Cepsa Química improves the effectivity and accuracy of product stewardship utilizing Amazon Bedrock
This can be a visitor publish co-written with Vicente Cruz Mínguez, Head of Knowledge and Superior Analytics at Cepsa Química, and Marcos Fernández Díaz, Senior Knowledge Scientist at Keepler.
Generative synthetic intelligence (AI) is quickly rising as a transformative drive, poised to disrupt and reshape companies of all sizes and throughout industries. Generative AI empowers organizations to mix their knowledge with the facility of machine studying (ML) algorithms to generate human-like content material, streamline processes, and unlock innovation. As with all different industries, the vitality sector is impacted by the generative AI paradigm shift, unlocking alternatives for innovation and effectivity. One of many areas the place generative AI is quickly exhibiting its worth is the streamlining of operational processes, lowering prices, and enhancing general productiveness.
On this publish, we clarify how Cepsa Química and accomplice Keepler have applied a generative AI assistant to extend the effectivity of the product stewardship staff when answering compliance queries associated to the chemical merchandise they market. To speed up growth, they used Amazon Bedrock, a totally managed service that gives a selection of high-performing basis fashions (FMs) from main AI corporations like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon by a single API, together with a broad set of capabilities to construct generative AI functions with safety, privateness and security.
Cepsa Química, a world chief within the manufacturing of linear alkylbenzene (LAB) and rating second within the manufacturing of phenol, is an organization aligned with Cepsa’s Positive Motion strategy for 2030, contributing to the decarbonization and sustainability of its processes by using renewable uncooked supplies, growth of merchandise with much less carbon, and use of waste as uncooked supplies.
At Cepsa’s Digital, IT, Transformation & Operational Excellence (DITEX) division, we work on democratizing using AI inside our enterprise areas in order that it turns into one other lever for producing worth. Inside this context, we recognized product stewardship as one of many areas with extra potential for worth creation by generative AI. We partnered with Keepler, a cloud-centered knowledge providers consulting firm specialised within the design, building, deployment, and operation of superior public cloud analytics custom-made options for big organizations, within the creation of the primary generative AI answer for considered one of our company groups.
The Security, Sustainability & Vitality Transition staff
The Security, Sustainability & Vitality Transition space of Cepsa Química is liable for all human well being, security, and environmental features associated to the merchandise manufactured by the corporate and the related uncooked supplies, amongst others. On this subject, its areas of motion are product security, regulatory compliance, sustainability, and customer support round security and compliance.
One of many obligations of the Security, Sustainability & Vitality Transition staff is product stewardship, which takes care of regulatory compliance of the marketed merchandise. The Product Stewardship division is liable for managing a big assortment of regulatory compliance paperwork. Their obligation includes figuring out which laws apply to every particular product within the firm’s portfolio, compiling an inventory of all of the relevant laws for a given product, and supporting different inside groups which may have questions associated to those merchandise and laws. Instance questions is perhaps “What are the restrictions for CMR substances?”, “How lengthy do I have to hold the paperwork associated to a toluene sale?”, or “What’s the attain characterization ratio and the way do I calculate it?” The regulatory content material required to reply these questions varies over time, introducing new clauses and repealing others. This work used to eat a big proportion of the staff’s time, so that they recognized a possibility to generate worth by lowering the search time for regulatory consultations.
The DITEX division engaged with the Security, Sustainability & Vitality Transition staff for a preliminary evaluation of their ache factors and deemed it possible to make use of generative AI methods to hurry up the decision of compliance queries sooner. The evaluation was performed for queries based mostly on each unstructured (regulatory paperwork and product specs sheets) and structured (product catalog) knowledge.
An strategy to product stewardship with generative AI
Massive language fashions (LLMs) are skilled with huge quantities of data crawled from the web, capturing appreciable data from a number of domains. Nevertheless, their data is static and tied to the info used throughout the pre-training part.
To beat this limitation and supply dynamism and adaptableness to data base adjustments, we determined to observe a Retrieval Augmented Technology (RAG) strategy, wherein the LLMs are introduced with related info extracted from exterior knowledge sources to supply up-to-date knowledge with out the necessity to retrain the fashions. This strategy is a good match for a situation the place regulatory info is up to date at a quick tempo, with frequent derogations, amendments, and new laws being printed.
Moreover, the RAG-based strategy permits fast prototyping of doc search use circumstances, permitting us to craft an answer based mostly on regulatory details about chemical substances in just a few weeks.
The answer we constructed is predicated on 4 principal useful blocks:
- Enter processing – Enter regulatory PDF paperwork are preprocessed to extract the related info. Every doc is split into chunks to ease the indexing and retrieval processes based mostly on semantic which means.
- Embeddings era – An embeddings mannequin is used to encode the semantic info of every chunk into an embeddings vector, which is saved in a vector database, enabling similarity search of consumer queries.
- LLM chain service – This service orchestrates the answer by invoking the LLM fashions with a becoming immediate and creating the response that’s returned to the consumer.
- Consumer interface – A conversational chatbot permits interplay with customers.
We divided the answer into two impartial modules: one to batch course of enter paperwork and one other one to reply consumer queries by operating inference.
Batch ingestion module
The batch ingestion module performs the preliminary processing of the uncooked compliance paperwork and product catalog and generates the embeddings that shall be later used to reply consumer queries. The next diagram illustrates this structure.

The batch ingestion module performs the next duties:
- AWS Glue, a serverless knowledge integration service, is used to run periodical extract, remodel, and cargo (ETL) jobs that learn enter uncooked paperwork and the product catalog from Amazon Simple Storage Service (Amazon S3), an object storage service that gives industry-leading scalability, knowledge availability, safety, and efficiency.
- The AWS Glue job calls Amazon Textract, an ML service that mechanically extracts textual content, handwriting, format components, and knowledge from scanned paperwork, to course of the enter PDF paperwork. After knowledge is extracted, the job performs doc chunking, knowledge cleanup, and postprocessing.
- The AWS Glue job makes use of Amazon Bedrock to generate vector embeddings for every doc chunk utilizing the Amazon Titan Text Embeddings
- Amazon Aurora PostgreSQL-Compatible Edition, a totally managed, PostgreSQL-compatible, and ACID-compliant relational database engine to retailer the extracted embeddings, is used with the pgvector extension enabled for environment friendly similarity searches.
Inference module
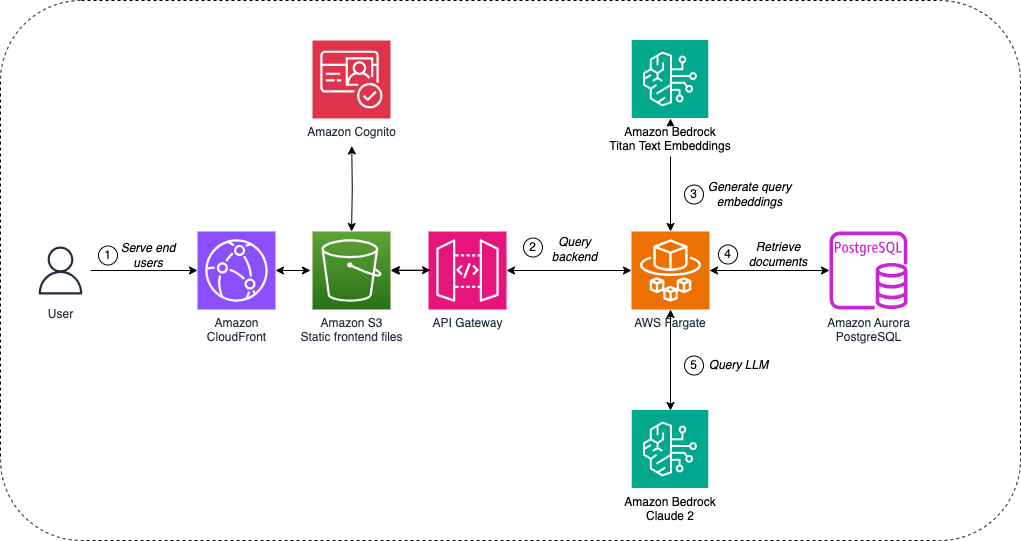
The inference module transforms consumer queries into embeddings, retrieves related doc chunks from the data base utilizing similarity search, and prompts an LLM with the question and retrieved chunks to generate a contextual response. The next diagram illustrates this structure.

The inference module implements the next steps:
- Customers work together by an internet portal, which consists of a static web site saved in Amazon S3, served by Amazon CloudFront, a content material supply community (CDN), and secured with AWS Cognito, a buyer identification and entry administration platform.
- Queries are despatched to the backend utilizing a REST API outlined in Amazon API Gateway, a totally managed service that makes it simple for builders to create, publish, preserve, monitor, and safe APIs at any scale, and applied by an API Gateway private integration. The backend is applied by an LLM chain service operating on AWS Fargate, a serverless, pay-as-you-go compute engine that permits you to concentrate on constructing functions with out managing servers. This service orchestrates the interplay with the totally different LLMs utilizing the LangChain
- The LLM chain service invokes Amazon Titan Textual content Embeddings on Amazon Bedrock to generate the embeddings for the consumer question.
- Primarily based on the question embeddings, the related paperwork are retrieved from the embeddings database utilizing similarity search.
- The service composes a immediate that features the consumer question and the paperwork extracted from the data base. The immediate is shipped to Anthropic Claude 2.0 on Amazon Bedrock, and the mannequin reply is shipped again to the consumer.
Word on the RAG implementation
The product stewardship chatbot was constructed earlier than Knowledge Bases for Amazon Bedrock was typically out there. Data Bases for Amazon Bedrock is a fully managed capability that helps you implement your complete RAG workflow from ingestion to retrieval and immediate augmentation with out having to construct {custom} integrations to knowledge sources and handle knowledge flows. Data Bases manages the preliminary vector retailer arrange, handles the embedding and querying, and gives supply attribution and short-term reminiscence wanted for manufacturing RAG functions.
With Data Bases for Amazon Bedrock, the implementation of steps 3–4 of the Batch Ingestion and Inference modules could be considerably simplified.
Challenges and options
On this part, we focus on the challenges we encountered throughout the growth of the system and the choices we made to beat these challenges.
Knowledge preprocessing and chunking technique
We found that the enter paperwork contained quite a lot of structural complexities, which posed a problem within the processing stage. As an illustration, some tables comprise giant quantities of data with minimal context apart from the header, which is displayed on the high of the desk. This may make it advanced to acquire the fitting solutions to consumer queries, as a result of the retrieval course of may lack context.
Moreover, some doc annexes are linked to different sections of the doc and even different paperwork, resulting in incomplete knowledge retrieval and era of inaccurate solutions.
To deal with these challenges, we applied three mitigation methods:
- Knowledge chunking – We determined to make use of bigger chunk sizes with important overlaps to supply most context for every chunk throughout ingestion. Nevertheless, we set an higher restrict to keep away from dropping the semantic which means of the chunk.
- Mannequin choice – We chosen a mannequin with a big context window to generate responses that take a bigger context into consideration. Anthropic Claude 2.0 on Amazon Bedrock, with a 100 Okay context window, supplied probably the most correct outcomes. (The system was constructed earlier than Anthropic Claude 2.1 or the Anthropic Claude 3 mannequin household had been out there on Amazon Bedrock).
- Question variants – Previous to retrieving paperwork from the database, a number of variants of the consumer question are generated utilizing an LLM. Paperwork for all variants are retrieved and deduplicated earlier than being supplied as context for the LLM question.
These three methods considerably enhanced the retrieval and response accuracy of the RAG system.
Analysis of outcomes and course of refinement
Evaluating the responses from the LLM fashions is one other problem that’s not present in conventional AI use circumstances. Due to the free textual content nature of the output, it’s troublesome to evaluate and examine totally different responses when it comes to a metric or KPI, resulting in a guide evaluate generally. Nevertheless, a guide course of is time-consuming and never scalable.
To attenuate the drawbacks, we created a benchmarking dataset with the assistance of seasoned customers, containing the next info:
- Consultant questions that require knowledge mixed from totally different paperwork
- Floor fact solutions for every query
- References to the supply paperwork, pages, and line numbers the place the fitting solutions are discovered
Then we applied an computerized analysis system with Anthropic Claude 2.0 on Amazon Bedrock, with totally different prompting methods to guage doc retrieval and response formation. This strategy allowed for adjustment of various parameters in a quick and automatic method:
- Preprocessing – Tried totally different values for chunk measurement and overlap measurement
- Retrieval – Examined a number of retrieval methods of incremental complexity
- Querying – Ran the assessments with totally different LLMs hosted on Amazon Bedrock:
- Amazon Titan Textual content Premier
- Cohere Command v1.4
- Anthropic Claude Instantaneous
- Anthropic Claude 2.0
The ultimate answer consists of three chains: one for translating the consumer question into English, one for producing variations of the enter query, and one for composing the ultimate response.
Achieved enhancements and subsequent steps
We constructed a conversational interface for the Security, Sustainability & Vitality Transition staff that helps the product stewardship staff be extra environment friendly and acquire solutions to compliance queries sooner. Moreover, the solutions comprise references to the enter paperwork utilized by the LLM to generate the reply, so the staff can double-check the response and discover further context if it’s wanted. The next screenshot reveals an instance of the conversational interface.

Among the qualitative and quantitative enhancements recognized by the product stewardship staff by using the answer are:
- Question occasions – The next desk summarizes the search time saved by question complexity and consumer seniority (contemplating all search occasions have been decreased to lower than 1 minute).
|
Complexity |
Time saved (minutes) | |
| Junior consumer | Senior consumer | |
| Low | 3.3 | 2 |
| Medium | 9.25 | 4 |
| Excessive | 28 | 10 |
- Reply high quality – The applied system affords further context and doc references which are utilized by the customers to enhance the standard of the reply.
- Operational effectivity – The applied system has accelerated the regulatory question course of, straight enhancing the division operational effectivity.
From the DITEX division, we’re presently working with different enterprise areas at Cepsa Química to determine comparable use circumstances to assist create a corporate-wide device that reuses parts from this primary initiative and generalizes using generative AI throughout enterprise capabilities.
Conclusion
On this publish, we shared how Cepsa Química and accomplice Keepler have applied a generative AI assistant that makes use of Amazon Bedrock and RAG methods to course of, retailer, and question the corpus of data associated to product stewardship. In consequence, customers save as much as 25 % of their time once they use the assistant to resolve compliance queries.
If you’d like your small business to get began with generative AI, go to Generative AI on AWS and join with a specialist, or rapidly construct a generative AI software in PartyRock.
Concerning the authors
 Vicente Cruz Mínguez is the Head of Knowledge & Superior Analytics at Cepsa Química. He has greater than 8 years of expertise with large knowledge and machine studying tasks in monetary, retail, vitality, and chemical industries. He’s presently main the Knowledge, Superior Analytics & Cloud Improvement staff within the Digital, IT, Transformation & Operational Excellence division at Cepsa Química, with a spotlight in feeding the company knowledge lake and democratizing knowledge for evaluation, machine studying tasks, and enterprise analytics. Since 2023, he has additionally been engaged on scaling using generative AI in all departments.
Vicente Cruz Mínguez is the Head of Knowledge & Superior Analytics at Cepsa Química. He has greater than 8 years of expertise with large knowledge and machine studying tasks in monetary, retail, vitality, and chemical industries. He’s presently main the Knowledge, Superior Analytics & Cloud Improvement staff within the Digital, IT, Transformation & Operational Excellence division at Cepsa Química, with a spotlight in feeding the company knowledge lake and democratizing knowledge for evaluation, machine studying tasks, and enterprise analytics. Since 2023, he has additionally been engaged on scaling using generative AI in all departments.
 Marcos Fernández Díaz is a Senior Knowledge Scientist at Keepler, with 10 years of expertise growing end-to-end machine studying options for various shoppers and domains, together with predictive upkeep, time sequence forecasting, picture classification, object detection, industrial course of optimization, and federated machine studying. His principal pursuits embody pure language processing and generative AI. Exterior of labor, he’s a journey fanatic.
Marcos Fernández Díaz is a Senior Knowledge Scientist at Keepler, with 10 years of expertise growing end-to-end machine studying options for various shoppers and domains, together with predictive upkeep, time sequence forecasting, picture classification, object detection, industrial course of optimization, and federated machine studying. His principal pursuits embody pure language processing and generative AI. Exterior of labor, he’s a journey fanatic.
 Guillermo Menéndez Corral is a Sr. Supervisor, Options Structure at AWS for Vitality and Utilities. He has over 18 years of expertise designing and constructing software program merchandise and presently helps AWS clients within the vitality {industry} harness the facility of the cloud by innovation and modernization.
Guillermo Menéndez Corral is a Sr. Supervisor, Options Structure at AWS for Vitality and Utilities. He has over 18 years of expertise designing and constructing software program merchandise and presently helps AWS clients within the vitality {industry} harness the facility of the cloud by innovation and modernization.





