Clever healthcare varieties evaluation with Amazon Bedrock
Generative synthetic intelligence (AI) gives a chance for enhancements in healthcare by combining and analyzing structured and unstructured knowledge throughout beforehand disconnected silos. Generative AI may help elevate the bar on effectivity and effectiveness throughout the complete scope of healthcare supply.
The healthcare trade generates and collects a big quantity of unstructured textual knowledge, together with medical documentation equivalent to affected person info, medical historical past, and take a look at outcomes, in addition to non-clinical documentation like administrative information. This unstructured knowledge can influence the effectivity and productiveness of medical companies, as a result of it’s usually present in varied paper-based varieties that may be troublesome to handle and course of. Streamlining the dealing with of this info is essential for healthcare suppliers to enhance affected person care and optimize their operations.
Dealing with massive volumes of knowledge, extracting unstructured knowledge from a number of paper varieties or pictures, and evaluating it with the usual or reference varieties could be a lengthy and arduous course of, liable to errors and inefficiencies. Nevertheless, developments in generative AI options have launched automated approaches that supply a extra environment friendly and dependable resolution for evaluating a number of paperwork.
Amazon Bedrock is a totally managed service that makes basis fashions (FMs) from main AI startups and Amazon obtainable via an API, so you may select from a variety of FMs to seek out the mannequin that’s greatest suited on your use case. Amazon Bedrock provides a serverless expertise, so you will get began shortly, privately customise FMs with your personal knowledge, and shortly combine and deploy them into your functions utilizing the AWS instruments with out having to handle the infrastructure.
On this put up, we discover utilizing the Anthropic Claude 3 on Amazon Bedrock massive language mannequin (LLM). Amazon Bedrock gives entry to a number of LLMs, equivalent to Anthropic Claude 3, which can be utilized to generate semi-structured knowledge related to the healthcare trade. This may be significantly helpful for creating varied healthcare-related varieties, equivalent to affected person consumption varieties, insurance coverage declare varieties, or medical historical past questionnaires.
Answer overview
To supply a high-level understanding of how the answer works earlier than diving deeper into the particular components and the companies used, we talk about the architectural steps required to construct our resolution on AWS. We illustrate the important thing components of the answer, providing you with an summary of the assorted elements and their interactions.
We then look at every of the important thing components in additional element, exploring the particular AWS companies which might be used to construct the answer, and talk about how these companies work collectively to attain the specified performance. This gives a stable basis for additional exploration and implementation of the answer.
Half 1: Normal varieties: Information extraction and storage
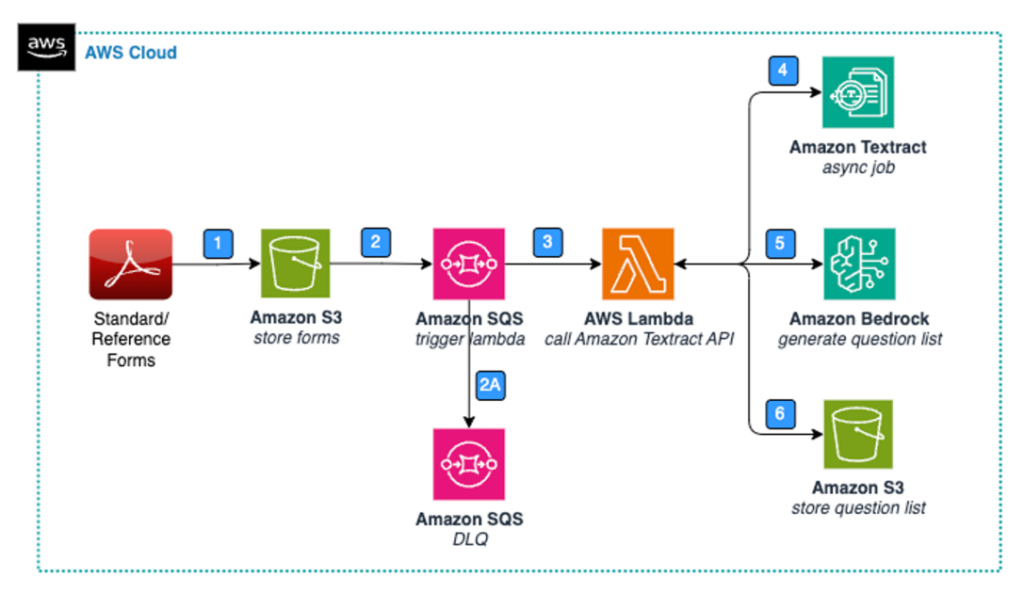
The next diagram highlights the important thing components of an answer for knowledge extraction and storage with commonplace varieties.

Determine 1: Structure – Normal Type – Information Extraction & Storage.
The Normal from processing steps are as follows:
- A person add pictures of paper varieties (PDF, PNG, JPEG) to Amazon Simple Storage Service (Amazon S3), a extremely scalable and sturdy object storage service.
- Amazon Simple Queue Service (Amazon SQS) is used because the message queue. Every time a brand new type is loaded, an occasion is invoked in Amazon SQS.
- If an S3 object isn’t processed, then after two tries it is going to be moved to the SQS dead-letter queue (DLQ), which could be configured additional with an Amazon Simple Notification Service (Amazon SNS) matter to inform the person via e mail.
- The SQS message invokes an AWS Lambda The Lambda perform is chargeable for processing the brand new type knowledge.
- The Lambda perform reads the brand new S3 object and passes it to the Amazon Textract API to course of the unstructured knowledge and generate a hierarchical, structured output. Amazon Textract is an AWS service that may extract textual content, handwriting, and knowledge from scanned paperwork and pictures. This method permits for the environment friendly and scalable processing of advanced paperwork, enabling you to extract beneficial insights and knowledge from varied sources.
- The Lambda perform passes the transformed textual content to Anthropic Claude 3 on Amazon Bedrock Anthropic Claude 3 to generate an inventory of questions.
- Lastly, the Lambda perform shops the query record in Amazon S3.
Amazon Bedrock API name to extract type particulars
We name an Amazon Bedrock API twice within the course of for the next actions:
- Extract questions from the usual or reference type – The primary API name is made to extract an inventory of questions and sub-questions from the usual or reference type. This record serves as a baseline or reference level for comparability with different varieties. By extracting the questions from the reference type, we will set up a benchmark towards which different varieties could be evaluated.
- Extract questions from the customized type – The second API name is made to extract an inventory of questions and sub-questions from the customized type or the shape that must be in contrast towards the usual or reference type. This step is critical as a result of we have to analyze the customized type’s content material and construction to establish its questions and sub-questions earlier than we will examine them with the reference type.
By having the questions extracted and structured individually for each the reference and customized varieties, the answer can then go these two lists to the Amazon Bedrock API for the ultimate comparability step. This method maintains the next:
- Correct comparability – The API has entry to the structured knowledge from each varieties, making it easy to establish matches, mismatches, and supply related reasoning
- Environment friendly processing – Separating the extraction course of for the reference and customized varieties helps keep away from redundant operations and optimizes the general workflow
- Observability and interoperability – Retaining the questions separate permits higher visibility, evaluation, and integration of the questions from completely different varieties
- Hallucination avoidance – By following a structured method and counting on the extracted knowledge, the answer helps keep away from producing or hallucinating content material, offering integrity within the comparability course of
This two-step method makes use of the capabilities of the Amazon Bedrock API whereas optimizing the workflow, enabling correct and environment friendly type comparability, and selling observability and interoperability of the questions concerned.
See the next code (API Name):
Consumer immediate to extract fields and record them
We offer the next person immediate to Anthropic Claude 3 to extract the fields from the uncooked textual content and record them for comparability as proven in step 3B (of Determine 3: Information Extraction & Type Subject comparability).
The next determine illustrates the output from Amazon Bedrock with an inventory of questions from the usual or reference type.

Determine 2: Normal Type Pattern Query Listing
Retailer this query record in Amazon S3 so it may be used for comparability with different varieties, as proven in Half 2 of the method under.
Half 2: Information extraction and type discipline comparability
The next diagram illustrates the structure for the following step, which is knowledge extraction and type discipline comparability.

Determine 3: Information Extraction & Type Subject comparability
Steps 1 and a couple of are just like these in Determine 1, however are repeated for the varieties to be in contrast towards the usual or reference varieties. The following steps are as follows:
- The SQS message invokes a Lambda perform. The Lambda perform is chargeable for processing the brand new type knowledge.
- The uncooked textual content is extracted by Amazon Textract utilizing a Lambda perform. The extracted uncooked textual content is then handed to Step 3B for additional processing and evaluation.
- Anthropic Claude 3 generates an inventory of questions from the customized type that must be in contrast with the usual from. Then each varieties and doc query lists are handed to Amazon Bedrock, which compares the extracted uncooked textual content with commonplace or reference uncooked textual content to establish variations and anomalies to offer insights and suggestions related to the healthcare trade by respective class. It then generates the ultimate output in JSON format for additional processing and dashboarding. The Amazon Bedrock API name and person immediate from Step 5 (Determine 1: Structure – Normal Type – Information Extraction & Storage) are reused for this step to generate a query record from the customized type.
We talk about Steps 4–6 within the subsequent part.
The next screenshot exhibits the output from Amazon Bedrock with an inventory of questions from the customized type.

Determine 4: Customized Type Pattern Query Listing
Last comparability utilizing Anthropic Claude 3 on Amazon Bedrock:
The next examples present the outcomes from the comparability train utilizing Amazon Bedrock with Anthropic Claude 3, displaying one which matched and one which didn’t match with the reference or commonplace type.
The next is the person immediate for varieties comparability:
The next is the primary name:
The next is the second name:
The next screenshot exhibits the questions matched with the reference type.

The next screenshot exhibits the questions that didn’t match with the reference type.


The steps from the previous structure diagram proceed as follows:
4. The SQS queue invokes a Lambda perform.
5. The Lambda perform invokes an AWS Glue job and screens for completion.
a. The AWS Glue job processes the ultimate JSON output from the Amazon Bedrock mannequin in tabular format for reporting.
6. Amazon QuickSight is used to create interactive dashboards and visualizations, permitting healthcare professionals to discover the evaluation, establish tendencies, and make knowledgeable selections primarily based on the insights offered by Anthropic Claude 3.
The next screenshot exhibits a pattern QuickSight dashboard.


Subsequent steps
Many healthcare suppliers are investing in digital know-how, equivalent to digital well being information (EHRs) and digital medical information (EMRs) to streamline knowledge assortment and storage, permitting acceptable employees to entry information for affected person care. Moreover, digitized well being information present the comfort of digital varieties and distant knowledge modifying for sufferers. Digital well being information provide a safer and accessible report system, decreasing knowledge loss and facilitating knowledge accuracy. Related options can provide capturing the information in these paper varieties into EHRs.
Conclusion
Generative AI options like Amazon Bedrock with Anthropic Claude 3 can considerably streamline the method of extracting and evaluating unstructured knowledge from paper varieties or pictures. By automating the extraction of type fields and questions, and intelligently evaluating them towards commonplace or reference varieties, this resolution provides a extra environment friendly and correct method to dealing with massive volumes of knowledge. The mixing of AWS companies like Lambda, Amazon S3, Amazon SQS, and QuickSight gives a scalable and sturdy structure for deploying this resolution. As healthcare organizations proceed to digitize their operations, such AI-powered options can play an important function in enhancing knowledge administration, sustaining compliance, and in the end enhancing affected person care via higher insights and decision-making.
Concerning the Authors
 Satish Sarapuri is a Sr. Information Architect, Information Lake at AWS. He helps enterprise-level prospects construct high-performance, extremely obtainable, cost-effective, resilient, and safe generative AI, knowledge mesh, knowledge lake, and analytics platform options on AWS, via which prospects could make data-driven selections to achieve impactful outcomes for his or her enterprise and assist them on their digital and knowledge transformation journey. In his spare time, he enjoys spending time together with his household and taking part in tennis.
Satish Sarapuri is a Sr. Information Architect, Information Lake at AWS. He helps enterprise-level prospects construct high-performance, extremely obtainable, cost-effective, resilient, and safe generative AI, knowledge mesh, knowledge lake, and analytics platform options on AWS, via which prospects could make data-driven selections to achieve impactful outcomes for his or her enterprise and assist them on their digital and knowledge transformation journey. In his spare time, he enjoys spending time together with his household and taking part in tennis.
 Harpreet Cheema is a Machine Studying Engineer on the AWS Generative AI Innovation Heart. He’s very passionate within the discipline of machine studying and in tackling data-oriented issues. In his function, he focuses on growing and delivering machine studying centered options for patrons throughout completely different domains.
Harpreet Cheema is a Machine Studying Engineer on the AWS Generative AI Innovation Heart. He’s very passionate within the discipline of machine studying and in tackling data-oriented issues. In his function, he focuses on growing and delivering machine studying centered options for patrons throughout completely different domains.
 Deborah Devadason is a Senior Advisory Marketing consultant within the Skilled Service staff at Amazon Net Providers. She is a results-driven and passionate Information Technique specialist with over 25 years of consulting expertise throughout the globe in a number of industries. She leverages her experience to unravel advanced issues and speed up business-focused journeys, thereby making a stronger spine for the digital and knowledge transformation journey.
Deborah Devadason is a Senior Advisory Marketing consultant within the Skilled Service staff at Amazon Net Providers. She is a results-driven and passionate Information Technique specialist with over 25 years of consulting expertise throughout the globe in a number of industries. She leverages her experience to unravel advanced issues and speed up business-focused journeys, thereby making a stronger spine for the digital and knowledge transformation journey.





