Improve speech synthesis and video era fashions with RLHF utilizing audio and video segmentation in Amazon SageMaker
As generative AI fashions advance in creating multimedia content material, the distinction between good and nice output usually lies within the particulars that solely human suggestions can seize. Audio and video segmentation gives a structured option to collect this detailed suggestions, permitting fashions to study via reinforcement studying from human suggestions (RLHF) and supervised fine-tuning (SFT). Annotators can exactly mark and consider particular moments in audio or video content material, serving to fashions perceive what makes content material really feel genuine to human viewers and listeners.
Take, for example, text-to-video era, the place fashions have to study not simply what to generate however learn how to preserve consistency and pure move throughout time. When making a scene of an individual performing a sequence of actions, components just like the timing of actions, visible consistency, and smoothness of transitions contribute to the standard. Via exact segmentation and annotation, human annotators can present detailed suggestions on every of those points, serving to fashions study what makes a generated video sequence really feel pure quite than synthetic. Equally, in text-to-speech purposes, understanding the delicate nuances of human speech—from the size of pauses between phrases to modifications in emotional tone—requires detailed human suggestions at a phase stage. This granular enter helps fashions learn to produce speech that sounds pure, with applicable pacing and emotional consistency. As massive language fashions (LLMs) more and more combine extra multimedia capabilities, human suggestions turns into much more important in coaching them to generate wealthy, multi-modal content material that aligns with human high quality requirements.
The trail to creating efficient AI fashions for audio and video era presents a number of distinct challenges. Annotators have to determine exact moments the place generated content material matches or deviates from pure human expectations. For speech era, this implies marking actual factors the place intonation modifications, the place pauses really feel unnatural, or the place emotional tone shifts unexpectedly. In video era, annotators should pinpoint frames the place movement turns into jerky, the place object consistency breaks, or the place lighting modifications seem synthetic. Conventional annotation instruments, with primary playback and marking capabilities, usually fall quick in capturing these nuanced particulars.
Amazon SageMaker Ground Truth allows RLHF by permitting groups to combine detailed human suggestions immediately into mannequin coaching. Via custom human annotation workflows, organizations can equip annotators with instruments for high-precision segmentation. This setup allows the mannequin to study from human-labeled knowledge, refining its potential to provide content material that aligns with pure human expectations.
On this submit, we present you learn how to implement an audio and video segmentation resolution within the accompanying GitHub repository utilizing SageMaker Floor Fact. We information you thru deploying the mandatory infrastructure utilizing AWS CloudFormation, creating an inner labeling workforce, and organising your first labeling job. We exhibit learn how to use Wavesurfer.js for exact audio visualization and segmentation, configure each segment-level and full-content annotations, and construct the interface to your particular wants. We cowl each console-based and programmatic approaches to creating labeling jobs, and supply steering on extending the answer with your individual annotation wants. By the tip of this submit, you should have a totally practical audio/video segmentation workflow you could adapt for varied use instances, from coaching speech synthesis fashions to bettering video era capabilities.
Function Overview
The combination of Wavesurfer.js in our UI gives an in depth waveform visualization the place annotators can immediately see patterns in speech, silence, and audio depth. For example, when engaged on speech synthesis, annotators can visually determine unnatural gaps between phrases or abrupt modifications in quantity which may make generated speech sound robotic. The flexibility to zoom into these waveform patterns means they will work with millisecond precision—marking precisely the place a pause is simply too lengthy or the place an emotional transition occurs too abruptly.
On this snapshot of audio segmentation, we’re capturing a customer-representative dialog, annotating speaker segments, feelings, and transcribing the dialogue. The UI permits for playback pace adjustment and zoom performance for exact audio evaluation.

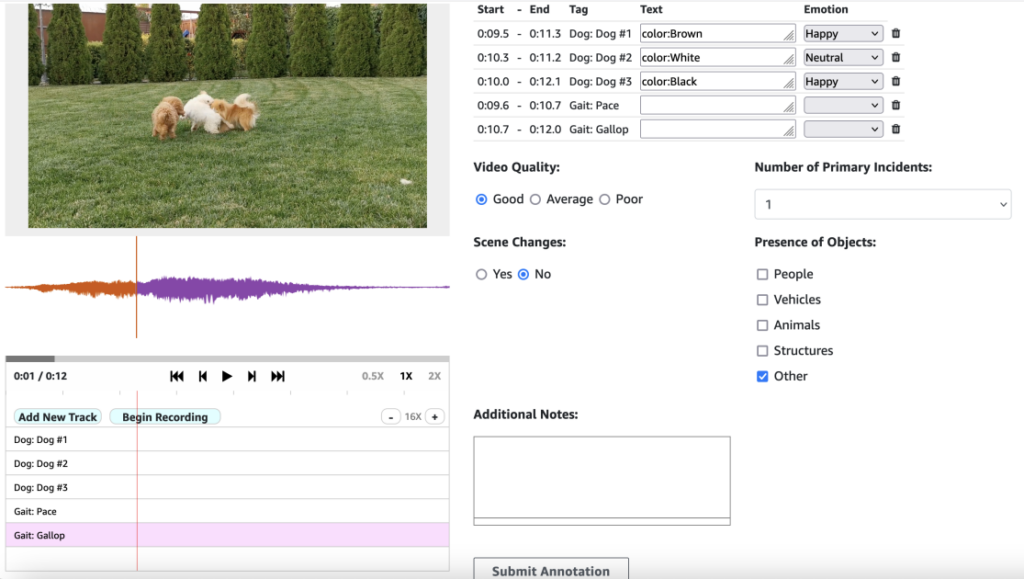
The multi-track characteristic lets annotators create separate tracks for evaluating totally different points of the content material. In a text-to-speech process, one monitor would possibly concentrate on pronunciation accuracy, one other on emotional consistency, and a 3rd on pure pacing. For video era duties, annotators can mark segments the place movement flows naturally, the place object consistency is maintained, and the place scene transitions work effectively. They will regulate playback pace to catch delicate particulars, and the visible timeline for exact begin and finish factors for every marked phase.
On this snapshot of video segmentation, we’re annotating a scene with canine, monitoring particular person animals, their colours, feelings, and gaits. The UI additionally allows total video high quality evaluation, scene change detection, and object presence classification.

Annotation course of
Annotators start by selecting Add New Monitor and choosing applicable classes and tags for his or her annotation process. After you create the monitor, you possibly can select Start Recording on the level the place you wish to begin a phase. Because the content material performs, you possibly can monitor the audio waveform or video frames till you attain the specified finish level, then select Cease Recording. The newly created phase seems in the fitting pane, the place you possibly can add classifications, transcriptions, or different related labels. This course of will be repeated for as many segments as wanted, with the flexibility to regulate phase boundaries, delete incorrect segments, or create new tracks for various annotation functions.

Significance of high-quality knowledge and lowering labeling errors
Excessive-quality knowledge is important for coaching generative AI fashions that may produce pure, human-like audio and video content material. The efficiency of those fashions relies upon immediately on the accuracy and element of human suggestions, which stems from the precision and completeness of the annotation course of. For audio and video content material, this implies capturing not simply what sounds or appears to be like unnatural, however precisely when and the way these points happen.
Our objective constructed UI in SageMaker Floor Fact addresses frequent challenges in audio and video annotation that usually result in inconsistent or imprecise suggestions. When annotators work with lengthy audio or video recordsdata, they should mark exact moments the place generated content material deviates from pure human expectations. For instance, in speech era, an unnatural pause would possibly final solely a fraction of a second, however its impression on perceived high quality is important. The device’s zoom performance permits annotators to develop these temporary moments throughout their display screen, making it attainable to mark the precise begin and finish factors of those delicate points. This precision helps fashions study the positive particulars that separate pure from artificial-sounding speech.
Answer overview
This audio/video segmentation resolution combines a number of AWS companies to create a sturdy annotation workflow. At its core, Amazon Simple Storage Service (Amazon S3) serves because the safe storage for enter recordsdata, manifest recordsdata, annotation outputs, and the net UI parts. SageMaker Floor Fact gives annotators with an online portal to entry their labeling jobs and manages the general annotation workflow. The next diagram illustrates the answer structure.

The UI template, which incorporates our specialised audio/video segmentation interface constructed with Wavesurfer.js, requires particular JavaScript and CSS recordsdata. These recordsdata are hosted via Amazon CloudFront distribution, offering dependable and environment friendly supply to annotators’ browsers. By utilizing CloudFront with an origin entry id and applicable bucket insurance policies, we permit the UI parts to be served to annotators. This setup follows AWS greatest practices for least-privilege entry, ensuring CloudFront can solely entry the precise UI recordsdata wanted for the annotation interface.
Pre-annotation and post-annotation AWS Lambda features are non-compulsory parts that may improve the workflow. The pre-annotation Lambda operate can course of the enter manifest file earlier than knowledge is introduced to annotators, enabling any obligatory formatting or modifications. Equally, the post-annotation Lambda operate can remodel the annotation outputs into particular codecs required for mannequin coaching. These features present flexibility to adapt the workflow to particular wants with out requiring modifications to the core annotation course of.
The answer makes use of AWS Identity and Access Management (IAM) roles to handle permissions:
- A SageMaker Floor Fact IAM position allows entry to Amazon S3 for studying enter recordsdata and writing annotation outputs
- If used, Lambda operate roles present the mandatory permissions for preprocessing and postprocessing duties
Let’s stroll via the method of organising your annotation workflow. We begin with a easy situation: you have got an audio file saved in Amazon S3, together with some metadata like a name ID and its transcription. By the tip of this walkthrough, you should have a totally practical annotation system the place your workforce can phase and classify this audio content material.
Stipulations
For this walkthrough, be sure to have the next:
Create your inner workforce
Earlier than we dive into the technical setup, let’s create a private workforce in SageMaker Floor Fact. This lets you check the annotation workflow together with your inner workforce earlier than scaling to a bigger operation.
- On the SageMaker console, select Labeling workforces.
- Select Personal for the workforce kind and create a brand new non-public workforce.
- Add workforce members utilizing their e mail addresses—they’ll obtain directions to arrange their accounts.
Deploy the infrastructure
Though this demonstrates utilizing a CloudFormation template for fast deployment, you too can arrange the parts manually. The property (JavaScript and CSS recordsdata) can be found in our GitHub repository. Full the next steps for guide deployment:
- Obtain these property immediately from the GitHub repository.
- Host them in your individual S3 bucket.
- Arrange your individual CloudFront distribution to serve these recordsdata.
- Configure the mandatory permissions and CORS settings.
This guide method provides you extra management over infrastructure setup and could be most popular in case you have current CloudFront distributions or a have to customise safety controls and property.
The remainder of this submit will concentrate on the CloudFormation deployment method, however the labeling job configuration steps stay the identical no matter the way you select to host the UI property.
![]()
This CloudFormation template creates and configures the next AWS assets:
- S3 bucket for UI parts:
- Shops the UI JavaScript and CSS recordsdata
- Configured with CORS settings required for SageMaker Floor Fact
- Accessible solely via CloudFront, in a roundabout way public
- Permissions are set utilizing a bucket coverage that grants learn entry solely to the CloudFront Origin Entry Id (OAI)
- CloudFront distribution:
- Gives safe and environment friendly supply of UI parts
- Makes use of an OAI to securely entry the S3 bucket
- Is configured with applicable cache settings for optimum efficiency
- Entry logging is enabled, with logs being saved in a devoted S3 bucket
- S3 bucket for CloudFront logs:
- Shops entry logs generated by CloudFront
- Is configured with the required bucket insurance policies and ACLs to permit CloudFront to write down logs
- Object possession is ready to ObjectWriter to allow ACL utilization for CloudFront logging
- Lifecycle configuration is ready to routinely delete logs older than 90 days to handle storage
- Lambda operate:
- Downloads UI recordsdata from our GitHub repository
- Shops them within the S3 bucket for UI parts
- Runs solely throughout preliminary setup and makes use of least privilege permissions
- Permissions embody Amazon CloudWatch Logs for monitoring and particular S3 actions (learn/write) restricted to the created bucket
After the CloudFormation stack deployment is full, yow will discover the CloudFront URLs for accessing the JavaScript and CSS recordsdata on the AWS CloudFormation console. You want these CloudFront URLs to replace your UI template earlier than creating the labeling job. Observe these values—you’ll use them when creating the labeling job.
Put together your enter manifest
Earlier than you create the labeling job, you must put together an enter manifest file that tells SageMaker Floor Fact what knowledge to current to annotators. The manifest construction is versatile and will be custom-made primarily based in your wants. For this submit, we use a easy construction:
You may adapt this construction to incorporate further metadata that your annotation workflow requires. For instance, you would possibly wish to add speaker info, timestamps, or different contextual knowledge. The secret is ensuring your UI template is designed to course of and show these attributes appropriately.
Create your labeling job
With the infrastructure deployed, let’s create the labeling job in SageMaker Floor Fact. For full directions, discuss with Accelerate custom labeling workflows in Amazon SageMaker Ground Truth without using AWS Lambda.
- On the SageMaker console, select Create labeling job.
- Give your job a reputation.
- Specify your enter knowledge location in Amazon S3.
- Specify an output bucket the place annotations shall be saved.
- For the duty kind, choose Customized labeling process.
- Within the UI template subject, find the placeholder values for the JavaScript and CSS recordsdata and replace as follows:
- Change
audiovideo-wavesufer.jstogether with your CloudFront JavaScript URL from the CloudFormation stack outputs. - Change
audiovideo-stylesheet.csstogether with your CloudFront CSS URL from the CloudFormation stack outputs.
- Change
- Earlier than you launch the job, use the Preview characteristic to confirm your interface.
It’s best to see the Wavesurfer.js interface load appropriately with all controls working correctly. This preview step is essential—it confirms that your CloudFront URLs are appropriately specified and the interface is correctly configured.
Programmatic setup
Alternatively, you possibly can create your labeling job programmatically utilizing the CreateLabelingJob API. That is notably helpful for automation or when you must create a number of jobs. See the next code:
The API method provides the identical performance because the SageMaker console, however permits for automation and integration with current workflows. Whether or not you select the SageMaker console or API method, the outcome is identical: a totally configured labeling job prepared to your annotation workforce.
Understanding the output
After your annotators full their work, SageMaker Floor Fact will generate an output manifest in your specified S3 bucket. This manifest incorporates wealthy info at two ranges:
- Phase-level classifications – Particulars about every marked phase, together with begin and finish instances and assigned classes
- Full-content classifications – Total scores and classifications for the whole file
Let’s take a look at a pattern output to know its construction:
This two-level annotation construction gives precious coaching knowledge to your AI fashions, capturing each fine-grained particulars and total content material evaluation.
Customizing the answer
Our audio/video segmentation resolution is designed to be extremely customizable. Let’s stroll via how one can adapt the interface to match your particular annotation necessities.
Customise segment-level annotations
The segment-level annotations are managed within the report() operate of the JavaScript code. The next code snippet reveals how one can modify the annotation choices for every phase:
You may take away current fields or add new ones primarily based in your wants. Be sure to’re updating the information mannequin (updateTrackListData operate) to deal with your {custom} fields.
Modify full-content classifications
For classifications that apply to the whole audio/video file, you possibly can modify the HTML template. The next code is an instance of including {custom} classification choices:
The classifications you add right here shall be included in your output manifest, permitting you to seize each segment-level and full-content annotations.
Extending Wavesurfer.js performance
Our resolution makes use of Wavesurfer.js, an open supply audio visualization library. Though we’ve applied core performance for segmentation and annotation, you possibly can lengthen this additional utilizing Wavesurfer.js’s wealthy characteristic set. For instance, you would possibly wish to:
- Add spectrogram visualization
- Implement further playback controls
- Improve zoom performance
- Add timeline markers
For these customizations, we suggest consulting the Wavesurfer.js documentation. When implementing further Wavesurfer.js options, keep in mind to check totally within the SageMaker Floor Fact preview to overview compatibility with the labeling workflow.
Wavesurfer.js is distributed below the BSD-3-Clause license. Though we’ve examined the combination totally, modifications you make to the Wavesurfer.js implementation ought to be examined in your setting. The Wavesurfer.js neighborhood gives glorious documentation and assist for implementing further options.
Clear up
To wash up the assets created throughout this tutorial, comply with these steps:
- Cease the SageMaker Floor Fact labeling job if it’s nonetheless operating and also you not want it. This can halt ongoing labeling duties and cease further expenses from accruing.
- Empty the S3 buckets by deleting all objects inside them. S3 buckets have to be emptied earlier than they are often deleted, so eradicating all saved recordsdata facilitates a easy cleanup course of.
- Delete the CloudFormation stack to take away all of the AWS assets provisioned by the template. This motion will routinely delete related companies just like the S3 buckets, CloudFront distribution, Lambda operate, and associated IAM roles.
Conclusion
On this submit, we walked via implementing an audio and video segmentation resolution utilizing SageMaker Floor Fact. We noticed learn how to deploy the mandatory infrastructure, configure the annotation interface, and create labeling jobs each via the SageMaker console and programmatically. The answer’s potential to seize exact segment-level annotations together with total content material classifications makes it notably precious for producing high-quality coaching knowledge for generative AI fashions, whether or not you’re engaged on speech synthesis, video era, or different multimedia AI purposes. As you develop your AI fashions for audio and video era, do not forget that the standard of human suggestions immediately impacts your mannequin’s efficiency—whether or not you’re coaching fashions to generate extra natural-sounding speech, create coherent video sequences, or perceive complicated audio patterns.
We encourage you to go to our GitHub repository to discover the answer additional and adapt it to your particular wants. You may improve your annotation workflows by customizing the interface, including new classification classes, or implementing further Wavesurfer.js options. To study extra about creating {custom} labeling workflows in SageMaker Floor Fact, go to Accelerate custom labeling workflows in Amazon SageMaker Ground Truth without using AWS Lambda and Custom labeling workflows.
If you happen to’re in search of a turnkey knowledge labeling resolution, think about Amazon SageMaker Ground Truth Plus, which gives entry to an skilled workforce educated in varied machine studying duties. With SageMaker Floor Fact Plus, you possibly can rapidly obtain high-quality annotations with out the necessity to construct and handle your individual labeling workflows, lowering prices by as much as 40% and accelerating the supply of labeled knowledge at scale.
Begin constructing your annotation workflow immediately and contribute to the subsequent era of AI fashions that push the boundaries of what’s attainable in audio and video era.
Concerning the Authors
 Sundar Raghavan is an AI/ML Specialist Options Architect at AWS, serving to prospects leverage SageMaker and Bedrock to construct scalable and cost-efficient pipelines for laptop imaginative and prescient purposes, pure language processing, and generative AI. In his free time, Sundar loves exploring new locations, sampling native eateries and embracing the nice outside.
Sundar Raghavan is an AI/ML Specialist Options Architect at AWS, serving to prospects leverage SageMaker and Bedrock to construct scalable and cost-efficient pipelines for laptop imaginative and prescient purposes, pure language processing, and generative AI. In his free time, Sundar loves exploring new locations, sampling native eateries and embracing the nice outside.
 Vineet Agarwal is a Senior Supervisor of Buyer Supply within the Amazon Bedrock workforce accountable for Human within the Loop companies. He has been in AWS for over 2 years managing Go-to-Market actions, enterprise and technical operations. Previous to AWS, he labored in SaaS , Fintech and Telecommunications trade in companies management position. He has MBA from the Indian Faculty of Enterprise and B. Tech in Electronics and Communications Engineering from Nationwide Institute of Expertise, Calicut (India). In his free time, Vineet loves taking part in racquetball and having fun with outside actions along with his household.
Vineet Agarwal is a Senior Supervisor of Buyer Supply within the Amazon Bedrock workforce accountable for Human within the Loop companies. He has been in AWS for over 2 years managing Go-to-Market actions, enterprise and technical operations. Previous to AWS, he labored in SaaS , Fintech and Telecommunications trade in companies management position. He has MBA from the Indian Faculty of Enterprise and B. Tech in Electronics and Communications Engineering from Nationwide Institute of Expertise, Calicut (India). In his free time, Vineet loves taking part in racquetball and having fun with outside actions along with his household.




