Accelerating Mixtral MoE fine-tuning on Amazon SageMaker with QLoRA

Firms throughout varied scales and industries are utilizing giant language fashions (LLMs) to develop generative AI purposes that present progressive experiences for patrons and workers. Nevertheless, constructing or fine-tuning these pre-trained LLMs on intensive datasets calls for substantial computational sources and engineering effort. With the rise in sizes of those pre-trained LLMs, the mannequin customization course of turns into complicated, time-consuming, and infrequently prohibitively costly for many organizations that lack the mandatory infrastructure and expert expertise.
On this put up, we exhibit how one can handle these challenges by utilizing totally managed setting with Amazon SageMaker Training jobs to fine-tune the Mixtral 8x7B mannequin utilizing PyTorch Fully Sharded Data Parallel (FSDP) and Quantized Low Rank Adaptation (QLoRA).
We information you thru a step-by-step implementation of mannequin fine-tuning on a GEM/viggo dataset, using the QLoRA fine-tuning technique on a single p4d.24xlarge employee node (offering 8 Nvidia A100 40GB GPUs).
Enterprise problem
Right this moment’s companies want to undertake quite a lot of LLMs to boost enterprise purposes. Primarily, they’re searching for basis fashions (FMs) which might be open supply (that’s, mannequin weights that work with out modification from the beginning) and may supply computational effectivity and flexibility. Mistral’s Mixtral 8x7B mannequin, launched with open weights beneath the Apache 2.0 license, is without doubt one of the fashions that has gained recognition with giant enterprises because of the excessive efficiency that it gives throughout varied duties. Mixtral employs a sparse mixture of experts (SMoE) structure, selectively activating solely a subset of its parameters for every enter throughout mannequin coaching. This structure permits these fashions to make use of solely 13B (about 18.5%) of its 46.7B complete parameters throughout inference, making it excessive performing and environment friendly.
These FMs work nicely for a lot of use circumstances however lack domain-specific data that limits their efficiency at sure duties. This requires companies to make use of fine-tuning methods to adapt these giant FMs to particular domains, thus bettering efficiency on focused purposes. As a result of rising variety of mannequin parameters and the growing context lengths of those trendy LLMs, this course of is reminiscence intensive and requires superior AI experience to align and optimize them successfully. The price of provisioning and managing the infrastructure will increase the general price of possession of the end-to-end answer.
Within the upcoming part, we talk about how one can cost-effectively construct such an answer with superior reminiscence optimization strategies utilizing Amazon SageMaker.
Resolution overview
To handle the reminiscence challenges of fine-tuning LLMs corresponding to Mixtral, we’ll undertake the QLoRA technique. As proven within the following diagram, QLoRA freezes the unique mannequin’s weights and provides low-rank trainable parameters to the transformer layers. QLoRA additional makes use of quantization to characterize the precise mannequin’s weights in a compact, optimized format corresponding to 4-bit NormalFloat (NF4), successfully compressing the mannequin and lowering its reminiscence footprint. This permits coaching and fine-tuning these LLMs even on methods with restricted reminiscence whereas sustaining efficiency corresponding to half-precision fine-tuning. QLoRA’s assist for double quantization and paged optimizers reduces the reminiscence footprint additional by quantizing the quantization constants and successfully dealing with any sudden reminiscence calls for.
Throughout the ahead cross computation of this structure, the 4-bit weights get dequantized to bfloat16 (BF16) precision. Then again, the LoRA adapters proceed to function on BF16 precision knowledge. Each (unique weights and adapter output vectors) are then added collectively element-wise to provide the ultimate outcome, denoted as h.
Throughout the backward cross of the mannequin, the gradients are computed with respect to solely the LoRA parameters, not the unique base mannequin weights. Though the dequantized unique weights are utilized in calculations, the unique 4-bit quantized weights of the bottom mannequin stay unchanged.
To undertake the next structure, we’ll use the Hugging Face Parameter-Efficent Fine-tuning (PEFT) library, which integrates immediately with bitsandbytes. This fashion, the QLoRA approach to fine-tune will be adopted with only a few traces of code.
QLoRA operates on a big FM. Within the determine beneath, X denotes the enter tokens of the coaching knowledge, W is the present mannequin weights (quantized), and Wa, Wb are the segments of the adapters added by QLoRA. The unique mannequin’s weights (W) are frozen, and QLoRA provides adapters (Wa, Wb), that are low-rank trainable parameters, onto the present transformer layer.
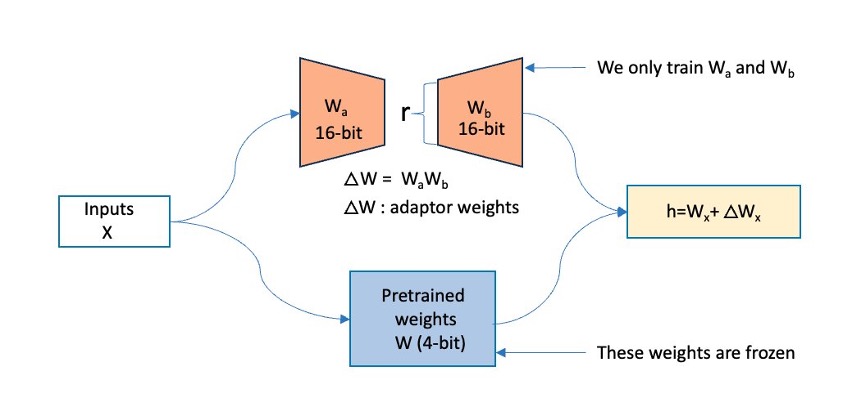
Determine 1: This determine reveals how QLoRA operates. The unique mannequin’s weights (W) are frozen, and QLoRA provides in adapters (Wa, Wb) onto the present transformer layer.
Though QLoRA helps optimize reminiscence throughout fine-tuning, we’ll use Amazon SageMaker Coaching to spin up a resilient coaching cluster, handle orchestration, and monitor the cluster for failures. By offloading the administration and upkeep of the coaching cluster to SageMaker, we scale back each coaching time and our complete price of possession (TCO). Utilizing this method, you possibly can concentrate on creating and refining the mannequin whereas utilizing the totally managed coaching infrastructure offered by SageMaker Coaching.
Implementation particulars
We spin up the cluster by calling the SageMaker management aircraft by way of APIs or the AWS Command Line Interface (AWS CLI) or utilizing the SageMaker AWS SDK. In response, SageMaker spins up coaching jobs with the requested quantity and sort of compute situations. In our instance, we use one ml.p4d.24xlarge compute occasion.
To take full benefit of this multi-GPU cluster, we use the current assist of QLoRA and PyTorch FSDP. Though QLoRA reduces computational necessities and reminiscence footprint, FSDP, an information/mannequin parallelism approach, will assist shard the mannequin throughout all eight GPUs (one ml.p4d.24xlarge), enabling coaching the mannequin much more effectively. Hugging Face PEFT is the place the combination occurs, and you’ll learn extra about it within the PEFT documentation.
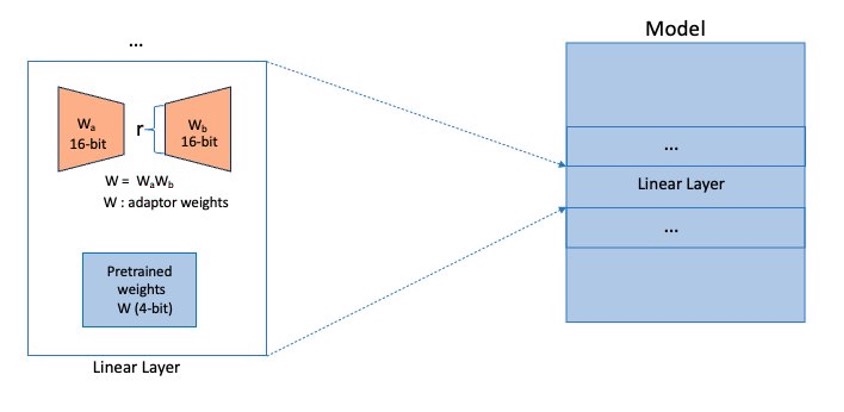
QLoRA adapters are added to the linear layers within the mannequin. The layers (for instance, transformer layers, gate networks, and feed-forward networks) put collectively will type your complete mannequin, as proven within the following diagram, which shall be thought of to be sharded by FSDP throughout our cluster (proven as small shards in blue).
The next structure diagram reveals how you should use SageMaker Coaching to have the SageMaker Management Aircraft spin up a resilient coaching job cluster. SageMaker downloads the coaching picture from Amazon Elastic Container Registry (Amazon ECR) and can use Amazon Simple Storage Service (Amazon S3) as an enter coaching knowledge supply and to retailer coaching artifacts.
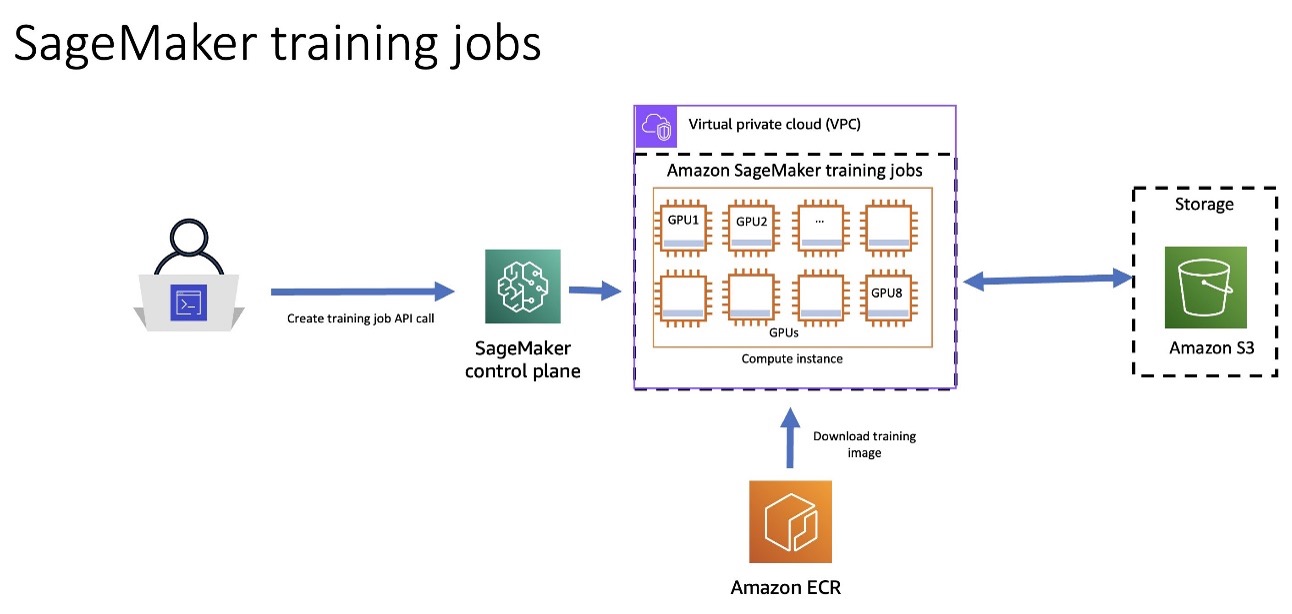
Determine 3: Structure Diagram displaying how one can make the most of SageMaker Coaching Jobs to spin up a resilient coaching cluster. Amazon ECR incorporates the coaching picture, and Amazon S3 incorporates the coaching artifacts.
To place this answer into follow, execute the next use case.
Conditions
To carry out the answer, you have to have the next stipulations in place:
- Create a Hugging Face User Access Token and get entry to the gated repo mistralai/Mixtral-8x7B-v0.1 on Hugging Face.
- (Non-compulsory) Create a Weights & Biases API key to entry the Weights & Biases dashboard for logging and monitoring. That is really helpful if you happen to’d like to visualise mannequin coaching particular metrics.
- Request a service quota at Service Quotas for 1x
ml.p4d.24xlargeon Amazon SageMaker. To request a service quota enhance, on the AWS Service Quotas console, navigate to AWS companies, Amazon SageMaker, and selectml.p4d.24xlargefor coaching job utilization. - Create an AWS Identity and Access Management (IAM) role with managed insurance policies
AmazonSageMakerFullAccessandAmazonEC2FullAccessto offer required entry to SageMaker to run the examples.
This position is for demonstration functions solely. You should modify it to your particular safety necessities for manufacturing. Adhere to the principle of least privilege whereas defining IAM insurance policies in manufacturing.
- (Non-compulsory) Create an Amazon SageMaker Studio area (see Quick setup to Amazon SageMaker) to entry Jupyter notebooks with the previous position. (You should use JupyterLab in your native setup too)
- Clone the GitHub repository with the property for this deployment. This repository consists of a pocket book that references coaching property.
The 15_mixtral_finetune_qlora listing incorporates the coaching scripts that you simply may have to deploy this pattern.
Subsequent, we’ll run the finetune-mixtral.ipynb pocket book to fine-tune the Mixtral 8x7B mannequin utilizing QLoRA on SageMaker. Take a look at the pocket book for extra particulars on every step. Within the subsequent part, we stroll by way of the important thing elements of the fine-tuning execution.
Resolution walkthrough
To carry out the answer, observe the steps within the subsequent sections.
Step 1: Arrange required libraries
Set up the related HuggingFace and SageMaker libraries:
Step 2: Load dataset
On this instance, we use the GEM/viggo dataset from Hugging Face. It is a data-to-text technology dataset within the online game area. The dataset is clear and arranged with about 5,000 knowledge factors, and the responses are extra conversational than data searching for. One of these dataset is right for extracting significant data from buyer critiques. For instance, an ecommerce software corresponding to Amazon.com might use a equally formatted dataset for fine-tuning a mannequin for pure language processing (NLP) evaluation to gauge curiosity in merchandise bought. The outcomes can be utilized for advice engines. Thus, this dataset is an efficient candidate for fine-tuning LLMs. To be taught extra in regards to the viggo dataset, take a look at this research paper.
Load the dataset and convert it to the required immediate construction. The immediate is constructed with the next components:
- Goal sentence – Consider this as the ultimate evaluation. Within the dataset, that is
goal. - Which means illustration – Consider this as a deconstructed evaluation, damaged down by attributes corresponding to
inform,request, orgive_opinion. Within the dataset, that ismeaning_representation.
Operating the next cell provides us the train_set and test_set (coaching break up and testing break up, respectively) with structured prompts. We use the Python map operate to construction the dataset splits in keeping with our immediate.
Add the dataset to Amazon S3. This step is essential as a result of the dataset saved in Amazon S3 will function the enter knowledge channel for the SageMaker coaching cluster. SageMaker will effectively handle the method of distributing this knowledge throughout the coaching cluster, permitting every node to entry the mandatory data for mannequin coaching.
We analyze the distribution of immediate tokens to find out the utmost sequence size required for coaching our mannequin within the upcoming steps.
The next graph reveals the immediate tokens plotted. The x-axis is the size of the prompts, and the y-axis is the variety of occasions that size happens within the coaching dataset (frequency). We use this to find out the utmost sequence size and pad the remainder of the information factors accordingly. The utmost variety of phrases in our instance is 173.
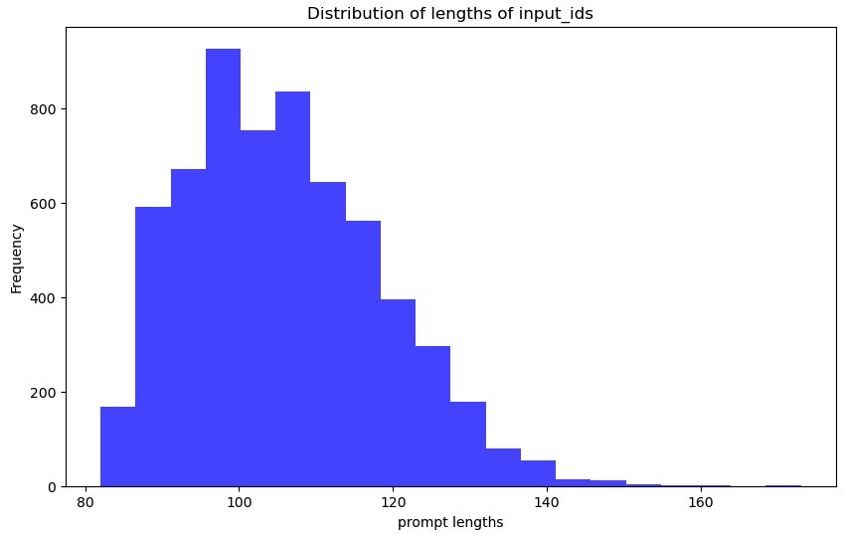
Determine 4: Graph displaying the distribution of enter token lengths prompted. The x-axis reveals the lengths and the y-axis reveals the frequency with which these enter token lengths happen within the prepare and check dataset splits.
Step 3: Configure the parameters for SFTTrainer for the fine-tuning process
We use TrlParser to parse hyperparameters in a YAML file that’s required to configure SFTTrainer API for fine-tuning the mannequin. This method gives flexibility as a result of we are able to additionally overwrite the arguments specified within the config file by explicitly passing them by way of the command line interface.
Step 4: Evaluation the launch script
You are actually ready to fine-tune the mannequin utilizing a mixture of PyTorch FSDP and QLoRA. We’ve ready a script referred to as launch_fsdp_qlora.py that can carry out the duties talked about within the following steps. The next is a fast evaluation of the important thing factors on this script earlier than launching the coaching job.
- Load the dataset from a JSON file situated on the specified path, utilizing the
load_datasetoperate to organize it for mannequin coaching.
- Put together the tokenizer and the mannequin.
We make use of the BitsAndBytes library to configure 4-bit quantization settings for our mannequin, enabling memory-efficient loading and computation.
By setting parameters corresponding to load_in_4bit and bnb_4bit_use_double_quant to True, we allow a dramatic discount in mannequin measurement with out important loss in efficiency. The nf4 quantization kind, coupled with bfloat16 compute and storage knowledge sorts, permits for nuanced management over the quantization course of, placing an optimum steadiness between mannequin compression and accuracy preservation. This configuration permits the deployment of huge fashions on resource-constrained {hardware}, making superior AI extra accessible and sensible for a variety of purposes.
- Provoke the coaching course of utilizing SFTTrainer from the Transformer Reinforcement Learning (TRL) library to fine-tune the mannequin. The
SFTTrainersimplifies the method of supervised fine-tuning for LLMs. This method makes fine-tuning environment friendly to adapt pre-trained fashions to particular duties or domains.
We use the LoraConfig class from the Hugging Face’s PEFT library to configure and add LoRA parameters (additionally referred to as “adapters”) to the mannequin.
Step 5: Positive-tune your mannequin
To fine-tune your mannequin, observe the steps within the subsequent sections.
Launch the coaching job
You are actually able to launch the coaching. We use the SageMaker Coaching estimator, which makes use of torchrun to provoke distributed coaching.
The SageMaker estimator simplifies the coaching course of by automating a number of key duties on this instance:
- The SageMaker estimator spins up a coaching cluster of 1
ml.p4d.24xlargeoccasion. SageMaker handles the setup and administration of those compute situations, which reduces your TCO. - This estimator additionally makes use of one of many pre-built containers managed by SageMaker, PyTorch, which incorporates an optimized compiled model of the PyTorch framework and its required dependencies and GPU-specific libraries for accelerated computations.
The coaching course of generates skilled adapters that shall be saved in a default S3 bucket named sagemaker-<area identify>-<account_id> for this job.
Monitor your coaching run
You’ll be able to monitor coaching metrics, corresponding to loss, and studying charge on your coaching run by way of the Weights & Biases Dashboard. The next figures present the outcomes of the coaching run, the place we monitor GPU utilization and GPU reminiscence utilization.
The instance is optimized to make use of GPU reminiscence to its most capability. Be aware that growing the batch measurement any additional will result in CUDA Out of Reminiscence errors.
The next graph reveals the GPU reminiscence utilization (for all eight GPUs) in the course of the coaching course of. You may also observe the GPU reminiscence utilization for any given time limit.
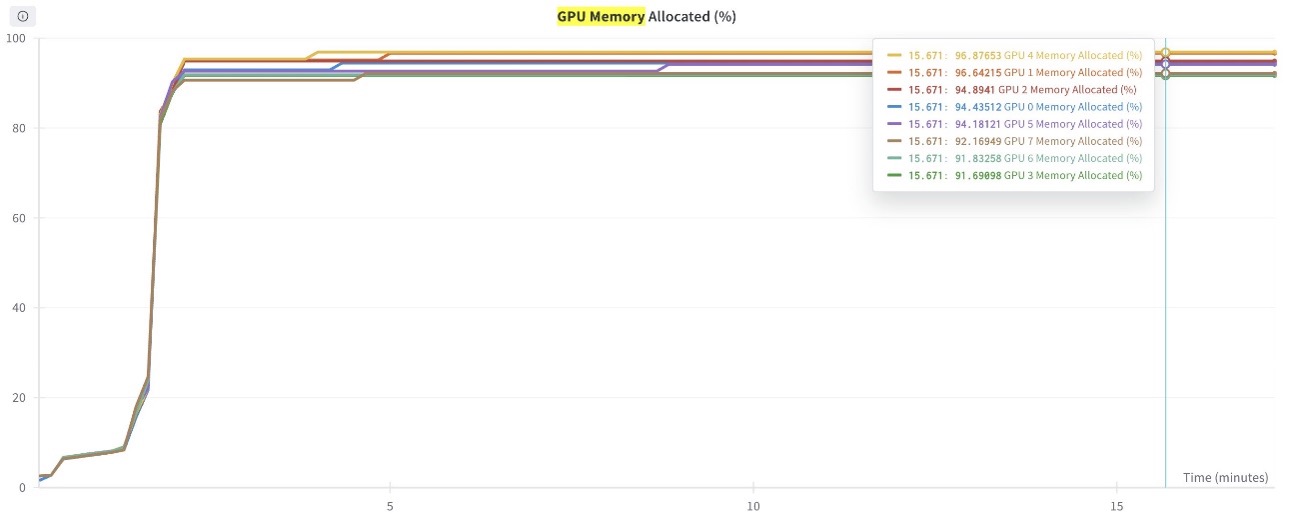
Determine 5: This graph reveals the GPU Reminiscence utilization plotted for all 8 GPUs within the coaching job.
The next graph reveals the GPU compute utilization (for all eight GPUs) in the course of the coaching course of. You may also observe the GPU reminiscence utilization for any given time limit.
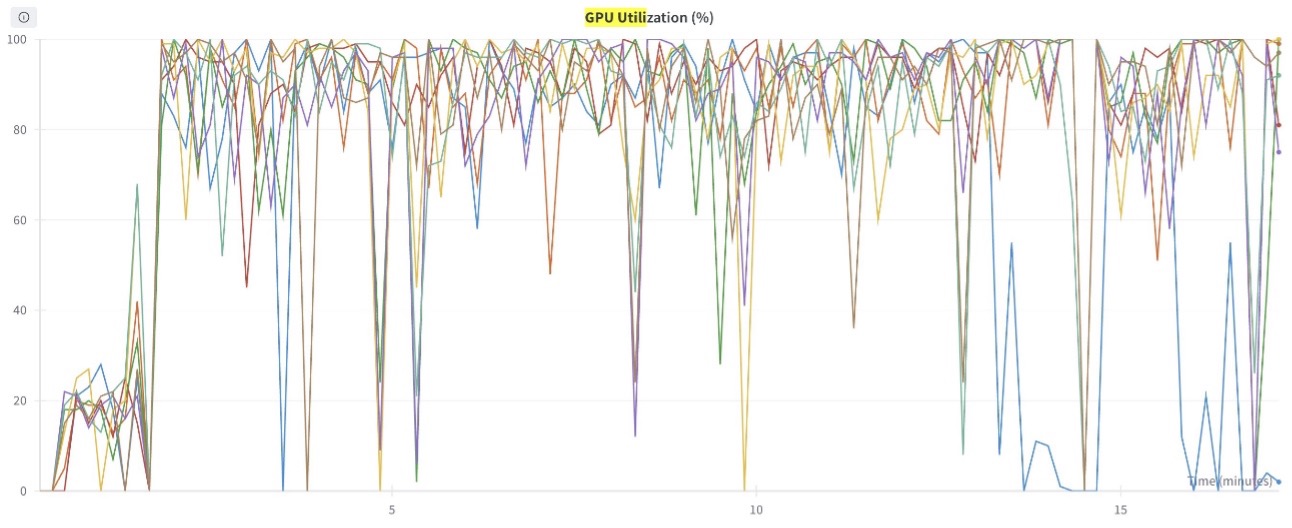
Determine 6: This graph reveals the GPU Compute utilization plotted for all 8 GPUs within the coaching job.
Step 6: Merge the skilled adapter with the bottom mannequin for inference
Merge the coaching LoRA adapter with the bottom mannequin. After the merge is full, run inference to search out the outcomes. Particularly, have a look at how the brand new fine-tuned and merged mannequin performs in comparison with the unique unmodified Mixtral-8x7b mannequin. The instance does the adapter merge and inference each in the identical launch script “merge_model_adapter.py.”
Earlier than launching the coaching job, evaluation the important thing elements of the merge script:
Use the Hugging Face Transformers library. Particularly, use AutoModelForCausalLM to load a PEFT mannequin from a specified HuggingFace mannequin listing (mistralai/Mixtral-8x7B-v0.1). We’ve got configured this library to have a low CPU reminiscence utilization (low_cpu_mem_usage=True) to cut back the CPU to GPU communication overhead, and we’ve additionally used automated gadget mapping (device_map="auto") whereas offloading the mannequin to a delegated folder to handle useful resource constraints.
After the mannequin is merged, ship inference requests to generate responses.
Step 7: Launch the SageMaker coaching job to merge the adapter
Run the next script as a part of the SageMaker coaching job.
First, discover the adapters that have been saved as a part of the coaching run.
Create and run the PyTorch estimator to configure the coaching job.
Right here’s the goal sentence (key immediate) to generate mannequin inference outcomes:
Floor reality inference (knowledge label):
Authentic mannequin inference (that’s, that means illustration):
Positive-tuned mannequin inference outcome (that’s, that means illustration):
The previous outcomes examine the inference outcomes of the fine-tuned mannequin in opposition to each the bottom reality and the inference outcomes of the unique unmodified Mixtral 8x7B mannequin. You’ll be able to observe that the fine-tuned mannequin gives extra particulars and higher illustration of the that means than the bottom mannequin. Run systematic analysis to quantify the fine-tuned mannequin’s enhancements on your manufacturing workloads.
Clear up
To scrub up your sources to keep away from incurring any extra fees, observe these steps:
- Delete any unused SageMaker Studio resources.
- (Non-compulsory) Delete the SageMaker Studio domain.
- Confirm that your coaching job isn’t working anymore. To take action, in your SageMaker console, select Coaching and test Coaching jobs.

Determine 7: Screenshot displaying that there aren’t any coaching jobs working anymore. That is what your console ought to appear like when you observe the clean-up steps offered
To be taught extra about cleansing up your provisioned sources, take a look at Clean up.
Conclusion
On this put up, we offered you with a step-by-step information to fine-tune the Mixtral 8x7B MoE mannequin with QLoRA. We use SageMaker Coaching Jobs and the Hugging Face PEFT bundle for QLoRA, with bitsandbytes for quantization collectively to carry out the fine-tuning process. The fine-tuning was performed utilizing the quantized mannequin loaded on a single compute occasion, which eliminates the necessity of a bigger cluster. As noticed, the mannequin efficiency improved with simply 50 epochs.
To be taught extra about Mistral on AWS and to search out extra examples, take a look at the mistral-on-aws GitHub repository. To get began, take a look at the pocket book on the mixtral_finetune_qlora GitHub repository. To be taught extra about generative AI on AWS, take a look at Generative AI on AWS, Amazon Bedrock, and Amazon SageMaker.
Concerning the Authors
 Aman Shanbhag is an Affiliate Specialist Options Architect on the ML Frameworks staff at Amazon Net Companies, the place he helps prospects and companions with deploying ML coaching and inference options at scale. Earlier than becoming a member of AWS, Aman graduated from Rice College with levels in pc science, arithmetic, and entrepreneurship.
Aman Shanbhag is an Affiliate Specialist Options Architect on the ML Frameworks staff at Amazon Net Companies, the place he helps prospects and companions with deploying ML coaching and inference options at scale. Earlier than becoming a member of AWS, Aman graduated from Rice College with levels in pc science, arithmetic, and entrepreneurship.
 Kanwaljit Khurmi is an AI/ML Principal Options Architect at Amazon Net Companies. He works with AWS product groups, engineering, and prospects to supply steerage and technical help for bettering the worth of their hybrid ML options when utilizing AWS. Kanwaljit focuses on serving to prospects with containerized and machine studying purposes.
Kanwaljit Khurmi is an AI/ML Principal Options Architect at Amazon Net Companies. He works with AWS product groups, engineering, and prospects to supply steerage and technical help for bettering the worth of their hybrid ML options when utilizing AWS. Kanwaljit focuses on serving to prospects with containerized and machine studying purposes.
 Nishant Karve is a Sr. Options Architect aligned with the healthcare and life sciences (HCLS) area. He collaborates with giant HCLS prospects for his or her generative AI initiatives and guides them from ideation to manufacturing.
Nishant Karve is a Sr. Options Architect aligned with the healthcare and life sciences (HCLS) area. He collaborates with giant HCLS prospects for his or her generative AI initiatives and guides them from ideation to manufacturing.





