PyramidInfer: Permitting Environment friendly KV Cache Compression for Scalable LLM Inference
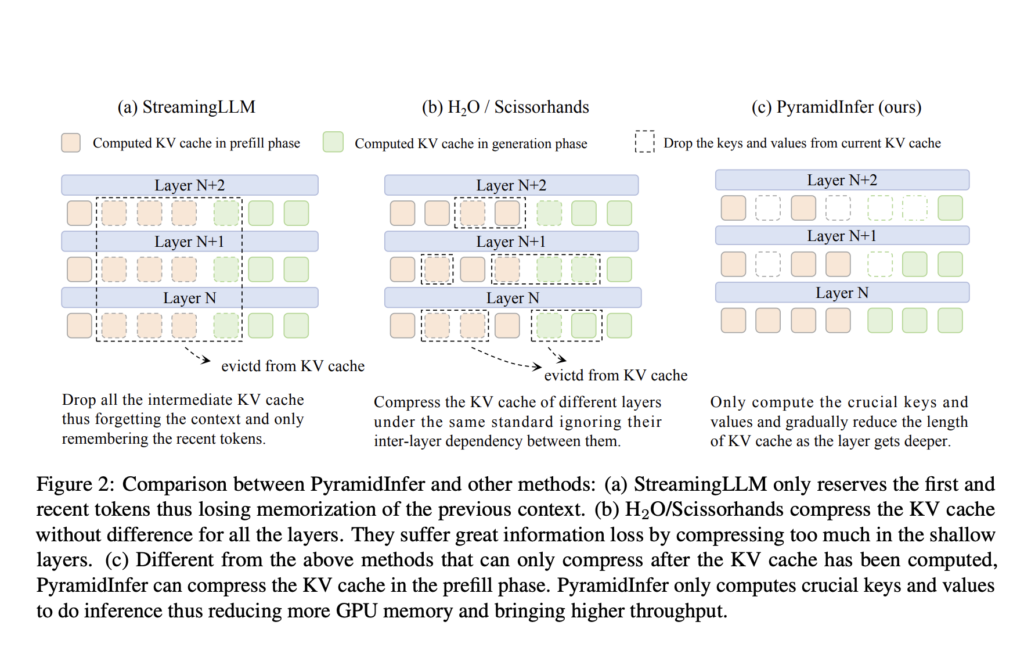
LLMs like GPT-4 excel in language comprehension however wrestle with excessive GPU reminiscence utilization throughout inference, limiting their scalability for real-time functions like chatbots. Current strategies scale back reminiscence by compressing the KV cache however overlook inter-layer dependencies and pre-computation reminiscence calls for. Inference reminiscence utilization primarily comes from mannequin parameters and the KV cache, with the latter consuming considerably extra reminiscence. For example, a 7 billion parameter mannequin makes use of 14 GB for parameters however 72 GB for the KV cache. This substantial reminiscence requirement restricts the throughput of LLM inference on GPUs.
Researchers from Shanghai Jiao Tong College, Xiaohongshu Inc., and South China College of Expertise developed PyramidInfer, which boosts LLM inference by compressing the KV cache. Not like present strategies that overlook inter-layer dependencies and the reminiscence calls for of pre-computation, PyramidInfer retains solely essential context keys and values layer-by-layer. Impressed by latest tokens’ consistency in consideration weights, this strategy considerably reduces GPU reminiscence utilization. Experiments present PyramidInfer improves throughput by 2.2x and reduces KV cache reminiscence by over 54% in comparison with present strategies, demonstrating its effectiveness throughout varied duties and fashions.
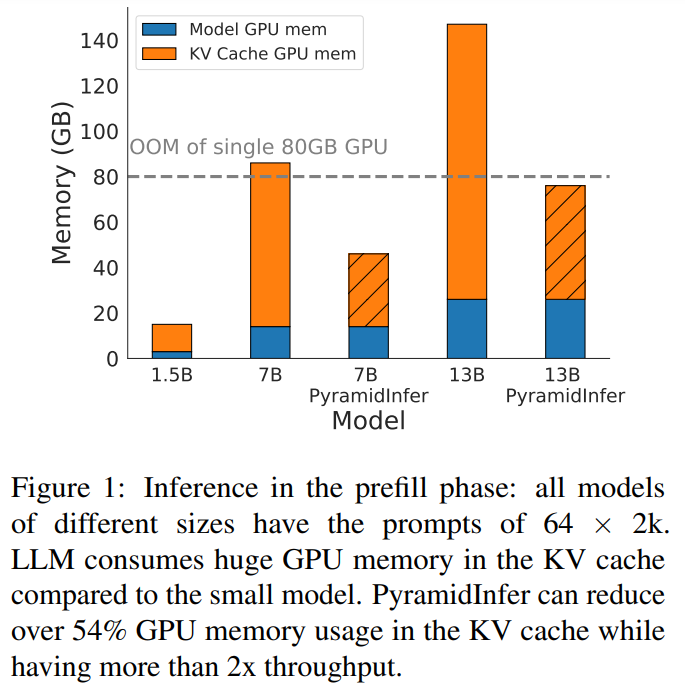
Environment friendly methods are important to deal with the rising demand for chatbot queries, aiming to maximise throughput by leveraging GPU parallelism. One strategy is rising GPU reminiscence by way of pipeline parallelism and KV cache offload, using a number of GPUs or RAM. For restricted GPU reminiscence, lowering the KV cache is an alternative choice. Strategies like FlashAttention 2 and PagedAttention reduce reminiscence waste by optimizing CUDA operations. Strategies similar to StreamingLLM, H2O, and Scissorhands compress the KV cache by specializing in latest context or consideration mechanisms however overlook layer variations and prefill part compression. PyramidInfer addresses these gaps by contemplating layer-specific compression in each phases.
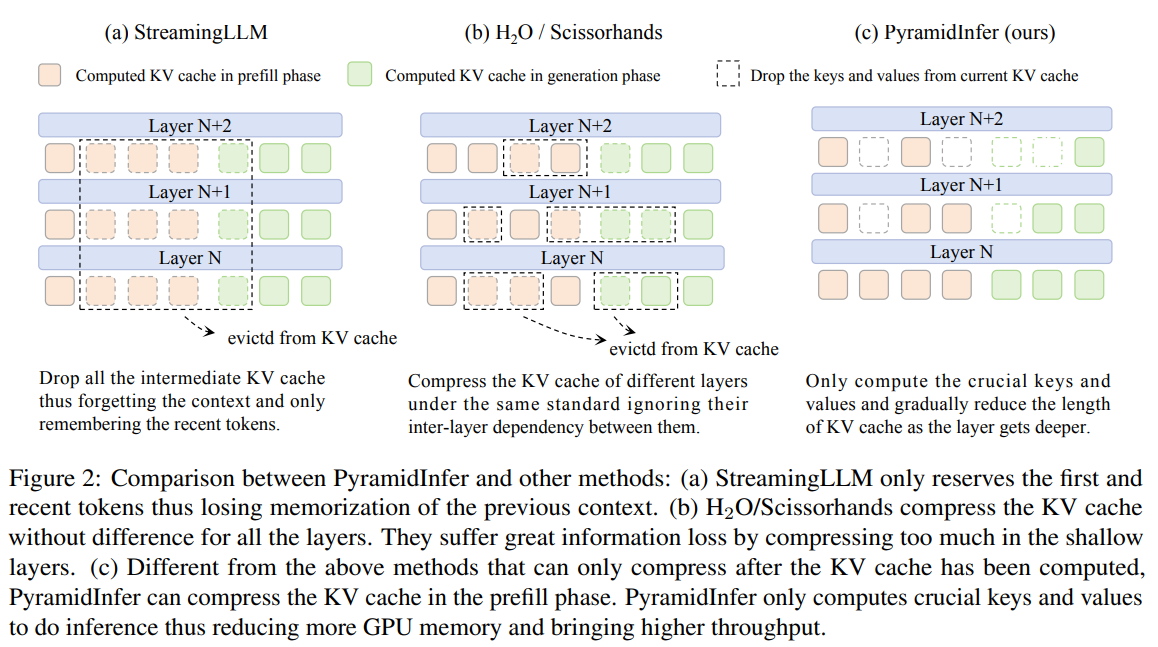
Verification of the Inference Context Redundancy (ICR) and Latest Consideration Consistency (RAC) hypotheses impressed the design of PyramidInfer. ICR posits that many context keys and values are redundant throughout inference and are solely obligatory in coaching to foretell the subsequent token. Experiments with a 40-layer LLaMA 2-13B mannequin revealed that deeper layers have larger redundancy, permitting for important KV cache discount with out affecting output high quality. RAC confirms that sure keys and values are persistently attended by latest tokens, enabling the collection of pivotal contexts (PVCs) for environment friendly inference. PyramidInfer leverages these insights to compress the KV cache successfully in each prefill and era phases.
PyramidInfer’s efficiency was evaluated throughout varied duties and fashions, demonstrating important reductions in GPU reminiscence utilization and elevated throughput whereas sustaining era high quality. The analysis included language modeling on wikitext-v2, LLM benchmarks like MMLU and BBH, mathematical reasoning with GSM8K, coding by way of HumanEval, dialog dealing with with MT-Bench, and lengthy textual content summarization utilizing LEval. PyramidInfer was examined on fashions similar to LLaMA 2, LLaMA 2-Chat, Vicuna 1.5-16k, and CodeLLaMA throughout completely different sizes. Outcomes confirmed that PyramidInfer successfully maintained era high quality with much less GPU reminiscence than full cache strategies and considerably outperformed native methods.
In conclusion, PyramidInfer introduces an environment friendly methodology to compress the KV cache throughout each prefill and era phases, impressed by ICR and RAC. This strategy considerably reduces GPU reminiscence utilization with out compromising mannequin efficiency, making it supreme for deploying massive language fashions in resource-constrained environments. Regardless of its effectiveness, PyramidInfer requires further computation, limiting speedup with small batch sizes. As the primary to compress the KV cache within the prefill part, PyramidInfer is but to be a lossless methodology, indicating potential for future enhancements on this space.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
When you like our work, you’ll love our newsletter..
Don’t Neglect to affix our 42k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is keen about making use of know-how and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.




