Can LLMs Visualize Graphics? Assessing Symbolic Program Understanding in AI
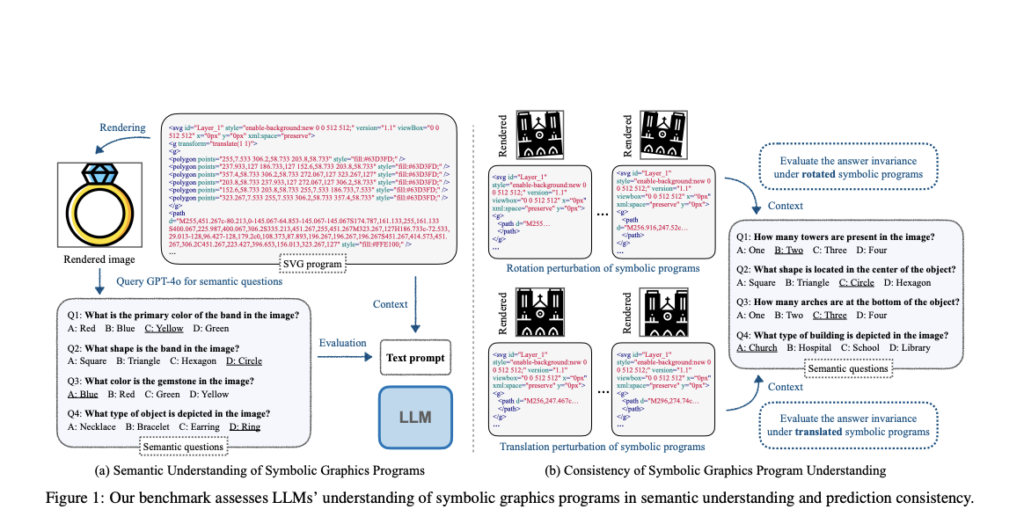
Massive language fashions (LLMs) have demonstrated the flexibility to generate generic laptop packages, offering an understanding of program construction. Nonetheless, it’s difficult to seek out the true capabilities of LLMs, particularly find duties they didn’t see throughout coaching. It’s essential to seek out whether or not LLMs can really “perceive” the symbolic graphics packages, which generate visible content material when executed. They outline this understanding as the flexibility to know the semantic content material of the rendered picture primarily based solely on the uncooked textual content enter, of this system. This methodology includes answering questions in regards to the picture’s content material with out really viewing it, which is simple with visible enter however a lot more durable when relying solely on this system’s textual content.
Present analysis on symbolic graphics packages has primarily targeted on procedural modeling for 2D shapes and 3D geometry. These packages, reminiscent of Constructive Strong Geometry (CSG), Pc-Aided Design (CAD), and Scalable Vector Graphics (SVG), present a transparent and interpretable illustration of visible content material. Furthermore, LLMs have been utilized to numerous programming duties, reminiscent of code retrieval, automated testing, and era; nevertheless, understanding symbolic graphics packages is basically totally different, as their semantic which means is usually outlined visually. Present benchmarks for LLMs concentrate on non-graphics program understanding, whereas vision-language fashions are evaluated utilizing multimodal datasets for duties like picture captioning and visible query answering.
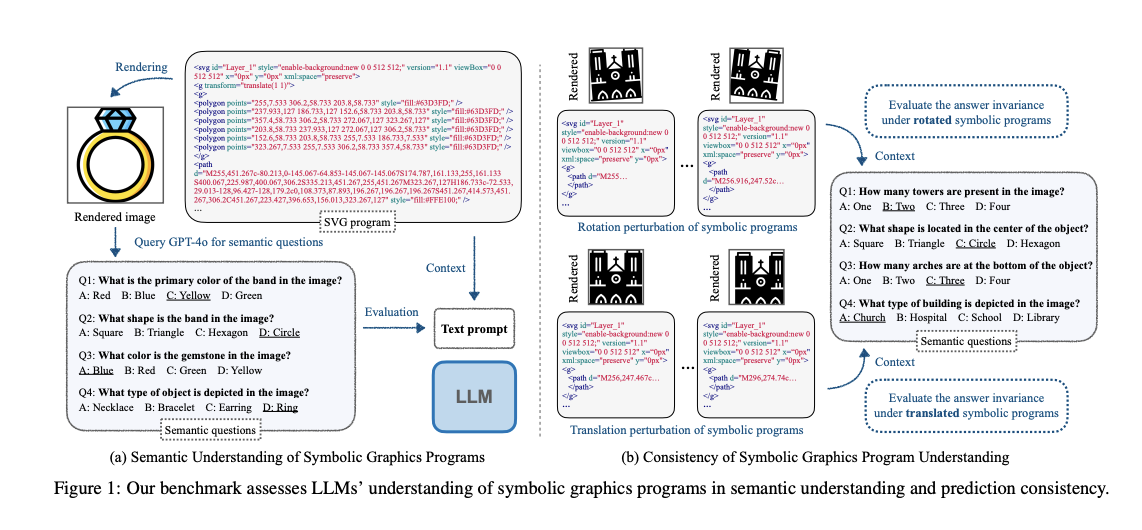
Researchers from the Max Planck Institute for Clever Programs, Tübingen, College of Cambridge, and MIT have proposed a novel method to guage and improve LLMs’ understanding of symbolic graphics packages. A benchmark referred to as SGP-Bench is launched for LLMs’ semantic understanding and consistency in decoding SVG (2D vector graphics) and CAD (2D/3D objects) packages. Furthermore, a brand new fine-tuning methodology primarily based on a collected instruction-following dataset referred to as symbolic instruction tuning is developed to reinforce efficiency. Additionally, the symbolic MNIST dataset created by the researchers reveals main variations between LLM and human understanding of symbolic graphics packages.
The method of setting up a benchmark to guage LLMs’ understanding of symbolic graphics packages makes use of a scalable and environment friendly pipeline. It makes use of a strong vision-language mannequin (GPT-4o) to generate semantic questions primarily based on rendered pictures of the symbolic packages. Additional, human annotators confirm the standard and accuracy of those robotically generated question-answer pairs. This method reduces the handbook effort wanted in comparison with conventional information creation strategies. The method for SVG and 2D CAD packages is simple as they straight produce 2D pictures, however in 3D CAD packages, the 3D fashions are first transformed into 2D pictures from a number of fastened digital camera positions.
The analysis of LLMs’ understanding of symbolic graphics packages is completed on the SGP-MNIST dataset that consists of 1,000 SVG packages that render MNIST-like digit pictures, with 100 packages per digit (0-9). Whereas people can simply acknowledge the photographs, LLMs discovered it extraordinarily difficult to interpret the symbolic packages. Even the superior GPT-4o mannequin carried out solely barely higher than random guessing. This stark distinction between human and LLM efficiency highlights a major hole in how machines course of and perceive symbolic representations of visible data in comparison with people.
In conclusion, researchers current a brand new solution to consider LLMs by assessing their capacity to know pictures straight from their symbolic graphics packages with out visible enter. The researchers created the SGP-Bench, a benchmark that successfully measures how properly LLMs carry out on this activity. In addition they launched Symbolic Instruction Finetuning (SIT) to reinforce LLMs’ capacity to interpret graphics packages. This analysis helps present a clearer image of LLM capabilities and promotes the creation of various analysis duties. Future analysis contains investigating how LLMs perceive semantics on this space and dealing on creating superior strategies to enhance their efficiency in these duties.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our newsletter..
Don’t Overlook to affix our 48k+ ML SubReddit
Discover Upcoming AI Webinars here

Sajjad Ansari is a remaining 12 months undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a concentrate on understanding the influence of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.





