IBM Researchers ACPBench: An AI Benchmark for Evaluating the Reasoning Duties within the Area of Planning
LLMs are gaining traction because the workforce throughout domains is exploring synthetic intelligence and automation to plan their operations and make essential selections. Generative and Foundational fashions are thus relied on for multi-step reasoning duties to attain planning and execution at par with people. Though this aspiration is but to be achieved, we require intensive and unique benchmarks to check our fashions’ intelligence in reasoning and decision-making. Given the recentness of Gen AI and the brief span of LLM evolution, it’s difficult to generate validation approaches matching the tempo of LLM improvements. Notably, subjective claims resembling in planning. the validation metric’s completeness could stay questionable. For one, even when a mannequin fulfills checkboxes for a aim, can we confirm its capacity to plan? Secondly, in sensible situations, there exists not solely a single plan however a number of plans and their options. This makes the scenario extra chaotic. Thankfully, researchers throughout the globe are working to upskill LLMs for business planning. Thus, we’d like a great benchmark that exams if LLMs have achieved adequate reasoning and planning capabilities or if it’s a distant dream.
ACPBench is an LLM reasoning analysis developed by IBM Analysis consisting of seven reasoning duties over 13 planning domains. This benchmark consists of reasoning duties mandatory for dependable planning, compiled in a proper language that may reproduce extra issues and scale with out human interference. The title ACPBench is derived from the core topic its reasoning duties deal with: Action, Change and Planning. The duties’ complexity varies, with a couple of requiring single-step reasoning and others needing multi-step reasoning. They observe Boolean and A number of Alternative Questions (MCQs) from all 13 domains (12 are well-established benchmarks in planning and Reinforcement Studying, and the final one is designed from scratch). Earlier benchmarks in LLM planning have been restricted to just a few domains, which prompted hassle scaling up.

Apart from making use of in a number of domains, ACPBench differed from its contemporaries because it generates datasets from formal Planning Area Definition Language (PDDL) descriptions, which is similar factor liable for creating right issues and scaling them with out human intervention.
The seven duties offered in ACPBench are:
- Applicability – It determines the legitimate actions from accessible ones in a given scenario.
- Development – To know the end result of an motion or change.
- Reachability- It checks if the mannequin can obtain the tip aim from the present state by taking a number of actions.
- Motion Reachability- Determine the conditions for execution to execute a particular perform.
- Validation-To evaluate whether or not the desired sequence of actions is legitimate, relevant, and efficiently achieves the supposed aim.
- Justification – Determine whether or not an motion is critical.
- Landmarks-Determine subgoals which might be mandatory to attain the aim.
Twelve of the 13 domains above duties span throughout are classical planning prevalent names resembling BlocksWorld, Logistics, and Rovers, and the final one is a brand new class which authors title Swap. Every of those domains has a proper illustration in PDDL.
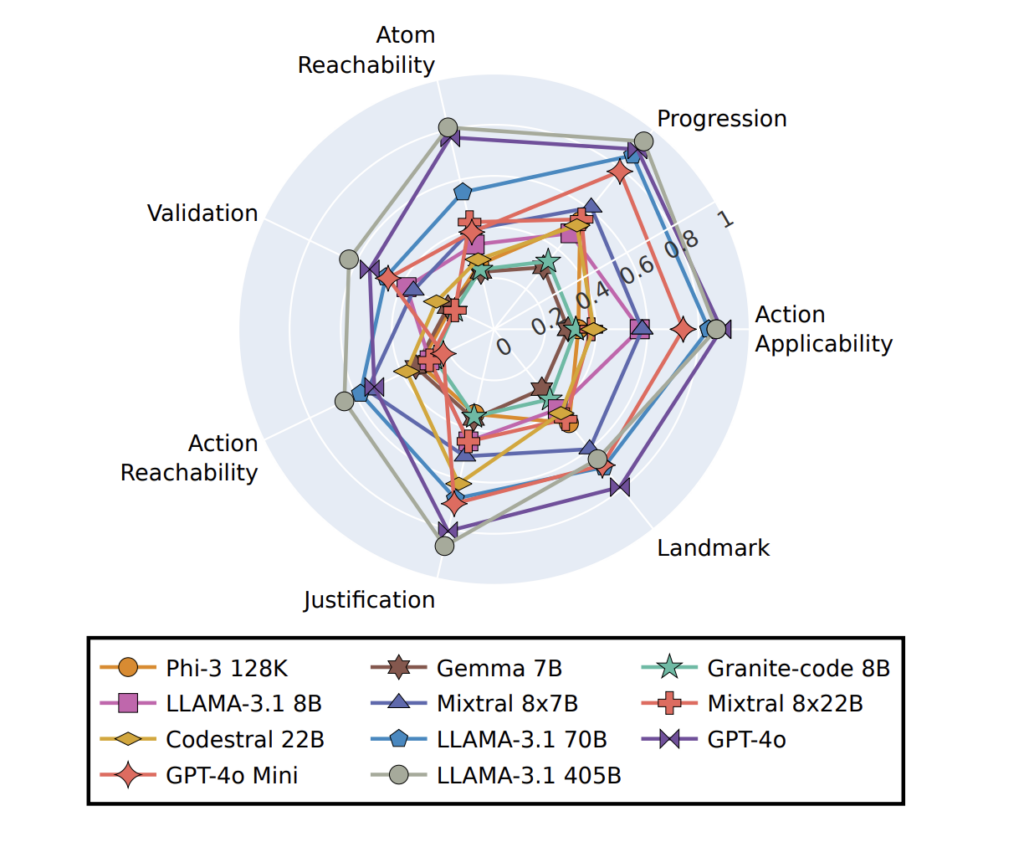
ACPBench was examined on 22 open-sourced and frontier LLMs.A few of the well-known ones included GPT-4o, LLAMAfashions, Mixtral, and others. The outcomes demonstrated that even the best-performing fashions (GPT-4o and LLAMA-3.1 405B) struggled with particular duties, significantly in motion reachability and validation. Some smaller fashions, like Codestral 22B, carried out nicely on boolean questions however lagged in multi-choice questions. The typical accuracy of GPT 4o went as little as 52 p.c on these duties. Submit-evaluation authors additionally effective tuned Granite-code 8B, a small mannequin and the method led to important enhancements. This effective tuned mannequin carried out at par with huge LLMs and generalized nicely on unseen domains, too!
ACPBench’s findings proved that LLMs underperformed on planning duties no matter measurement and complexity. Nonetheless, with skillfully crafted prompts and effective tuning methods, they’ll carry out higher at planning.
Try the Paper, GitHub and Project. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our newsletter.. Don’t Neglect to hitch our 50k+ ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – The GenAI Data Retrieval Conference (Promoted)
Adeeba Alam Ansari is presently pursuing her Twin Diploma on the Indian Institute of Know-how (IIT) Kharagpur, incomes a B.Tech in Industrial Engineering and an M.Tech in Monetary Engineering. With a eager curiosity in machine studying and synthetic intelligence, she is an avid reader and an inquisitive particular person. Adeeba firmly believes within the energy of expertise to empower society and promote welfare by way of progressive options pushed by empathy and a deep understanding of real-world challenges.





