Newest Improvements in Suggestion Techniques with LLMs


Picture by Editor | Midjourney
How LLMs are Altering the Suggestion Trade
Know-how is quickly evolving with the emergence of enormous language fashions (LLMs), notably remodeling advice techniques. Suggestion techniques affect quite a lot of person experiences from the subsequent tune Spotify performs to the posts in your TikTok feed. By anticipating person preferences, advice techniques improve person satisfaction and enhance engagement by maintaining content material related and interesting.
Just lately, advice techniques have been going by way of a step operate development with the emergence of enormous language fashions (LLMs). These fashions are altering each person experiences and rating. Nevertheless, integrating LLMs straight into manufacturing environments poses challenges, primarily as a result of excessive latency points. Due to this, relatively than getting used straight, LLMs are sometimes employed to boost different parts of the system.
On this article, we’ll discover how LLMs are altering advice techniques as we communicate. Let’s first begin with a short overview.
A Temporary Overview of Fashionable Suggestion Techniques
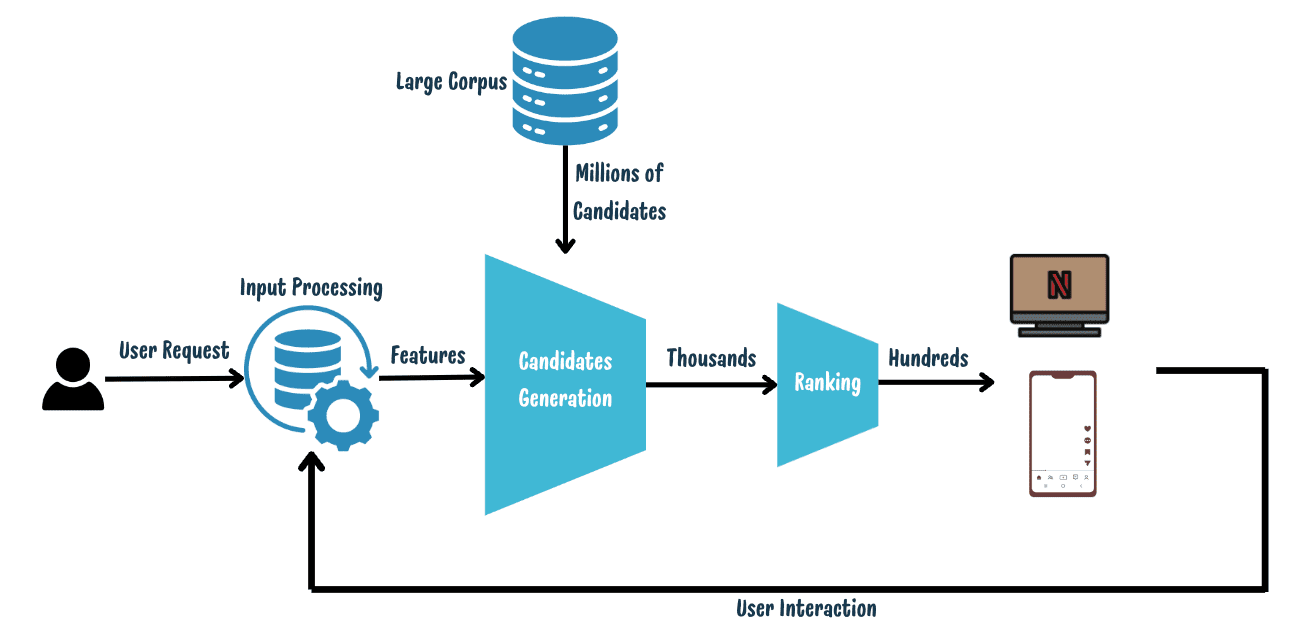
Picture by Writer | A typical fashionable advice system
Fashionable advice techniques usually function in a four-stage loop:
- Enter Processing and Function Era: This stage processes knowledge from person interactions — together with specific indicators like critiques and scores, and implicit indicators similar to clicks — turning them into related options for making suggestions.
- Candidate Era: Upon receiving a person request, the system retrieves an preliminary checklist of potential suggestions, similar to movies and music, from an unlimited corpus. Whereas conventional techniques may use key phrase matching to seek out gadgets that straight correspond to the person’s enter or search phrases, fashionable strategies typically make use of extra subtle algorithms like Embedding-based retrieval.
- Rating of Candidates: Every candidate is scored primarily based on a relevance operate. Predictive fashions, similar to twin-tower neural networks, are used to rework each person and candidate knowledge into embeddings. The relevance is then decided by computing the similarity between these embeddings.
- Consumer Interplay and Information Assortment: The ranked suggestions are introduced to the person, who interacts by clicking or ignoring gadgets. These interactions are then collected to refine and enhance future fashions.
The appliance of enormous language fashions (LLMs) in advice techniques will be divided into two major classes: discriminative and generative.
- Discriminative Circumstances: Conventional LLMs similar to BERT are utilized for classifying or predicting particular outcomes, specializing in categorizing person inputs or predicting person behaviors primarily based on predefined classes.
- Generative Circumstances: More moderen developments focus on fashions like GPT, that are able to producing new content material or solutions in human-readable textual content.
We are going to discover the generative functions the place superior fashions, similar to GPT-4 and LLaMA 3.1, are being employed to boost advice techniques at each stage.
The place to Adapt LLMs in Suggestion Techniques
As advice techniques evolve, the strategic integration of enormous language fashions (LLMs) is turning into more and more essential. This part explores a number of the newest analysis on how LLMs are being tailored at numerous levels of the advice pipeline.
1. Function Era
Function Augmentation
LLMs will be employed to generate particular options for customers or gadgets. For example, contemplate the strategy utilized in a product categorization research (seek advice from the schema described in this paper). The mannequin makes use of structured instruction, which incorporates parts like process description, prompts, enter textual content, candidate labels, output constraints, and the specified output. This structured strategy helps in producing exact options tailor-made to particular advice duties. Few-shot studying and fine-tuning methods can be utilized to adapt giant language fashions to particular duties additional.
- Few-shot Studying: This strategy “trains” a LLM on a brand new process by offering it with just a few examples inside the immediate, leveraging its pre-trained information to shortly adapt.
- High-quality-Tuning: This method includes further coaching of a pre-trained mannequin on a bigger, task-specific dataset to boost its efficiency by adjusting for the brand new process
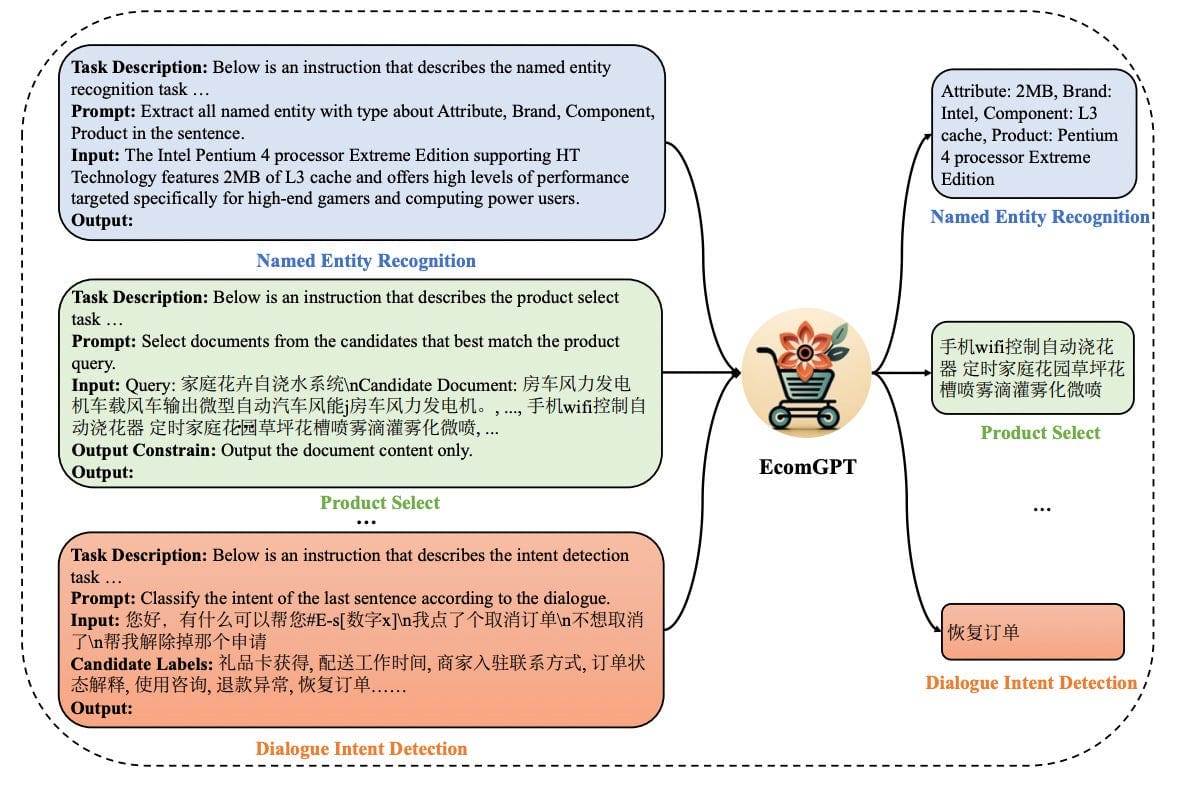
Li et al., 2023: An summary of related characteristic extractions from EcomGPT for various E-commerce duties
Artificial Label Era
Artificial knowledge era includes creating sensible, synthetic knowledge entries for coaching functions, as demonstrated in this study The method includes two major steps:
- Context Setting: This preliminary step establishes a domain-specific context to information the info era. For instance, utilizing a immediate similar to “Think about you’re a film reviewer” helps set the scene for producing knowledge related to film critiques.
- Information Era Immediate: After setting the context, the LLM is given particular directions in regards to the desired output. This contains particulars on the type of textual content (e.g., film evaluation), the sentiment (optimistic or unfavourable), and any constraints like phrase depend or particular terminology. This ensures the artificial knowledge aligns intently with the necessities of the advice system, making them helpful for enhancing its accuracy and effectiveness.
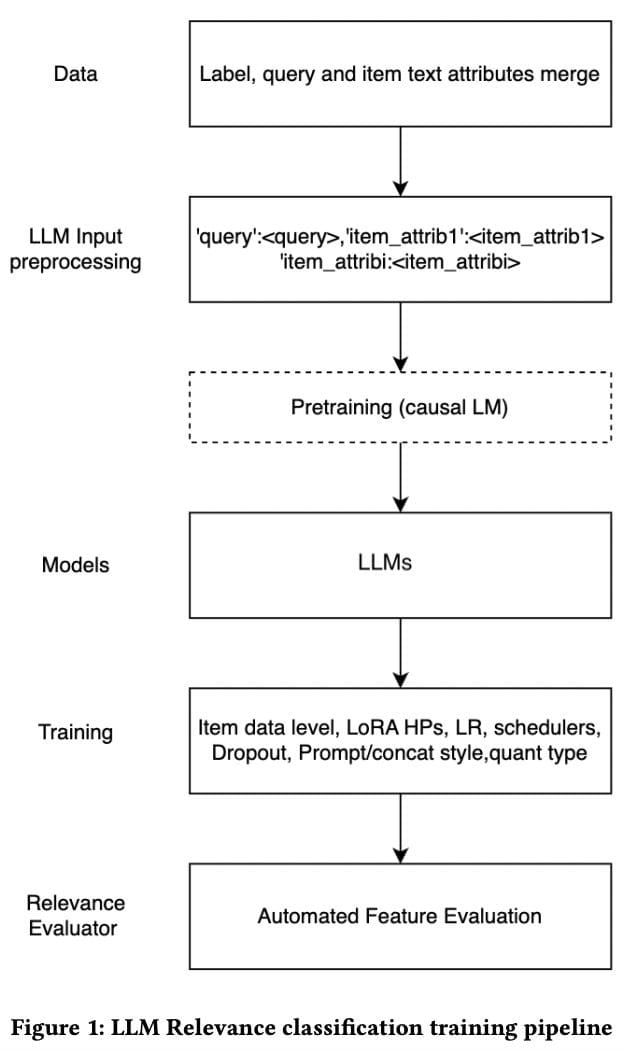
Mehrdad et al., 2024: LLM Relevance classification coaching pipeline
2. Candidates Era
The retrieval is designed to pick a set of potential candidates for the goal person earlier than they are often ranked from a considerable amount of corpus. There are basically two sorts of retrieval mechanisms:
- Bag of Phrases Retrieval: Converts textual content into vectors of phrase frequencies and retrieves paperwork by measuring similarity (e.g., cosine similarity) between these frequency vectors and the person.
- Embedding-Primarily based Retrieval: Transforms textual content into dense semantic embeddings and retrieves paperwork by evaluating the semantic similarity (cosine similarity) between the person’s and paperwork’ embeddings.
LLM Augmented Retrieval
LLM enhances each bag of phrases and embedding-based retrieval by including artificial textual content (basically augmenting person request) to higher symbolize each the person facet and the doc facet embeddings. This was introduced in this study the place every person request question is augmented with related queries to enhance retrieval.
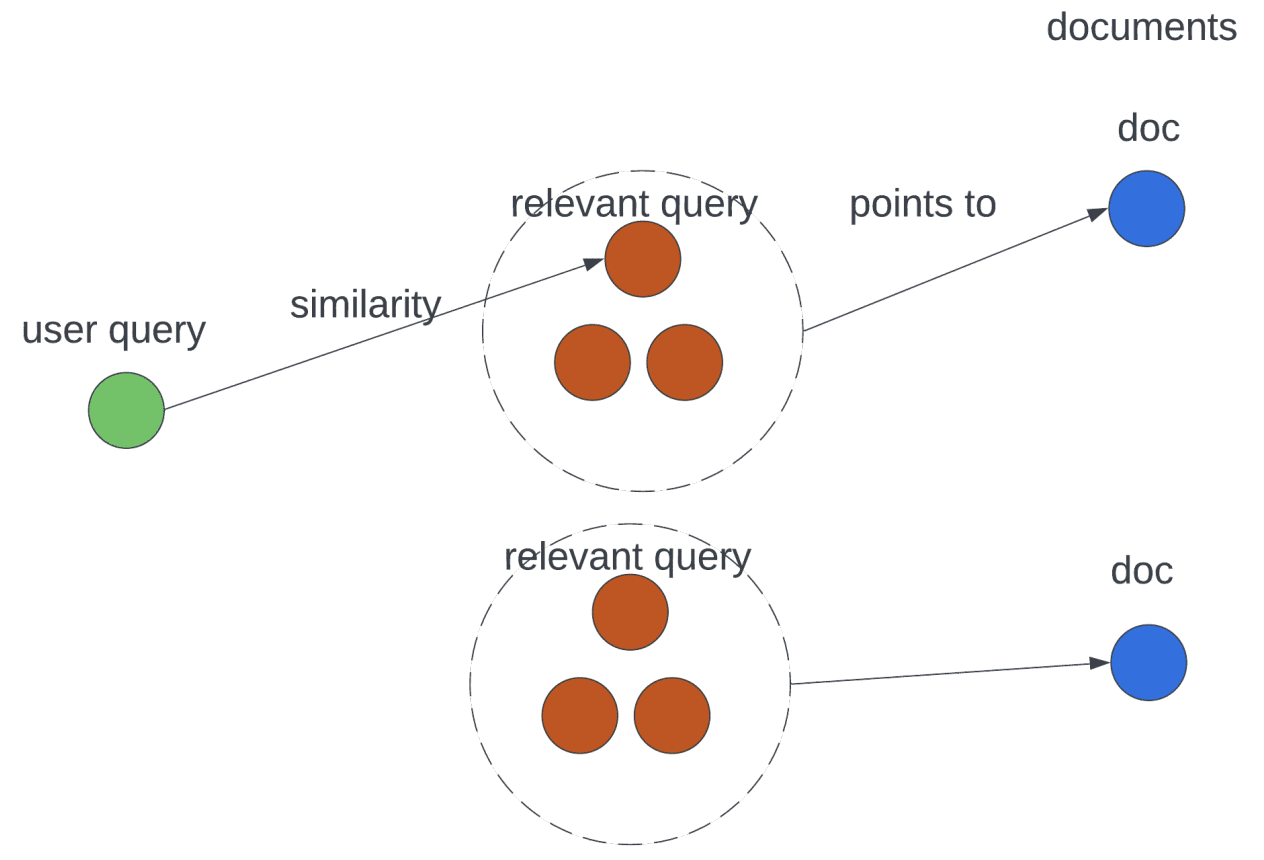
Wu et al., 2024: By artificial related queries, the relevance relationship isn’t solely expressed by the similarity now but additionally expressed by the augmentation steps of the big language fashions
3. Rating
Candidate scoring process
The candidate scoring process includes using a LLM as a pointwise operate which assigns a rating for each goal person u and for each candidate c within the candidate set C. The ultimate ranked checklist of things is generated by sorting these utility scores for every merchandise within the candidate set.
the place
is a listing of ranked candidates.
For candidate scoring duties, three main approaches are getting used:
Method 1: Data Distillation
This methodology employs a dual-model technique the place a scholar mannequin (usually a smaller language mannequin) learns from a dataset generated by a extra complicated trainer mannequin, similar to an LLaMA 3.1, typically enhanced by integrating person attributes. Once more strategies similar to few-shot studying and fine-tuning are used for adapting the LLM to particular area circumstances, permitting the coed mannequin to successfully mimic the trainer’s efficiency whereas being extra environment friendly. This strategy not solely improves mannequin scalability but additionally retains excessive efficiency as a result of solely smaller fashions used for inference, as detailed within the research out there at this link.
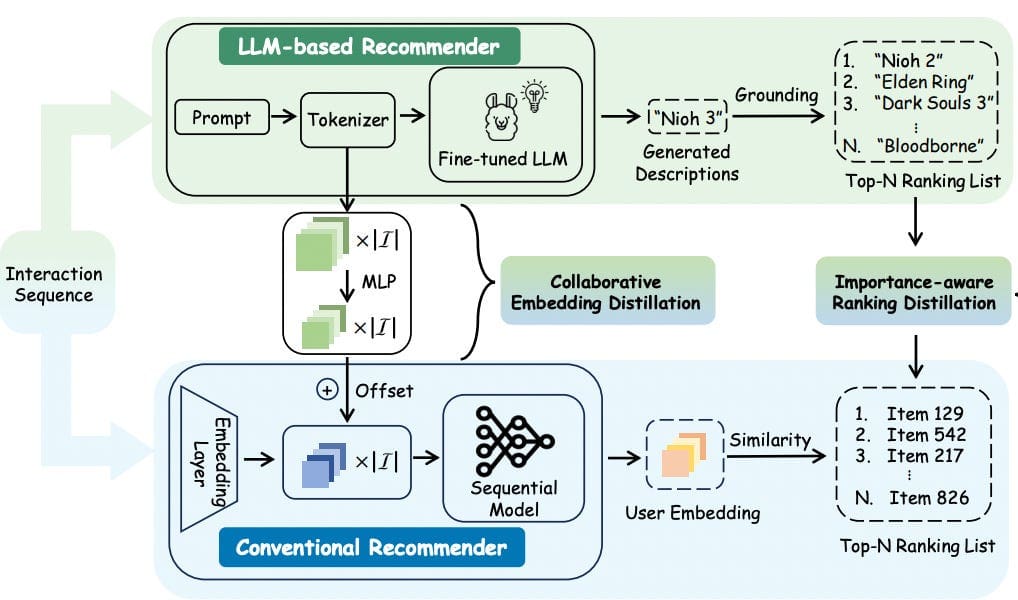
Cui et al., 2024: Illustration of DLLM2Rec that distills the information from the LLM-based recommenders to the traditional recommenders
Method 2: Rating Era
Rating era strategies, as mentioned in this research, contain the LLM producing scores straight from the given prompts, which might then be used to rank gadgets in response to these scores by exposing them by way of caching mechanisms.

Method 3: Rating prediction from LLM
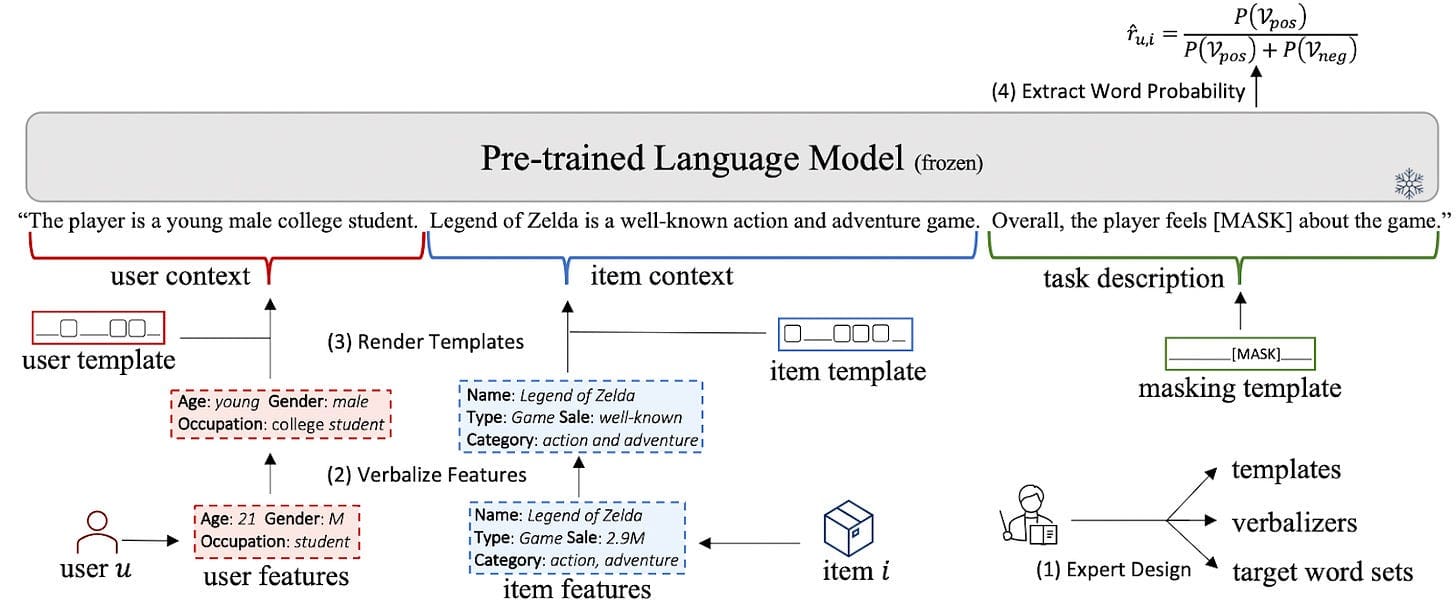
Wu et al., 2023: PromptRec: Prompting PLMs to make personalised suggestions
On this methodology, the candidate scoring process is reworked right into a binary question-answering problem. The method begins with an in depth textual description of the person profile, behaviors, and goal merchandise. The mannequin then solutions a query geared toward figuring out person preferences, producing an estimated rating or chance. To refine this strategy, modifications embody changing the decoder layer of the LLM with a Multi-Layer Perceptron (MLP) for predictions or utilizing a bidimensional softmax operate on the logits of binary solutions like “Sure” or “No” to calculate scores (See this study). This simplifies the complicated scoring process into an easy binary classification drawback.
Candidate Era Activity
In merchandise era duties, a big language mannequin features as a generative mechanism, delivering a closing ranked checklist of things as an alternative of sorting it primarily based on scores. Due to this fact, for each goal person u, and for each candidate c in candidate set C, the ranked checklist
turns into:
This methodology primarily is dependent upon the inherent reasoning abilities of the LLM to evaluate person preferences and generate an appropriately ranked checklist of solutions. That is what was proposed in this study.
This ranked checklist can then be used to cache probably the most steadily occurring customers/requests and replace it with batch processing.

4. Consumer Interplay and Information Assortment
LLMs are evolving the person expertise in advice techniques in a number of important and noticeable methods. Maybe probably the most transformative software is embedding the advice course of straight into conversational interfaces like within the case of conversational engines like google like perplexity. As mentioned in this study, chatbots powered by LLMs which might be fine-tuned on attribute-based conversations , the place the bot asks customers about their preferences earlier than making solutions, symbolize a significant shift in how suggestions are delivered. This methodology leverages LLMs straight, shifting past enhancing current fashions.
It introduces a brand new paradigm the place applied sciences like Retrieval Augmented Era (RAG) play a vital function. Within the context of advice techniques, significantly these built-in into conversational brokers, RAG might help by pulling related and well timed info to make extra knowledgeable solutions primarily based on the person’s present context or question.
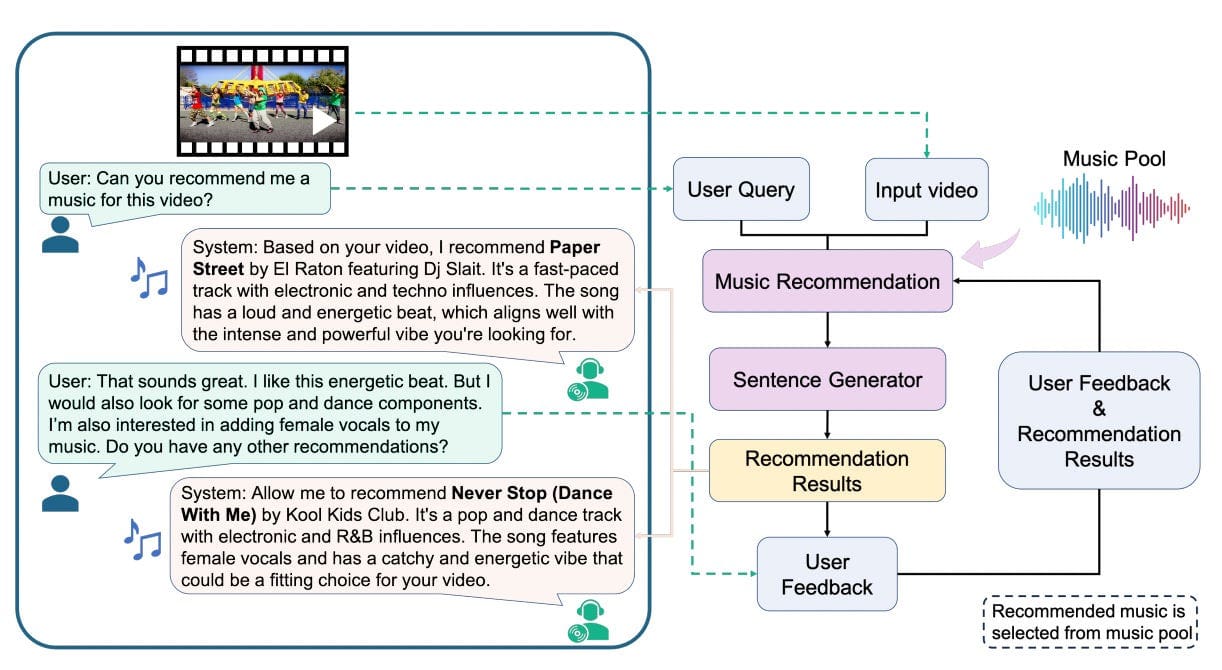
Dong et al., 2024: A conversational music advice system. It options two modules: the Music Suggestion Module, which processes both video enter alone or together with person prompts and previous music solutions, and the Sentence Generator Module, which makes use of these inputs to create pure language music suggestions
Conclusion
All through the most recent research, we’ve seen how LLMs are reshaping advice techniques regardless of challenges like excessive latency that stop them from being the first inference mannequin. Whereas LLMs presently empower backend enhancements in characteristic era and predictive accuracy, ongoing developments like quantization in computational effectivity will ultimately mitigate latency points. This can allow the direct integration of LLMs, dramatically enhancing their responsiveness and ship seamless, intuitive experiences that enhance person expertise.
Acknowledgement
I want to prolong my honest gratitude to Kanwal Mehreen, who offered invaluable suggestions and insights through the peer evaluation technique of this text. Her experience significantly enhanced the standard of the content material, and her solutions have been essential in refining the ultimate model.
References
[1] Wu, Likang, et al. “A survey on giant language fashions for advice.” arXiv preprint arXiv:2305.19860 (2023)
[2] Li, Yangning, et al. “Ecomgpt: Instruction-tuning giant language fashions with chain-of-task duties for e-commerce.” Proceedings of the AAAI Convention on Synthetic Intelligence. Vol. 38. №17. 2024
[3] Mehrdad, Navid, et al. “Massive Language Fashions for Relevance Judgment in Product Search.” arXiv preprint arXiv:2406.00247 (2024)
[4] Wu, Mingrui, and Sheng Cao. “LLM-Augmented Retrieval: Enhancing Retrieval Fashions By Language Fashions and Doc-Stage Embedding.” arXiv preprint arXiv:2404.05825 (2024)
[5] Cui, Yu, et al. “Distillation Issues: Empowering Sequential Recommenders to Match the Efficiency of Massive Language Mannequin.” arXiv preprint arXiv:2405.00338 (2024)
[6] Li, Zhiyu, et al. “Bookgpt: A common framework for guide advice empowered by giant language mannequin.” Electronics 12.22 (2023): 4654
[7] Wu, Xuansheng, et al. “In direction of personalised cold-start advice with prompts.” arXiv preprint arXiv:2306.17256 (2023)
[8] Luo, Sichun, et al. “Integrating giant language fashions into advice through mutual augmentation and adaptive aggregation.” arXiv preprint arXiv:2401.13870 (2024)
[9] Dong, Zhikang, et al. “Musechat: A conversational music advice system for movies.” Proceedings of the IEEE/CVF Convention on Pc Imaginative and prescient and Sample Recognition. 2024
If this text was useful to you and also you wish to be taught extra about real-world suggestions for Machine Studying, join with me on LinkedIn.
Kartik Singhal is a Senior Machine Studying Engineer at Meta with over 6 years of expertise with a concentrate on Search and Suggestions. He has beforehand labored at Amazon in Dynamic Pricing and forecasting. He’s pushed by his ardour for making use of the most recent analysis in Machine Studying and has beforehand mentored many engineers and college students who wished to get into Machine Studying.





