Qwen2-Audio Launched: A Revolutionary Audio-Language Mannequin Overcoming Advanced Audio Challenges with Unmatched Precision and Versatile Interplay Capabilities
Audio, as a medium, holds immense potential for conveying advanced info, making it important for creating programs that may precisely interpret & reply to audio inputs. The sector goals to create fashions that may comprehend a variety of sounds, from spoken language to environmental noise, and use this understanding to facilitate extra pure interactions between people & machines. These developments are key to pushing the boundaries of Synthetic Common Intelligence (AGI), the place machines not solely course of audio but in addition derive which means and context from it.
One of many main challenges on this area is the event of programs able to dealing with the varied nature of audio alerts in real-world situations. Conventional fashions usually fall brief when recognizing and responding to advanced audio inputs, resembling overlapping sounds, multi-speaker environments, and blended audio codecs. The issue is exacerbated when these programs are anticipated to carry out with out in depth task-specific fine-tuning. This limitation has pushed researchers to discover new methodologies that may higher equip fashions to cope with the unpredictability and complexity of real-world audio knowledge, thus enhancing their capacity to comply with directions and reply precisely in varied contexts.
Traditionally, audio-language fashions have relied on hierarchical tagging programs and complex pre-training processes. These fashions, resembling Whisper and SpeechT5, have been instrumental in advancing the sphere however require important fine-tuning to carry out properly on particular duties. Whisper-large-v3, as an example, is understood for its zero-shot analysis capabilities on sure datasets, however it struggles with duties that require understanding past easy speech recognition. Regardless of enhancements, these fashions have proven limitations in situations that demand nuanced interpretation of multi-modal audio knowledge, resembling simultaneous speech, music, and environmental sounds.
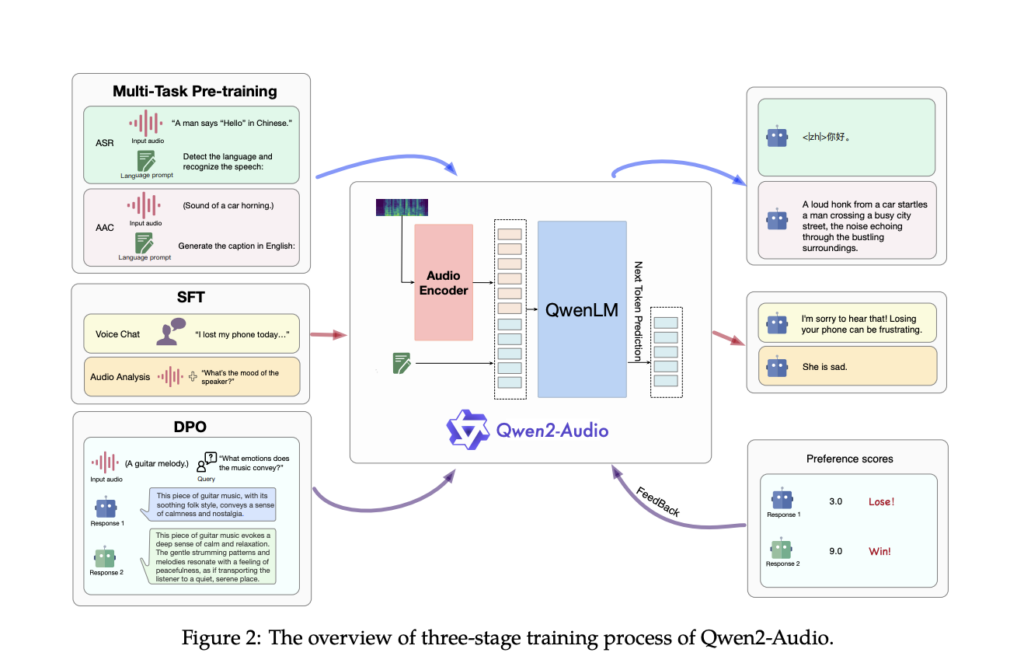
Researchers at Qwen Staff, Alibaba Group launched Qwen2-Audio, a complicated large-scale audio-language mannequin designed to course of and reply to advanced audio alerts with out requiring task-specific fine-tuning. Qwen2-Audio distinguishes itself by simplifying the pre-training course of utilizing pure language prompts as a substitute of hierarchical tags, considerably increasing the mannequin’s knowledge quantity and enhancing its instruction-following capabilities. The mannequin operates in two major modes: Voice Chat and Audio Evaluation, permitting it to interact in free-form voice interactions or analyze varied kinds of audio knowledge primarily based on person directions. The twin-mode performance ensures that Qwen2-Audio seamlessly transitions between duties with out separate system prompts.
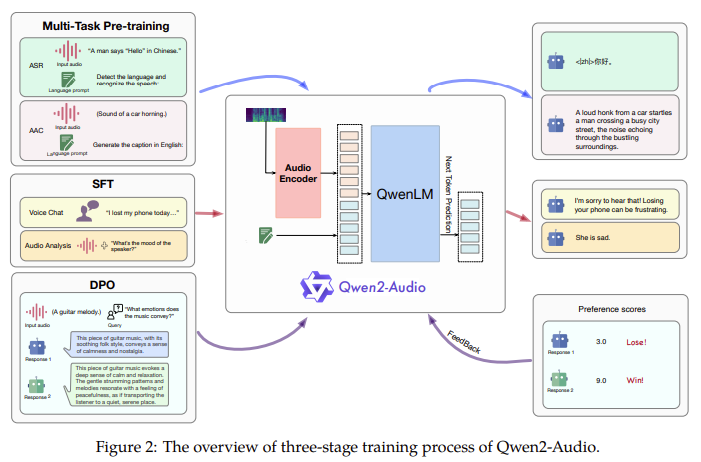
The structure of Qwen2-Audio integrates a classy audio encoder, initialized primarily based on the Whisper-large-v3 mannequin, with the Qwen-7B massive language mannequin as its core part. The coaching course of includes changing uncooked audio waveforms into 128-channel mel-spectrograms, that are then processed utilizing a window measurement of 25ms and a hop measurement of 10ms. The ensuing knowledge is handed by a pooling layer, decreasing the size of the audio illustration and guaranteeing that every body corresponds to roughly 40ms of the unique audio sign. With 8.2 billion parameters, Qwen2-Audio can deal with varied audio inputs, from easy speech to advanced, multi-modal audio environments.
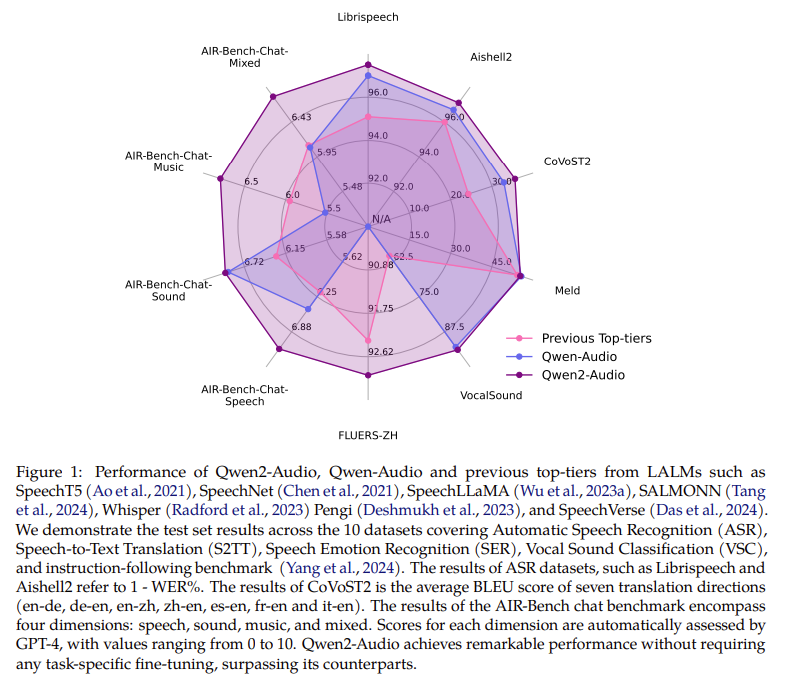
Efficiency evaluations reveal that Qwen2-Audio excels throughout varied benchmarks, outperforming earlier fashions in duties resembling Automated Speech Recognition (ASR), Speech-to-Textual content Translation (S2TT), and Speech Emotion Recognition (SER). The mannequin achieved a Phrase Error Fee (WER) of 1.6% on the Librispeech test-clean dataset and three.6% on the test-other dataset, considerably bettering over earlier fashions like Whisper-large-v3. In speech-to-text translation, Qwen2-Audio outperformed baselines throughout seven translation instructions, attaining a BLEU rating of 45.2 within the en-de path and 24.4 within the zh-en path. Moreover, within the Vocal Sound Classification (VSC) activity, Qwen2-Audio attained an accuracy of 93.92%, showcasing its strong efficiency throughout numerous audio duties.

In conclusion, Qwen2-Audio, by simplifying the pre-training course of, increasing knowledge quantity, and integrating superior structure, the mannequin addresses the restrictions of its predecessors and units a brand new customary for audio interplay programs. Its capacity to carry out properly throughout varied duties with out requiring task-specific fine-tuning highlights its potential to revolutionize how machines course of and work together with audio alerts.
Take a look at the Paper, Model Card, and Demo. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our newsletter..
Don’t Overlook to hitch our 48k+ ML SubReddit
Discover Upcoming AI Webinars here
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.





