The Concise Information to Function Engineering for Higher Mannequin Efficiency


The Full Information to Function Engineering for Higher Mannequin Efficiency
Function engineering helps make fashions work higher. It entails deciding on and modifying knowledge to enhance predictions. This text explains function engineering and easy methods to use it to get higher outcomes.
What’s Function Engineering?
Uncooked knowledge is commonly messy and never prepared for predictions. Options are vital particulars in your knowledge. They assist the mannequin perceive and make predictions. Function engineering improves these options to make them extra helpful. Modeling makes use of these improved options to foretell outcomes. Analyzing the mannequin’s outcomes gives insights. Nicely-engineered options make these insights clearer. This helps you perceive knowledge patterns higher and improves mannequin efficiency.
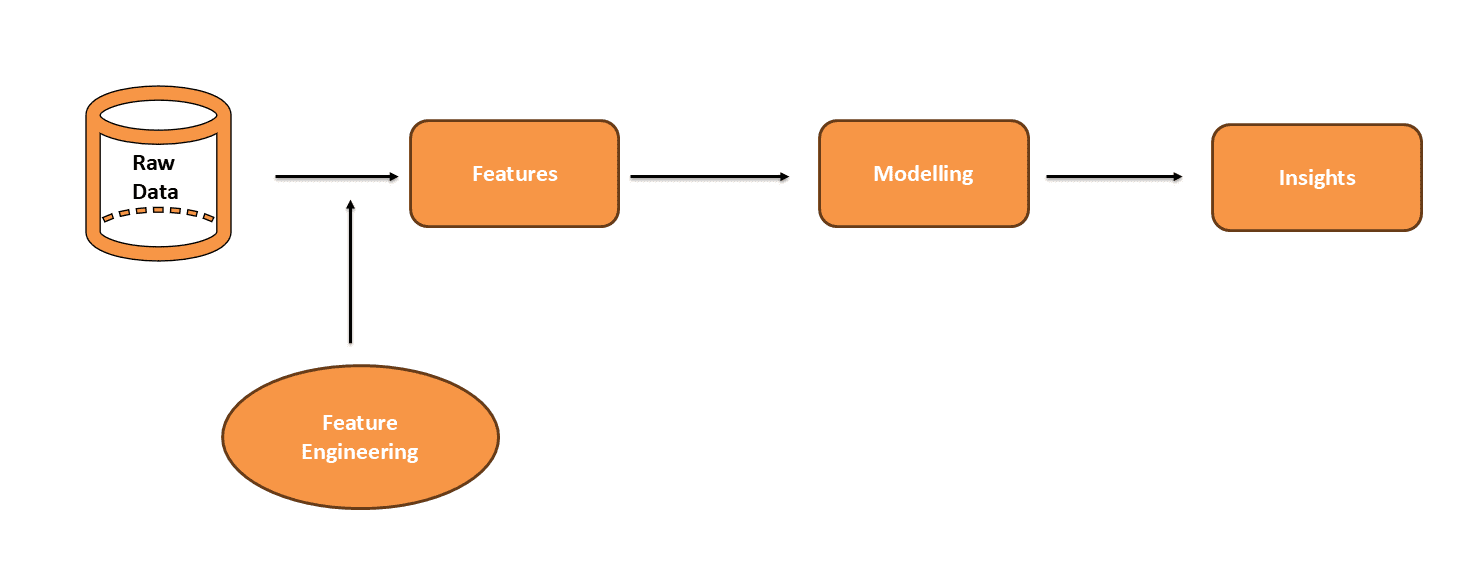
Why is Function Engineering Essential?
- Improved Accuracy: Good options assist the mannequin study higher patterns. This results in extra correct predictions.
- Decreased Overfitting: Higher options assist the mannequin generalize nicely to new knowledge. This reduces the possibility of overfitting.
- Algorithm Flexibility: Many algorithms work higher with clear and well-prepared options.
- Straightforward Interpretability: Clear options make it simpler to know how the mannequin makes selections.
Function Engineering Processes
Function engineering can contain a number of processes:
- Function Extraction: Make new options from what you have already got. Use strategies like PCA or embeddings to do that.
- Function Choice: Select an important options to assist your mannequin work higher. This retains the mannequin centered on the vital particulars.
- Function Creation: Create new options from present ones to assist the mannequin make higher predictions. This offers the mannequin extra helpful info.
- Function Transformation: Modify options to make them extra appropriate for the mannequin. Normalization scales values to be inside a variety of 0 to 1. Standardization adjusts options to have a imply of 0 and a regular deviation of 1.
Function Engineering Strategies
Let’s talk about a few of the widespread strategies of function engineering.
Dealing with Lacking Values
It’s vital to deal with lacking knowledge is for making correct fashions. Listed here are some methods to take away them:
- Imputation: Use strategies like imply, median, or mode to fill in lacking values primarily based on different knowledge within the column.
- Deletion: Take away rows or columns with lacking values if the quantity is small and received’t considerably impression the evaluation.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
import pandas as pd from sklearn.impute import SimpleImputer
# Load knowledge from a CSV file df = pd.read_csv(‘knowledge.csv’)
# Print knowledge earlier than imputation print(“Information earlier than cleansing:”) print(df.head())
# Take away commas from ‘Wage’ column and convert to numeric df[‘Salary’] = df[‘Salary’].str.exchange(‘,’, ”).astype(float)
# Impute lacking numerical values with the median imputer = SimpleImputer(technique=‘median’) df[[‘Age’, ‘Salary’]] = imputer.fit_transform(df[[‘Age’, ‘Salary’]])
# Print knowledge after imputation print(“nData after imputing lacking values:”) print(df.head()) |
The lacking values within the “Age” and “Wage” columns are crammed in with the median values.

Encoding Categorical Variables
Categorical variables have to be transformed into numerical values for machine studying fashions. Listed here are some widespread strategies:
- One-Sizzling Encoding: Generate new columns for every class. Every class will get its personal column with a 1 or 0.
- Label Encoding: Give every class a definite quantity. Helpful for ordinal knowledge the place the order issues.
- Binary Encoding: Convert classes to binary numbers after which cut up into separate columns. This methodology is beneficial for high-cardinality knowledge.
|
import pandas as pd from sklearn.preprocessing import LabelEncoder
# Load the dataset df = pd.read_csv(‘knowledge.csv’)
# One-Sizzling Encoding for the Division column df = pd.get_dummies(df, columns=[‘Department’], drop_first=True)
# Show the information after encoding print(“Information after encoding categorical variables:”) print(df.head()) |
After one-hot encoding, the “Division” column is split into new columns. Every column represents a class with binary values.

Binning
Binning teams steady values into discrete bins or ranges. It simplifies the information and can assist with noisy knowledge.
- Equal-Width Binning: Divide the vary into equal-width intervals. Every worth falls into one in all these intervals.
- Equal-Frequency Binning: Divide knowledge into bins so every bin has roughly the identical variety of values.
|
import pandas as pd
# Load the dataset df = pd.read_csv(‘knowledge.csv’)
# Binning Age into 3 classes (Younger, Center-Aged, Senior) df[‘Age_Binned’] = pd.lower(df[‘Age’], bins=3, labels=[‘Young’, ‘Middle-Aged’, ‘Senior’])
# Show the Age and Age_Binned columns (first 5 rows) print(“Information after binning Age (first 5 rows):”) print(df[[‘Age’, ‘Age_Binned’]].head()) |
Right here, age is categorized into “Younger,” “Center-Aged,” or “Senior” primarily based on the binning.

Dealing with Outliers
Outliers are knowledge factors which can be completely different from the remainder. They’ll mess up outcomes and have an effect on how nicely a mannequin works. Listed here are some widespread methods to deal with outliers:
- Elimination: Exclude excessive values that don’t match the general sample.
- Capping: Restrict excessive values to a most or minimal threshold.
- Transformation: Use strategies like log transformation to cut back the impression of outliers.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import pandas as pd import numpy as np from scipy import stats
# Load the dataset df = pd.read_csv(‘knowledge.csv’)
# Take away commas from ‘Wage’ column and convert to numeric df[‘Salary’] = df[‘Salary’].str.exchange(‘,’, ”).astype(float)
# Detect Outliers utilizing Interquartile Vary (IQR) methodology Q1 = df[‘Salary’].quantile(0.25) Q3 = df[‘Salary’].quantile(0.75) IQR = Q3 – Q1
# Outline outlier boundaries lower_bound = Q1 – 1.5 * IQR upper_bound = Q3 + 1.5 * IQR
# Determine outliers df[‘IQR_Outlier’] = (df[‘Salary’] < lower_bound) | (df[‘Salary’] > upper_bound)
# Take away outliers primarily based on IQR df_cleaned_iqr = df[~df[‘IQR_Outlier’]]
# Print the primary 5 rows of the cleaned knowledge after eradicating outliers print(df_cleaned_iqr.head()) |
The output shows the dataset after eradicating outliers primarily based on the Interquartile Vary (IQR) methodology. These rows not embody any entries with salaries outdoors the outlined outlier boundaries.

Scaling
Scaling adjusts the vary of function values. It ensures that options contribute equally to mannequin coaching.
- Normalization: Rescales values to a variety, typically 0 to 1. Instance: Min-Max scaling.
- Standardization: Facilities values round a imply of 0 and scales by the usual deviation. Instance: Z-score normalization.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
import pandas as pd from sklearn.preprocessing import MinMaxScaler, StandardScaler
# Load the dataset df = pd.read_csv(‘knowledge.csv’)
# Take away commas from ‘Wage’ column and convert to numeric df[‘Salary’] = df[‘Salary’].str.exchange(‘,’, ”).astype(float)
# Normalize options (Min-Max Scaling) min_max_scaler = MinMaxScaler() df[[‘Salary_Norm’, ‘Age_Norm’]] = min_max_scaler.fit_transform(df[[‘Salary’, ‘Age’]])
# Standardize options (Z-score Normalization) standard_scaler = StandardScaler() df[[‘Salary_Std’, ‘Age_Std’]] = standard_scaler.fit_transform(df[[‘Salary’, ‘Age’]]
# Print first 5 rows of unique knowledge print(“Authentic Information:”) print(df[[‘EmployeeID’, ‘Salary’, ‘Age’]].head())
# Print first 5 rows after normalization print(“nData after normalization (Min-Max Scaling):”) print(df[[‘EmployeeID’, ‘Salary_Norm’, ‘Age_Norm’]].head())
# Print first 5 rows after standardization print(“nData after standardization (Z-score Normalization):”) print(df[[‘EmployeeID’, ‘Salary_Std’, ‘Age_Std’]].head()) |
The code normalizes “Wage” and “Age” utilizing Min-Max scaling, leading to Salary_Norm and Age_Norm. It additionally standardizes these options utilizing Z-score normalization.

Greatest Practices for Function Engineering
Listed here are some suggestions to enhance function engineering:
- Iterate and Experiment: Function engineering is commonly an iterative course of. Check completely different transformations and interactions and validate them utilizing cross-validation.
- Automate with Instruments: Use instruments like Featuretools for automated function engineering or AutoML frameworks that carry out function choice and transformation.
- Perceive the Function’s Affect: At all times monitor the impression of recent options on mannequin efficiency. Generally, a fancy function might not present as a lot profit as anticipated.
- Leverage Area Information: Incorporate insights from area specialists to create options that seize industry-specific patterns and nuances. This will present priceless context and enhance mannequin relevance.
Conclusion
Function engineering helps enhance machine studying fashions. It makes your knowledge extra helpful. By creating and deciding on the suitable options, you get higher predictions. This course of is essential for profitable machine studying.
About Jayita Gulati
Jayita Gulati is a machine studying fanatic and technical author pushed by her ardour for constructing machine studying fashions. She holds a Grasp’s diploma in Laptop Science from the College of Liverpool.




