Optimizing Your LLM for Efficiency and Scalability

Picture by Writer
Massive language fashions or LLMs have emerged as a driving catalyst in pure language processing. Their use-cases vary from chatbots and digital assistants to content material era and translation companies. Nonetheless, they’ve turn out to be one of many fastest-growing fields within the tech world – and we will discover them all over.
As the necessity for extra highly effective language fashions grows, so does the necessity for efficient optimization methods.
Nonetheless,many pure questions emerge:
How you can enhance their data?
How you can enhance their common efficiency?
How you can scale these fashions up?
The insightful presentation titled “A Survey of Methods for Maximizing LLM Efficiency” by John Allard and Colin Jarvis from OpenAI DevDay tried to reply these questions. If you happen to missed the occasion, you possibly can catch the speak on YouTube.
This presentation supplied a wonderful overview of varied methods and finest practices for enhancing the efficiency of your LLM functions. This text goals to summarize one of the best methods to enhance each the efficiency and scalability of our AI-powered options.
Understanding the Fundamentals
LLMs are refined algorithms engineered to know, analyze, and produce coherent and contextually applicable textual content. They obtain this by means of intensive coaching on huge quantities of linguistic knowledge protecting numerous subjects, dialects, and kinds. Thus, they will perceive how human-language works.
Nonetheless, when integrating these fashions in complicated functions, there are some key challenges to think about:
Key Challenges in Optimizing LLMs
- LLMs Accuracy: Making certain that LLMs output is correct and dependable info with out hallucinations.
- Useful resource Consumption: LLMs require substantial computational sources, together with GPU energy, reminiscence and massive infrastructure.
- Latency: Actual-time functions demand low latency, which will be difficult given the scale and complexity of LLMs.
- Scalability: As consumer demand grows, making certain the mannequin can deal with elevated load with out degradation in efficiency is essential.
Methods for a Higher Efficiency
The primary query is about “How you can enhance their data?”
Creating {a partially} useful LLM demo is comparatively straightforward, however refining it for manufacturing requires iterative enhancements. LLMs might need assistance with duties needing deep data of particular knowledge, techniques, and processes, or exact habits.
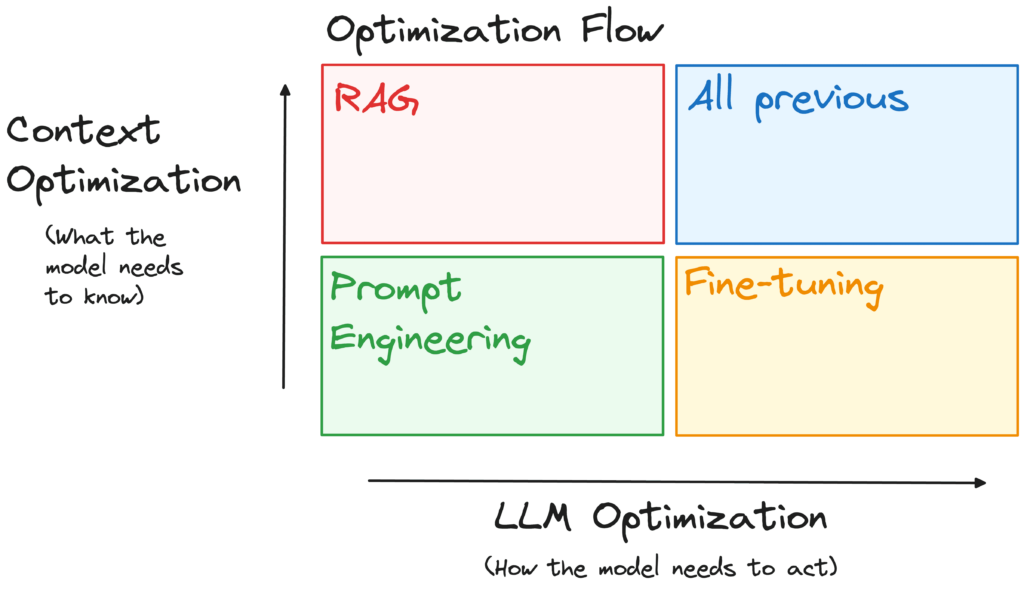
Groups use immediate engineering, retrieval augmentation, and fine-tuning to handle this. A typical mistake is to imagine that this course of is linear and ought to be adopted in a selected order. As a substitute, it’s simpler to method it alongside two axes, relying on the character of the problems:
- Context Optimization: Are the issues as a result of mannequin missing entry to the suitable info or data?
- LLM Optimization: Is the mannequin failing to generate the right output, corresponding to being inaccurate or not adhering to a desired type or format?

Picture by Writer
To deal with these challenges, three main instruments will be employed, every serving a novel function within the optimization course of:
Immediate Engineering
Tailoring the prompts to information the mannequin’s responses. As an example, refining a customer support bot’s prompts to make sure it constantly supplies useful and well mannered responses.
Retrieval-Augmented Technology (RAG)
Enhancing the mannequin’s context understanding by means of exterior knowledge. For instance, integrating a medical chatbot with a database of the most recent analysis papers to supply correct and up-to-date medical recommendation.
Nice-Tuning
Modifying the bottom mannequin to higher go well with particular duties. Identical to fine-tuning a authorized doc evaluation device utilizing a dataset of authorized texts to enhance its accuracy in summarizing authorized paperwork.
The method is very iterative, and never each method will work in your particular downside. Nonetheless, many methods are additive. While you discover a answer that works, you possibly can mix it with different efficiency enhancements to realize optimum outcomes.
Methods for an Optimized Efficiency
The second query is about “How you can enhance their common efficiency?”
After having an correct mannequin, a second regarding level is the Inference time. Inference is the method the place a educated language mannequin, like GPT-3, generates responses to prompts or questions in real-world functions (like a chatbot).
It’s a essential stage the place fashions are put to the take a look at, producing predictions and responses in sensible eventualities. For giant LLMs like GPT-3, the computational calls for are monumental, making optimization throughout inference important.
Take into account a mannequin like GPT-3, which has 175 billion parameters, equal to 700GB of float32 knowledge. This dimension, coupled with activation necessities, necessitates important RAM. This is the reason Operating GPT-3 with out optimization would require an in depth setup.
Some methods can be utilized to scale back the quantity of sources required to execute such functions:
Mannequin Pruning
It entails trimming non-essential parameters, making certain solely the essential ones to efficiency stay. This will drastically scale back the mannequin’s dimension with out considerably compromising its accuracy.
Which suggests a major lower within the computational load whereas nonetheless having the identical accuracy. You can find easy-to-implement pruning code in the following GitHub.
Quantization
It’s a mannequin compression method that converts the weights of a LLM from high-precision variables to lower-precision ones. This implies we will scale back the 32-bit floating-point numbers to decrease precision codecs like 16-bit or 8-bit, that are extra memory-efficient. This will drastically scale back the reminiscence footprint and enhance inference velocity.
LLMs will be simply loaded in a quantized method utilizing HuggingFace and bitsandbytes. This enables us to execute and fine-tune LLMs in lower-power sources.
from transformers import AutoModelForSequenceClassification, AutoTokenizer
import bitsandbytes as bnb
# Quantize the mannequin utilizing bitsandbytes
quantized_model = bnb.nn.quantization.Quantize(
mannequin,
quantization_dtype=bnb.nn.quantization.quantization_dtype.int8
)
Distillation
It’s the course of of coaching a smaller mannequin (pupil) to imitate the efficiency of a bigger mannequin (additionally known as a instructor). This course of entails coaching the coed mannequin to imitate the instructor’s predictions, utilizing a mix of the instructor’s output logits and the true labels. By doing so, we will a obtain comparable efficiency with a fraction of the useful resource requirement.
The concept is to switch the data of bigger fashions to smaller ones with less complicated structure. One of the vital identified examples is Distilbert.
This mannequin is the results of mimicking the efficiency of Bert. It’s a smaller model of BERT that retains 97% of its language understanding capabilities whereas being 60% quicker and 40% smaller in dimension.
Methods for Scalability
The third query is about “How you can scale these fashions up?”
This step is commonly essential. An operational system can behave very otherwise when utilized by a handful of customers versus when it scales as much as accommodate intensive utilization. Listed below are some methods to handle this problem:
Load-balancing
This method distributes incoming requests effectively, making certain optimum use of computational sources and dynamic response to demand fluctuations. As an example, to supply a widely-used service like ChatGPT throughout completely different international locations, it’s higher to deploy a number of situations of the identical mannequin.
Efficient load-balancing methods embrace:
Horizontal Scaling: Add extra mannequin situations to deal with elevated load. Use container orchestration platforms like Kubernetes to handle these situations throughout completely different nodes.
Vertical Scaling: Improve current machine sources, corresponding to CPU and reminiscence.
Sharding
Mannequin sharding distributes segments of a mannequin throughout a number of gadgets or nodes, enabling parallel processing and considerably decreasing latency. Totally Sharded Information Parallelism (FSDP) provides the important thing benefit of using a various array of {hardware}, corresponding to GPUs, TPUs, and different specialised gadgets in a number of clusters.
This flexibility permits organizations and people to optimize their {hardware} sources in accordance with their particular wants and finances.
Caching
Implementing a caching mechanism reduces the load in your LLM by storing incessantly accessed outcomes, which is particularly useful for functions with repetitive queries. Caching these frequent queries can considerably save computational sources by eliminating the necessity to repeatedly course of the identical requests over.
Moreover, batch processing can optimize useful resource utilization by grouping comparable duties.
Conclusion
For these constructing functions reliant on LLMs, the methods mentioned listed below are essential for maximizing the potential of this transformative know-how. Mastering and successfully making use of methods to a extra correct output of our mannequin, optimize its efficiency, and permitting scaling up are important steps in evolving from a promising prototype to a strong, production-ready mannequin.
To totally perceive these methods, I extremely advocate getting a deeper element and beginning to experiment with them in your LLM functions for optimum outcomes.
Josep Ferrer is an analytics engineer from Barcelona. He graduated in physics engineering and is presently working within the knowledge science discipline utilized to human mobility. He’s a part-time content material creator centered on knowledge science and know-how. Josep writes on all issues AI, protecting the appliance of the continuing explosion within the discipline.




