Self-Knowledge Distilled High-quality-Tuning: A Resolution for Pruning and Supervised High-quality-tuning Challenges in LLMs

Massive language fashions (LLMs) like GPT-4, Gemini, and Llama 3 have revolutionized pure language processing by means of in depth pre-training and supervised fine-tuning (SFT). Nonetheless, these fashions include excessive computational prices for coaching and inference. Structured pruning has emerged as a promising methodology to enhance LLM effectivity by selectively eradicating much less crucial parts. Regardless of its potential, depth-wise structured pruning faces challenges like accuracy degradation, particularly in duties that require multi-step reasoning. Pruning can disrupt data movement between layers, resulting in poor mannequin high quality even after SFT. Additionally, fine-tuning can enhance catastrophic forgetting, additional degrading mannequin high quality. So, growing efficient methods to mitigate these challenges throughout pruning is essential.
Present makes an attempt to deal with LLM effectivity challenges embody pruning for mannequin compression, distillation, and strategies to mitigate catastrophic forgetting. Pruning goals to cut back mannequin complexity however can result in inefficient acceleration or degraded mannequin high quality. Data Distillation (KD) permits smaller fashions to study from bigger ones, with latest purposes in pre-training and fine-tuning. Nonetheless, these methods typically lead to catastrophic forgetting, the place fashions lose beforehand discovered capabilities. In catastrophic forgetting, regularization methods like Elastic Weight Consolidation and architecture-based strategies have been used to resolve this problem, however in addition they have limitations. Nonetheless, challenges persist in sustaining mannequin high quality whereas bettering effectivity, particularly for advanced reasoning duties.
A group from Cerebras Techniques has proposed self-data distilled fine-tuning, a way to deal with the challenges related to pruning and SFT in giant language fashions. This strategy makes use of the unique, unpruned mannequin to generate a distilled dataset that preserves semantic richness and mitigates catastrophic forgetting by sustaining alignment with the bottom mannequin’s information. This methodology exhibits important enchancment over normal SFT, with a rise in common accuracy by as much as 8% on the HuggingFace OpenLLM Leaderboard v1. This strategy scales successfully throughout datasets, with high quality enhancements correlating positively with dataset dimension.
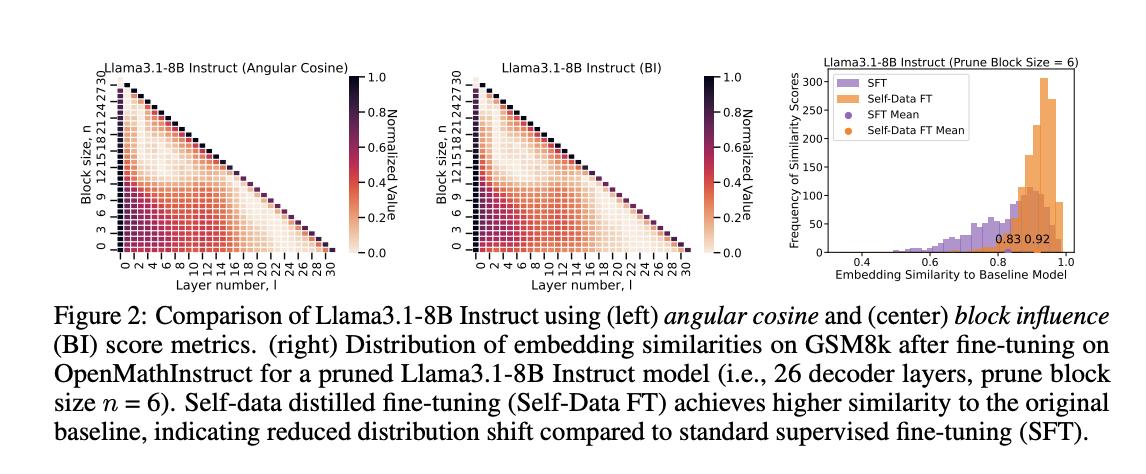
The methodology entails evaluating layer significance metrics, pruning block sizes, and fine-tuning methods. Block Significance (BI) and angular cosine metrics are in comparison with decide layer redundancy, discovering comparable outcomes throughout block sizes. The proposed methodology makes use of LoRA fine-tuning on normal and self-distilled datasets, specializing in reasoning-heavy duties. Fashions are evaluated on ARC-C, GSM8k, and MMLU duties utilizing LM-eval-harness. To cut back catastrophic forgetting, the researchers in contrast sentence embeddings of fashions fine-tuned on supervised and self-data distilled datasets. The self-data fine-tuned mannequin preserves the unique mannequin’s discovered representations in comparison with SFT.
The Llama3.1-8B Instruct fashions pruned at numerous block sizes are evaluated utilizing three fine-tuning methods: no fine-tuning, SFT, and self-data distillation. Pruned fashions with out fine-tuning present a considerable loss in accuracy, highlighting the necessity for post-pruning adaptation. Whereas SFT improved high quality, attaining a mean restoration of 81.66% at block dimension 6, it struggled with reasoning-heavy duties. Self-data distillation considerably enhanced high quality restoration, reaching 91.24% at block dimension 6, with nice enhancements in GSM8k accuracy. Furthermore, the self-data distillation is improved utilizing mannequin merging known as Spherical Linear Interpolation (SLERP). At block dimension 6, the merged mannequin achieved a 93.30% restoration, outperforming the 91.24% restoration of the OpenMathInstruct mannequin alone.
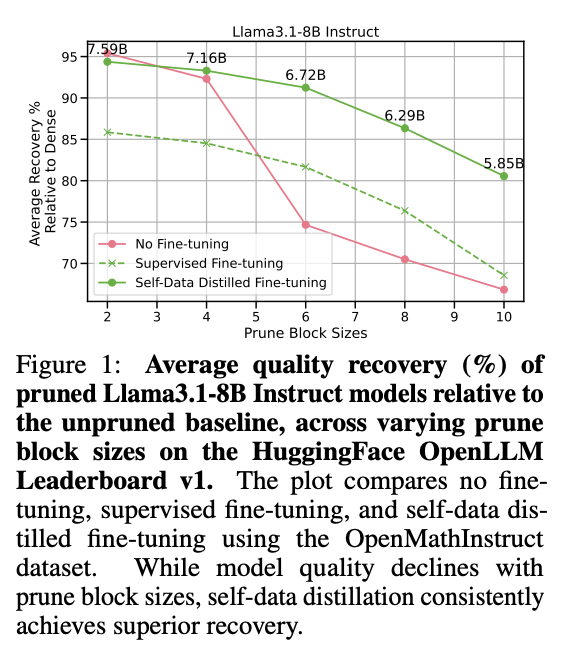
In conclusion, the group launched self-data distilled fine-tuning, an efficient methodology to counteract high quality degradation in pruned Llama3.1-8B Instruct fashions. This strategy outperforms normal SFT, exhibiting superior accuracy restoration post-pruning throughout numerous duties on the HuggingFace OpenLLM Leaderboard v1. The findings on this paper set up self-data distilled fine-tuning as a crucial software for sustaining excessive mannequin high quality post-pruning, offering an environment friendly answer for large-scale mannequin compression. Future analysis consists of integrating this system with complementary compression strategies, adopting fine-tuning methods that leverage dynamically generated datasets or multi-modal inputs, and increasing these methodologies to next-generation LLM architectures.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our newsletter.. Don’t Overlook to affix our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)

Sajjad Ansari is a last yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a deal with understanding the impression of AI applied sciences and their real-world implications. He goals to articulate advanced AI ideas in a transparent and accessible method.






