Mirage: A Multi-Stage Tensor Algebra Tremendous-Optimizer that Automates GPU Kernel Technology for PyTorch Functions
With the rising development of synthetic intelligence—introduction of huge language fashions (LLMs) and generative AI—there was a rising demand for extra environment friendly graphics processing models (GPUs). GPUs are specialised {hardware} extensively used for top computing duties and able to executing computations in parallel. Writing correct GPU kernels is vital to make the most of GPUs to their full potential. This job is kind of time-consuming and sophisticated, requiring deep experience in GPU structure and a few programming languages like C++, CUDA, and many others.
Machine Studying ML compilers like TVM, Triton, and Mojo present sure automation however nonetheless want guide dealing with of the GPU kernels to acquire the optimum outcome. To realize optimum outcomes and keep away from guide tasking, researchers at Carnegie Mellon College have developed Mirage, an modern software designed to automate the technology of high-performance GPU kernels by trying to find and producing them. The kernels generated by Mirage can immediately be used on PyTorch tensors and be known as in PyTorch packages. Customers want to put in writing just a few strains of code in Mirage in comparison with the normal script, which makes use of many strains.
Mirage may be seen as a future changer, attaining excessive productiveness, higher efficiency, and stronger correctness in AI functions. Writing guide codes requires substantial engineering experience because of the complicated nature of GPU structure, however Mirage simplifies the method by routinely producing kernels, easing and simplifying the duties for engineers.
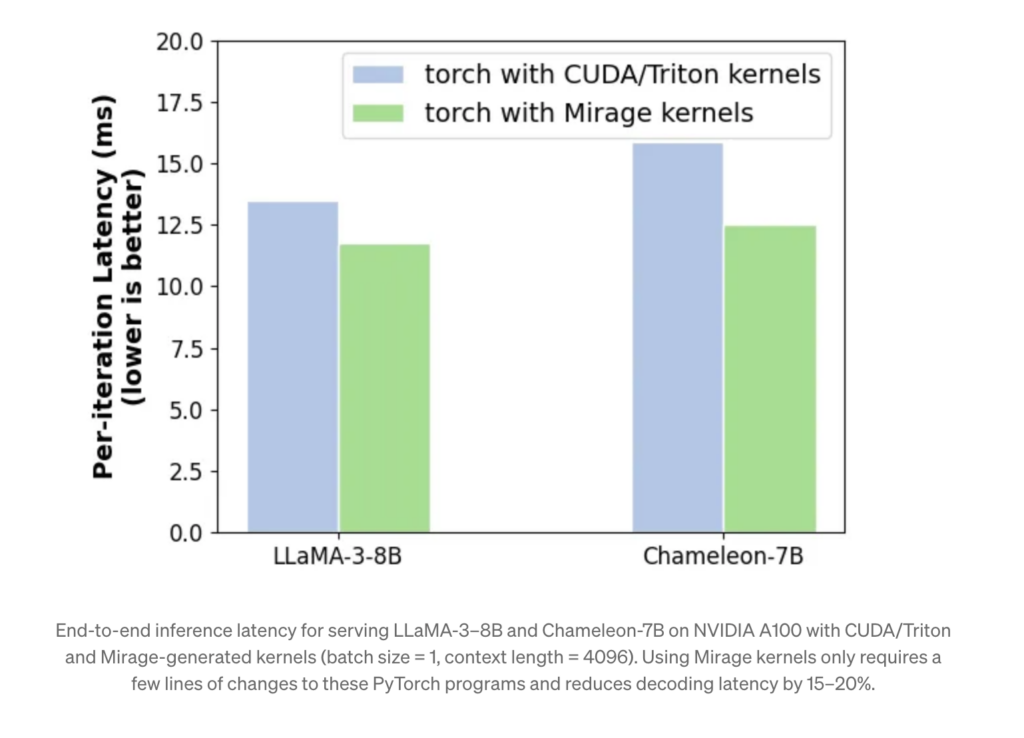
Manually written GPU kernels might need some errors, which makes it onerous to attain the required outcomes, however analysis on Mirage has proven that kernels generated by Mirage are 1.2x-2.5x instances quicker than the very best human-written code. Additionally, integrating Mirage into PyTorch reduces general latency by 15-20%.
# Use Mirage to generate GPU kernels for consideration
import mirage as mi
graph = mi.new_kernel_graph()
Q = graph.new_input(dims=(64, 1, 128), dtype=mi.float16)
Ok = graph.new_input(dims=(64, 128, 4096), dtype=mi.float16)
V = graph.new_input(dims=(64, 4096, 128), dtype=mi.float16)
A = graph.matmul(Q, Ok)
S = graph.softmax(A)
O = graph.matmul(S, V)
optimized_graph = graph.superoptimize()Code in Mirage takes few strains in comparison with conventional methodology with many strains
All of the computations in GPUs are centered round kernels, that are capabilities operating parallely round a number of streaming multiprocessors (SM) in a single-program-multiple information trend (SPMD). Kernels arrange computation in a grid of thread blocks, with every thread block operating on a single SM. Every block additional has a number of threads to carry out calculations on particular person information parts.
GPU follows a selected reminiscence hierarchy with:
- Register file for fast information entry
- Shared Reminiscence: Shared by all threads in a block for environment friendly information trade.
- System Reminiscence: Accessible by all threads in a kernel
The structure is represented with the assistance of the uGraph illustration, which accommodates graphs on a number of ranges: Kernel degree, thread block degree and thread degree with kernel-level encapsulating computation over your entire GPU, thread block degree addressing computation on a person streaming multiprocessor (SM), and thread graph addressing computation on the CUDA or tensor core degree. The uGraph supplies a structured method to symbolize GPU computations.
4 Classes of GPU Optimization:
1. Normalization + Linear
LLMs typically use LayernNorm, RMSNorm, GroupNorm, and BatchNorm methods, which are sometimes handled individually by ML compilers. This separation is as a result of normalization methods require each discount and broadcast operations. These normalization layers may be fused with linear ones by matrix multiplication.
2. LoRA + Linear
It fuses low-rank adaptation (LoRA), a way to adapt pre-trained fashions to new duties or datasets whereas lowering computational necessities with linear layers. It’s 1.6x quicker than the present methods.
3. Gated MLP
It combines two MatMuls, SiLU activation, and element-wise multiplication. Gated MLP reduces kernel launch overhead and gadget reminiscence entry to 1.3x quicker than the very best baseline.
4. Consideration variants
a. Question-Key Normalization
Chameleon, ViT-22B, and Google’s latest paper have launched query-key normalization and fused LayerNorm into the eye kernel. This practice kernel additionally performs current GPU optimizations tailor-made for consideration with a 1.7x-2.5x efficiency enchancment.
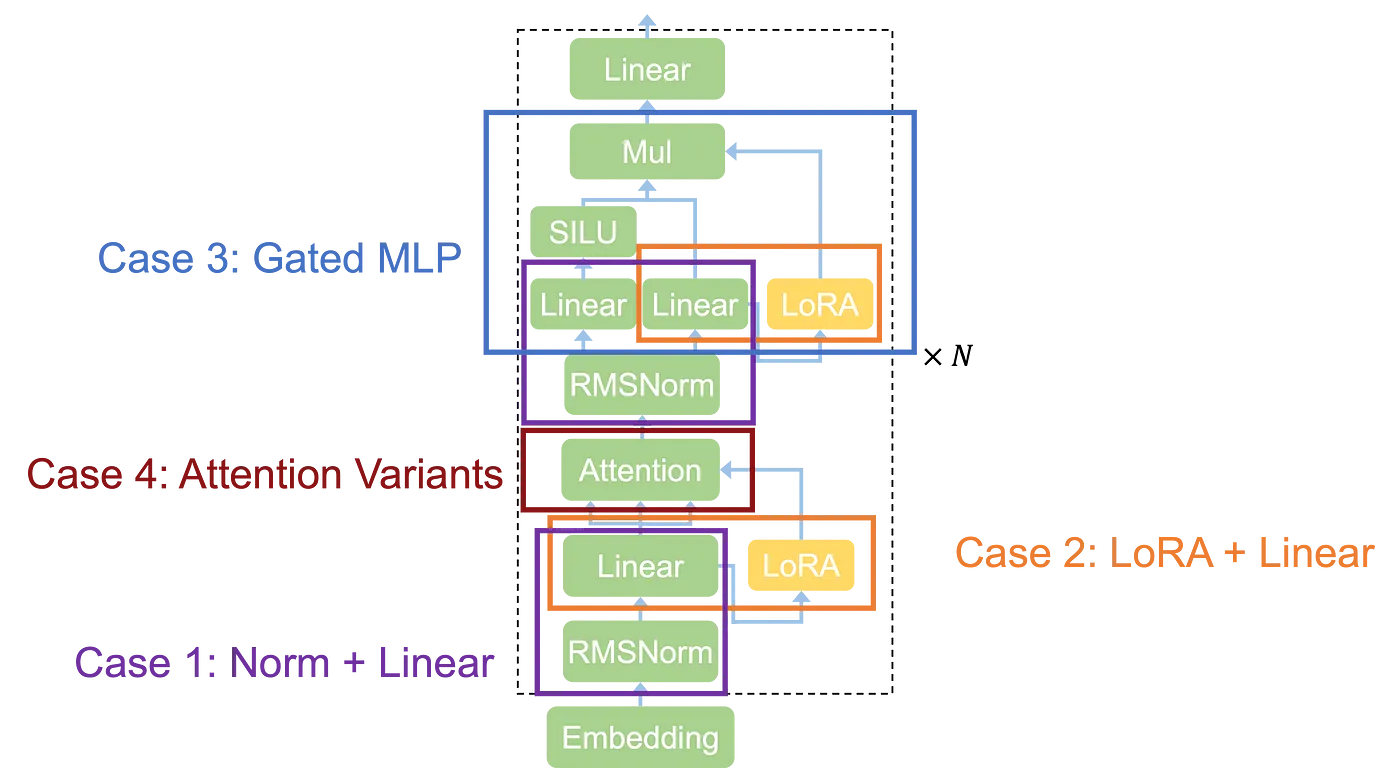
b. Multi-Head Latent Consideration
It optimizes reminiscence utilization by compressing conventional key-value cache of consideration right into a extra compact latent vector. This transformation introduces two linear layers earlier than consideration. Mirage generates a customized kernel that integrates the linear layers with the eye mechanism right into a single kernel. This prevents storing intermediate key-value vectors within the GPU gadget reminiscence.
In conclusion, Mirage addresses the crucial problem of coping with excessive GPU kernels in superior synthetic intelligence issues. It eliminates the issues of great time funding, excessive coding experience, and error technology by offering the very best optimum GPU kernels that work in a PyTorch-based atmosphere. It additionally offers with the loopholes that guide computing may miss, accelerating the deployment of LLMs and different AI applied sciences throughout real-world functions.
Take a look at the GitHub page and Details. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our newsletter..
Don’t Overlook to hitch our 50k+ ML SubReddit
Concerned with selling your organization, product, service, or occasion to over 1 Million AI builders and researchers? Let’s collaborate!
Nazmi Syed is a consulting intern at MarktechPost and is pursuing a Bachelor of Science diploma on the Indian Institute of Expertise (IIT) Kharagpur. She has a deep ardour for Knowledge Science and actively explores the wide-ranging functions of synthetic intelligence throughout varied industries. Fascinated by technological developments, Nazmi is dedicated to understanding and implementing cutting-edge improvements in real-world contexts.






