Enhance AI assistant response accuracy utilizing Data Bases for Amazon Bedrock and a reranking mannequin
AI chatbots and digital assistants have turn out to be more and more in style lately thanks the breakthroughs of enormous language fashions (LLMs). Educated on a big quantity of datasets, these fashions incorporate reminiscence elements of their architectural design, permitting them to grasp and comprehend textual context.
Commonest use instances for chatbot assistants concentrate on a couple of key areas, together with enhancing buyer experiences, boosting worker productiveness and creativity, or optimizing enterprise processes. As an illustration, buyer assist, troubleshooting, and inside and exterior knowledge-based search.
Regardless of these capabilities, a key problem with chatbots is producing high-quality and correct responses. A method of fixing this problem is to make use of Retrieval Augmented Technology (RAG). RAG is the method of optimizing the output of an LLM so it references an authoritative data base outdoors of its coaching knowledge sources earlier than producing a response. Reranking seeks to enhance search relevance by reordering the consequence set returned by a retriever with a unique mannequin. On this put up, we clarify how two strategies—RAG and reranking—can assist enhance chatbot responses utilizing Knowledge Bases for Amazon Bedrock.
Resolution overview
RAG is a method that mixes the strengths of information base retrieval and generative fashions for textual content era. It really works by first retrieving related responses from a database, then utilizing these responses as context to feed the generative mannequin to provide a remaining output. Utilizing a RAG method for constructing a chatbot has many benefits. For instance, retrieving responses from its database earlier than producing a response may present extra related and coherent responses. This helps enhance the conversational stream. RAG additionally scales higher with extra knowledge in comparison with pure generative fashions, and it doesn’t require fine-tuning of the mannequin when new knowledge is added to the data base. Moreover, the retrieval element allows the mannequin to include exterior data by retrieving related background info from its database. This method helps present factual, in-depth, and educated responses.
To search out a solution, RAG takes an method that makes use of vector search throughout the paperwork. The benefit of utilizing vector search is velocity and scalability. Somewhat than scanning each single doc to seek out the reply, with the RAG method, you flip the texts (data base) into embeddings and retailer these embeddings within the database. The embeddings are a compressed model of the paperwork, represented by an array of numerical values. After the embeddings are saved, the vector search queries the vector database to seek out the similarity based mostly on the vectors related to the paperwork. Sometimes, a vector search will return the highest okay most related paperwork based mostly on the consumer query, and return the okay outcomes. Nevertheless, as a result of the similarity algorithm in a vector database works on vectors and never paperwork, vector search doesn’t all the time return essentially the most related info within the high okay outcomes. This straight impacts the accuracy of the response if essentially the most related contexts aren’t out there to the LLM.
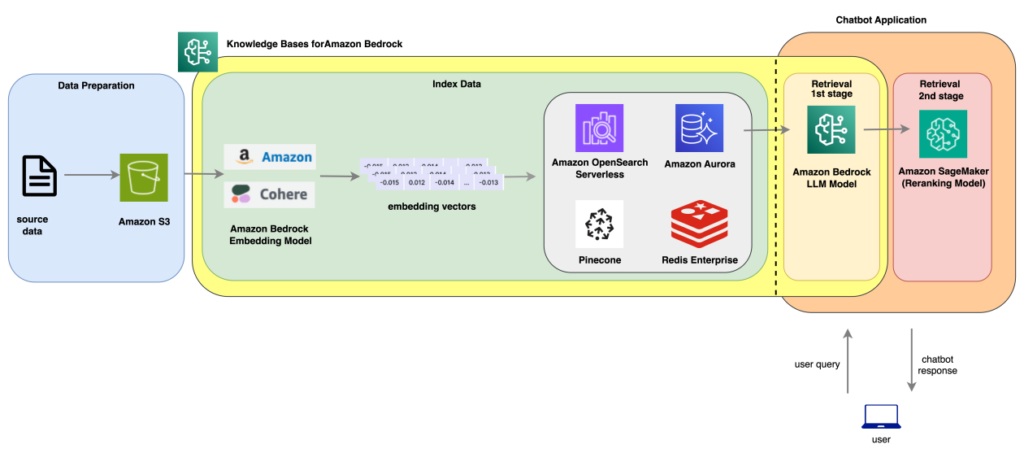
Reranking is a method that may additional enhance the responses by choosing the most suitable choice out of a number of candidate responses. The next structure illustrates how a reranking answer may work.
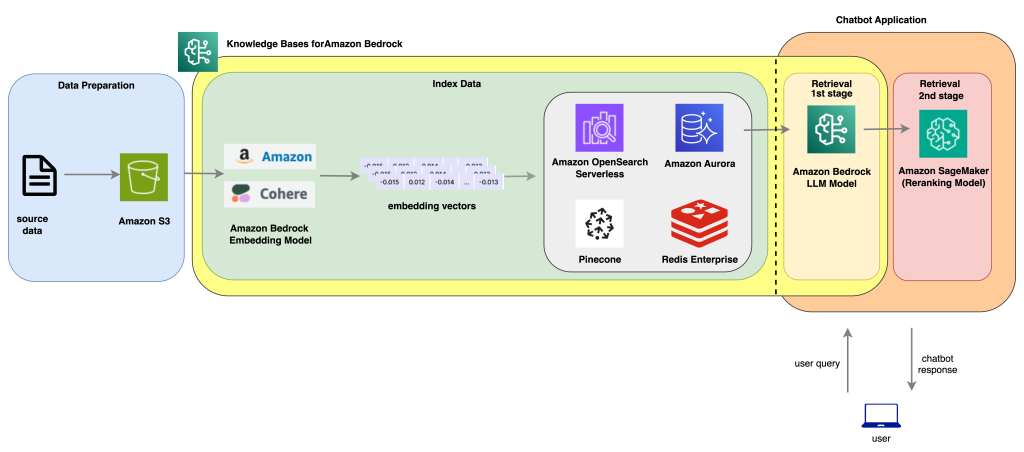
Structure diagram for Reranking mannequin integration with Data Bases for Bedrock
Let’s create a query answering answer, the place we ingest The Nice Gatsby, a 1925 novel by American author F. Scott Fitzgerald. This guide is publicly out there via Project Gutenberg. We use Data Bases for Amazon Bedrock to implement the end-to-end RAG workflow and ingest the embeddings into an Amazon OpenSearch Serverless vector search assortment. We then retrieve solutions utilizing normal RAG and a two-stage RAG, which includes a reranking API. We then evaluate outcomes from these two strategies.
The code pattern is on the market on this GitHub repo.
Within the following sections, we stroll via the high-level steps:
- Put together the dataset.
- Generate questions from the doc utilizing an Amazon Bedrock LLM.
- Create a data base that accommodates this guide.
- Retrieve solutions utilizing the data base
retrieveAPI - Consider the response utilizing the RAGAS
- Retrieve solutions once more by working a two-stage RAG, utilizing the data base
retrieveAPI after which making use of reranking on the context. - Consider the two-stage RAG response utilizing the RAGAS framework.
- Evaluate the outcomes and the efficiency of every RAG method.
For effectivity functions, we supplied pattern code in a notebook used to generate a set of questions and solutions. These Q&A pairs are used within the RAG analysis course of. We extremely advocate having a human to validate every query and reply for accuracy.
The next sections explains main steps with the assistance of code blocks.
Stipulations
To clone the GitHub repository to your native machine, open a terminal window and run the next instructions:
Put together the dataset
Obtain the guide from the Project Gutenberg website. For this put up, we create 10 massive paperwork from this guide and add them to Amazon Simple Storage Service (Amazon S3):
Create Data Base for Bedrock
In case you’re new to utilizing Data Bases for Amazon Bedrock, confer with Knowledge Bases for Amazon Bedrock now supports Amazon Aurora PostgreSQL and Cohere embedding models, the place we described how Data Bases for Amazon Bedrock manages the end-to-end RAG workflow.
On this step, you create a data base utilizing a Boto3 shopper. You utilize Amazon Titan Textual content Embedding v2 to transform the paperwork into embeddings (‘embeddingModelArn’) and level to the S3 bucket you created earlier as the info supply (dataSourceConfiguration):
Generate questions from the doc
We use Anthropic Claude on Amazon Bedrock to generate a listing of 10 questions and the corresponding solutions. The Q&An information serves as the muse for the RAG analysis based mostly on the approaches that we’re going to implement. We outline the generated solutions from this step as floor fact knowledge. See the next code:
Retrieve solutions utilizing the data base APIs
We use the generated questions and retrieve solutions from the data base utilizing the retrieve and converse APIs:
Consider the RAG response utilizing the RAGAS framework
We now consider the effectiveness of the RAG utilizing a framework referred to as RAGAS. The framework supplies a collection of metrics to guage totally different dimensions. In our instance, we consider responses based mostly on the next dimensions:
- Reply relevancy – This metric focuses on assessing how pertinent the generated reply is to the given immediate. A decrease rating is assigned to solutions which are incomplete or include redundant info. This metric is computed utilizing the query and the reply, with values ranging between 0–1, the place increased scores point out higher relevancy.
- Reply similarity – This assesses the semantic resemblance between the generated reply and the bottom fact. This analysis relies on the bottom fact and the reply, with values falling throughout the vary of 0–1. A better rating signifies a greater alignment between the generated reply and the bottom fact.
- Context relevancy – This metric gauges the relevancy of the retrieved context, calculated based mostly on each the query and contexts. The values fall throughout the vary of 0–1, with increased values indicating higher relevancy.
- Reply correctness – The evaluation of reply correctness includes gauging the accuracy of the generated reply when in comparison with the bottom fact. This analysis depends on the bottom fact and the reply, with scores starting from 0–1. A better rating signifies a better alignment between the generated reply and the bottom fact, signifying higher correctness.
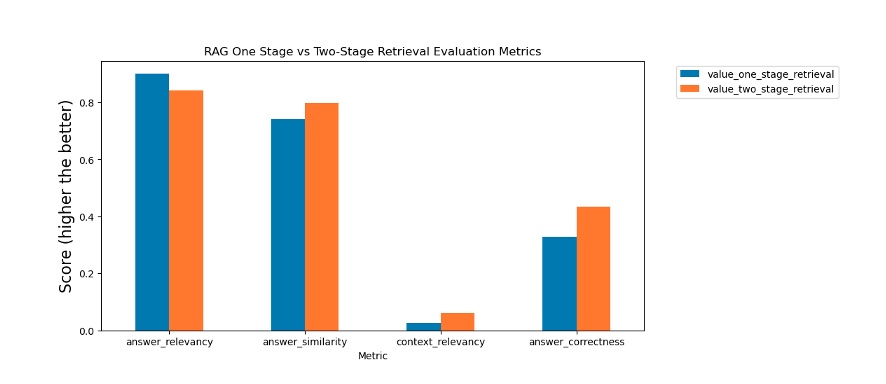
A summarized report for normal RAG method based mostly on RAGAS analysis:
answer_relevancy: 0.9006225160334027
answer_similarity: 0.7400904157096762
answer_correctness: 0.32703043056663855
context_relevancy: 0.024797687553157175
Two-stage RAG: Retrieve and rerank
Now that you’ve the outcomes with the retrieve_and_generate API, let’s discover the two-stage retrieval method by extending the usual RAG method to combine with a reranking mannequin. Within the context of RAG, reranking fashions are used after an preliminary set of contexts are retrieved by the retriever. The reranking mannequin takes within the listing of outcomes and reranks each based mostly on the similarity between the context and the consumer question. In our instance, we use a robust reranking mannequin referred to as bge-reranker-large. The mannequin is on the market within the Hugging Face Hub and can also be free for business use. Within the following code, we use the data base’s retrieve API so we are able to get the deal with on the context, and rerank it utilizing the reranking mannequin deployed as an Amazon SageMaker endpoint. We offer the pattern code for deploying the reranking mannequin in SageMaker within the GitHub repository. Right here’s a code snippet that demonstrates two-stage retrieval course of:
Consider the two-stage RAG response utilizing the RAGAS framework
We consider the solutions generated by the two-stage retrieval course of. The next is a summarized report based mostly on RAGAS analysis:
answer_relevancy: 0.841581671275458
answer_similarity: 0.7961827348349313
answer_correctness: 0.43361356731293665
context_relevancy: 0.06049484724216884
Evaluate the outcomes
Let’s evaluate the outcomes from our assessments. As proven within the following determine, the reranking API improves context relevancy, reply correctness, and reply similarity, that are vital for enhancing the accuracy of the RAG course of.
RAG vs Two Stage Retrieval analysis metrics
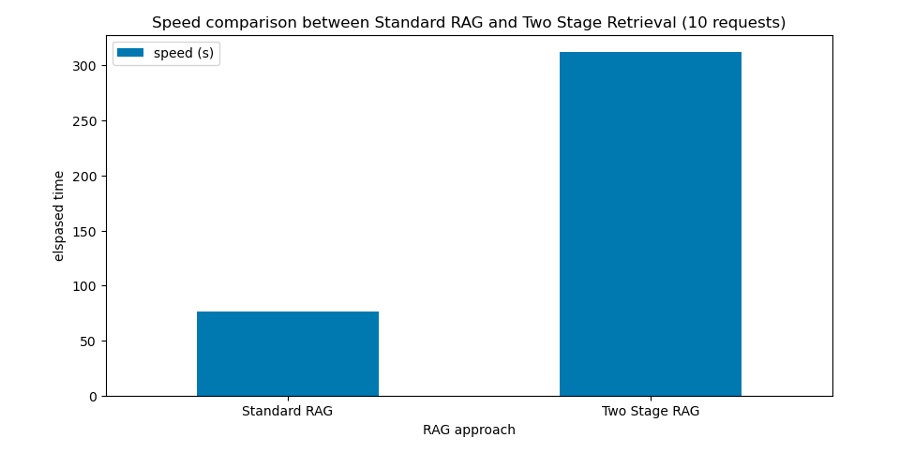
Equally, we additionally measured the RAG latency for each approaches. The outcomes will be proven within the following metrics and the corresponding chart:
Normal RAG latency: 76.59s
Two Stage Retrieval latency: 312.12s
Latency metric for RAG and Two Stage Retrieval course of
In abstract, utilizing a reranking mannequin (tge-reranker-large) hosted on an ml.m5.xlarge occasion yields roughly 4 instances the latency in comparison with the usual RAG method. We advocate testing with totally different reranking mannequin variants and occasion sorts to acquire the optimum efficiency to your use case.
Conclusion
On this put up, we demonstrated learn how to implement a two-stage retrieval course of by integrating a reranking mannequin. We explored how integrating a reranking mannequin with Data Bases for Amazon Bedrock can present higher efficiency. Lastly, we used RAGAS, an open supply framework, to supply context relevancy, reply relevancy, reply similarity, and reply correctness metrics for each approaches.
Check out this retrieval course of as we speak, and share your suggestions within the feedback.
Concerning the Creator
 Wei Teh is an Machine Studying Options Architect at AWS. He’s obsessed with serving to clients obtain their enterprise goals utilizing cutting-edge machine studying options. Exterior of labor, he enjoys out of doors actions like tenting, fishing, and climbing along with his household.
Wei Teh is an Machine Studying Options Architect at AWS. He’s obsessed with serving to clients obtain their enterprise goals utilizing cutting-edge machine studying options. Exterior of labor, he enjoys out of doors actions like tenting, fishing, and climbing along with his household.
 Pallavi Nargund is a Principal Options Architect at AWS. In her function as a cloud expertise enabler, she works with clients to grasp their targets and challenges, and provides prescriptive steering to attain their goal with AWS choices. She is obsessed with girls in expertise and is a core member of Girls in AI/ML at Amazon. She speaks at inside and exterior conferences comparable to AWS re:Invent, AWS Summits, and webinars. Exterior of labor she enjoys volunteering, gardening, biking and climbing.
Pallavi Nargund is a Principal Options Architect at AWS. In her function as a cloud expertise enabler, she works with clients to grasp their targets and challenges, and provides prescriptive steering to attain their goal with AWS choices. She is obsessed with girls in expertise and is a core member of Girls in AI/ML at Amazon. She speaks at inside and exterior conferences comparable to AWS re:Invent, AWS Summits, and webinars. Exterior of labor she enjoys volunteering, gardening, biking and climbing.
 Qingwei Li is a Machine Studying Specialist at Amazon Internet Providers. He acquired his Ph.D. in Operations Analysis after he broke his advisor’s analysis grant account and did not ship the Nobel Prize he promised. Presently he helps clients within the monetary service and insurance coverage business construct machine studying options on AWS. In his spare time, he likes studying and educating.
Qingwei Li is a Machine Studying Specialist at Amazon Internet Providers. He acquired his Ph.D. in Operations Analysis after he broke his advisor’s analysis grant account and did not ship the Nobel Prize he promised. Presently he helps clients within the monetary service and insurance coverage business construct machine studying options on AWS. In his spare time, he likes studying and educating.
 Mani Khanuja is a Tech Lead – Generative AI Specialists, creator of the guide Utilized Machine Studying and Excessive Efficiency Computing on AWS, and a member of the Board of Administrators for Girls in Manufacturing Training Basis Board. She leads machine studying initiatives in varied domains comparable to laptop imaginative and prescient, pure language processing, and generative AI. She speaks at inside and exterior conferences such AWS re:Invent, Girls in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for lengthy runs alongside the seaside.
Mani Khanuja is a Tech Lead – Generative AI Specialists, creator of the guide Utilized Machine Studying and Excessive Efficiency Computing on AWS, and a member of the Board of Administrators for Girls in Manufacturing Training Basis Board. She leads machine studying initiatives in varied domains comparable to laptop imaginative and prescient, pure language processing, and generative AI. She speaks at inside and exterior conferences such AWS re:Invent, Girls in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for lengthy runs alongside the seaside.





