed with such a functionality, a mannequin can help analysts in figuring out which incidents are most urgent, to allow them to work extra effectively by organizing their work queue primarily based on severity ranges, reduce by means of the noise, and save time and power.
The enter information on this use case is semi-structured alert information, typical of what’s produced by numerous detection methods throughout an incident. We clearly outline severity classes—essential, excessive, medium, low, and informational—throughout which the mannequin is to categorise the severity of the incident. That is due to this fact a classification drawback that exams an LLM’s intrinsic cybersecurity information.
Every safety incident throughout the Sophos Managed Detection and Response (MDR) platform is made up of a number of detections that spotlight suspicious actions occurring in a person’s atmosphere. A detection would possibly contain figuring out probably dangerous patterns, reminiscent of uncommon command executions, irregular file entry, anomalous community site visitors, or suspicious script use. We’ve hooked up beneath an instance enter information.
The “detection” part gives detailed details about every particular suspicious exercise that was recognized. It contains the kind of safety incident, reminiscent of “Execution,” together with an outline that explains the character of the risk, like using suspicious PowerShell instructions. The detection is tied to a singular identifier for monitoring and reference functions. Moreover, it incorporates particulars from the MITRE ATT&CK framework which categorizes the techniques and methods concerned within the risk. This part may also reference associated Sigma guidelines, that are community-driven signatures for detecting threats throughout totally different methods. By together with these components, the detection part serves as a complete define of the potential risk, serving to analysts perceive not simply what was detected but additionally why it issues.
The “machine_data” part holds essential details about the machine on which the detection occurred. It may well present additional metadata on the machine, serving to to pinpoint the place precisely within the atmosphere the suspicious exercise was noticed.
To facilitate analysis, the immediate used for this job requires that the mannequin communicates its severity assessments in a uniform manner, offering the response in a standardized format, for instance, as a dictionary with severity_pred as the important thing and their chosen severity degree as the worth. The immediate beneath is an instance for incident severity classification. Mannequin efficiency is then evaluated in opposition to a check set of over 3,800 safety incidents with goal severity ranges.
Numerous experimental setups are used for this job, together with zero-shot prompting, three-shot prompting utilizing random or nearest-neighbor incidents examples, and easy classifiers.
This job turned out to be fairly difficult, due to the noise within the goal labels and the inherent problem of assessing the criticality of an incident with out additional investigation by fashions that weren’t skilled particularly for this use case.
Even beneath numerous setups, reminiscent of few-shot prompting with nearest neighbor incidents, the mannequin’s efficiency couldn’t reliably outperform random probability. For reference, the baseline accuracy on the check set is roughly 71 p.c and the baseline balanced accuracy is 20 p.c.
Determine 1 presents the confusion matrix of the mannequin’s responses. The confusion matrix permits to see in a single graph the efficiency of the mannequin’s classification. We will see that solely 12% (0.12) of the Precise essential incidents have been appropriately predicted/categorised. Then 50% of the Essential incidents have been predicted as Excessive incidents, 25% as Medium incidents and 12% as Informational incidents. We will equally see low accuracy on the remainder of the labels and the bottom being bee the Low incidents label with solely 2% of the incidents appropriately predicted. There’s additionally a notable tendency to overpredict Excessive and Medium classes throughout the board.
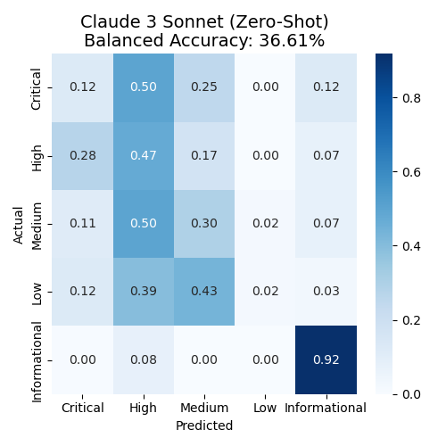
Determine 1: Confusion matrix for the five-severity-level classification utilizing Anthropic Claude 3 Sonnet
The efficiency noticed on this benchmark job signifies it is a significantly onerous drawback for an unmodified, all-purpose LLM, and the issue requires a extra specialised mannequin, particularly skilled or fine-tuned on cybersecurity information.
Process 3: Incident summarization
The third job is worried with the summarization of incoming incidents. It evaluates the potential of a mannequin to help risk analysts within the triage and investigation of safety incidents as they arrive in by offering a succinct and concise abstract of the exercise that triggered the incident.
Safety incidents usually include a collection of occasions occurring on a person endpoint or community, related to detected suspicious exercise. The analysts investigating the incident are introduced with a collection of occasions that occurred on the endpoint on the time the suspicious exercise was detected. Nonetheless, analyzing this occasion sequence will be difficult and time-consuming, leading to problem in figuring out noteworthy occasions. That is the place LLMs will be helpful by serving to manage and categorize occasion information following a particular template, thereby aiding comprehension, and serving to analysts shortly decide the suitable subsequent actions.
We use actual incident information from Sophos’s MDR for incident summarization. The enter for this job encompasses a set of JSON occasions, every having distinct schemas and attributes primarily based on the capturing sensor. Together with directions and a predefined template, this information is offered to the mannequin to generate a abstract. The immediate beneath is an instance template immediate for producing incident summaries from SOC information.
Evaluating these generated incident summaries is hard as a result of a number of components have to be thought of. For instance, it’s essential that the extracted info isn’t solely right, but additionally related. To achieve a basic understanding of the standard of a mannequin’s incident summarization, we use a set of 5 distinct metrics and depend on a dataset comprising of N incidents. We examine the generated descriptions with corresponding gold-standard descriptions crafted primarily based on Sophos analysts’ suggestions.
We compute two lessons of metrics. The primary class of metrics assesses factual accuracy; they’re used to guage what number of artifacts reminiscent of command strains, file paths, usernames, and so forth had been appropriately recognized and summarized by the mannequin. The computation right here is simple; we compute the typical distance throughout extracted artifacts between the generated description and the goal. We use two distance metrics, Levenshtein distance and longest frequent subsequence (LCS).
The second class of metrics is used to supply a extra semantic analysis of the generated description, utilizing three totally different metrics:
- BERTScore metric: This metric is used to guage the generated summaries utilizing a pre-trained BERT mannequin’s contextual embeddings. It determines the similarity between the generated abstract and the reference abstract utilizing cosine similarity.
- ADA2 embeddings cosine similarity: This metric assesses the cosine similarity of ADA2 embeddings of tokens within the generated abstract with these of the reference abstract.
- METEOR rating: METEOR is an analysis metric primarily based on the harmonic imply of unigram precision and recall.
Extra superior analysis strategies can be utilized reminiscent of coaching a reward mannequin on human preferences and utilizing it as an evaluator, however for the sake of simplicity and cost-effectiveness, we restricted the scope to those metrics.
Beneath is a abstract of our outcomes on this job:
| Mannequin | Levenshtein-based factual accuracy | LCS-based factual accuracy | BERTScore | Cosine similarity of ADA2 embeddings | METEOR rating |
| Anthropic’s Claude 3 Sonnet | 0.810 | 0.721 | 0.886 | 0.951 | 0.4165 |
Primarily based on these findings, we acquire a broad understanding of the efficiency of the mannequin in relation to producing incident summaries, focusing particularly on factual accuracy and retrieval charge. Anthropic’s Claude 3 Sonnet mannequin can seize the exercise that’s occurring within the incident and summarize it nicely. Nonetheless, it ignores sure directions reminiscent of defanging all IPs and URLs. The returned studies are additionally not absolutely aligned with the goal responses on a token degree as signaled by the METEOR rating. Anthropic’s Claude 3 Sonnet mannequin skims over some particulars and explanations within the studies.
Experimental setup utilizing Amazon Bedrock and Amazon SageMaker
This part outlines the experimental setup for evaluating numerous giant language fashions (LLMs) utilizing Amazon Bedrock and Amazon SageMaker. These companies allowed us to effectively work together with and deploy a number of LLMs for fast and cost-effective experimentation.
Amazon Bedrock
Amazon Bedrock is a managed service that permits experimenting with numerous LLMs shortly in an on-demand method. This brings the benefit of with the ability to work together and experiment with LLMs with out having to self-host them and solely pay by tokens consumed. We used the InvokeModel API to work together with the mannequin with minimal latency. We wrote the next operate that allow us name totally different fashions by passing the required inference parameters to the API. For extra particulars on what the inference parameters are per supplier, we advocate you learn the Inference request parameters and response fields for foundation models part within the Amazon Bedrock documentation. The instance beneath makes use of the operate primarily based on Anthropic’s Claude 3 Sonnet mannequin. Discover that we gave the mannequin a task by way of the system prompt and that we prefilled its response.
The above instance relies on our use case. The model_id parameter specifies the identifier of the particular mannequin you want to invoke utilizing the Bedrock runtime. We used the mannequin id anthropic.claude-3-sonnet-20240229-v1:0. For different mannequin ids, please discuss with the bedrock documentation. For additional particulars about this API, we advocate you learn the API documentation. We advise you to adapt it to your use case primarily based in your necessities.
Our evaluation on this weblog publish has targeted on Anthropic’s Claude 3 Sonnet mannequin and three particular use circumstances. These insights will be tailored to different SOCs’ particular necessities and desired fashions. For instance, it’s doable to entry different fashions reminiscent of Meta’s Llama fashions, Mistral fashions, Amazon Titan fashions and others. For added fashions, we used Amazon SageMaker Jumpstart.
Amazon SageMaker
Amazon SageMaker is a totally managed machine studying (ML) service. With SageMaker, information scientists and builders can shortly and confidently construct, prepare, and deploy ML fashions right into a production-ready hosted atmosphere. Amazon SageMaker JumpStart is a sturdy characteristic throughout the SageMaker machine studying (ML) atmosphere, providing practitioners a complete hub of publicly obtainable and proprietary basis fashions (FMs). It presents a variety of publicly obtainable and proprietary LLMs you could, in a low-code method, shortly tune and deploy. To shortly deploy and experiment with the out of the field fashions in SageMaker in a cheap method, we deployed the LLMs from SageMaker JumpStart utilizing asynchronous inference endpoints.
Inference endpoints had been a simple manner for us to instantly obtain these fashions from the respective Hugging Face repositories and deploy them utilizing just a few strains of code and pre-made Text Generation Inference (TGI) containers (see the example notebook on GitHub). As well as, we used asynchronous inference endpoints with autoscaling, which helped us to handle prices by robotically scaling the inference endpoints right down to zero after they weren’t getting used. Contemplating the variety of endpoints we had been creating, asynchronous inference made it easy for us to handle endpoints by having the endpoint prepared to make use of every time they had been wanted and scaling them down after they weren’t getting used, with out further administration on our finish after the scaling coverage was outlined.
Subsequent steps
On this weblog publish we utilized the duties on a single mannequin to indicate case it for instance; in actuality, you would choose a few LLMs that you’d put by means of the experiments on this publish primarily based in your necessities. From there, if the out-of-the-box fashions aren’t enough for the duty, you would choose the most effective suited LLM after which fine-tune it on the particular job.
For instance, primarily based on the outcomes of our three experimental duties, we discovered that the outcomes of the incident info summarization job didn’t meet our expectations. Subsequently, we are going to fine-tune the out-of-the-box mannequin that most accurately fits our wants. This fine-tuning course of will be completed utilizing Amazon Bedrock Custom Models or SageMaker fine tuning, and the fine-tuned mannequin may then be deployed using the customized model by importing it into Amazon Bedrock or by deploying the mannequin to a SageMaker endpoint.
On this weblog we coated the experimentation part. When you establish an LLM that meets your efficiency necessities, it’s essential to start out contemplating productionize it. When productionizing an LLM, you will need to think about issues like guardrails and scalability of the LLM. Implementing guardrails lets you reduce the chance of the mannequin being misused or safety breaches. Amazon Bedrock Guardrails lets you implement safeguards in your generative AI purposes primarily based in your use circumstances and accountable AI insurance policies. This blog covers construct guardrails in your generative AI purposes. When transferring an LLM into ] manufacturing, you additionally need to validate the scalability of the LLM primarily based on request site visitors. In Amazon Bedrock, think about increasing the quotas of your mannequin, batch inference, queuing the requests, and even distributing the requests between totally different Areas which have the identical mannequin. Choose the method that fits you primarily based in your use case and site visitors.
Conclusion
On this publish, SophosAI shared insights on use and consider out-of-the-box LLMs following a set of specialised duties for the enhancement of a safety operations middle’s (SOC) productiveness by utilizing Amazon Bedrock and Amazon SageMaker. We used Anthropic’s Claude 3 Sonnet mannequin on Amazon Bedrock for instance three use circumstances.
Amazon Bedrock and SageMaker have been key to enabling us to run these experiments. With the handy entry to high-performing basis fashions (FMs) from main AI firms offered by Amazon Bedrock by means of a single API name, we had been capable of check numerous LLMs without having to deploy them ourselves. Moreover, the on-demand pricing mannequin allowed us to solely pay for what we used primarily based on token consumption.
To entry further fashions with versatile management, SageMaker is a superb various that gives a variety of LLMs prepared for deployment. Whilst you would deploy these fashions your self, you possibly can nonetheless obtain nice price optimization by utilizing asynchronous endpoints with a scaling coverage that scales the occasion right down to zero when not in use.
Basic takeaways as to the applicability of an LLM reminiscent of Anthropic’s Claude 3 Sonnet mannequin in cybersecurity will be summarized as follows:
- An out-of-the-box LLM will be an efficient assistant in risk looking and incident investigation. Nonetheless, it nonetheless requires some guardrails and steerage. We consider that this potential software will be carried out utilizing an current highly effective mannequin, reminiscent of Anthropic’s Claude 3 Sonnet mannequin, with cautious immediate engineering.
- In the case of summarizing incident info from uncooked information, Anthropic’s Claude 3 Sonnet mannequin performs adequately, however there’s room for enchancment by means of fine-tuning.
- Evaluating particular person artifacts or teams of artifacts stays a difficult job for a pre-trained LLM. To sort out this drawback, a specialised LLM skilled particularly on cybersecurity information is perhaps required.
It’s also price noticing that whereas we used the InvokeModel API from Amazon Bedrock, one other easier option to entry Amazon Bedrock fashions is by utilizing the Converse API. The Converse API gives constant API calls that work with Amazon Bedrock fashions that help messages. This implies you possibly can write code as soon as and use it with totally different fashions. Ought to a mannequin have distinctive inference parameters, the Converse API additionally lets you go these distinctive parameters in a mannequin particular construction.
In regards to the Authors
 Benoit de Patoul is a GenAI/AI/ML Specialist Options Architect at AWS. He helps clients by offering steerage and technical help to construct options associated to GenAI/AI/ML utilizing Amazon Net Providers. In his free time, he likes to play piano and spend time with mates.
Benoit de Patoul is a GenAI/AI/ML Specialist Options Architect at AWS. He helps clients by offering steerage and technical help to construct options associated to GenAI/AI/ML utilizing Amazon Net Providers. In his free time, he likes to play piano and spend time with mates.
 Naresh Nagpal is a Options Architect at AWS with in depth expertise in software improvement, integration, and know-how structure. At AWS, he works with ISV clients within the UK to assist them construct and modernize their SaaS purposes on AWS. He’s additionally serving to clients to combine GenAI capabilities of their SaaS purposes.
Naresh Nagpal is a Options Architect at AWS with in depth expertise in software improvement, integration, and know-how structure. At AWS, he works with ISV clients within the UK to assist them construct and modernize their SaaS purposes on AWS. He’s additionally serving to clients to combine GenAI capabilities of their SaaS purposes.
 Adarsh Kyadige oversees the Analysis wing of the Sophos AI group, the place he has been working since 2018 on the intersection of Machine Studying and Safety. He earned a Masters diploma in Laptop Science, with a specialization in Synthetic Intelligence and Machine Studying, from UC San Diego. His pursuits and tasks contain making use of Deep Studying to Cybersecurity, in addition to orchestrating pipelines for big scale information processing. In his leisure time, Adarsh will be discovered on the archery vary, tennis courts, or in nature. His newest analysis will be discovered on Google Scholar.
Adarsh Kyadige oversees the Analysis wing of the Sophos AI group, the place he has been working since 2018 on the intersection of Machine Studying and Safety. He earned a Masters diploma in Laptop Science, with a specialization in Synthetic Intelligence and Machine Studying, from UC San Diego. His pursuits and tasks contain making use of Deep Studying to Cybersecurity, in addition to orchestrating pipelines for big scale information processing. In his leisure time, Adarsh will be discovered on the archery vary, tennis courts, or in nature. His newest analysis will be discovered on Google Scholar.
 Salma Taoufiq was a Senior Knowledge Scientist at Sophos focusing on the intersection of machine studying and cybersecurity. With an undergraduate background in laptop science, she graduated from the Central European College with a MSc. in Arithmetic and Its Purposes. When not growing a malware detector, Salma is an avid hiker, traveler, and shopper of thrillers.
Salma Taoufiq was a Senior Knowledge Scientist at Sophos focusing on the intersection of machine studying and cybersecurity. With an undergraduate background in laptop science, she graduated from the Central European College with a MSc. in Arithmetic and Its Purposes. When not growing a malware detector, Salma is an avid hiker, traveler, and shopper of thrillers.





