Harness the ability of AI and ML utilizing Splunk and Amazon SageMaker Canvas

As the size and complexity of information dealt with by organizations improve, conventional rules-based approaches to analyzing the info alone are now not viable. As an alternative, organizations are more and more seeking to make the most of transformative applied sciences like machine learning (ML) and artificial intelligence (AI) to ship progressive merchandise, enhance outcomes, and acquire operational efficiencies at scale. Moreover, the democratization of AI and ML via AWS and AWS Accomplice options is accelerating its adoption throughout all industries.
For instance, a health-tech firm could also be seeking to enhance affected person care by predicting the likelihood that an aged affected person might turn into hospitalized by analyzing each medical and non-clinical information. This may enable them to intervene early, personalize the supply of care, and take advantage of environment friendly use of current assets, reminiscent of hospital mattress capability and nursing employees.
AWS gives the broadest and deepest set of AI and ML services and supporting infrastructure, reminiscent of Amazon SageMaker and Amazon Bedrock, that can assist you at each stage of your AI/ML adoption journey, together with adoption of generative AI. Splunk, an AWS Accomplice, gives a unified safety and observability platform constructed for velocity and scale.
As the variety and quantity of information will increase, it’s critical to grasp how they are often harnessed at scale through the use of complementary capabilities of the 2 platforms. For organizations trying past using out-of-the-box Splunk AI/ML features, this submit explores how Amazon SageMaker Canvas, a no-code ML improvement service, can be utilized at the side of information collected in Splunk to drive actionable insights. We additionally exhibit easy methods to use the generative AI capabilities of SageMaker Canvas to hurry up your information exploration and enable you construct higher ML fashions.
Use case overview
On this instance, a health-tech firm providing distant affected person monitoring is amassing operational information from wearables utilizing Splunk. These system metrics and logs are ingested into and saved in a Splunk index, a repository of incoming information. Inside Splunk, this information is used to meet context-specific safety and observability use instances by Splunk customers, reminiscent of monitoring the safety posture and uptime of units and performing proactive upkeep of the fleet.
Individually, the corporate makes use of AWS information companies, reminiscent of Amazon Simple Storage Service (Amazon S3), to retailer information associated to sufferers, reminiscent of affected person data, system possession particulars, and medical telemetry information obtained from the wearables. These might embody exports from buyer relationship administration (CRM), configuration administration database (CMDB), and digital well being report (EHR) methods. On this instance, they’ve entry to an extract of affected person data and hospital admission information that reside in an S3 bucket.
The next desk illustrates the totally different information explored on this instance use case.
|
Description |
Characteristic Identify |
Storage |
Instance Supply |
|
|
Age of affected person |
|
AWS |
EHR |
|
|
Items of alcohol consumed by affected person each week |
|
AWS |
EHR |
|
|
Tobacco utilization by affected person per week |
|
AWS |
EHR |
|
|
Common systolic blood strain of affected person |
|
AWS |
Wearables |
|
|
Common diastolic blood strain of affected person |
|
AWS |
Wearables |
|
|
Common resting coronary heart fee of affected person |
|
AWS |
Wearables |
|
|
Affected person admission report |
|
AWS |
EHR |
|
|
Variety of days the system has been lively over a interval |
|
Splunk |
Wearables |
|
|
Common finish of the day battery stage over a interval |
|
Splunk |
Wearables |
|
This submit describes an method with two key elements:
- The 2 information sources are saved alongside one another utilizing a typical AWS information engineering pipeline. Information is introduced to the personas that want entry utilizing a unified interface.
- An ML mannequin to foretell hospital admissions (
admitted) is developed utilizing the mixed dataset and SageMaker Canvas. Professionals with no background in ML are empowered to investigate the info utilizing no-code tooling.
The answer permits customized ML fashions to be developed from a broader number of medical and non-clinical information sources to cater for various real-life situations. For instance, it may be used to reply questions reminiscent of “If sufferers will be inclined to have their wearables turned off and there’s no medical telemetry information out there, can the chance that they’re hospitalized nonetheless be precisely predicted?”
AWS information engineering pipeline
The adaptable method detailed on this submit begins with an automatic information engineering pipeline to make information saved in Splunk out there to a variety of personas, together with enterprise intelligence (BI) analysts, information scientists, and ML practitioners, via a SQL interface. That is achieved through the use of the pipeline to switch information from a Splunk index into an S3 bucket, the place it is going to be cataloged.
The method is proven within the following diagram.
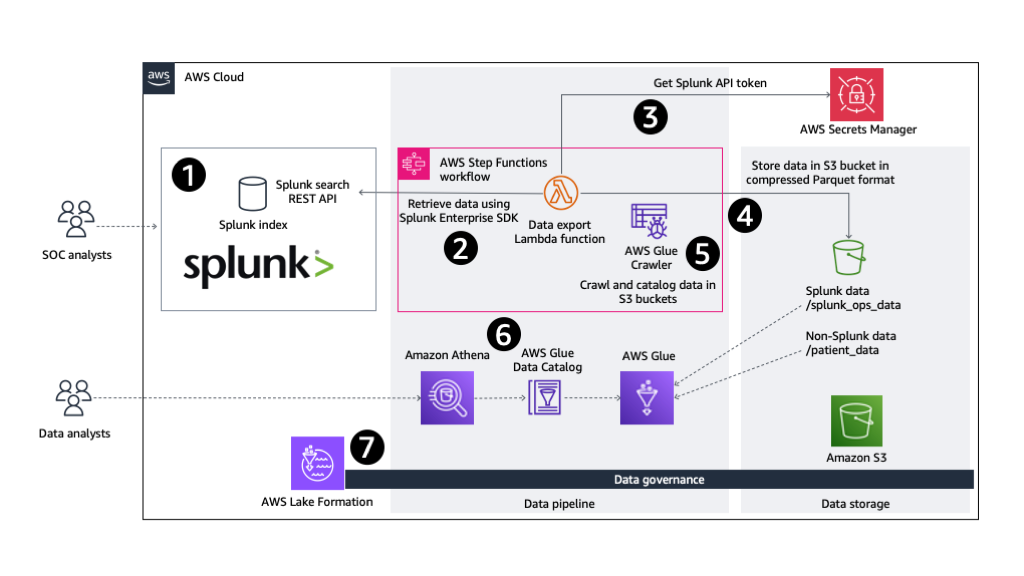
Determine 1: Structure overview of information engineering pipeline
The automated AWS information pipeline consists of the next steps:
- Information from wearables is saved in a Splunk index the place it may be queried by customers, reminiscent of safety operations heart (SOC) analysts, utilizing the Splunk search processing language (SPL). Spunk’s out-of-the-box AI/ML capabilities, such because the Splunk Machine Learning Toolkit (Splunk MLTK) and purpose-built fashions for safety and observability use instances (for instance, for anomaly detection and forecasting), may be utilized contained in the Splunk Platform. Utilizing these Splunk ML options means that you can derive contextualized insights shortly with out the necessity for added AWS infrastructure or abilities.
- Some organizations might look to develop customized, differentiated ML fashions, or wish to construct AI-enabled purposes utilizing AWS companies for his or her particular use instances. To facilitate this, an automatic information engineering pipeline is constructed utilizing AWS Step Functions. The Step Features state machine is configured with an AWS Lambda function to retrieve information from the Splunk index utilizing the Splunk Enterprise SDK for Python. The SPL question requested via this REST API name is scoped to solely retrieve the info of curiosity.
-
- Lambda helps container images. This answer makes use of a Lambda operate that runs a Docker container picture. This permits bigger information manipulation libraries, reminiscent of pandas and PyArrow, to be included within the deployment bundle.
- If a big quantity of information is being exported, the code might must run for longer than the utmost doable length, or require extra reminiscence than supported by Lambda features. If that is so, Step Features may be configured to directly run a container task on Amazon Elastic Container Service (Amazon ECS).
-
- For authentication and authorization, the Spunk bearer token is securely retrieved from AWS Secrets Manager by the Lambda operate earlier than calling the Splunk
/searchREST API endpoint. This bearer authentication token lets customers entry the REST endpoint utilizing an authenticated id. - Information retrieved by the Lambda operate is reworked (if required) and uploaded to the designated S3 bucket alongside different datasets. This information is partitioned and compressed, and saved in storage and performance-optimized Apache Parquet file format.
- As its final step, the Step Features state machine runs an AWS Glue crawler to deduce the schema of the Splunk information residing within the S3 bucket, and catalogs it for wider consumption as tables utilizing the AWS Glue Data Catalog.
- Wearable information exported from Splunk is now out there to customers and purposes via the Information Catalog as a desk. Analytics tooling reminiscent of Amazon Athena can now be used to question the info utilizing SQL.
- As information saved in your AWS surroundings grows, it’s important to have centralized governance in place. AWS Lake Formation means that you can simplify permissions administration and information sharing to take care of safety and compliance.
An AWS Serverless Application Model (AWS SAM) template is accessible to deploy all AWS assets required by this answer. This template may be discovered within the accompanying GitHub repository.
Seek advice from the README file for required conditions, deployment steps, and the method to check the info engineering pipeline answer.
AWS AI/ML analytics workflow
After the info engineering pipeline’s Step Features state machine efficiently completes and wearables information from Splunk is accessible alongside affected person healthcare information utilizing Athena, we use an instance method based mostly on SageMaker Canvas to drive actionable insights.
SageMaker Canvas is a no-code visible interface that empowers you to organize information, construct, and deploy extremely correct ML fashions, streamlining the end-to-end ML lifecycle in a unified surroundings. You may put together and remodel information via point-and-click interactions and pure language, powered by Amazon SageMaker Data Wrangler. It’s also possible to faucet into the ability of automated machine studying (AutoML) and robotically construct customized ML fashions for regression, classification, time sequence forecasting, pure language processing, and pc imaginative and prescient, supported by Amazon SageMaker Autopilot.
On this instance, we use the service to categorise whether or not a affected person is prone to be admitted to a hospital over the subsequent 30 days based mostly on the mixed dataset.
The method is proven within the following diagram.
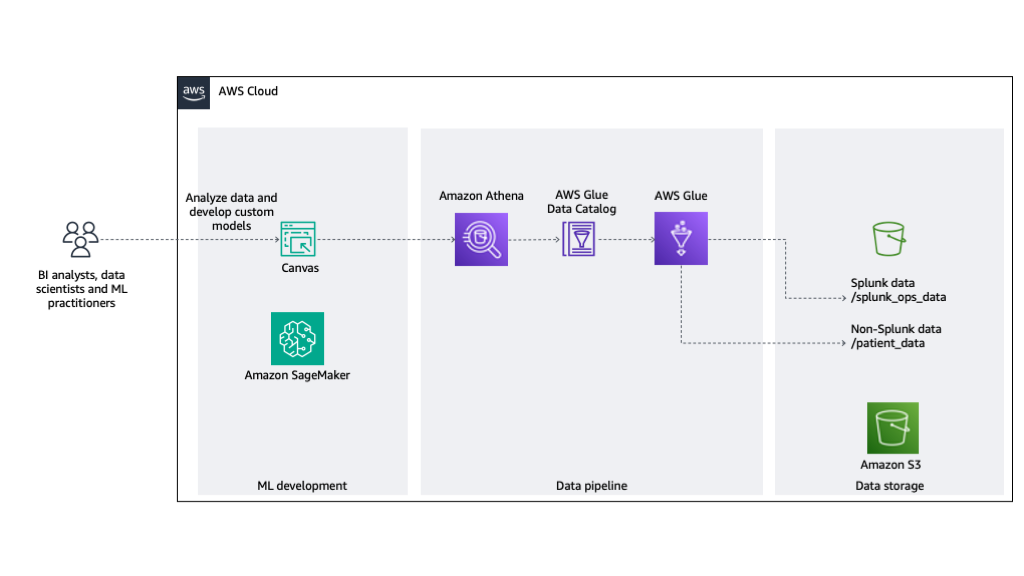
Determine 2: Structure overview of ML improvement
The answer consists of the next steps:
- An AWS Glue crawler crawls the info saved in S3 bucket. The Information Catalog exposes this information discovered within the folder construction as tables.
- Athena gives a question engine to permit individuals and purposes to work together with the tables utilizing SQL.
- SageMaker Canvas makes use of Athena as a knowledge supply to permit the info saved within the tables for use for ML mannequin improvement.
Resolution overview
SageMaker Canvas means that you can construct a customized ML mannequin utilizing a dataset that you’ve imported. Within the following sections, we exhibit easy methods to create, discover, and remodel a pattern dataset, use pure language to question the info, test for information high quality, create further steps for the info stream, and construct, check, and deploy an ML mannequin.
Conditions
Earlier than continuing, check with Getting started with using Amazon SageMaker Canvas to ensure you have the required conditions in place. Particularly, validate that the AWS Identity and Access Management (IAM) position your SageMaker area is utilizing has a policy attached with enough permissions to entry Athena, AWS Glue, and Amazon S3 assets.
Create the dataset
SageMaker Canvas helps Athena as a data source. Information from wearables and affected person healthcare information residing throughout your S3 bucket is accessed utilizing Athena and the Information Catalog. This permits this tabular information to be straight imported into SageMaker Canvas to begin your ML improvement.
To create your dataset, full the next steps:
- On the SageMaker Canvas console, select Information Wrangler within the navigation pane.
- On the Import and put together dropdown menu, select Tabular because the dataset kind to indicate that the imported information consists of rows and columns.
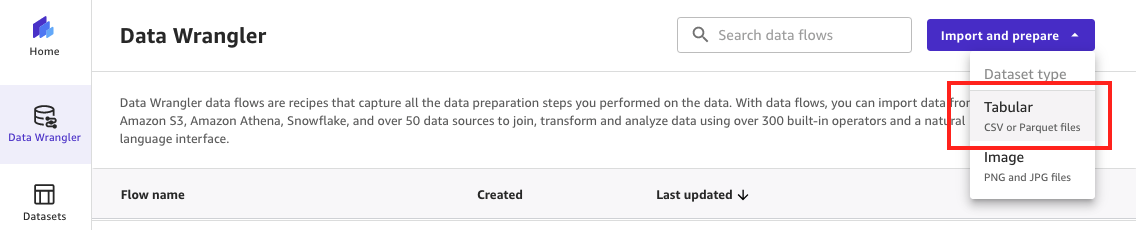
Determine 3: Importing tabular information utilizing SageMaker Information Wrangler
- For Choose a knowledge supply, select Athena.
On this web page, you will note your Information Catalog database and tables listed, named patient_data and splunk_ops_data.
- Be part of (inside be part of) the tables collectively utilizing the
user_idandidto create one overarching dataset that can be utilized throughout ML mannequin improvement. - Underneath Import settings, enter
unprocessed_datafor Dataset identify. - Select Import to finish the method.
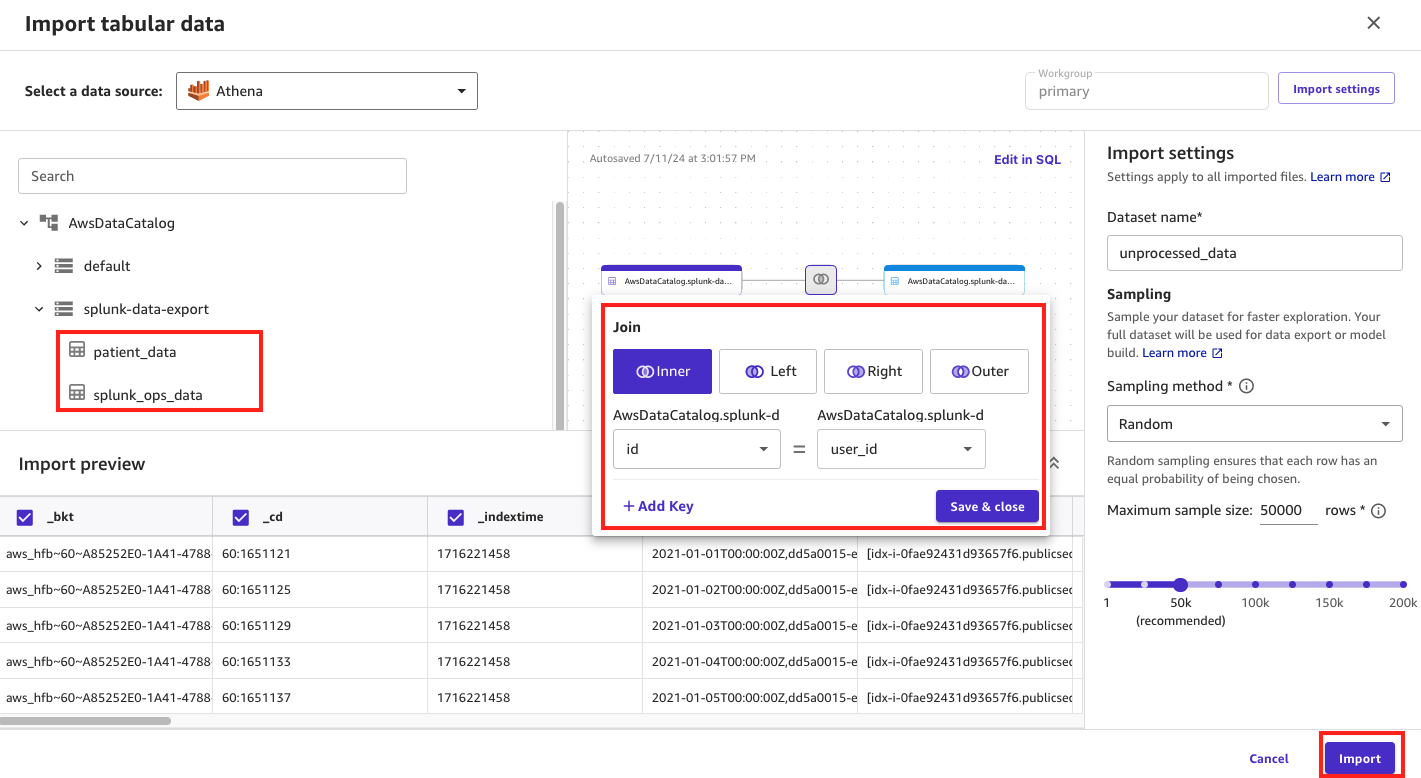
Determine 4: Becoming a member of information utilizing SageMaker Information Wrangler
The mixed dataset is now out there to discover and remodel utilizing SageMaker Information Wrangler.
Discover and remodel the dataset
SageMaker Information Wrangler lets you remodel and analyze the supply dataset via data flows whereas nonetheless sustaining a no-code method.
The earlier step robotically created a knowledge stream within the SageMaker Canvas console which we’ve renamed to data_prep_data_flow.stream. Moreover, two steps are robotically generated, as listed within the following desk.
|
Step |
Identify |
Description |
|
1 |
Athena Supply |
Units the |
|
2 |
Information sorts |
Units column sorts of |
Earlier than we create further remodel steps, let’s discover two SageMaker Canvas options that may assist us give attention to the correct actions.
Use pure language to question the info
SageMaker Information Wrangler additionally gives generative AI capabilities known as Chat for data prep powered by a big language mannequin (LLM). This function means that you can discover your information utilizing pure language with none background in ML or SQL. Moreover, any contextualized suggestions returned by the generative AI mannequin may be launched straight again into the info stream with out writing any code.
On this part, we current some instance prompts to exhibit this in motion. These examples have been chosen for instance the artwork of the doable. We advocate that you simply experiment with totally different prompts to achieve one of the best outcomes in your specific use instances.
Instance 1: Establish Splunk default fields
On this first instance, we wish to know whether or not there are Splunk default fields that we might doubtlessly exclude from our dataset previous to ML mannequin improvement.
- In SageMaker Information Wrangler, open your information stream.
- Select Step 2 Information sorts, and select Chat for information prep.
- Within the Chat for information prep pane, you possibly can enter prompts in pure language to discover and remodel the info. For instance:
On this instance, the generative AI LLM has appropriately recognized Splunk default fields that might be safely dropped from the dataset.
- Select Add to steps so as to add this recognized transformation to the info stream.
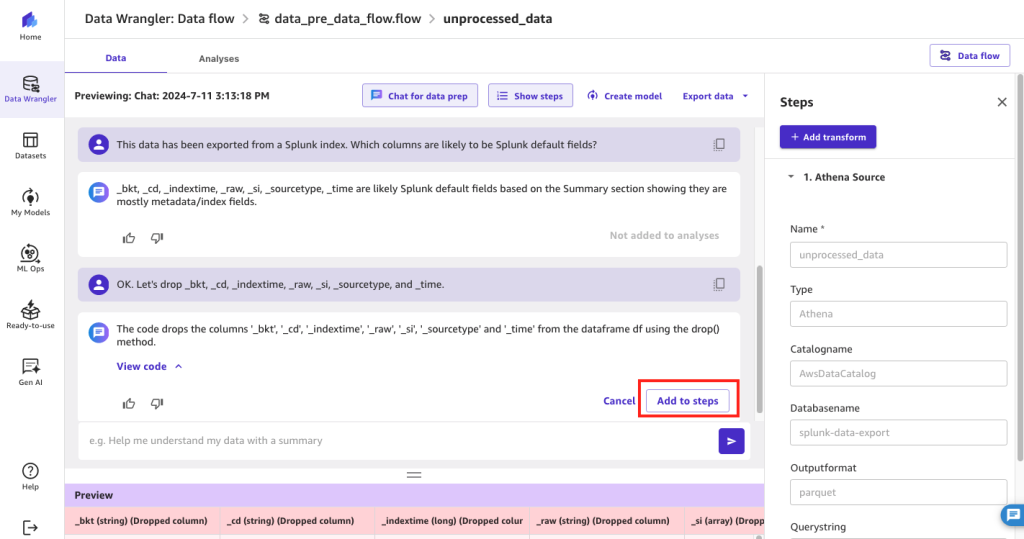
Determine 5: Utilizing SageMaker Information Wrangler’s chat for information prep to establish Splunk’s default fields
Instance 2: Establish further columns that might be dropped
We now wish to establish any additional columns that might be dropped with out being too particular about what we’re in search of. We wish the LLM to make the ideas based mostly on the info, and supply us with the rationale. For instance:
Along with the Splunk default fields recognized earlier, the generative AI mannequin is now proposing the removing of columns reminiscent of timestamp, punct, id, index, and linecount that don’t seem like conducive to ML mannequin improvement.
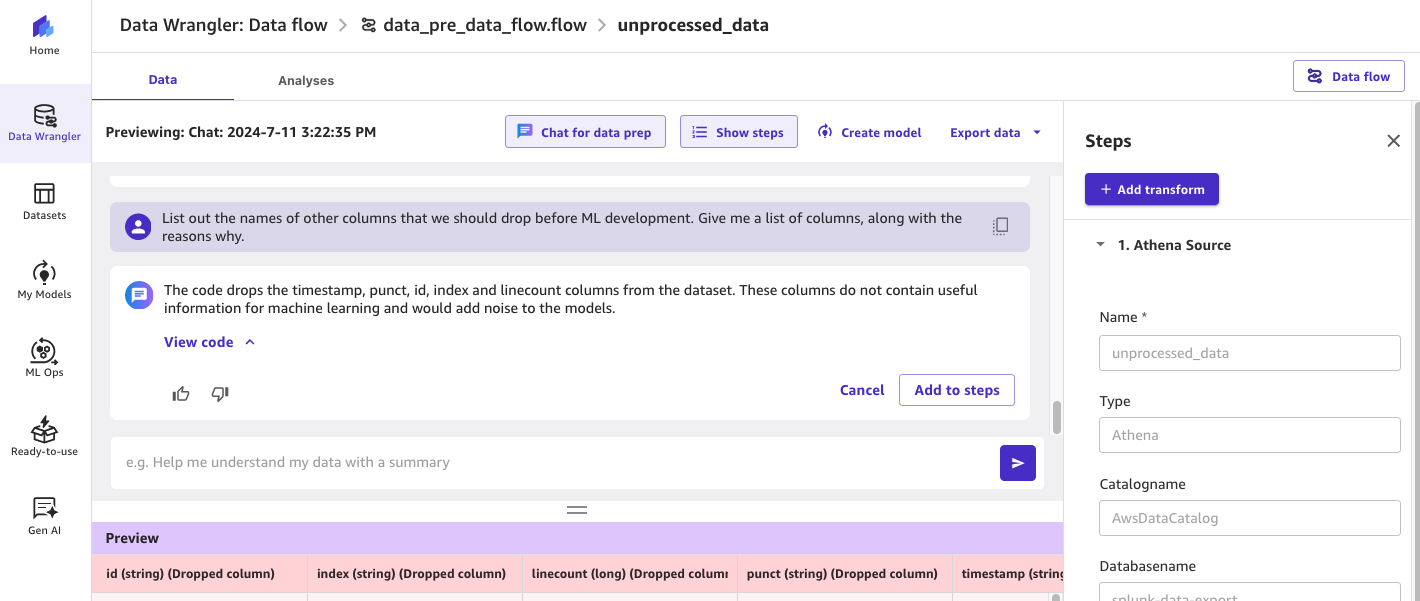
Determine 6: Utilizing SageMaker Information Wrangler’s chat for information prep to establish further fields that may be dropped
Instance 3: Calculate common age column in dataset
It’s also possible to use the generative AI mannequin to carry out Text2SQL duties in which you’ll merely ask questions of the info utilizing pure language. That is helpful if you wish to validate the content material of the dataset.
On this instance, we wish to know what the typical affected person age worth is throughout the dataset:
By increasing View code, you possibly can see what SQL statements the LLM has constructed utilizing its Text2SQL capabilities. This provides you full visibility into how the outcomes are being returned.

Determine 7: Utilizing SageMaker Information Wrangler’s chat for information prep to run SQL statements
Test for information high quality
SageMaker Canvas additionally gives exploratory data analysis (EDA) capabilities that let you acquire deeper insights into the info previous to the ML mannequin construct step. With EDA, you possibly can generate visualizations and analyses to validate whether or not you will have the correct information, and whether or not your ML mannequin construct is prone to yield outcomes which can be aligned to your group’s expectations.
Instance 1: Create a Information High quality and Insights Report
Full the next steps to create a Information High quality and Insights Report:
- Whereas within the information stream step, select the Analyses tab.
- For Evaluation kind, select Information High quality and Insights Report.
- For Goal column, select
admitted. - For Drawback kind, select Classification.
This performs an evaluation of the info that you’ve and gives data such because the variety of lacking values and outliers.
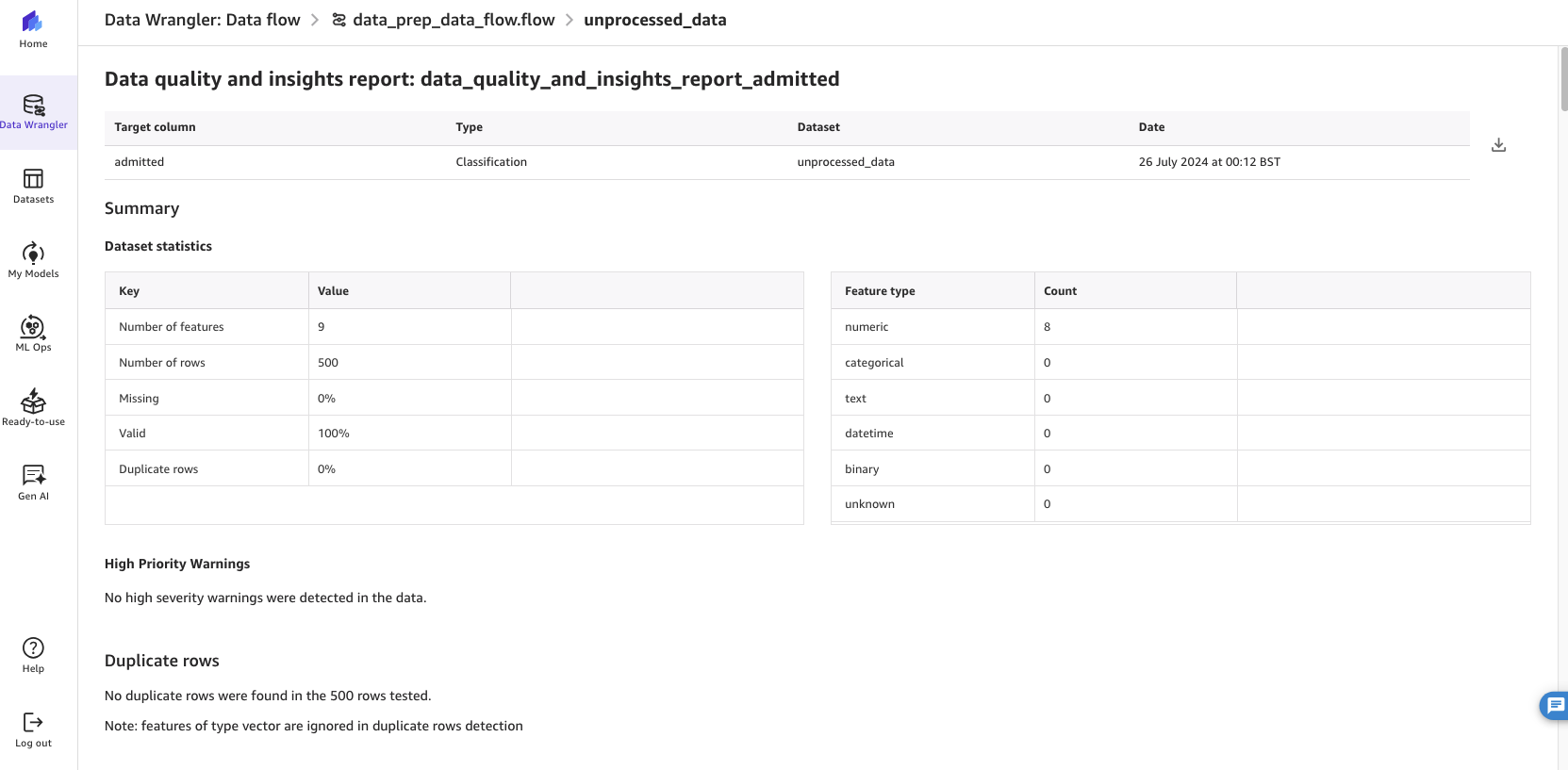
Determine 8: Operating SageMaker Information Wrangler’s information high quality and insights report
Seek advice from Get Insights On Data and Data Quality for particulars on easy methods to interpret the outcomes of this report.
Instance 2: Create a Fast Mannequin
On this second instance, select Fast Mannequin for Evaluation kind and for Goal column, select admitted. The Fast Mannequin estimates the anticipated predicted high quality of the mannequin.
By operating the evaluation, the estimated F1 score (a measure of predictive efficiency) of the mannequin and have significance scores are displayed.
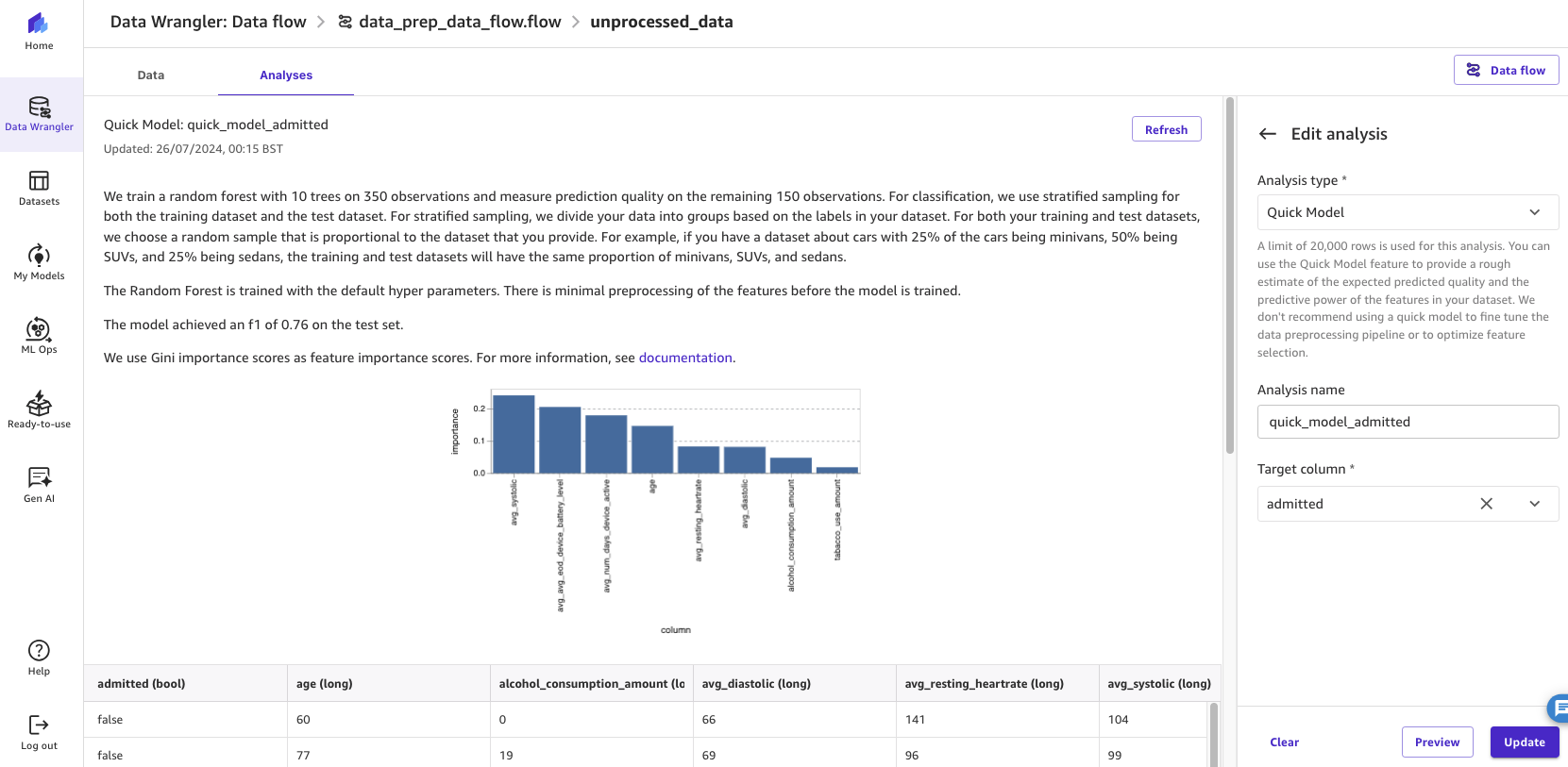
Determine 9: Operating SageMaker Information Wrangler’s fast mannequin function to evaluate the potential accuracy of the mannequin
SageMaker Canvas helps many different analysis types. By reviewing these analyses prematurely of your ML mannequin construct, you possibly can proceed to engineer the info and options to achieve enough confidence that the ML mannequin will meet your online business targets.
Create further steps within the information stream
On this instance, we’ve determined to replace our data_prep_data_flow.stream information stream to implement further transformations. The next desk summarizes these steps.
|
Step |
Rework |
Description |
|
3 |
Chat for information prep |
Removes Splunk default fields recognized. |
|
4 |
Chat for information prep |
Removes further fields recognized as being unhelpful to ML mannequin improvement. |
|
5 |
Group by |
Teams collectively the rows by user_id and calculates a median |
|
6 |
Drop column (handle columns) |
Drops remaining columns which can be pointless for our ML improvement, reminiscent of columns with excessive cardinality (for instance, |
|
7 |
Parse column as kind |
Converts numerical worth sorts, for instance from |
|
8 |
Parse column as kind |
Converts further columns that should be parsed (every column requires a separate step). |
|
9 |
Drop duplicates (handle rows) |
Drops duplicate rows to keep away from overfitting. |
To create a brand new remodel, view the info stream, then select Add remodel on the final step.
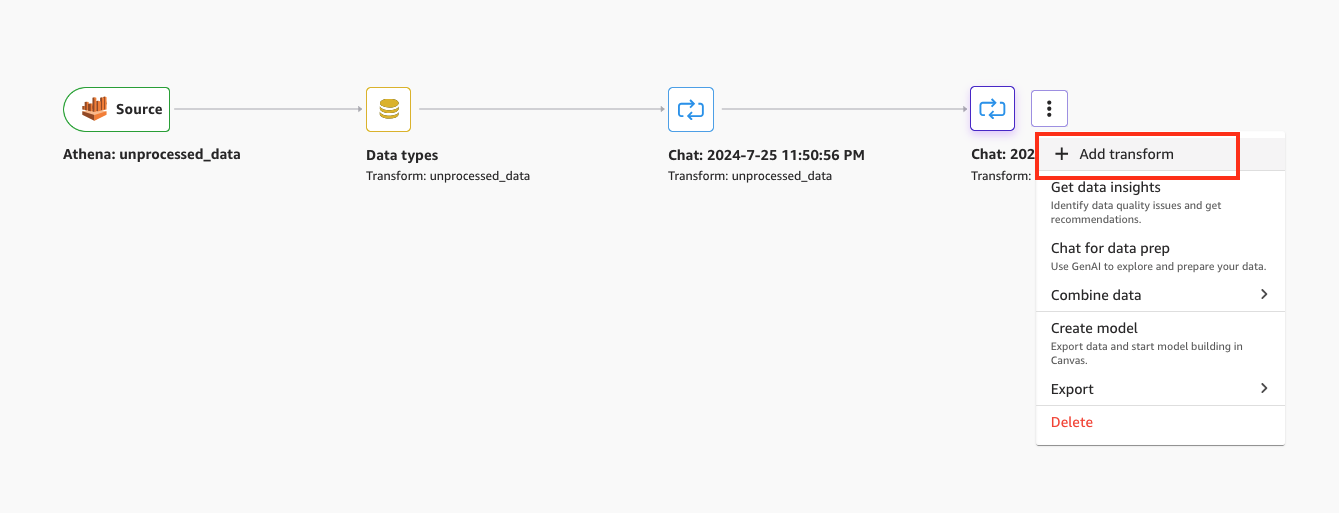
Determine 10: Utilizing SageMaker Information Wrangler so as to add a remodel to a knowledge stream
Select Add remodel, and proceed to decide on a remodel kind and its configuration.
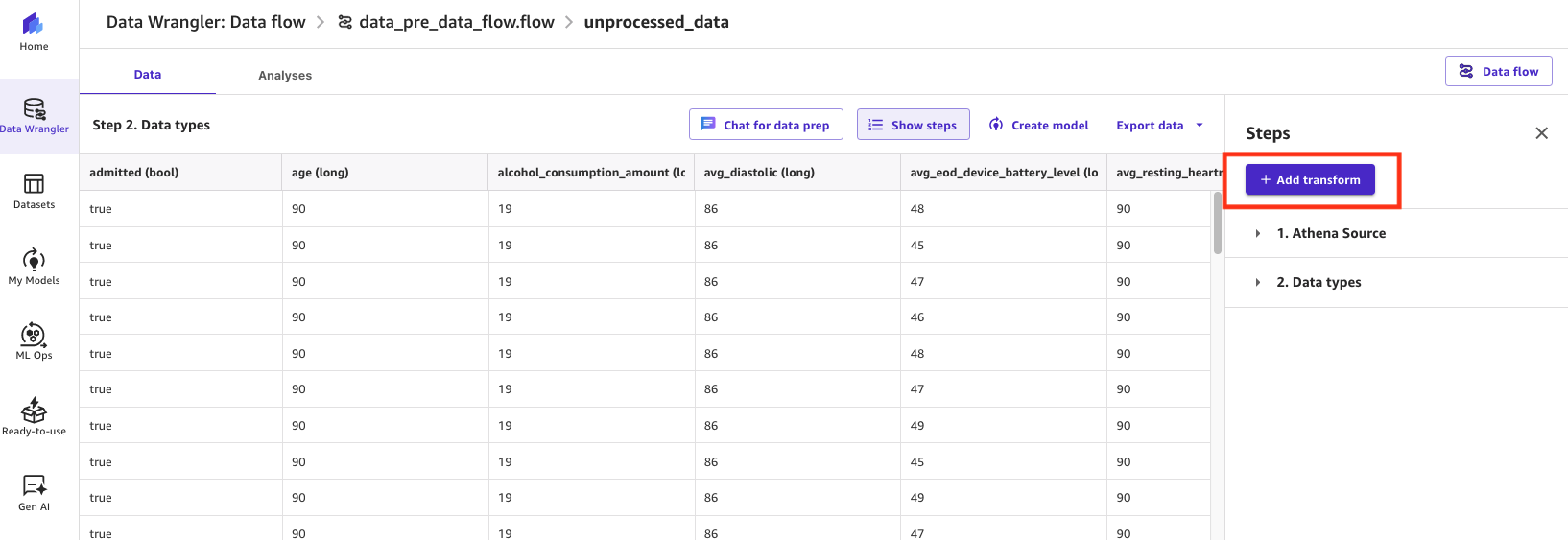
Determine 11: Utilizing SageMaker Information Wrangler so as to add a remodel to a knowledge stream
The next screenshot reveals our newly up to date end-to-end information stream that includes a number of steps. On this instance, we ran the analyses on the finish of the info stream.
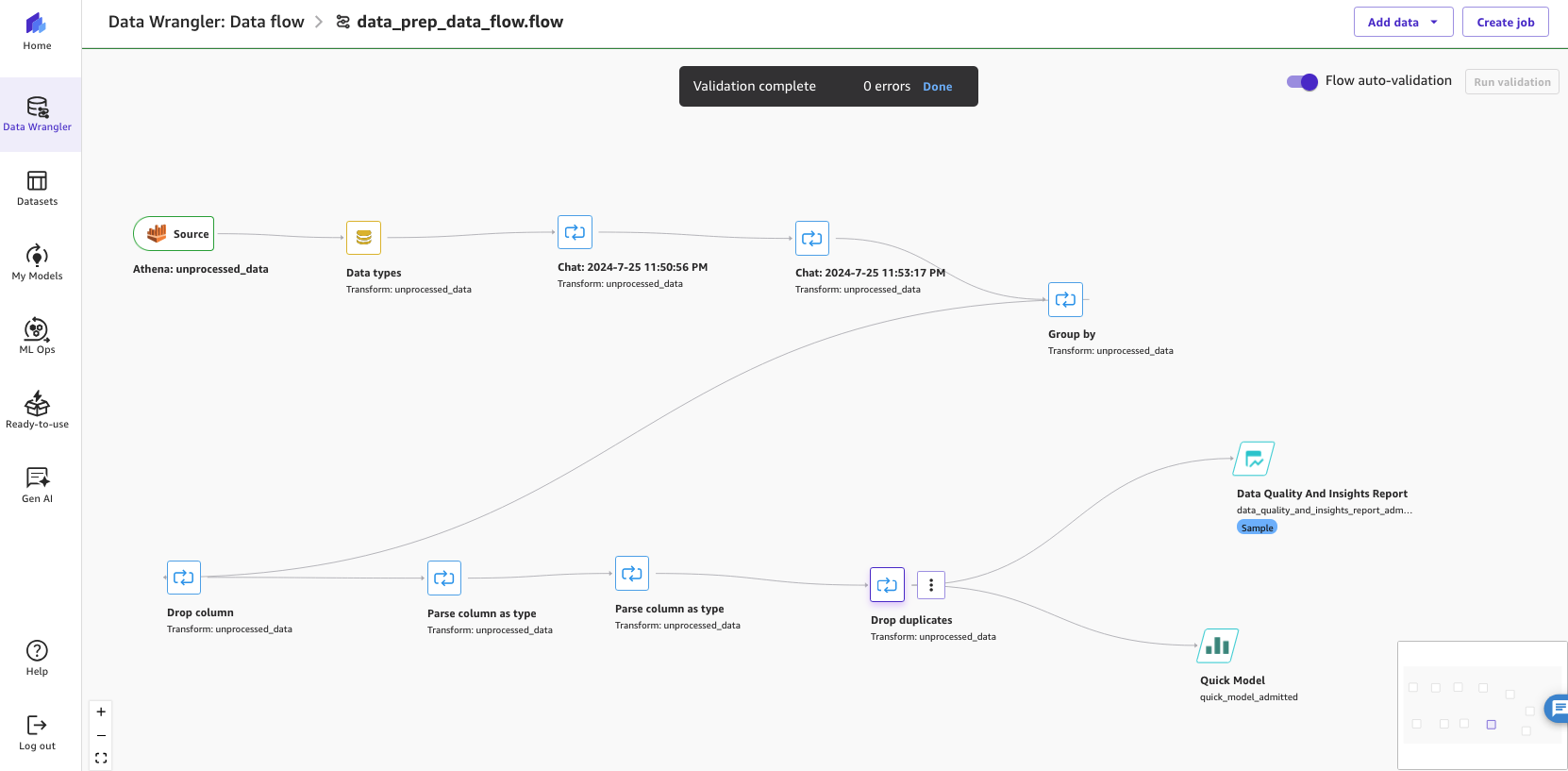
Determine 12: Exhibiting the end-to-end SageMaker Canvas Information Wrangler information stream
If you wish to incorporate this information stream right into a productionized ML workflow, SageMaker Canvas can create a Jupyter pocket book that exports your data flow to Amazon SageMaker Pipelines.
Develop the ML mannequin
To get began with ML mannequin improvement, full the next steps:
- Select Create mannequin straight from the final step of the info stream.
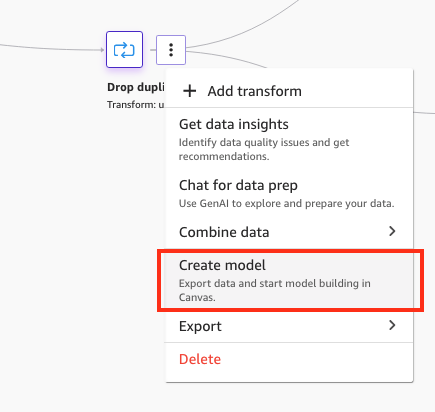
Determine 13: Making a mannequin from the SageMaker Information Wrangler information stream
- For Dataset identify, enter a reputation in your reworked dataset (for instance,
processed_data). - Select Export.
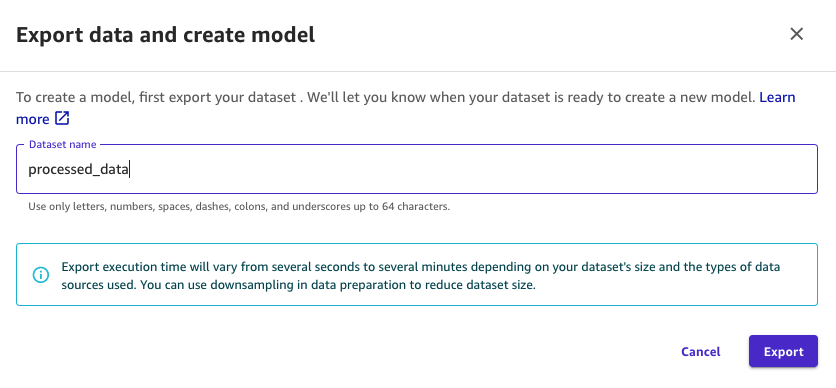
Determine 14: Naming the exported dataset for use by the mannequin in SageMaker Information Wrangler
This step will robotically create a brand new dataset.
- After the dataset has been created efficiently, select Create mannequin to start the ML mannequin creation.
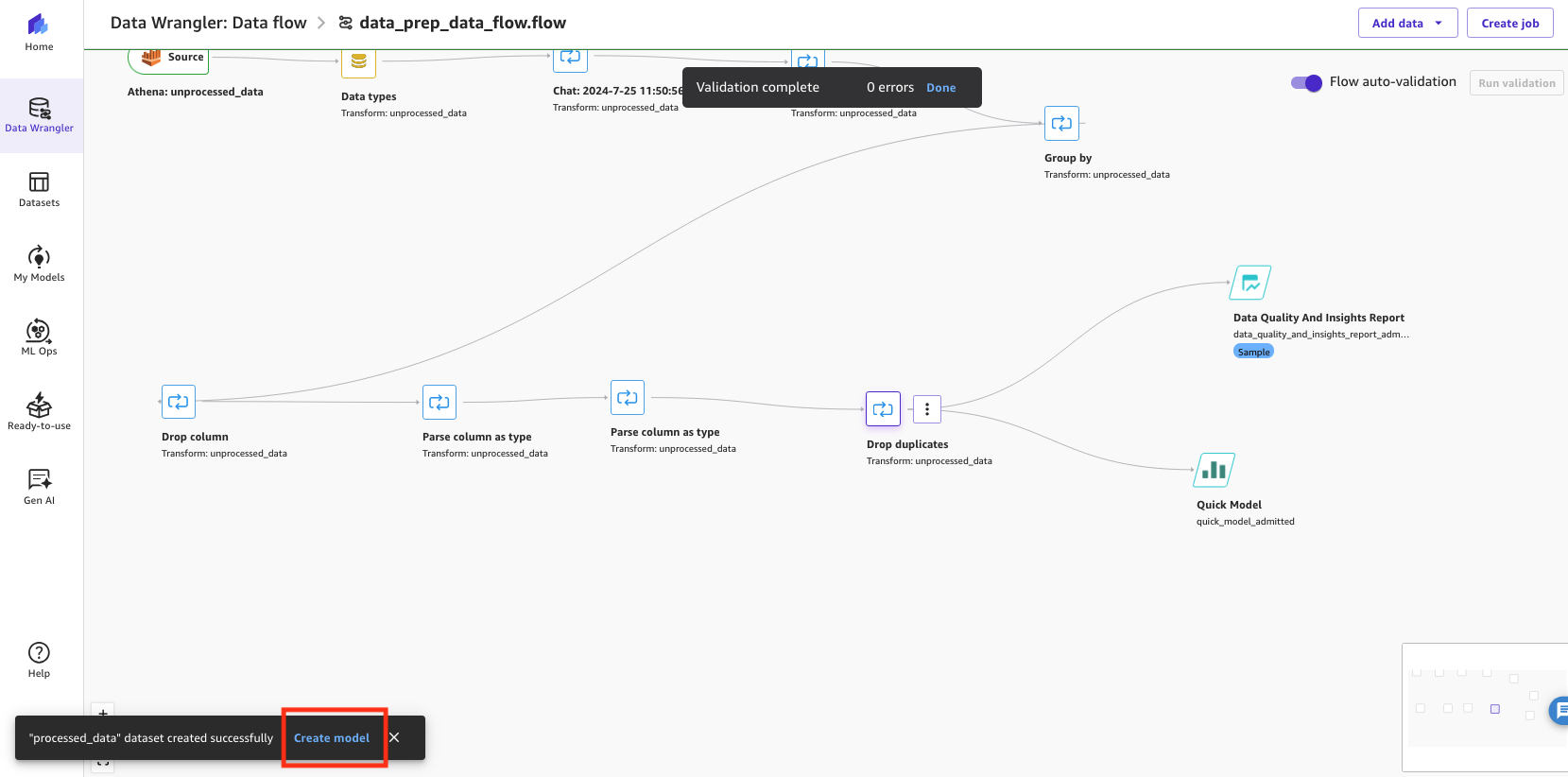
Determine 15: Creating the mannequin in SageMaker Information Wrangler
- For Mannequin identify, enter a reputation for the mannequin (for instance,
my_healthcare_model). - For Drawback kind, choose Predictive evaluation.
- Select Create.
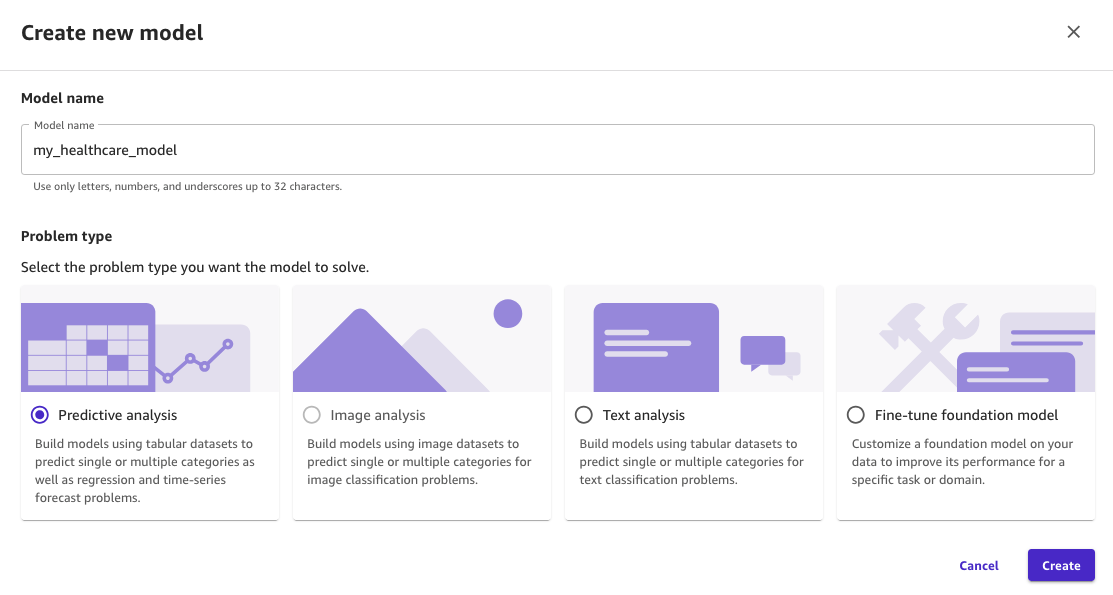
Determine 16: Naming the mannequin in SageMaker Canvas and deciding on the predictive evaluation kind
You are actually able to progress via the Construct, Analyze, Predict, and Deploy phases to develop and operationalize the ML mannequin utilizing SageMaker Canvas.
- On the Construct tab, for Goal column, select the column you wish to predict (
admitted). - Select Fast construct to construct the mannequin.
The Quick build possibility has a shorter construct time, however the Normal construct possibility typically enjoys increased accuracy.
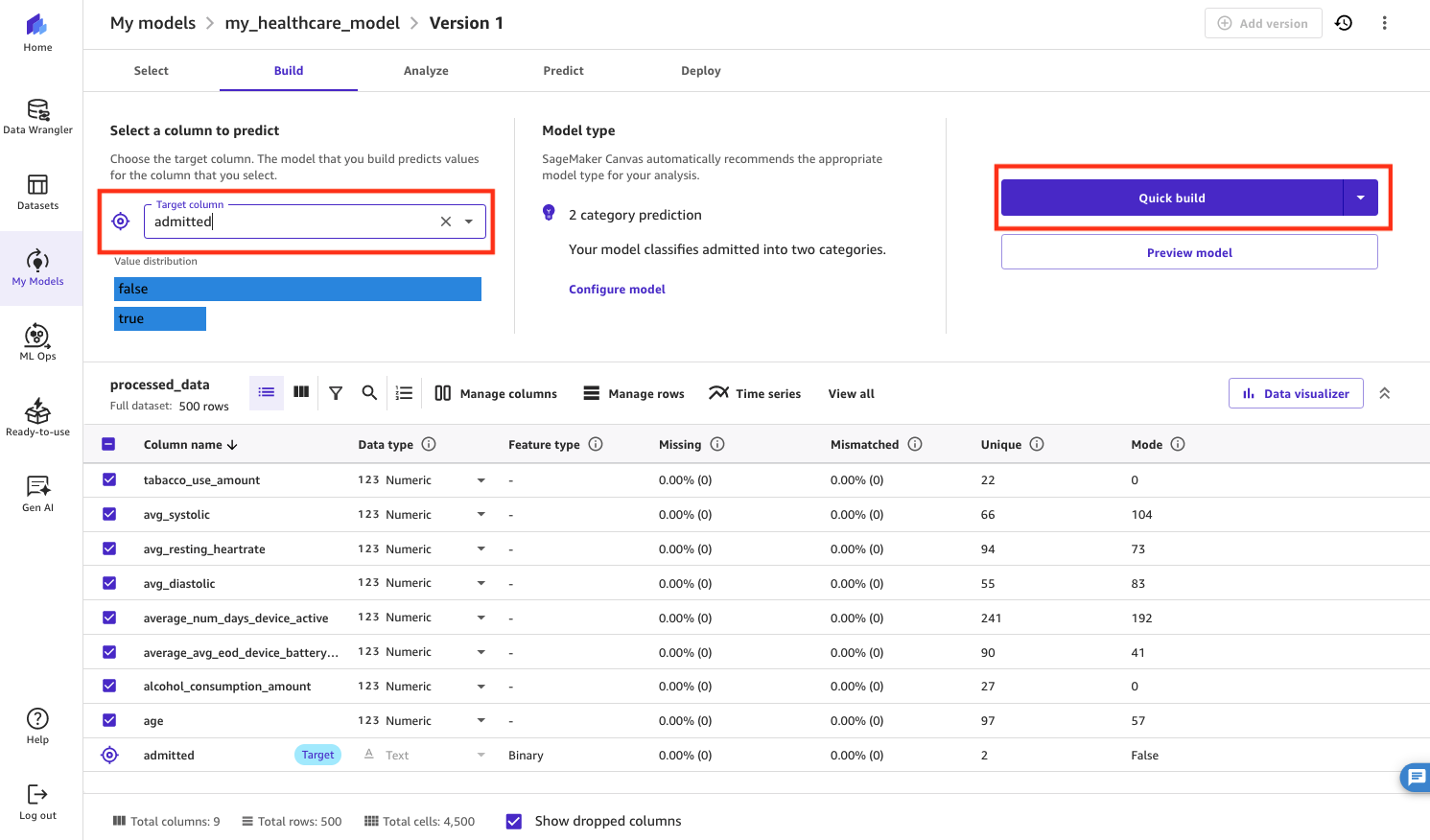
Determine 17: Deciding on the goal column to foretell in SageMaker Canvas
After a couple of minutes, on the Analyze tab, it is possible for you to to view the accuracy of the mannequin, together with column affect, scoring, and different superior metrics. For instance, we will see {that a} function from the wearables information captured in Splunk—average_num_days_device_active—has a robust affect on whether or not the affected person is prone to be admitted or not, together with their age. As such, the health-tech firm might proactively attain out to aged sufferers who are likely to maintain their wearables off to reduce the danger of their hospitalization.
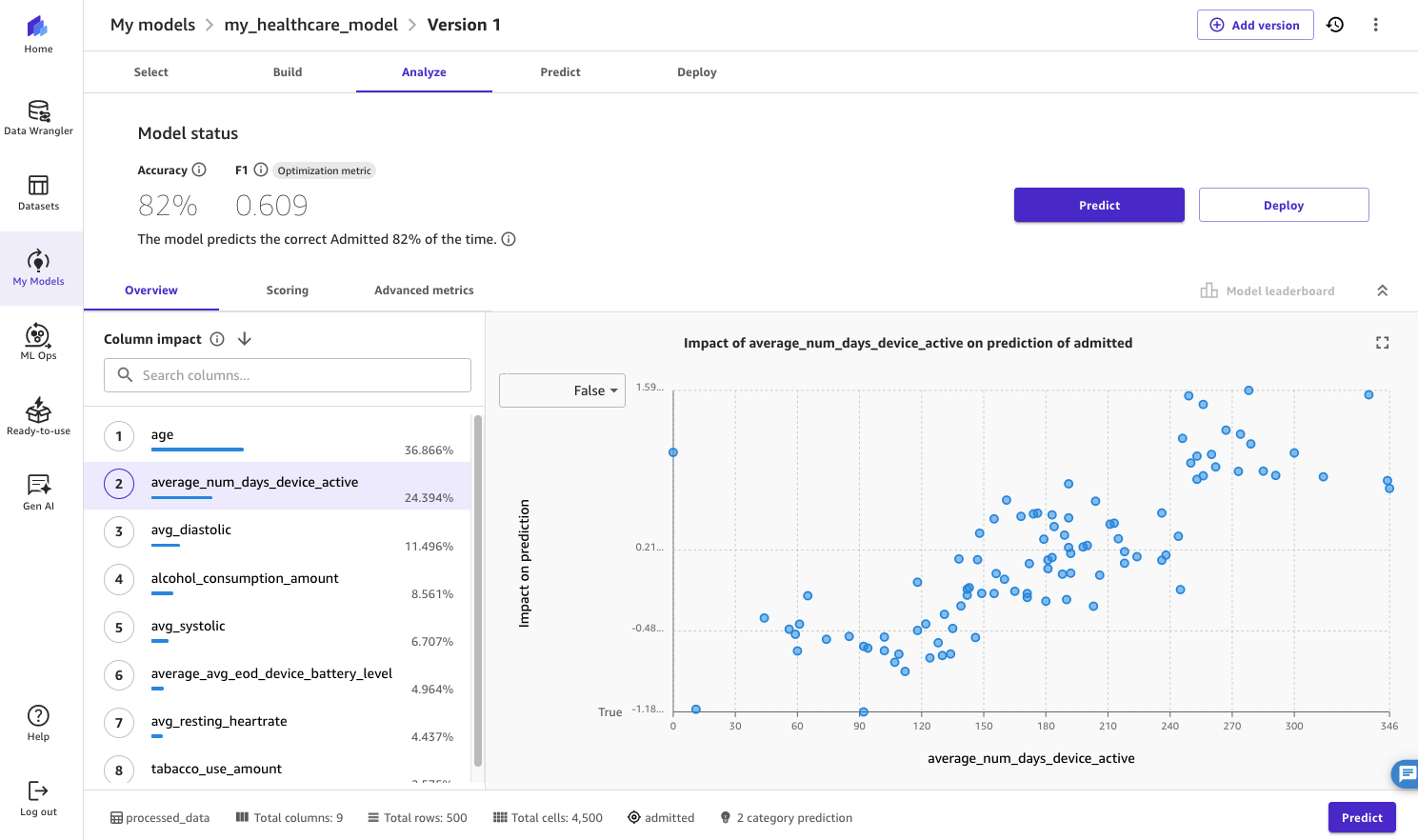
Determine 18: Displaying the outcomes from the mannequin fast construct in SageMaker Canvas
While you’re pleased with the outcomes from the Fast construct, repeat the method with a Normal construct to ensure you have an ML mannequin with increased accuracy that may be deployed.
Check the ML mannequin
Our ML mannequin has now been constructed. In the event you’re happy with its accuracy, you may make predictions utilizing this ML mannequin utilizing internet new information on the Predict tab. Predictions may be carried out both utilizing batch (record of sufferers) or for a single entry (one affected person).
Experiment with totally different values and select Replace prediction. The ML mannequin will reply with a prediction for the brand new values that you’ve entered.
On this instance, the ML mannequin has recognized a 64.5% likelihood that this specific affected person shall be admitted to hospital within the subsequent 30 days. The health-tech firm will doubtless wish to prioritize the care of this affected person.
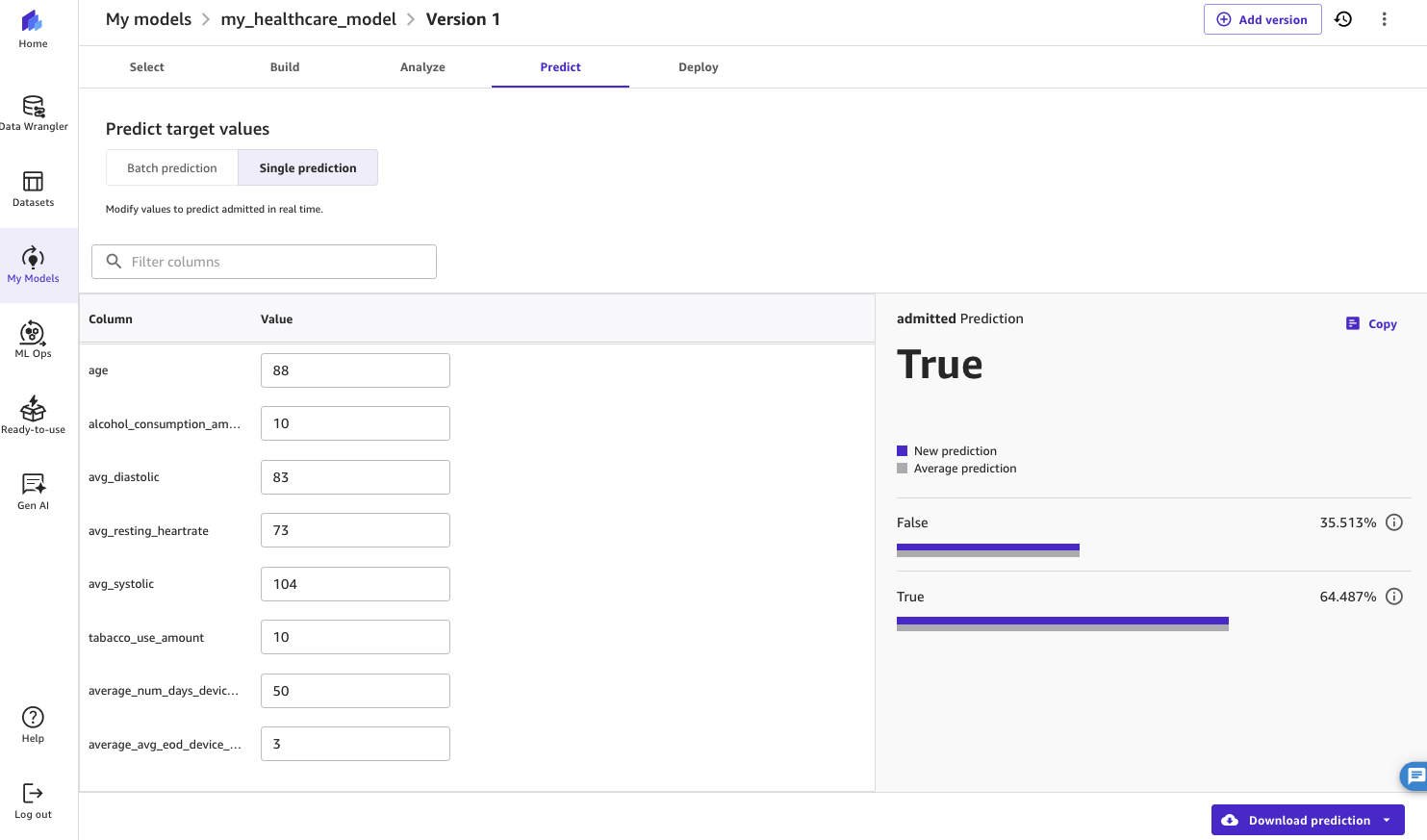
Determine 19: Displaying the outcomes from a single prediction utilizing the mannequin in SageMaker Canvas
Deploy the ML mannequin
It’s now doable for the health-tech firm to construct purposes that may use this ML mannequin to make predictions. ML fashions developed in SageMaker Canvas may be operationalized utilizing a broader set of SageMaker companies. For instance:
To deploy the ML mannequin, full the next steps:
- On the Deploy tab, select Create Deployment.
- Specify Deployment identify, Occasion kind, and Occasion depend.
- Select Deploy to make the ML mannequin out there as a SageMaker endpoint.
On this instance, we diminished the occasion kind to ml.m5.4xlarge and occasion depend to 1 earlier than deployment.
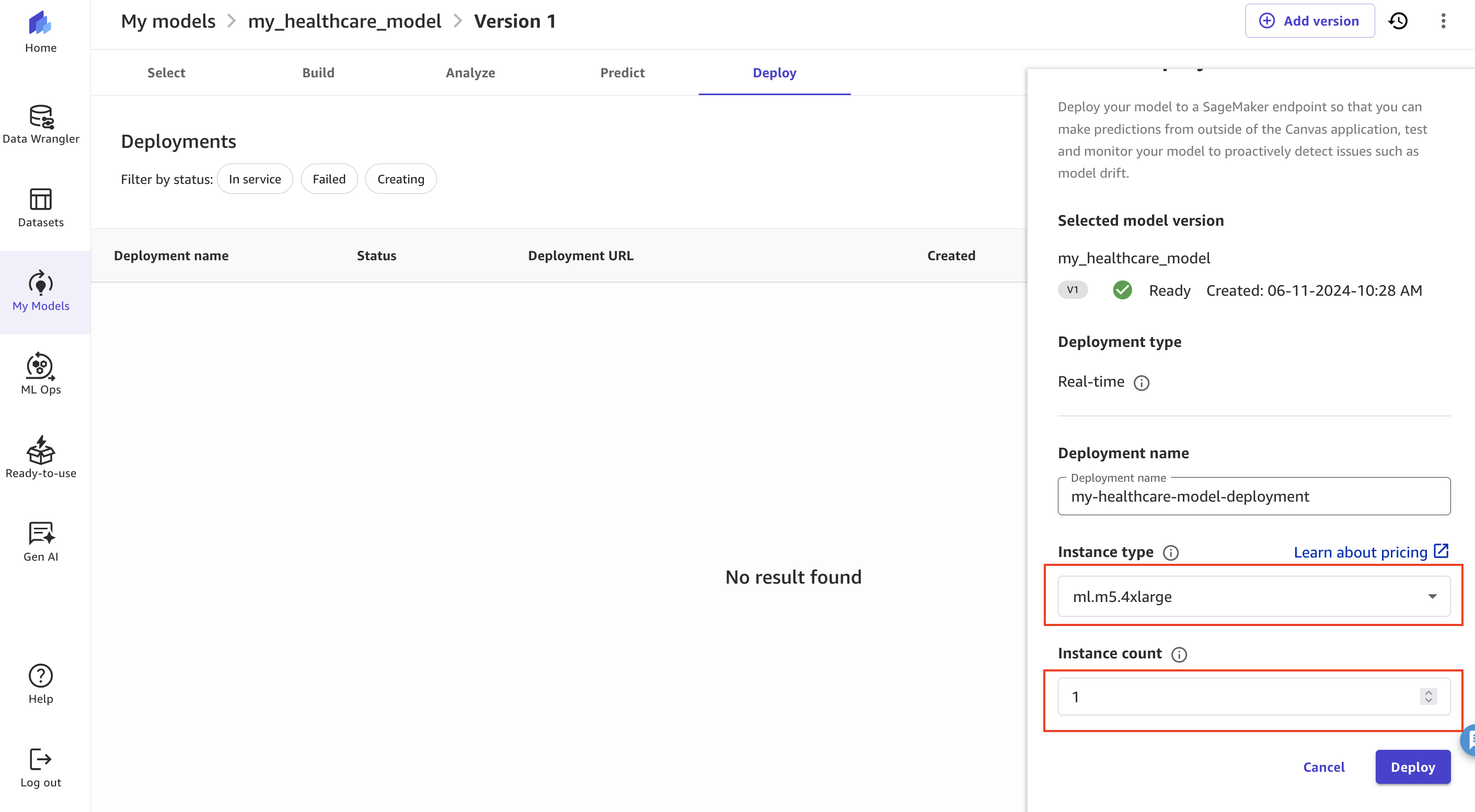
Determine 20: Deploying the utilizing SageMaker Canvas
At any time, you possibly can straight test the endpoint from SageMaker Canvas on the Check deployment tab of the deployed endpoint listed underneath Operations on the SageMaker Canvas console.
Seek advice from the Amazon SageMaker Canvas Developer Guide for detailed steps to take your ML mannequin improvement via its full improvement lifecycle and construct purposes that may devour the ML mannequin to make predictions.
Clear up
Seek advice from the directions within the README file to wash up the assets provisioned for the AWS information engineering pipeline answer.
SageMaker Canvas payments you in the course of the session, and we advocate logging out of SageMaker Canvas when you find yourself not utilizing it. Seek advice from Logging out of Amazon SageMaker Canvas for extra particulars. Moreover, in case you deployed a SageMaker endpoint, ensure you have deleted it.
Conclusion
This submit explored a no-code method involving SageMaker Canvas that may drive actionable insights from information saved throughout each Splunk and AWS platforms utilizing AI/ML strategies. We additionally demonstrated how you should utilize the generative AI capabilities of SageMaker Canvas to hurry up your information exploration and construct ML fashions which can be aligned to your online business’s expectations.
Be taught extra about AI on Splunk and ML on AWS.
Concerning the Authors

Alan Peaty is a Senior Accomplice Options Architect, serving to International Programs Integrators (GSIs), International Unbiased Software program Distributors (GISVs), and their clients undertake AWS companies. Previous to becoming a member of AWS, Alan labored as an architect at methods integrators reminiscent of IBM, Capita, and CGI. Exterior of labor, Alan is a eager runner who likes to hit the muddy trails of the English countryside, and is an IoT fanatic.

Brett Roberts is the International Accomplice Technical Supervisor for AWS at Splunk, main the technical technique to assist clients higher safe and monitor their important AWS environments and purposes utilizing Splunk. Brett was a member of the Splunk Belief and holds a number of Splunk and AWS certifications. Moreover, he co-hosts a neighborhood podcast and weblog known as Massive Information Beard, exploring tendencies and applied sciences within the analytics and AI house.

Arnaud Lauer is a Principal Accomplice Options Architect within the Public Sector staff at AWS. He allows companions and clients to grasp easy methods to finest use AWS applied sciences to translate enterprise wants into options. He brings greater than 18 years of expertise in delivering and architecting digital transformation initiatives throughout a variety of industries, together with public sector, power, and shopper items.





