Tracing the Transformer in Diagrams | by Eric Silberstein | Nov, 2024
What precisely do you place in, what precisely do you get out, and the way do you generate textual content with it?
Final week I used to be listening to an Acquired episode on Nvidia. The episode talks about transformers: the T in GPT and a candidate for the largest invention of the twenty first century.
Strolling down Beacon Road, listening, I used to be considering, I perceive transformers, proper? You masks out tokens throughout coaching, you will have these consideration heads that study to attach ideas in textual content, you are expecting the chance of the subsequent phrase. I’ve downloaded LLMs from Hugging Face and performed with them. I used GPT-3 within the early days earlier than the “chat” half was discovered. At Klaviyo we even constructed one of many first GPT-powered generative AI options in our subject line assistant. And means again I labored on a grammar checker powered by an older model language mannequin. So possibly.
The transformer was invented by a group at Google engaged on automated translation, like from English to German. It was launched to the world in 2017 within the now well-known paper Attention Is All You Need. I pulled up the paper and checked out Determine 1:
Hmm…if I understood, it was solely on the most hand-wavy stage. The extra I appeared on the diagram and browse the paper, the extra I spotted I didn’t get the main points. Listed here are a couple of questions I wrote down:
- Throughout coaching, are the inputs the tokenized sentences in English and the outputs the tokenized sentences in German?
- What precisely is every merchandise in a coaching batch?
- Why do you feed the output into the mannequin and the way is “masked multi-head consideration” sufficient to maintain it from dishonest by studying the outputs from the outputs?
- What precisely is multi-head consideration?
- How precisely is loss calculated? It may possibly’t be that it takes a supply language sentence, interprets the entire thing, and computes the loss, that doesn’t make sense.
- After coaching, what precisely do you feed in to generate a translation?
- Why are there three arrows going into the multi-head consideration blocks?
I’m positive these questions are simple and sound naive to 2 classes of individuals. The primary is individuals who had been already working with comparable fashions (e.g. RNN, encoder-decoder) to do comparable issues. They should have immediately understood what the Google group achieved and the way they did it once they learn the paper. The second is the various, many extra individuals who realized how vital transformers had been these final seven years and took the time to study the main points.
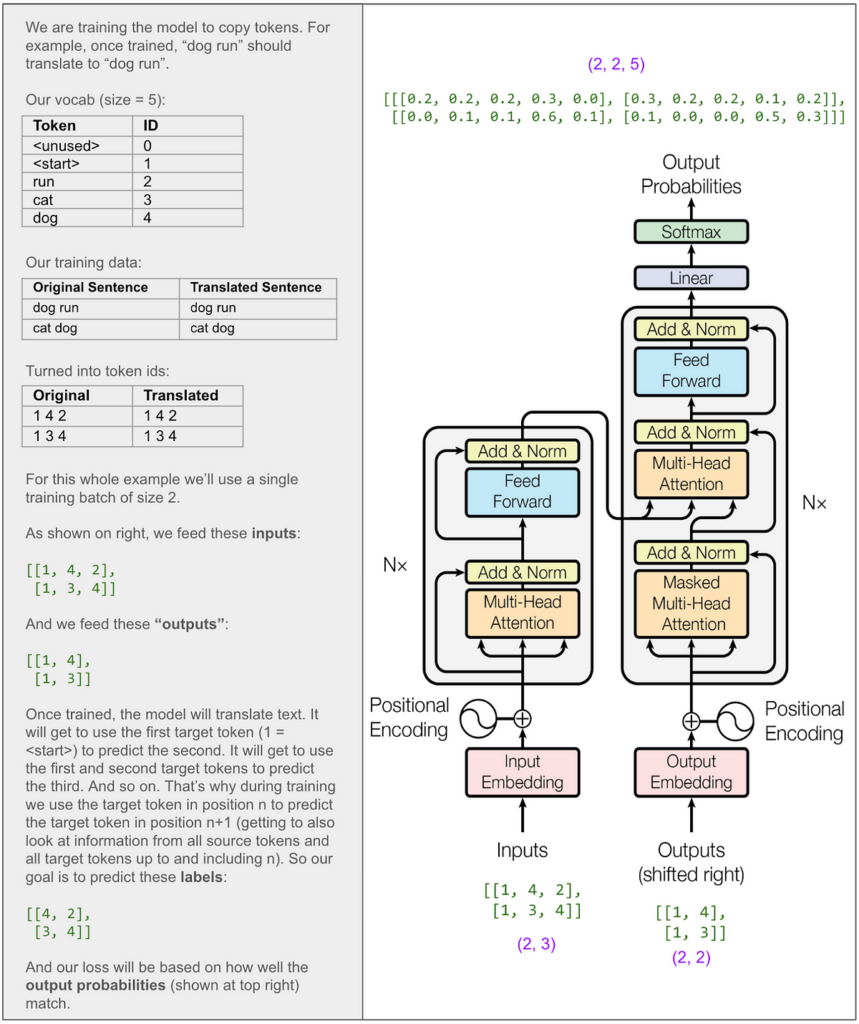
Nicely, I needed to study, and I figured one of the simplest ways was to construct the mannequin from scratch. I received misplaced fairly shortly and as a substitute determined to hint code another person wrote. I discovered this terrific notebook that explains the paper and implements the mannequin in PyTorch. I copied the code and educated the mannequin. I saved every part (inputs, batches, vocabulary, dimensions) tiny in order that I may hint what was taking place at every step. I discovered that noting the scale and the tensors on the diagrams helped me preserve issues straight. By the point I completed I had fairly good solutions to all of the questions above, and I’ll get again to answering them after the diagrams.
Listed here are cleaned up variations of my notes. All the things on this half is for coaching one single, tiny batch, which implies all of the tensors within the totally different diagrams go collectively.
To maintain issues simple to observe, and copying an concept from the pocket book, we’re going to coach the mannequin to repeat tokens. For instance, as soon as educated, “canine run” ought to translate to “canine run”.
In different phrases:
And right here’s attempting to place into phrases what the tensor dimensions (proven in purple) on the diagram thus far imply:
One of many hyperparameters is d-model and within the base mannequin within the paper it’s 512. On this instance I made it 8. This implies our embedding vectors have size 8. Right here’s the principle diagram once more with dimensions marked in a bunch of locations:
Let’s zoom in on the enter to the encoder:
Many of the blocks proven within the diagram (add & norm, feed ahead, the ultimate linear transformation) act solely on the final dimension (the 8). If that’s all that was taking place then the mannequin would solely get to make use of the knowledge in a single place within the sequence to foretell a single place. Someplace it should get to “combine issues up” amongst positions and that magic occurs within the multi-head consideration blocks.
Let’s zoom in on the multi-head consideration block throughout the encoder. For this subsequent diagram, remember the fact that in my instance I set the hyperparameter h (variety of heads) to 2. (Within the base mannequin within the paper it’s 8.)
How did (2,3,8) grow to be (2,2,3,4)? We did a linear transformation, then took the outcome and break up it into variety of heads (8 / 2 = 4) and rearranged the tensor dimensions in order that our second dimension is the pinnacle. Let’s take a look at some precise tensors:
We nonetheless haven’t completed something that mixes info amongst positions. That’s going to occur subsequent within the scaled dot-product consideration block. The “4” dimension and the “3” dimension will lastly contact.
Let’s take a look at the tensors, however to make it simpler to observe, we’ll look solely on the first merchandise within the batch and the primary head. In different phrases, Q[0,0], Okay[0,0], and many others. The identical factor might be taking place to the opposite three.
Let’s take a look at that ultimate matrix multiplication between the output of the softmax and V:
Following from the very starting, we will see that up till that multiplication, every of the three positions in V going all the way in which again to our authentic sentence “<begin> canine run” has solely been operated on independently. This multiplication blends in info from different positions for the primary time.
Going again to the multi-head consideration diagram, we will see that the concat places the output of every head again collectively so every place is now represented by a vector of size 8. Discover that the 1.8 and the -1.1 within the tensor after concat however earlier than linear match the 1.8 and -1.1 from the primary two parts within the vector for the primary place of the primary head within the first merchandise within the batch from the output of the scaled dot-product consideration proven above. (The following two numbers match too however they’re hidden by the ellipses.)
Now let’s zoom again out to the entire encoder:
At first I believed I might wish to hint the feed ahead block intimately. It’s referred to as a “position-wise feed-forward community” within the paper and I believed that meant it’d deliver info from one place to positions to the suitable of it. Nevertheless, it’s not that. “Place-wise” signifies that it operates independently on every place. It does a linear remodel on every place from 8 parts to 32, does ReLU (max of 0 and quantity), then does one other linear remodel to get again to eight. (That’s in our small instance. Within the base mannequin within the paper it goes from 512 to 2048 after which again to 512. There are a number of parameters right here and doubtless that is the place a number of the training occurs!) The output of the feed ahead is again to (2,3,8).
Getting away from our toy mannequin for a second, right here’s how the encoder appears to be like within the base mannequin within the paper. It’s very good that the enter and output dimensions match!
Now let’s zoom out all the way in which so we will take a look at the decoder.
We don’t have to hint a lot of the decoder aspect as a result of it’s similar to what we simply checked out on the encoder aspect. Nevertheless, the elements I labeled A and B are totally different. A is totally different as a result of we do masked multi-head consideration. This should be the place the magic occurs to not “cheat” whereas coaching. B we’ll come again to later. However first let’s conceal the inner particulars and bear in mind the massive image of what we wish to come out of the decoder.
And simply to actually drive residence this level, suppose our English sentence is “she pet the canine” and our translated Pig Latin sentence is “eshay etpay ethay ogday”. If the mannequin has “eshay etpay ethay” and is attempting to give you the subsequent phrase, “ogday” and “atcay” are each excessive chance selections. Given the context of the complete English sentence of “she pet the canine,” it actually ought to be capable to select “ogday.” Nevertheless, if the mannequin may see the “ogday” throughout coaching, it wouldn’t have to discover ways to predict utilizing the context, it could simply study to repeat.
Let’s see how the masking does this. We are able to skip forward a bit as a result of the primary a part of A works precisely the identical as earlier than the place it applies linear transforms and splits issues up into heads. The one distinction is the scale coming into the scaled dot-product consideration half are (2,2,2,4) as a substitute of (2,2,3,4) as a result of our authentic enter sequence is of size two. Right here’s the scaled dot-product consideration half. As we did on the encoder aspect, we’re taking a look at solely the primary merchandise within the batch and the primary head.
This time we’ve a masks. Let’s take a look at the ultimate matrix multiplication between the output of the softmax and V:
Now we’re prepared to take a look at B, the second multi-head consideration within the decoder. In contrast to the opposite two multi-head consideration blocks, we’re not feeding in three equivalent tensors, so we want to consider what’s V, what’s Okay and what’s Q. I labeled the inputs in pink. We are able to see that V and Okay come from the output of the encoder and have dimension (2,3,8). Q has dimension (2,2,8).
As earlier than, we skip forward to the scaled dot-product consideration half. It is sensible, however can be complicated, that V and Okay have dimensions (2,2,3,4) — two objects within the batch, two heads, three positions, vectors of size 4, and Q has dimension (2,2,2,4).
Despite the fact that we’re “studying from” the encoder output the place the “sequence” size is three, by some means all of the matrix math works out and we find yourself with our desired dimension (2,2,2,4). Let’s take a look at the ultimate matrix multiplication:
The outputs of every multi-head consideration block get added collectively. Let’s skip forward to see the output from the decoder and turning that into predictions:
The linear remodel takes us from (2,2,8) to (2,2,5). Take into consideration that as reversing the embedding, besides that as a substitute of going from a vector of size 8 to the integer identifier for a single token, we go to a chance distribution over our vocabulary of 5 tokens. The numbers in our tiny instance make that appear a bit humorous. Within the paper, it’s extra like going from a vector of measurement 512 to a vocabulary of 37,000 once they did English to German.
In a second we’ll calculate the loss. First, although, even at a look, you will get a really feel for the way the mannequin is doing.
It received one token proper. No shock as a result of that is our first coaching batch and it’s all simply random. One good factor about this diagram is it makes clear that this can be a multi-class classification downside. The lessons are the vocabulary (5 lessons on this case) and, that is what I used to be confused about earlier than, we make (and rating) one prediction per token within the translated sentence, NOT one prediction per sentence. Let’s do the precise loss calculation.
If, for instance, the -3.2 grew to become a -2.2, our loss would lower to five.7, transferring within the desired course, as a result of we would like the mannequin to study that the proper prediction for that first token is 4.
The diagram above leaves out label smoothing. Within the precise paper, the loss calculation smooths labels and makes use of KL Divergence loss. I believe that works out to be the identical or simialr to cross entropy when there is no such thing as a smoothing. Right here’s the identical diagram as above however with label smoothing.
Let’s additionally take a fast take a look at the variety of parameters being realized within the encoder and decoder:
As a sanity verify, the feed ahead block in our toy mannequin has a linear transformation from 8 to 32 and again to eight (as defined above) in order that’s 8 * 32 (weights) + 32 (bias) + 32 * 8 (weights) + 8 (bias) = 52. Needless to say within the base mannequin within the paper, the place d-model is 512 and d-ff is 2048 and there are 6 encoders and 6 decoders there might be many extra parameters.
Now let’s see how we put supply language textual content in and get translated textual content out. I’m nonetheless utilizing a toy mannequin right here educated to “translate” by coping tokens, however as a substitute of the instance above, this one makes use of a vocabulary of measurement 11 and d-model is 512. (Above we had vocabulary of measurement 5 and d-model was 8.)
First let’s do a translation. Then we’ll see the way it works.
The first step is to feed the supply sentence into the encoder and maintain onto its output, which on this case is a tensor with dimensions (1, 10, 512).
Step two is to feed the primary token of the output into the decoder and predict the second token. We all know the primary token as a result of it’s all the time <begin> = 1.
Within the paper, they use beam search with a beam measurement of 4, which implies we might take into account the 4 highest chance tokens at this level. To maintain issues easy I’m going to as a substitute use grasping search. You may consider that as a beam search with a beam measurement of 1. So, studying off from the highest of the diagram, the best chance token is quantity 5. (The outputs above are logs of chances. The very best chance remains to be the best quantity. On this case that’s -0.0 which is definitely -0.004 however I’m solely exhibiting one decimal place. The mannequin is absolutely assured that 5 is appropriate! exp(-0.004) = 99.6%)
Now we feed [1,5] into the decoder. (If we had been doing beam search with a beam measurement of two, we may as a substitute feed in a batch containing [1,5] and [1,4] which is the subsequent most certainly.)
Now we feed [1,5,4]:
And get out 3. And so forth till we get a token that signifies the top of the sentence (not current in our instance vocabulary) or hit a most size.
Now I can largely reply my authentic questions.
Sure, kind of.
Every merchandise corresponds to at least one translated sentence pair.
- The “x” of the merchandise has two elements. The primary half is all of the tokens of the supply sentence. The second half is all tokens of the goal sentence aside from the final one.
- The “y” (label) of the merchandise is all tokens of the goal sentence aside from the primary one. Because the first token for supply and goal is all the time <begin>, we’re not losing or shedding any coaching knowledge.
What’s a bit refined is that if this had been a classification process the place say the mannequin needed to take a picture and output a category (home, automobile, rabbit, and many others.), we might consider every merchandise within the batch as contributing one “classification” to the loss calculation. Right here, nonetheless, every merchandise within the batch will contribute (number_of_tokens_in_target_sentence — 1) “classifications” to the loss calculation.
You feed the output so the mannequin can study to foretell the interpretation based mostly each on the that means of the supply sentence and the phrases translated thus far. Though numerous issues are occurring within the mannequin, the one time info strikes between positions is through the consideration steps. Though we do feed the translated sentence into the decoder, the primary consideration calculation makes use of a masks to zero out all info from positions past the one we’re predicting.
I in all probability ought to have requested what precisely is consideration, as a result of that’s the extra central idea. Multi-head consideration means slicing the vectors up into teams, doing consideration on the teams, after which placing the teams again collectively. For instance, if the vectors have measurement 512 and there are 8 heads, consideration might be completed independently on 8 teams every containing a full batch of the complete positions, every place having a vector of measurement 64. For those who squint, you may see how every head may find yourself studying to present consideration to sure linked ideas as within the well-known visualizations exhibiting how a head will study what phrase a pronoun references.
Proper. We’re not translating a full sentence in a single go and calculating total sentence similarity or one thing like that. Loss is calculated similar to in different multi-class classification issues. The lessons are the tokens in our vocabulary. The trick is we’re independently predicting a category for each token within the goal sentence utilizing solely the knowledge we must always have at that time. The labels are the precise tokens from our goal sentence. Utilizing the predictions and labels we calculate loss utilizing cross entropy. (In actuality we “easy” our labels to account for the truth that they’re notabsolute, a synonym may typically work equally effectively.)
You may’t feed one thing in and have the mannequin spit out the interpretation in a single analysis. You might want to use the mannequin a number of instances. You first feed the supply sentence into the encoder a part of the mannequin and get an encoded model of the sentence that represents its that means in some summary, deep means. Then you definately feed that encoded info and the beginning token <begin> into the decoder a part of the mannequin. That permits you to predict the second token within the goal sentence. Then you definately feed within the <begin> and second token to foretell the third. You repeat this till you will have a full translated sentence. (In actuality, although, you take into account a number of excessive chance tokens for every place, feed a number of candidate sequences in every time, and choose the ultimate translated sentence based mostly on complete chance and a size penalty.)
I’m guessing three causes. 1) To point out that the second multi-head consideration block within the decoder will get a few of its enter from the encoder and a few from the prior block within the decoder. 2) To trace at how the eye algorithm works. 3) To trace that every of the three inputs undergoes its personal unbiased linear transformation earlier than the precise consideration occurs.
It’s lovely! I in all probability wouldn’t assume that if it weren’t so extremely helpful. I now get the sensation individuals should have had once they first noticed this factor working. This elegant and trainable mannequin expressible in little or no code realized the right way to translate human languages and beat out sophisticated machine translations methods constructed over a long time. It’s superb and intelligent and unbelievable. You may see how the subsequent step was to say, neglect about translated sentence pairs, let’s use this system on each little bit of textual content on the web — and LLMs had been born!
(I wager have some errors above. Please LMK.)
Until in any other case famous, all photographs are by writer, or include annotations by the writer on figures from Attention Is All You Need.





