Monitor, allocate, and handle your generative AI price and utilization with Amazon Bedrock
As enterprises more and more embrace generative AI , they face challenges in managing the related prices. With demand for generative AI functions surging throughout initiatives and a number of strains of enterprise, precisely allocating and monitoring spend turns into extra advanced. Organizations must prioritize their generative AI spending primarily based on enterprise impression and criticality whereas sustaining price transparency throughout buyer and consumer segments. This visibility is crucial for setting correct pricing for generative AI choices, implementing chargebacks, and establishing usage-based billing fashions.
And not using a scalable method to controlling prices, organizations danger unbudgeted utilization and value overruns. Guide spend monitoring and periodic utilization restrict changes are inefficient and susceptible to human error, resulting in potential overspending. Though tagging is supported on a variety of Amazon Bedrock resources—together with provisioned fashions, customized fashions, brokers and agent aliases, mannequin evaluations, prompts, immediate flows, data bases, batch inference jobs, customized mannequin jobs, and mannequin duplication jobs—there was beforehand no functionality for tagging on-demand basis fashions. This limitation has added complexity to price administration for generative AI initiatives.
To handle these challenges, Amazon Bedrock has launched a functionality that group can use to tag on-demand fashions and monitor related prices. Organizations can now label all Amazon Bedrock fashions with AWS cost allocation tags, aligning utilization to particular organizational taxonomies equivalent to price facilities, enterprise items, and functions. To handle their generative AI spend judiciously, organizations can use providers like AWS Budgets to set tag-based budgets and alarms to watch utilization, and obtain alerts for anomalies or predefined thresholds. This scalable, programmatic method eliminates inefficient handbook processes, reduces the danger of extra spending, and ensures that crucial functions obtain precedence. Enhanced visibility and management over AI-related bills permits organizations to maximise their generative AI investments and foster innovation.
Introducing Amazon Bedrock software inference profiles
Amazon Bedrock not too long ago launched cross-region inference, enabling computerized routing of inference requests throughout AWS Areas. This characteristic makes use of system-defined inference profiles (predefined by Amazon Bedrock), which configure totally different mannequin Amazon Useful resource Names (ARNs) from varied Areas and unify them underneath a single mannequin identifier (each mannequin ID and ARN). Whereas this enhances flexibility in mannequin utilization, it doesn’t help attaching customized tags for monitoring, managing, and controlling prices throughout workloads and tenants.
To bridge this hole, Amazon Bedrock now introduces application inference profiles, a brand new functionality that permits organizations to use customized price allocation tags to trace, handle, and management their Amazon Bedrock on-demand mannequin prices and utilization. This functionality permits organizations to create customized inference profiles for Bedrock base basis fashions, including metadata particular to tenants, thereby streamlining useful resource allocation and value monitoring throughout diverse AI functions.
Creating software inference profiles
Utility inference profiles enable customers to outline personalized settings for inference requests and useful resource administration. These profiles will be created in two methods:
- Single mannequin ARN configuration: Straight create an software inference profile utilizing a single on-demand base mannequin ARN, permitting fast setup with a selected mannequin.
- Copy from system-defined inference profile: Copy an present system-defined inference profile to create an software inference profile, which is able to inherit configurations equivalent to cross-Area inference capabilities for enhanced scalability and resilience.
The appliance inference profile ARN has the next format, the place the inference profile ID part is a novel 12-digit alphanumeric string generated by Amazon Bedrock upon profile creation.
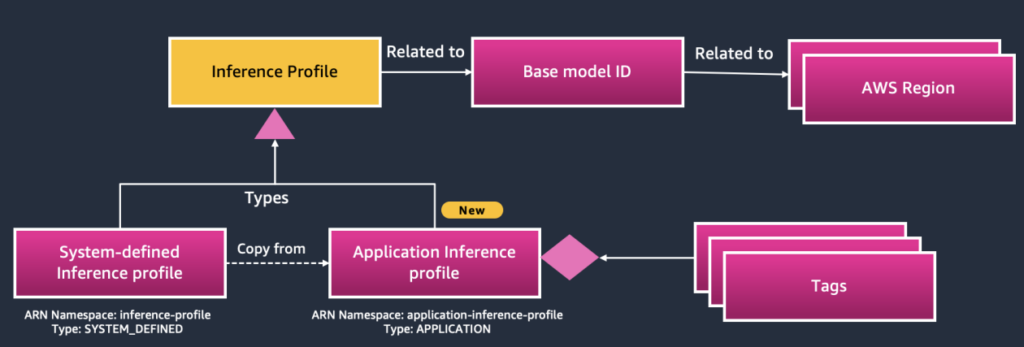
System-defined in comparison with software inference profiles
The first distinction between system-defined and software inference profiles lies of their kind attribute and useful resource specs inside the ARN namespace:
- System-defined inference profiles: These have a kind attribute of
SYSTEM_DEFINEDand make the most of theinference-profileuseful resource kind. They’re designed to help cross-Area and multi-model capabilities however are managed centrally by AWS. - Utility inference profiles: These profiles have a
kindattribute ofAPPLICATIONand use theapplication-inference-profileuseful resource kind. They’re user-defined, offering granular management and suppleness over mannequin configurations and permitting organizations to tailor insurance policies with attribute-based entry management (ABAC) utilizing AWS Identification and Entry Administration (IAM). This permits extra exact IAM coverage authoring to handle Amazon Bedrock entry extra securely and effectively.
These variations are vital when integrating with Amazon API Gateway or different API shoppers to assist guarantee right mannequin invocation, useful resource allocation, and workload prioritization. Organizations can apply personalized insurance policies primarily based on profile kind, enhancing management and safety for distributed AI workloads. Each fashions are proven within the following determine.

Establishing software inference profiles for price administration
Think about an insurance coverage supplier embarking on a journey to reinforce buyer expertise by way of generative AI. The corporate identifies alternatives to automate claims processing, present personalised coverage suggestions, and enhance danger evaluation for shoppers throughout varied areas. Nevertheless, to understand this imaginative and prescient, the group should undertake a sturdy framework for successfully managing their generative AI workloads.
The journey begins with the insurance coverage supplier creating software inference profiles which might be tailor-made to their numerous enterprise items. By assigning AWS price allocation tags, the group can successfully monitor and observe their Bedrock spend patterns. For instance, the claims processing workforce established an software inference profile with tags equivalent to dept:claims, workforce:automation, and app:claims_chatbot. This tagging construction categorizes prices and permits evaluation of utilization in opposition to budgets.
Customers can handle and use software inference profiles utilizing Bedrock APIs or the boto3 SDK:
- CreateInferenceProfile: Initiates a brand new inference profile, permitting customers to configure the parameters for the profile.
- GetInferenceProfile: Retrieves the small print of a selected inference profile, together with its configuration and present standing.
- ListInferenceProfiles: Lists all obtainable inference profiles inside the consumer’s account, offering an summary of the profiles which have been created.
- TagResource: Permits customers to connect tags to particular Bedrock sources, together with software inference profiles, for higher group and value monitoring.
- ListTagsForResource: Fetches the tags related to a selected Bedrock useful resource, serving to customers perceive how their sources are categorized.
- UntagResource: Removes specified tags from a useful resource, permitting for administration of useful resource group.
- Invoke fashions with software inference profiles:
-
- Converse API: Invokes the mannequin utilizing a specified inference profile for conversational interactions.
- ConverseStream API: Much like the Converse API however helps streaming responses for real-time interactions.
- InvokeModel API: Invokes the mannequin with a specified inference profile for normal use circumstances.
- InvokeModelWithResponseStream API: Invokes the mannequin and streams the response, helpful for dealing with giant knowledge outputs or long-running processes.
Be aware that software inference profile APIs can’t be accessed by way of the AWS Administration Console.
Invoke mannequin with software inference profile utilizing Converse API
The next instance demonstrates the way to create an software inference profile after which invoke the Converse API to interact in a dialog utilizing that profile –
Tagging, useful resource administration, and value administration with software inference profiles
Tagging inside software inference profiles permits organizations to allocate prices with particular generative AI initiatives, guaranteeing exact expense monitoring. Utility inference profiles allow organizations to use price allocation tags at creation and help further tagging by way of the prevailing TagResource and UnTagResource APIs, which permit metadata affiliation with varied AWS sources. Customized tags equivalent to project_id, cost_center, model_version, and surroundings assist categorize sources, bettering price transparency and permitting groups to watch spend and utilization in opposition to budgets.
Visualize price and utilization with software inference profiles and value allocation tags
Leveraging price allocation tags with instruments like AWS Budgets, AWS Cost Anomaly Detection, AWS Cost Explorer, AWS Cost and Usage Reports (CUR), and Amazon CloudWatch gives organizations insights into spending developments, serving to detect and deal with price spikes early to remain inside funds.
With AWS Budgets, group can set tag-based thresholds and obtain alerts as spending method funds limits, providing a proactive method to sustaining management over AI useful resource prices and rapidly addressing any surprising surges. For instance, a $10,000 monthly funds may very well be utilized on a selected chatbot software for the Help Group within the Gross sales Division by making use of the next tags to the applying inference profile: dept:gross sales, workforce:help, and app:chat_app. AWS Price Anomaly Detection may also monitor tagged sources for uncommon spending patterns, making it simpler to operationalize price allocation tags by routinely figuring out and flagging irregular prices.
The next AWS Budgets console screenshot illustrates an exceeded funds threshold:

For deeper evaluation, AWS Price Explorer and CUR allow organizations to investigate tagged sources day by day, weekly, and month-to-month, supporting knowledgeable choices on useful resource allocation and value optimization. By visualizing price and utilization primarily based on metadata attributes, equivalent to tag key/worth and ARN, organizations achieve an actionable, granular view of their spending.
The next AWS Price Explorer console screenshot illustrates a price and utilization graph filtered by tag key and worth:

The next AWS Price Explorer console screenshot illustrates a price and utilization graph filtered by Bedrock software inference profile ARN:

Organizations may also use Amazon CloudWatch to watch runtime metrics for Bedrock functions, offering further insights into efficiency and value administration. Metrics will be graphed by software inference profile, and groups can set alarms primarily based on thresholds for tagged sources. Notifications and automatic responses triggered by these alarms allow real-time administration of price and useful resource utilization, stopping funds overruns and sustaining monetary stability for generate AI workloads.
The next Amazon CloudWatch console screenshot highlights Bedrock runtime metrics filtered by Bedrock software inference profile ARN:

The next Amazon CloudWatch console screenshot highlights an invocation restrict alarm filtered by Bedrock software inference profile ARN:

By way of the mixed use of tagging, budgeting, anomaly detection, and detailed price evaluation, organizations can successfully handle their AI investments. By leveraging these AWS instruments, groups can keep a transparent view of spending patterns, enabling extra knowledgeable decision-making and maximizing the worth of their generative AI initiatives whereas guaranteeing crucial functions stay inside funds.
Retrieving software inference profile ARN primarily based on the tags for Mannequin invocation
Organizations typically use a generative AI gateway or giant language mannequin proxy when calling Amazon Bedrock APIs, together with mannequin inference calls. With the introduction of software inference profiles, organizations must retrieve the inference profile ARN to invoke mannequin inference for on-demand basis fashions. There are two major approaches to acquire the suitable inference profile ARN.
- Static configuration method: This technique entails sustaining a static configuration file within the AWS Systems Manager Parameter Store or AWS Secrets Manager that maps tenant/workload keys to their corresponding software inference profile ARNs. Whereas this method gives simplicity in implementation, it has vital limitations. Because the variety of inference profiles scales from tens to a whole bunch and even 1000’s, managing and updating this configuration file turns into more and more cumbersome. The static nature of this technique requires handbook updates at any time when adjustments happen, which may result in inconsistencies and elevated upkeep overhead, particularly in large-scale deployments the place organizations must dynamically retrieve the right inference profile primarily based on tags.
- Dynamic retrieval utilizing the Useful resource Teams API: The second, extra sturdy method leverages the AWS Useful resource Teams GetResources API to dynamically retrieve software inference profile ARNs primarily based on useful resource and tag filters. This technique permits for versatile querying utilizing varied tag keys equivalent to tenant ID, challenge ID, division ID, workload ID, mannequin ID, and area. The first benefit of this method is its scalability and dynamic nature, enabling real-time retrieval of software inference profile ARNs primarily based on present tag configurations.
Nevertheless, there are concerns to remember. The GetResources API has throttling limits, necessitating the implementation of a caching mechanism. Organizations ought to keep a cache with a Time-To-Stay (TTL) primarily based on the API’s output to optimize efficiency and cut back API calls. Moreover, implementing thread security is essential to assist be certain that organizations at all times learn essentially the most up-to-date inference profile ARNs when the cache is being refreshed primarily based on the TTL.
As illustrated within the following diagram, this dynamic method entails a consumer making a request to the Useful resource Teams service with particular useful resource kind and tag filters. The service returns the corresponding software inference profile ARN, which is then cached for a set interval. The consumer can then use this ARN to invoke the Bedrock mannequin by way of the InvokeModel or Converse API.
By adopting this dynamic retrieval technique, organizations can create a extra versatile and scalable system for managing software inference profiles, permitting for extra easy adaptation to altering necessities and progress within the variety of profiles.

The structure within the previous determine illustrates two strategies for dynamically retrieving inference profile ARNs primarily based on tags. Let’s describe each approaches with their professionals and cons:
- Bedrock consumer sustaining the cache with TTL: This technique entails the consumer instantly querying the AWS
ResourceGroupsservice utilizing theGetResourcesAPI primarily based on useful resource kind and tag filters. The consumer caches the retrieved keys in a client-maintained cache with a TTL. The consumer is liable for refreshing the cache by calling theGetResourcesAPI within the thread protected manner. - Lambda-based Technique: This method makes use of AWS Lambda as an middleman between the calling consumer and the
ResourceGroupsAPI. This technique employs Lambda Extensions core with an in-memory cache, probably decreasing the variety of API calls toResourceGroups. It additionally interacts with Parameter Retailer, which can be utilized for configuration administration or storing cached knowledge persistently.
Each strategies use related filtering standards (resource-type-filter and tag-filters) to question the ResourceGroup API, permitting for exact retrieval of inference profile ARNs primarily based on attributes equivalent to tenant, mannequin, and Area. The selection between these strategies will depend on components such because the anticipated request quantity, desired latency, price concerns, and the necessity for added processing or safety measures. The Lambda-based method gives extra flexibility and optimization potential, whereas the direct API technique is less complicated to implement and keep.
Overview of Amazon Bedrock sources tagging capabilities
The tagging capabilities of Amazon Bedrock have advanced considerably, offering a complete framework for useful resource administration throughout multi-account AWS Control Tower setups. This evolution permits organizations to handle sources throughout improvement, staging, and manufacturing environments, serving to organizations observe, handle, and allocate prices for his or her AI/ML workloads.
At its core, the Amazon Bedrock useful resource tagging system spans a number of operational parts. Organizations can successfully tag their batch inference jobs, brokers, customized mannequin jobs, data bases, prompts, and immediate flows. This foundational stage of tagging helps granular management over operational sources, enabling exact monitoring and administration of various workload parts. The mannequin administration side of Amazon Bedrock introduces one other layer of tagging capabilities, encompassing each customized and base fashions, and distinguishes between provisioned and on-demand fashions, every with its personal tagging necessities and capabilities.
With the introduction of software inference profiles, organizations can now handle and observe their on-demand Bedrock base basis fashions. As a result of groups can create software inference profiles derived from system-defined inference profiles, they will configure extra exact useful resource monitoring and value allocation on the software stage. This functionality is especially priceless for organizations which might be working a number of AI functions throughout totally different environments, as a result of it gives clear visibility into useful resource utilization and prices at a granular stage.
The next diagram visualizes the multi-account construction and demonstrates how these tagging capabilities will be carried out throughout totally different AWS accounts.

Conclusion
On this publish we launched the most recent characteristic from Amazon Bedrock, software inference profiles. We explored the way it operates and mentioned key concerns. The code pattern for this characteristic is accessible on this GitHub repository. This new functionality permits organizations to tag, allocate, and observe on-demand mannequin inference workloads and spending throughout their operations. Organizations can label all Amazon Bedrock fashions utilizing tags and monitoring utilization based on their particular organizational taxonomy—equivalent to tenants, workloads, price facilities, enterprise items, groups, and functions. This characteristic is now usually obtainable in all AWS Areas the place Amazon Bedrock is obtainable.
In regards to the authors
 Kyle T. Blocksom is a Sr. Options Architect with AWS primarily based in Southern California. Kyle’s ardour is to convey individuals collectively and leverage know-how to ship options that clients love. Outdoors of labor, he enjoys browsing, consuming, wrestling together with his canine, and spoiling his niece and nephew.
Kyle T. Blocksom is a Sr. Options Architect with AWS primarily based in Southern California. Kyle’s ardour is to convey individuals collectively and leverage know-how to ship options that clients love. Outdoors of labor, he enjoys browsing, consuming, wrestling together with his canine, and spoiling his niece and nephew.
 Dhawal Patel is a Principal Machine Studying Architect at AWS. He has labored with organizations starting from giant enterprises to mid-sized startups on issues associated to distributed computing, and Synthetic Intelligence. He focuses on Deep studying together with NLP and Laptop Imaginative and prescient domains. He helps clients obtain excessive efficiency mannequin inference on SageMaker.
Dhawal Patel is a Principal Machine Studying Architect at AWS. He has labored with organizations starting from giant enterprises to mid-sized startups on issues associated to distributed computing, and Synthetic Intelligence. He focuses on Deep studying together with NLP and Laptop Imaginative and prescient domains. He helps clients obtain excessive efficiency mannequin inference on SageMaker.





