How Zalando optimized large-scale inference and streamlined ML operations on Amazon SageMaker
This publish is cowritten with Mones Raslan, Ravi Sharma and Adele Gouttes from Zalando.
Zalando SE is one in every of Europe’s largest ecommerce trend retailers with round 50 million energetic prospects. Zalando faces the problem of normal (weekly or each day) {discount} steering for greater than 1 million merchandise, additionally known as markdown pricing. Markdown pricing is a pricing method that adjusts costs over time and is a typical technique to maximise income from items which have a restricted lifespan or are topic to seasonal demand (Sul 2023).
As a result of many gadgets are ordered forward of season and never replenished afterwards, companies have an curiosity in promoting the merchandise evenly all through the season. The principle rationale is to keep away from overstock and understock conditions. An overstock state of affairs would result in excessive prices after the season ends, and an understock state of affairs would result in misplaced gross sales as a result of prospects would select to purchase at opponents.
To deal with this difficulty, {discount} steering is an efficient method as a result of it influences item-level demand and due to this fact inventory ranges.
The markdown pricing algorithmic resolution Zalando depends on is a forecast-then-optimize method (Kunz et al. 2023 and Streeck et al. 2024). A high-level description of the markdown pricing algorithm resolution could be damaged down into 4 steps:
- Low cost-dependent forecast – Utilizing previous information, forecast future discount-dependent portions which are related for figuring out the long run revenue of an merchandise. The next are vital metrics that have to be forecasted:
-
- Demand – What number of gadgets might be offered within the subsequent X weeks for various reductions?
- Return price – What share of offered gadgets might be returned by the client?
- Return time – When will a returned merchandise reappear within the warehouse in order that it may be offered once more?
- Success prices – How a lot will delivery and returning an merchandise price?
- Residual worth – At what worth can an merchandise be realistically offered after the tip of the season?
-
- Decide an optimum {discount} – Use the forecasts from Step 1 as enter to maximise revenue as a operate of {discount}, which is topic to enterprise and inventory constraints. Concrete particulars could be present in Streeck et al. 2024.
- Suggestions – Low cost suggestions decided in Step 2 are integrated into the store or overwritten by pricing managers.
- Knowledge assortment – Up to date store costs result in up to date demand. The brand new data is used to reinforce the coaching units utilized in Step 1 for forecasting reductions.
The next diagram illustrates this workflow.

The main focus of this publish is on Step 1, making a discount-dependent forecast. Relying on the complexity of the issue and the construction of underlying information, the predictive fashions at Zalando vary from easy statistical averages, over tree-based fashions to a Transformer-based deep studying structure (Kunz et al. 2023).
Whatever the fashions used, all of them embody information preprocessing, coaching, and inference over a number of billions of information containing weekly information spanning a number of years and markets to provide forecasts. Working such large-scale forecasting requires resilient, reusable, reproducible, and automatic machine studying (ML) workflows with quick experimentation and steady enhancements.
On this publish, we current the implementation and orchestration of the forecast mannequin’s coaching and inference. The answer was in-built a current collaboration between AWS Professional Services, beneath which Well-Architected machine learning design principles had been adopted.
The results of the collaboration is a blueprint that’s being reused for comparable use circumstances inside Zalando.
Motivation for streamlined ML operations and large-scale inference
As talked about earlier, {discount} steering of greater than 1,000,000 gadgets each week requires producing a considerable amount of forecast information (roughly 10 billion). Efficient {discount} steering requires steady enchancment of forecasting accuracy.
To enhance forecasting accuracy, all concerned ML fashions have to be retrained, and predictions have to be produced weekly, and in some circumstances each day.
Given the quantity of knowledge and nature of ML fashions in query, coaching and inference takes from a number of hours to a number of days. Any error within the course of represents dangers when it comes to operational prices and alternative prices as a result of Zalando’s industrial pricing workforce expects outcomes in line with outlined service stage goals (SLOs).
If an ML mannequin coaching or inference fails in any given week, an ML mannequin with outdated information is used to generate the forecast information. This has a direct impression on income for Zalando as a result of the forecasts and reductions are much less correct when utilizing outdated information.
On this context, our motivation for streamlining ML operations (MLOps) could be summarized as follows:
- Velocity up experimentation and analysis, and allow fast prototyping and supply enough time to fulfill SLOs
- Design the structure in a templated method with the target of supporting a number of mannequin coaching and inference, offering a unified ML infrastructure and enabling automated integration for coaching and inference
- Present scalability to accommodate several types of forecasting fashions (additionally supporting GPU) and rising datasets
- Make end-to-end ML pipelines and experimentation repeatable, fault-tolerant, and traceable
To realize these goals, we explored a number of distributed computing instruments.
Throughout our evaluation section, we found two key elements that influenced our selection of distributed computing device. First, our enter datasets had been saved within the columnar Parquet format, unfold throughout a number of partitions. Second, the required inference operations exhibited embarrassingly parallel traits, that means they could possibly be run independently with out necessitating inter-node communication. These elements guided our decision-making course of for choosing probably the most appropriate distributed computing device.
We explored a number of massive information processing options and determined to make use of an Amazon SageMaker Processing job for the next causes:
- It’s extremely configurable, with help of pre-built photographs, customized cluster necessities, and containers. This makes it easy to handle and scale with no overhead of inter-node communication.
- Amazon SageMaker helps easy experimentation with Amazon SageMaker Studio.
- SageMaker Processing integrates seamlessly with AWS Identity and Access Management (IAM), Amazon Simple Storage Service (Amazon S3), AWS Step Functions, and different AWS providers.
- SageMaker Processing helps the choice to improve to GPUs with minimal change within the structure.
- SageMaker Processing unifies our coaching and inference structure, enabling us to make use of inference structure for mannequin backtesting.
We additionally explored different instruments, however most well-liked SageMaker Processing jobs for the next causes:
- Apache Spark on Amazon EMR – Because of the inference operations displaying embarrassingly parallel traits and never requiring inter-node communication, we determined in opposition to utilizing Spark on Amazon EMR, which concerned extra overhead for inter-node communication.
- SageMaker batch rework jobs – Batch rework jobs have a tough restrict of 100 MB payload measurement, which couldn’t accommodate the dataset partitions. This proved to be a limiting issue for operating batch inference on it.
Answer overview
Giant-scale inference requires a scalable inference and scalable coaching resolution.
We approached this by designing an structure with an event-driven precept in thoughts that enabled us to construct ML workflows for coaching and inference utilizing infrastructure as code (IaC). On the similar time, we integrated steady integration and supply (CI/CD) processes, automated testing, and mannequin versioning into the answer. As a result of utilized scientists have to iterate and experiment, we created a versatile experimentation surroundings very near the manufacturing one.
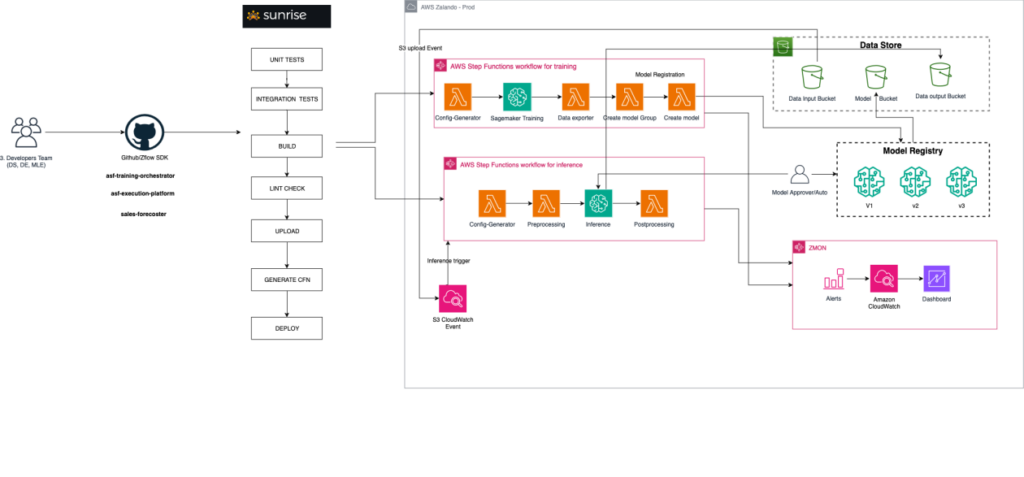
The next high-level structure diagram exhibits the ML resolution deployed on AWS, which is now utilized by Zalando’s forecasting workforce to run pricing forecasting fashions.

The structure consists of the next elements:
- Dawn – Dawn is Zalando’s inside CI/CD device, which automates the deployment of the ML resolution in an AWS surroundings.
- AWS Step Capabilities – AWS Step Functions orchestrates all the ML workflow, coordinating numerous phases similar to mannequin coaching, versioning, and inference. Step Capabilities can seamlessly combine with AWS providers similar to SageMaker, AWS Lambda, and Amazon S3.
- Knowledge retailer – S3 buckets function the info retailer, holding enter and output information in addition to mannequin artifacts.
- Mannequin registry – Amazon SageMaker Model Registry supplies a centralized repository for organizing, versioning, and monitoring fashions.
- Logging and monitoring – Amazon CloudWatch handles logging and monitoring, forwarding the metrics to Zalando’s inside alerting device for additional evaluation and notifications.
To orchestrate a number of steps inside the coaching and inference pipelines, we used Zflow, a Python-based SDK developed by Zalando that makes use of the AWS Cloud Development Kit (AWS CDK) to create Step Capabilities workflows. It makes use of SageMaker coaching jobs for mannequin coaching, processing jobs for batch inference, and the mannequin registry for mannequin versioning.
All of the elements are declared utilizing Zflow and are deployed utilizing CI/CD (Dawn) to construct reusable end-to-end ML workflows, whereas integrating with AWS providers.
The reusable ML workflow permits experimentation and productionization of various fashions. This permits the separation of the mannequin orchestration and enterprise logic, permitting information scientists and utilized scientists to deal with the enterprise logic and use these predefined ML workflows.
A completely automated manufacturing workflow
The MLOps lifecycle begins with ingesting the coaching information within the S3 buckets. On the arrival of knowledge, Amazon EventBridge invokes the coaching workflow (containing SageMaker coaching jobs). Upon completion of the coaching job, a brand new mannequin is created and saved in SageMaker Mannequin Registry.
To keep up high quality management, the workforce verifies the mannequin properties in opposition to the predetermined necessities. If the mannequin meets the factors, it’s authorised for inference. After a mannequin is authorised, the inference pipeline will level to the most recent authorised model of that mannequin group.
When inference information is ingested on Amazon S3, EventBridge robotically runs the inference pipeline.
This automated workflow streamlines all the course of, from information ingestion to inference, lowering guide interventions and minimizing the chance of errors. Through the use of AWS providers similar to Amazon S3, EventBridge, SageMaker, and Step Capabilities, we had been in a position to orchestrate the end-to-end MLOps lifecycle effectively and reliably.
Seamless integration of experiments
To permit for easy mannequin experimentation, we created SageMaker notebooks that use the Amazon SageMaker SDK to launch SageMaker coaching and processing jobs. The notebooks use the identical Docker photographs (SageMaker Studio pocket book kernels) as those utilized in CI/CD workflows all the best way to manufacturing. With these notebooks, utilized scientists can deliver their very own code and hook up with completely different information sources, whereas additionally experimenting with completely different occasion sizes by scaling up or down computation and reminiscence necessities. The experimentation setup displays the manufacturing workflows.
Conclusion
On this publish, we described how MLOps, in collaboration between Zalando and AWS Skilled Providers, had been streamlined with the target of enhancing {discount} steering at Zalando.
MLOps greatest practices applied for forecast mannequin coaching and inference has offered Zalando a versatile and scalable structure with diminished engineering complexity.
The applied structure permits Zalando’s workforce to conduct large-scale inference, with frequent experimentation and decreased dangers of lacking weekly SLOs.
Templatization and automation is predicted to offer engineers with weekly financial savings of three–4 hours per ML mannequin in operations and upkeep duties. Moreover, the transition from information science experimentation into mannequin productionization has been streamlined.
To study extra about ML streamlining, experimentation, and scalability, confer with the next weblog posts:
References
- Eleanor, L., R. Brian, Ok. Jalaj, and D. A. Little. 2022. “Promotheus: An Finish-to-Finish Machine Studying Framework for Optimizing Markdown in On-line Style E-commerce.” arXiv. https://arxiv.org/abs/2207.01137.
- Kunz, M., S. Birr, M. Raslan, L. Ma, Z. Li, A. Gouttes, M. Koren, et al. 2023. “Deep Studying based mostly Forecasting: a case research from the web trend trade.” In Forecasting with Synthetic Intelligence: Idea and Purposes (Switzerland), 2023.
- Streeck, R., T. Gellert, A. Schmitt, A. Dipkaya, V. Fux, T. Januschowski, and T. Berthold. 2024. “Tips from the Commerce for Giant-Scale Markdown Pricing: Heuristic Minimize Technology for Lagrangian Decomposition.” arXiv. https://arxiv.org/abs/2404.02996#.
- Sul, Inki. 2023. “Buyer-centric Pricing: Maximizing Income By means of Understanding Buyer Conduct.” The College of Texas at Dallas. https://utd-ir.tdl.org/gadgets/a2b9fde1-aa17-4544-a16e-c5a266882dda.
Concerning the Authors
 Mones Raslan is an Utilized Scientist at Zalando’s Pricing Platform with a background in utilized arithmetic. His work encompasses the event of business-relevant and scalable forecasting fashions, stretching from prototyping to deployment. In his spare time, Mones enjoys operatic singing and scuba diving.
Mones Raslan is an Utilized Scientist at Zalando’s Pricing Platform with a background in utilized arithmetic. His work encompasses the event of business-relevant and scalable forecasting fashions, stretching from prototyping to deployment. In his spare time, Mones enjoys operatic singing and scuba diving.
 Ravi Sharma is a Senior Software program Engineer at Zalando’s Pricing Platform, bringing expertise throughout various domains similar to soccer betting, radio astronomy, healthcare, and ecommerce. His broad technical experience permits him to ship sturdy and scalable options constantly. Outdoors work, he enjoys nature hikes, desk tennis, and badminton.
Ravi Sharma is a Senior Software program Engineer at Zalando’s Pricing Platform, bringing expertise throughout various domains similar to soccer betting, radio astronomy, healthcare, and ecommerce. His broad technical experience permits him to ship sturdy and scalable options constantly. Outdoors work, he enjoys nature hikes, desk tennis, and badminton.
 Adele Gouttes is a Senior Utilized Scientist, with expertise in machine studying, time sequence forecasting, and causal inference. She has expertise creating merchandise finish to finish, from the preliminary discussions with stakeholders to manufacturing, and creating technical roadmaps for cross-functional groups. Adele performs music and enjoys gardening.
Adele Gouttes is a Senior Utilized Scientist, with expertise in machine studying, time sequence forecasting, and causal inference. She has expertise creating merchandise finish to finish, from the preliminary discussions with stakeholders to manufacturing, and creating technical roadmaps for cross-functional groups. Adele performs music and enjoys gardening.
 Irem Gokcek is a Knowledge Architect on the AWS Skilled Providers workforce, with experience spanning each analytics and AI/ML. She has labored with prospects from numerous industries, similar to retail, automotive, manufacturing, and finance, to construct scalable information architectures and generate invaluable insights from the info. In her free time, she is enthusiastic about swimming and portray.
Irem Gokcek is a Knowledge Architect on the AWS Skilled Providers workforce, with experience spanning each analytics and AI/ML. She has labored with prospects from numerous industries, similar to retail, automotive, manufacturing, and finance, to construct scalable information architectures and generate invaluable insights from the info. In her free time, she is enthusiastic about swimming and portray.
 Jean-Michel Lourier is a Senior Knowledge Scientist inside AWS Skilled Providers. He leads groups implementing data-driven purposes aspect by aspect with AWS prospects to generate enterprise worth out of their information. He’s enthusiastic about diving into tech and studying about AI, machine studying, and their enterprise purposes. He’s additionally a biking fanatic.
Jean-Michel Lourier is a Senior Knowledge Scientist inside AWS Skilled Providers. He leads groups implementing data-driven purposes aspect by aspect with AWS prospects to generate enterprise worth out of their information. He’s enthusiastic about diving into tech and studying about AI, machine studying, and their enterprise purposes. He’s additionally a biking fanatic.
 Junaid Baba, a Senior DevOps Marketing consultant with AWS Skilled Providers, has experience in machine studying, generative AI operations, and cloud-centered architectures. He applies these expertise to design scalable options for purchasers within the international retail and monetary providers sectors. In his spare time, Junaid spends high quality time along with his household and finds pleasure in climbing adventures.
Junaid Baba, a Senior DevOps Marketing consultant with AWS Skilled Providers, has experience in machine studying, generative AI operations, and cloud-centered architectures. He applies these expertise to design scalable options for purchasers within the international retail and monetary providers sectors. In his spare time, Junaid spends high quality time along with his household and finds pleasure in climbing adventures.
 Luis Bustamante is a Senior Engagement Supervisor inside AWS Skilled Providers. He helps prospects speed up their journey to the cloud by way of experience in digital transformation, cloud migration, and IT distant supply. He enjoys touring and studying about historic occasions.
Luis Bustamante is a Senior Engagement Supervisor inside AWS Skilled Providers. He helps prospects speed up their journey to the cloud by way of experience in digital transformation, cloud migration, and IT distant supply. He enjoys touring and studying about historic occasions.
 Viktor Malesevic is a Senior Machine Studying Engineer inside AWS Skilled Providers, main groups to construct superior machine studying options within the cloud. He’s enthusiastic about making AI impactful, overseeing all the course of from modeling to manufacturing. In his spare time, he enjoys browsing, biking, and touring.
Viktor Malesevic is a Senior Machine Studying Engineer inside AWS Skilled Providers, main groups to construct superior machine studying options within the cloud. He’s enthusiastic about making AI impactful, overseeing all the course of from modeling to manufacturing. In his spare time, he enjoys browsing, biking, and touring.





