Use LangChain with PySpark to course of paperwork at huge scale with Amazon SageMaker Studio and Amazon EMR Serverless

Harnessing the facility of big data has turn out to be more and more vital for companies trying to achieve a aggressive edge. From deriving insights to powering generative artificial intelligence (AI)-driven purposes, the power to effectively course of and analyze giant datasets is a crucial functionality. Nevertheless, managing the advanced infrastructure required for giant information workloads has historically been a major problem, typically requiring specialised experience. That’s the place the brand new Amazon EMR Serverless software integration in Amazon SageMaker Studio will help.
With the introduction of EMR Serverless support for Apache Livy endpoints, SageMaker Studio customers can now seamlessly combine their Jupyter notebooks working sparkmagic kernels with the highly effective information processing capabilities of EMR Serverless. This permits SageMaker Studio customers to carry out petabyte-scale interactive information preparation, exploration, and machine studying (ML) immediately inside their acquainted Studio notebooks, with out the necessity to handle the underlying compute infrastructure. By utilizing the Livy REST APIs, SageMaker Studio customers can even lengthen their interactive analytics workflows past simply notebook-based eventualities, enabling a extra complete and streamlined data science expertise inside the Amazon SageMaker ecosystem.
On this publish, we display how you can leverage the brand new EMR Serverless integration with SageMaker Studio to streamline your information processing and machine studying workflows.
Advantages of integrating EMR Serverless with SageMaker Studio
The EMR Serverless software integration in SageMaker Studio presents a number of key advantages that may remodel the way in which your group approaches large information:
- Simplified infrastructure administration – By abstracting away the complexities of organising and managing Spark clusters, the EMR Serverless integration permits you to shortly spin up the compute sources wanted to your large information workloads, with out the work of provisioning and configuring the underlying infrastructure.
- Seamless integration with SageMaker – As a built-in function of the SageMaker platform, the EMR Serverless integration supplies a unified and intuitive expertise for information scientists and engineers. You may entry and make the most of this performance immediately inside the SageMaker Studio setting, permitting for a extra streamlined and environment friendly growth workflow.
- Price optimization – The serverless nature of the combination means you solely pay for the compute sources you utilize, reasonably than having to provision and preserve a persistent cluster. This could result in important value financial savings, particularly for workloads with variable or intermittent utilization patterns.
- Scalability and efficiency – The EMR Serverless integration robotically scales the compute sources up or down based mostly in your workload’s calls for, ensuring you all the time have the mandatory processing energy to deal with your large information duties. This flexibility helps optimize efficiency and decrease the danger of bottlenecks or useful resource constraints.
- Lowered operational overhead – The EMR Serverless integration with AWS streamlines large information processing by managing the underlying infrastructure, liberating up your group’s time and sources. This function in SageMaker Studio empowers information scientists, engineers, and analysts to give attention to growing data-driven purposes, simplifying infrastructure administration, lowering prices, and enhancing scalability. By unlocking the potential of your information, this highly effective integration drives tangible enterprise outcomes.
Resolution overview
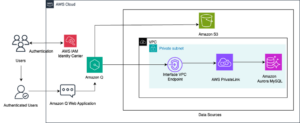
SageMaker Studio is a totally built-in growth setting (IDE) for ML that allows information scientists and builders to construct, prepare, debug, deploy, and monitor fashions inside a single web-based interface. SageMaker Studio runs inside an AWS managed digital personal cloud (VPC), with community entry for SageMaker Studio domains, on this setup configured as VPC-only. SageMaker Studio robotically creates an elastic community interface inside your VPC’s personal subnet, which connects to the required AWS providers via VPC endpoints. This identical interface can be used for provisioning EMR clusters. The next diagram illustrates this answer.

An ML platform administrator can handle permissioning for the EMR Serverless integration in SageMaker Studio. The administrator can configure the suitable privileges by updating the runtime position with an inline coverage, permitting SageMaker Studio customers to interactively create, replace, record, begin, cease, and delete EMR Serverless clusters. SageMaker Studio customers are introduced with built-in varieties inside the SageMaker Studio UI that don’t require extra configuration to work together with each EMR Serverless and Amazon Elastic Compute Cloud (Amazon EC2) based mostly clusters.

Apache Spark and its Python API, PySpark, empower customers to course of huge datasets effortlessly through the use of distributed computing throughout a number of nodes. These highly effective frameworks simplify the complexities of parallel processing, enabling you to put in writing code in a well-recognized syntax whereas the underlying engine manages information partitioning, process distribution, and fault tolerance. With scalability as a core energy, Spark and PySpark let you deal with datasets of just about any measurement, eliminating the constraints of a single machine.
Empowering information retrieval and technology with scalable Retrieval Augmented Generation (RAG) structure is more and more necessary in immediately’s period of ever-growing info. Successfully utilizing information to supply contextual and informative responses has turn out to be an important problem. That is the place RAG methods excel, combining the strengths of knowledge retrieval and textual content technology to ship complete and correct outcomes. On this publish, we discover how you can construct a scalable and environment friendly RAG system utilizing the brand new EMR Serverless integration, Spark’s distributed processing, and an Amazon OpenSearch Service vector database powered by the LangChain orchestration framework. This answer lets you course of huge volumes of textual information, generate relevant embeddings, and retailer them in a robust vector database for seamless retrieval and technology.
Authentication mechanism
When integrating EMR Serverless in SageMaker Studio, you should use runtime roles. Runtime roles are AWS Identity and Access Management (IAM) roles you could specify when submitting a job or question to an EMR Serverless software. These runtime roles present the mandatory permissions to your workloads to entry AWS sources, similar to Amazon Simple Storage Service (Amazon S3) buckets. When integrating EMR Serverless in SageMaker Studio, you may configure the IAM position for use by SageMaker Studio. By utilizing EMR runtime roles, you may make positive your workloads have the minimal set of permissions required to entry the mandatory sources, following the precept of least privilege. This enhances the general safety of your information processing pipelines and helps you preserve higher management over the entry to your AWS sources.
Price attribution of EMR Serverless clusters
EMR Serverless clusters created inside SageMaker Studio are robotically tagged with system default tags, particularly the domain-arn and user-profile-arn tags. These system-generated tags simplify value allocation and attribution of Amazon EMR sources. See the next code:
To study extra about enterprise-level value allocation for ML environments, discuss with Set up enterprise-level cost allocation for ML environments and workloads using resource tagging in Amazon SageMaker.
Conditions
Earlier than you get began, full the prerequisite steps on this part.
Create a SageMaker Studio area
This publish walks you thru the combination between SageMaker Studio and EMR Serverless utilizing an interactive SageMaker Studio pocket book. We assume you have already got a SageMaker Studio area provisioned with a UserProfile and an ExecutionRole. In the event you don’t have a SageMaker Studio area accessible, discuss with Quick setup to Amazon SageMaker to provision one.
Create an EMR Serverless job runtime position
EMR Serverless permits you to specify IAM position permissions that an EMR Serverless job run can assume when calling different providers in your behalf. This consists of entry to Amazon S3 for information sources and targets, in addition to different AWS sources like Amazon Redshift clusters and Amazon DynamoDB tables. To study extra about creating a task, discuss with Create a job runtime role.
The pattern following IAM inline coverage hooked up to a runtime position permits EMR Serverless to imagine a runtime position that gives entry to an S3 bucket and AWS Glue. You may modify the position to incorporate any extra providers that EMR Serverless must entry at runtime. Moreover, be sure you scope down the sources within the runtime insurance policies to stick to the precept of least privilege.
Lastly, ensure that your position has a belief relationship with EMR Serverless:

Optionally, you may create a runtime position and coverage utilizing infrastructure as code (IaC), similar to with AWS CloudFormation or Terraform, or utilizing the AWS Command Line Interface (AWS CLI).
Replace the SageMaker position to permit EMR Serverless entry
This one-time process permits SageMaker Studio customers to create, replace, record, begin, cease, and delete EMR Serverless clusters. We start by creating an inline coverage that grants the mandatory permissions for these actions on EMR Serverless clusters, then connect the coverage to the Studio area or person profile position:
Replace the area with EMR Serverless runtime roles
SageMaker Studio helps entry to EMR Serverless clusters in two methods: in the identical account because the SageMaker Studio area or throughout accounts.
To work together with EMR Serverless clusters created in the identical account because the SageMaker Studio area, create a file named same-account-update-domain.json:
Then run an update-domain command to permit all customers inside a website to permit customers to make use of the runtime position:
For EMR Serverless clusters created in a special account, create a file named cross-account-update-domain.json:
Then run an update-domain command to permit all customers inside a website to permit customers to make use of the runtime position:
Replace the person profile with EMR Serverless runtime roles
Optionally, this replace will be utilized extra granularly on the person profile stage as a substitute of the area stage. Just like area replace, to work together with EMR Serverless clusters created in the identical account because the SageMaker Studio area, create a file named same-account-update-user-profile.json:
Then run an update-user-profile command to permit this person profile use this run time position:
For EMR Serverless clusters created in a special account, create a file named cross-account-update-user-profile.json:
Then run an update-user-profile command to permit all customers inside a website to permit customers to make use of the runtime position:
Grant entry to the Amazon ECR repository
The really useful method to customise environments inside EMR Serverless clusters is through the use of custom Docker images.
Ensure you have an Amazon ECR repository in the identical AWS Area the place you launch EMR Serverless purposes. To create an ECR personal repository, discuss with Creating an Amazon ECR private repository to store images.
To grant customers entry to your ECR repository, add the next insurance policies to the customers and roles that create or replace EMR Serverless purposes utilizing photographs from this repository:
Customise the runtime setting in EMR Serverless clusters
Customizing cluster runtimes upfront is essential for a seamless expertise. As talked about earlier, we use custom-built Docker photographs from an ECR repository to optimize our cluster setting, together with the mandatory packages and binaries. The best method to construct these photographs is through the use of the SageMaker Studio built-in Docker performance, as mentioned in Accelerate ML workflows with Amazon SageMaker Studio Local Mode and Docker support. On this publish, we construct a Docker picture that features the Python 3.11 runtime and important packages for a typical RAG workflow, similar to langchain, sagemaker, opensearch-py, PyPDF2, and extra.
Full the next steps:
- Begin by launching a SageMaker Studio JupyterLab pocket book.
- Set up Docker in your JupyterLab setting. For directions, discuss with Accelerate ML workflows with Amazon SageMaker Studio Local Mode and Docker support.
- Open a brand new terminal inside your JupyterLab setting and confirm the Docker set up by working the next:

- Create a Docker file (discuss with Using custom images with EMR Serverless) and publish the picture to an ECR repository:
- Out of your JupyterLab terminal, run the next command to log in to the ECR repository:
- Run the next set of Docker instructions to construct, tag, and push the Docker picture to the ECR repository:
Use the EMR Serverless integration with SageMaker Studio
On this part, we display the combination of EMR Serverless into SageMaker Studio and how one can effortlessly work together together with your clusters, whether or not they’re in the identical account or throughout totally different accounts. To entry SageMaker Studio, full the next steps:
- On the SageMaker console, open SageMaker Studio.
- Relying in your group’s setup, you may log in to Studio both via the IAM console or utilizing AWS IAM Identity Center.

The new Studio experience is a serverless internet UI, which makes positive any updates happen seamlessly and asynchronously, with out interrupting your growth expertise.
- Below Knowledge within the navigation pane, select EMR Clusters.
You may navigate to 2 totally different tabs: EMR Serverless Functions or EMR Clusters (on Amazon EC2). For this publish, we give attention to EMR Serverless.

Create an EMR Serverless cluster
To create a brand new EMR Serverless cluster, full the next steps:
- On the EMR Serverless Functions tab, select Create.

- Within the Community connections part, you may optionally choose Hook up with your VPC and nest your EMR Serverless cluster inside a VPC and personal subnet.
- To customise your cluster runtime, select a appropriate {custom} picture out of your ECR repository and ensure your person profile position has the mandatory permissions to tug from this repository.
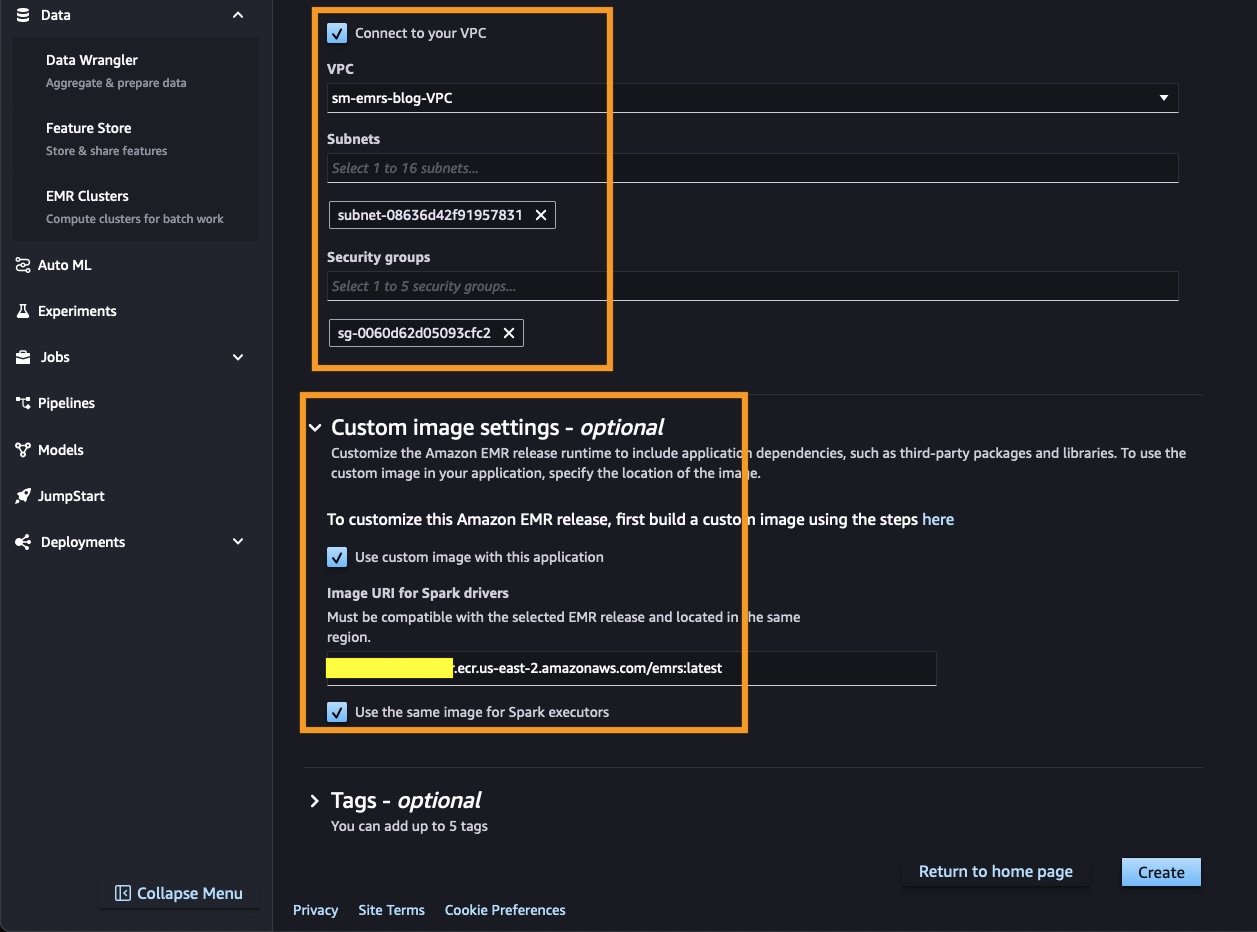
Work together with EMR Serverless clusters
EMR Serverless clusters can robotically scale all the way down to zero when not in use, eliminating prices related to idling sources. This function makes EMR Serverless clusters extremely versatile and cost-effective. You may record, view, create, begin, cease, and delete all of your EMR Serverless clusters immediately inside SageMaker Studio.

It’s also possible to interactively connect an current cluster to a pocket book by selecting Connect to new pocket book.

Construct a RAG doc processing engine utilizing PySpark
On this part, we use the SageMaker Studio cluster integration to parallelize information processing at an enormous scale. A typical RAG framework consists of two fundamental elements:
- Offline doc embedding technology – This course of includes extracting information (textual content, photographs, tables, and metadata) from varied sources and producing embeddings utilizing a big language embeddings mannequin. These embeddings are then saved in a vector database, similar to OpenSearch Service.
- On-line textual content technology with context – Throughout this course of, a person’s question is searched towards the vector database, and the paperwork most much like the question are retrieved. The retrieved paperwork, together with the person’s question, are mixed into an augmented immediate and despatched to a big language mannequin (LLM), similar to Meta Llama 3 or Anthropic Claude on Amazon Bedrock, for textual content technology.
Within the following sections, we give attention to the offline doc embedding technology course of and discover how you can use PySpark on EMR Serverless utilizing an interactive SageMaker Studio JupyterLab pocket book to effectively parallel course of PDF paperwork.
Deploy an embeddings mannequin
For this use case, we use the Hugging Face All MiniLM L6 v2 embeddings mannequin from Amazon SageMaker JumpStart. To shortly deploy this embedding mannequin, full the next steps:
- In SageMaker Studio, select JumpStart within the navigation pane.
- Seek for and select All MiniLM L6 v2.
- On the mannequin card, select Deploy.
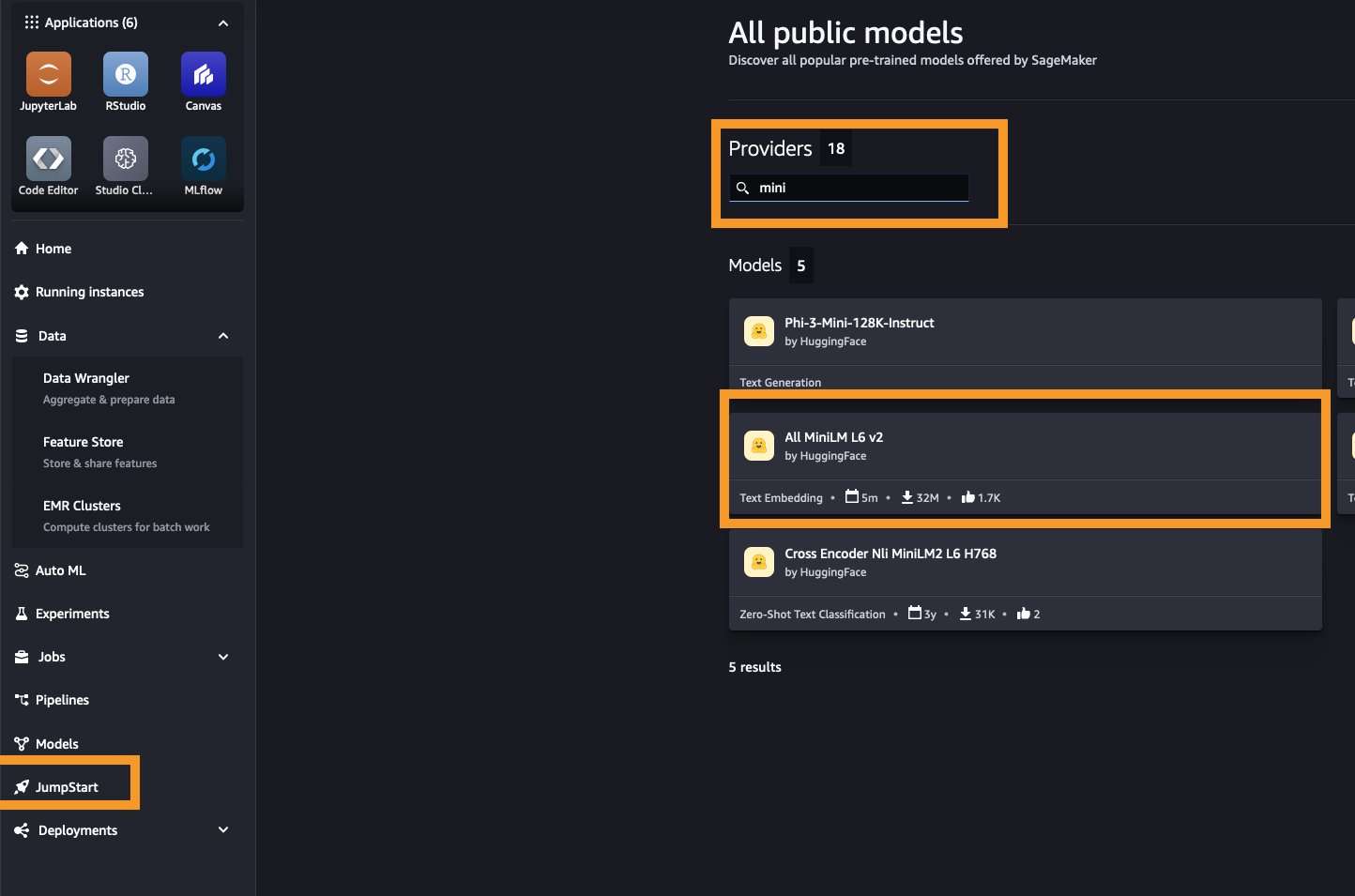
Your mannequin can be prepared inside a couple of minutes. Alternatively, you may select some other embedding fashions from SageMaker JumpStart by filtering Job kind to Textual content embedding.
Interactively construct an offline doc embedding generator
On this part, we use code from the next GitHub repo and interactively construct a doc processing engine utilizing LangChain and PySpark. Full the next steps:
- Create a SageMaker Studio JupyterLab growth setting. For extra particulars, see Boost productivity on Amazon SageMaker Studio: Introducing JupyterLab Spaces and generative AI tools.
- Select an applicable occasion kind and EBS storage quantity to your growth setting.
You may change the occasion kind at any time by stopping and restarting the house.

- Clone the pattern code from the next GitHub repository and use the pocket book accessible beneath
use-cases/pyspark-langchain-rag-processor/Offline_RAG_Processor_on_SageMaker_Studio_using_EMR-Serverless.ipynb - In SageMaker Studio, beneath Knowledge within the navigation pane, select EMR Clusters.
- On the EMR Serverless Functions tab, select Create to create a cluster.
- Choose your cluster and select Connect to new pocket book.
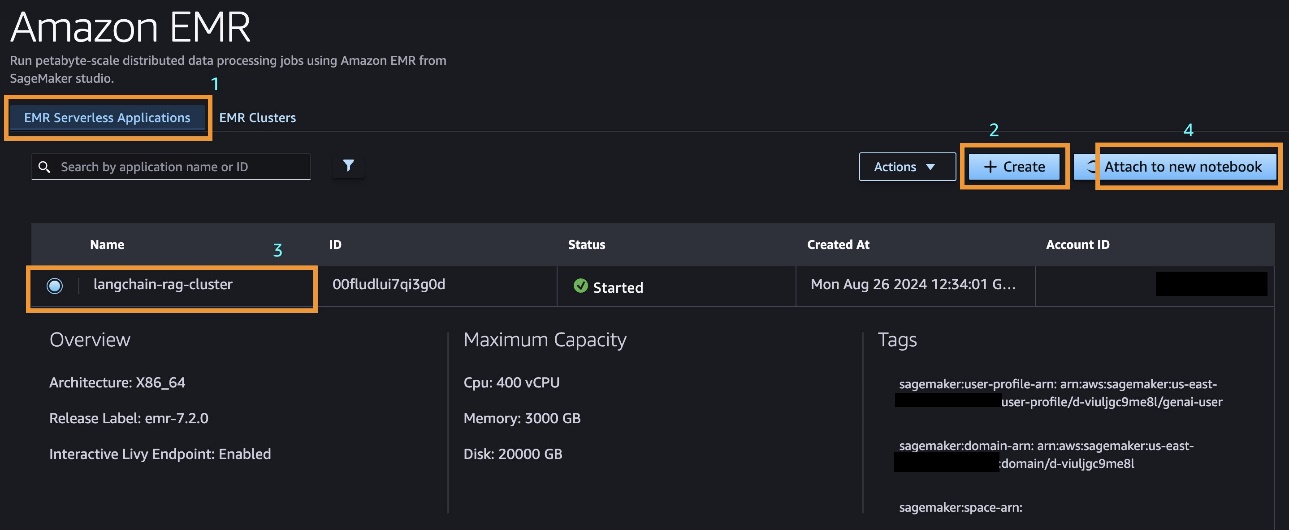
- Connect this cluster to a JupyterLab pocket book working inside an area.
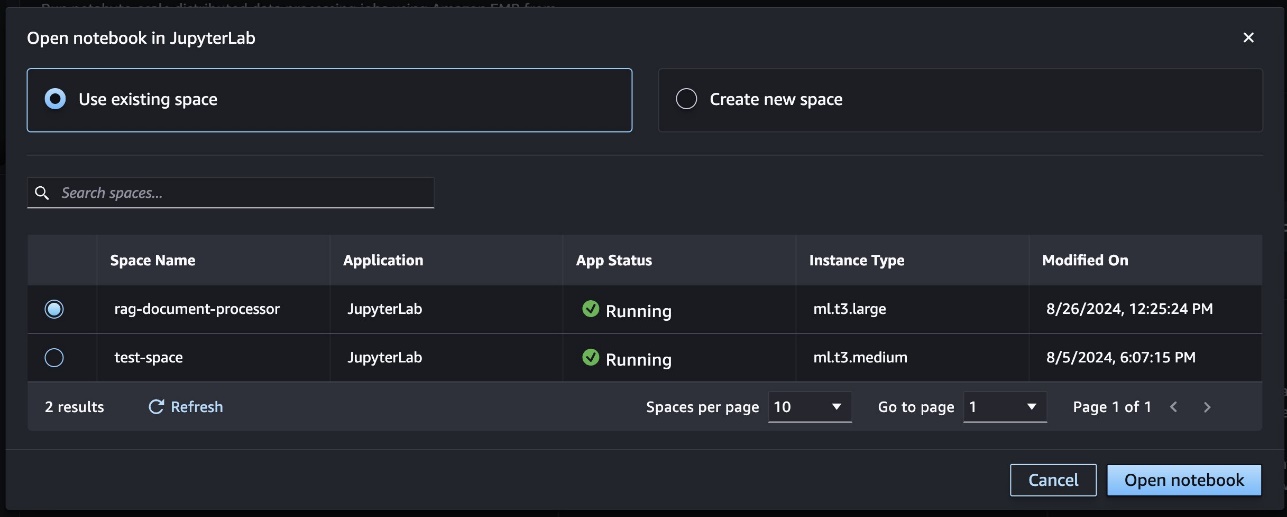
Alternatively, you may connect your cluster to any pocket book inside your JupyterLab house by selecting Cluster and choosing the EMR Serverless cluster you need to connect to the pocket book.

Ensure you select the SparkMagic PySpark kernel when interactively working PySpark workloads.

A profitable cluster connection to a pocket book ought to lead to a useable Spark session and hyperlinks to the Spark UI and driver logs.

When a pocket book cell is run inside a SparkMagic PySpark kernel, the operations are, by default, run inside a Spark cluster. Nevertheless, should you embellish the cell with %%native, it permits the code to be run on the native compute the place the JupyterLab pocket book is hosted. We start by studying a listing of PDF paperwork from Amazon S3 immediately into the cluster reminiscence, as illustrated within the following diagram.

- Use the next code to learn the paperwork:
Subsequent, you may visualize the scale of every doc to grasp the quantity of knowledge you’re processing.
- You may generate charts and visualize your information inside your PySpark pocket book cell utilizing static visualization instruments like matplotlib and seaborn. See the next code:

Each PDF doc incorporates a number of pages to course of, and this process will be run in parallel utilizing Spark. Every doc is cut up web page by web page, with every web page referencing the worldwide in-memory PDFs. We obtain parallelism on the web page stage by creating a listing of pages and processing each in parallel. The next diagram supplies a visible illustration of this course of.

The extracted textual content from every web page of a number of paperwork is transformed right into a LangChain-friendly Doc class.
- The
CustomDocumentclass, proven within the following code, is a {custom} implementation of theDocclass that permits you to convert {custom} textual content blobs right into a format acknowledged by LangChain. After conversion, the paperwork are cut up into chunks and ready for embedding. - Subsequent, you should use LangChain’s built-in
OpenSearchVectorSearchto create textual content embeddings. Nevertheless, we use a {custom}EmbeddingsGeneratorclass that parallelizes (utilizing PySpark) the embeddings technology course of utilizing a load-balanced SageMaker hosted embeddings model endpoint:
The {custom} EmbeddingsGenerator class can generate embeddings for roughly 2,500 pages (12,000 chunks) of paperwork in beneath 180 seconds utilizing simply two concurrent load-balanced SageMaker embedding mannequin endpoints and 10 PySpark employee nodes. This course of will be additional accelerated by growing the variety of load-balanced embedding endpoints and employee nodes within the cluster.
Conclusion
The mixing of EMR Serverless with SageMaker Studio represents a major leap ahead in simplifying and enhancing large information processing and ML workflows. By eliminating the complexities of infrastructure administration, enabling seamless scalability, and optimizing prices, this highly effective mixture empowers organizations to make use of petabyte-scale information processing with out the overhead sometimes related to managing Spark clusters. The streamlined expertise inside SageMaker Studio permits information scientists and engineers to give attention to what actually issues—driving insights and innovation from their information. Whether or not you’re processing huge datasets, constructing RAG methods, or exploring different superior analytics, this integration opens up new prospects for effectivity and scale, all inside the acquainted and user-friendly setting of SageMaker Studio.
As information continues to develop in quantity and complexity, adopting instruments like EMR Serverless and SageMaker Studio can be key to sustaining a aggressive edge within the ever-evolving panorama of data-driven decision-making. We encourage you to do that function immediately by organising SageMaker Studio utilizing the SageMaker quick setup guide. To study extra concerning the EMR Serverless integration with SageMaker Studio, discuss with Prepare data using EMR Serverless. You may discover extra generative AI samples and use instances within the GitHub repository.
In regards to the authors
 Raj Ramasubbu is a Senior Analytics Specialist Options Architect centered on large information and analytics and AI/ML with Amazon Internet Companies. He helps prospects architect and construct extremely scalable, performant, and safe cloud-based options on AWS. Raj offered technical experience and management in constructing information engineering, large information analytics, enterprise intelligence, and information science options for over 18 years previous to becoming a member of AWS. He helped prospects in varied business verticals like healthcare, medical units, life science, retail, asset administration, automotive insurance coverage, residential REIT, agriculture, title insurance coverage, provide chain, doc administration, and actual property.
Raj Ramasubbu is a Senior Analytics Specialist Options Architect centered on large information and analytics and AI/ML with Amazon Internet Companies. He helps prospects architect and construct extremely scalable, performant, and safe cloud-based options on AWS. Raj offered technical experience and management in constructing information engineering, large information analytics, enterprise intelligence, and information science options for over 18 years previous to becoming a member of AWS. He helped prospects in varied business verticals like healthcare, medical units, life science, retail, asset administration, automotive insurance coverage, residential REIT, agriculture, title insurance coverage, provide chain, doc administration, and actual property.
 Pranav Murthy is an AI/ML Specialist Options Architect at AWS. He focuses on serving to prospects construct, prepare, deploy and migrate machine studying (ML) workloads to SageMaker. He beforehand labored within the semiconductor business growing giant pc imaginative and prescient (CV) and pure language processing (NLP) fashions to enhance semiconductor processes utilizing cutting-edge ML methods. In his free time, he enjoys taking part in chess and touring. Yow will discover Pranav on LinkedIn.
Pranav Murthy is an AI/ML Specialist Options Architect at AWS. He focuses on serving to prospects construct, prepare, deploy and migrate machine studying (ML) workloads to SageMaker. He beforehand labored within the semiconductor business growing giant pc imaginative and prescient (CV) and pure language processing (NLP) fashions to enhance semiconductor processes utilizing cutting-edge ML methods. In his free time, he enjoys taking part in chess and touring. Yow will discover Pranav on LinkedIn.
 Naufal Mir is an Senior GenAI/ML Specialist Options Architect at AWS. He focuses on serving to prospects construct, prepare, deploy and migrate machine studying (ML) workloads to SageMaker. He beforehand labored at monetary providers institutes growing and working methods at scale. He enjoys extremely endurance working and biking.
Naufal Mir is an Senior GenAI/ML Specialist Options Architect at AWS. He focuses on serving to prospects construct, prepare, deploy and migrate machine studying (ML) workloads to SageMaker. He beforehand labored at monetary providers institutes growing and working methods at scale. He enjoys extremely endurance working and biking.
 Kunal Jha is a Senior Product Supervisor at AWS. He’s centered on constructing Amazon SageMaker Studio because the best-in-class selection for end-to-end ML growth. In his spare time, Kunal enjoys snowboarding and exploring the Pacific Northwest. Yow will discover him on LinkedIn.
Kunal Jha is a Senior Product Supervisor at AWS. He’s centered on constructing Amazon SageMaker Studio because the best-in-class selection for end-to-end ML growth. In his spare time, Kunal enjoys snowboarding and exploring the Pacific Northwest. Yow will discover him on LinkedIn.
 Ashwin Krishna is a Senior SDE working for SageMaker Studio at Amazon Internet Companies. He’s centered on constructing interactive ML options for AWS enterprise prospects to realize their enterprise wants. He’s a giant supporter of Arsenal soccer membership and spends spare time taking part in and watching soccer.
Ashwin Krishna is a Senior SDE working for SageMaker Studio at Amazon Internet Companies. He’s centered on constructing interactive ML options for AWS enterprise prospects to realize their enterprise wants. He’s a giant supporter of Arsenal soccer membership and spends spare time taking part in and watching soccer.
 Harini Narayanan is a software program engineer at AWS, the place she’s excited to construct cutting-edge information preparation know-how for machine studying at SageMaker Studio. With a eager curiosity in sustainability, inside design, and a love for all issues inexperienced, Harini brings a considerate strategy to innovation, mixing know-how along with her numerous passions.
Harini Narayanan is a software program engineer at AWS, the place she’s excited to construct cutting-edge information preparation know-how for machine studying at SageMaker Studio. With a eager curiosity in sustainability, inside design, and a love for all issues inexperienced, Harini brings a considerate strategy to innovation, mixing know-how along with her numerous passions.