Speed up Mixtral 8x7B pre-training with professional parallelism on Amazon SageMaker
Combination of Consultants (MoE) architectures for giant language fashions (LLMs) have lately gained recognition attributable to their capacity to extend mannequin capability and computational effectivity in comparison with totally dense fashions. By using sparse professional subnetworks that course of totally different subsets of tokens, MoE fashions can successfully enhance the variety of parameters whereas requiring much less computation per token throughout coaching and inference. This permits more cost effective coaching of bigger fashions inside fastened compute budgets in comparison with dense architectures.
Regardless of their computational advantages, coaching and fine-tuning massive MoE fashions effectively presents some challenges. MoE fashions can battle with load balancing if the tokens aren’t evenly distributed throughout consultants throughout coaching, and a few consultants could turn out to be overloaded whereas others are under-utilized. MoE fashions have excessive reminiscence necessities, as a result of all professional parameters must be loaded into reminiscence despite the fact that solely a subset is used for every enter.
On this put up, we spotlight new options of the Amazon SageMaker mannequin parallelism library that allow environment friendly coaching of MoE fashions utilizing professional parallelism. Knowledgeable parallelism is a kind of parallelism that handles splitting consultants of an MoE mannequin throughout separate employees or units, much like how tensor parallelism can partition dense mannequin layers. We display how you can use these new options of SMP by pre-training the 47 billion parameter Mixtral 8x7B MoE mannequin utilizing professional parallelism. To study extra, discuss with our GitHub repo and Expert parallelism.
Knowledgeable parallelism
The Mixtral 8x7B mannequin has a sparse MoE structure, containing eight professional subnetworks with round 7 billion parameters every. A trainable gate community referred to as a router determines which enter tokens are despatched to which professional. With this structure, the consultants specialise in processing totally different elements of the enter information. The entire Mixtral 8x7B mannequin has a complete of 47 billion parameters, however solely round 12.9 billion (two consultants, for this mannequin structure) are activated for any given enter token; this ends in improved computational effectivity relative to a dense mannequin of the identical whole measurement. To study extra in regards to the MoE structure typically, discuss with Applying Mixture of Experts in LLM Architectures.
SMP provides assist for professional parallelism
SMP now helps professional parallelism, which is crucial to performant MoE mannequin coaching. With professional parallelism, totally different professional subnetworks that comprise the MoE layers are positioned on separate units. Throughout coaching, totally different information is routed to the totally different units, with every gadget dealing with the computation for the consultants it comprises. By distributing consultants throughout employees, professional parallelism addresses the excessive reminiscence necessities of loading all consultants on a single gadget and permits MoE coaching on a bigger cluster. The next determine gives a simplified take a look at how professional parallelism works on a multi-GPU cluster.
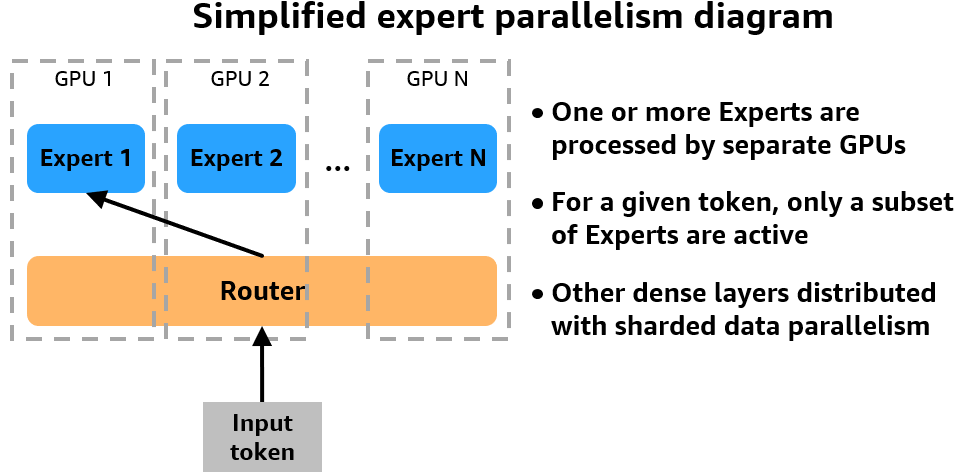
The SMP library makes use of NVIDIA Megatron to implement professional parallelism and assist coaching MoE fashions, and runs on prime of PyTorch Totally Sharded Knowledge Parallel (FSDP) APIs. You may hold utilizing your PyTorch FSDP coaching code as is and activate SMP professional parallelism for coaching MoE fashions. SMP gives a simplified workflow the place you could specify the expert_parallel_degree parameter, which is able to evenly divide consultants throughout the variety of GPUs in your cluster. For instance, to shard your mannequin whereas utilizing an occasion with 8 GPUs, you possibly can set the expert_parallel_degree to 2, 4, or 8. We suggest that you simply begin with a small quantity and regularly enhance it till the mannequin suits within the GPU reminiscence.
SMP’s professional parallelism is suitable with sharded information parallelism
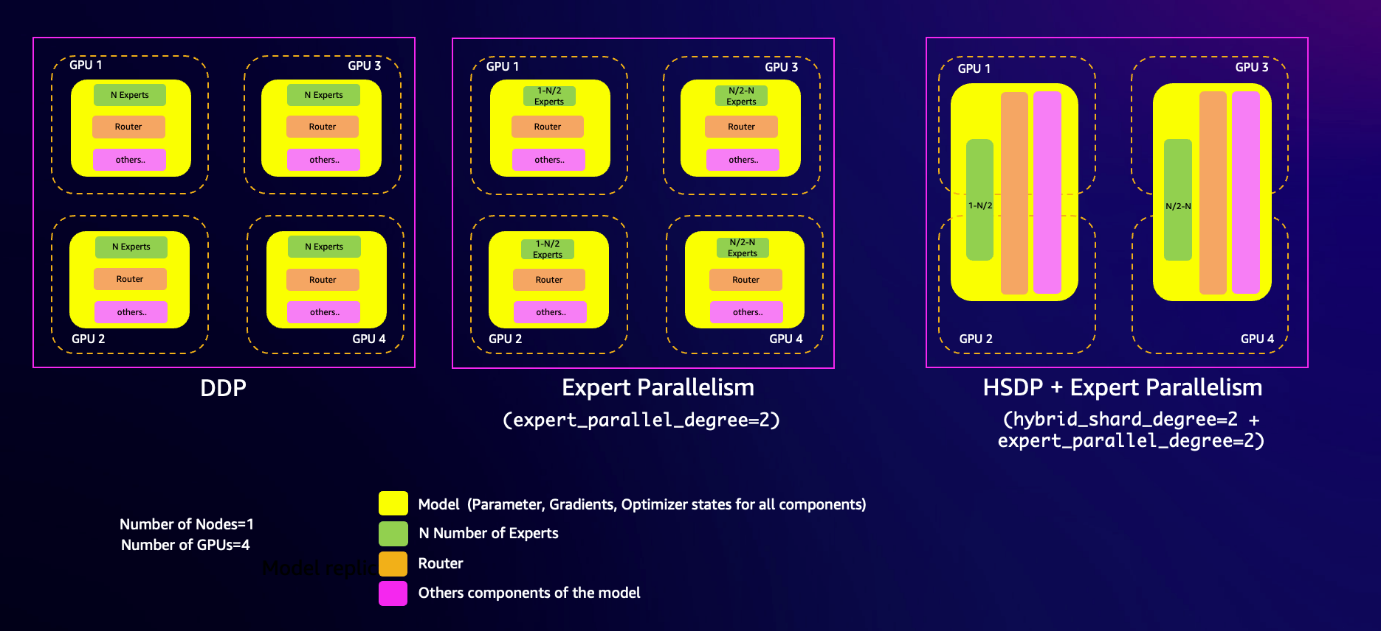
SMP’s professional parallel implementation is suitable with sharded information parallelism, enabling extra memory-efficient and sooner coaching. To grasp how this works, contemplate an MoE mannequin within the following instance with eight consultants (N=8) coaching on a easy cluster with one node containing 4 GPUs.
SMP’s professional parallelism splits the MoE consultants throughout GPUs. You management what number of consultants are instantiated on every gadget by utilizing the expert_parallel_degree parameter. For instance, in case you set the diploma to 2, SMP will assign half of the eight consultants to every information parallel group. The diploma worth should be an element of the variety of GPUs in your cluster and the variety of consultants in your mannequin. Knowledge is dynamically routed to and from the GPU or GPUs internet hosting the chosen professional utilizing all-to-all GPU communication.
Subsequent, sharded information parallelism partitions and distributes the consultants in addition to the non-MoE layers of the mannequin, like consideration or routers, throughout your cluster to scale back the reminiscence footprint of the mannequin. The hybrid_shard_degree parameter controls this. For instance, a hybrid_shard_degree of two will shard the mannequin states (together with consultants and non-MoE layers) throughout half of the GPUs in our cluster. The product of expert_parallel_degree and hybrid_shard_degree mustn’t exceed the world measurement of the cluster. Within the following instance, hybrid_shard_degree * expert_parallel_degree = 4 is a legitimate configuration.
Answer overview
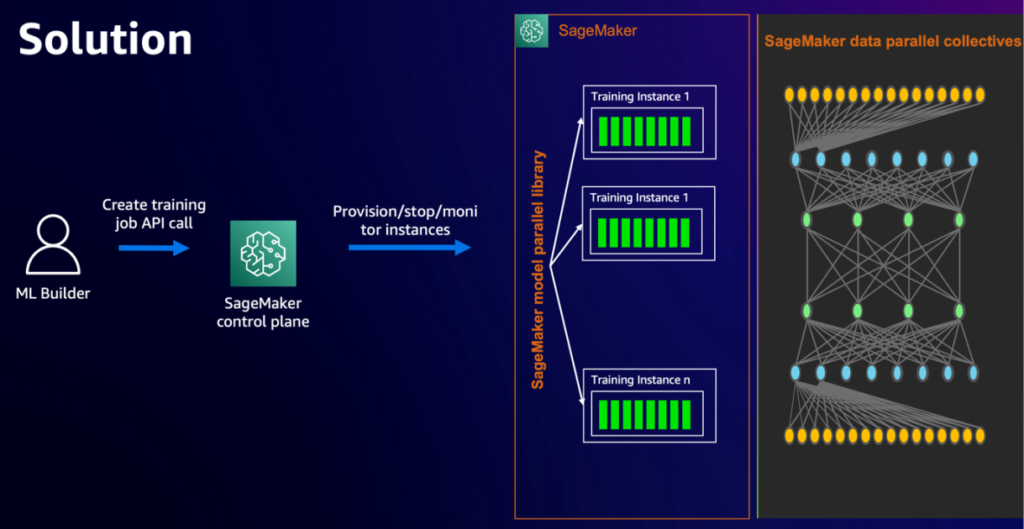
With the background out of the way in which, let’s dig into the elements of our distributed coaching structure. The next diagram illustrates the answer structure.
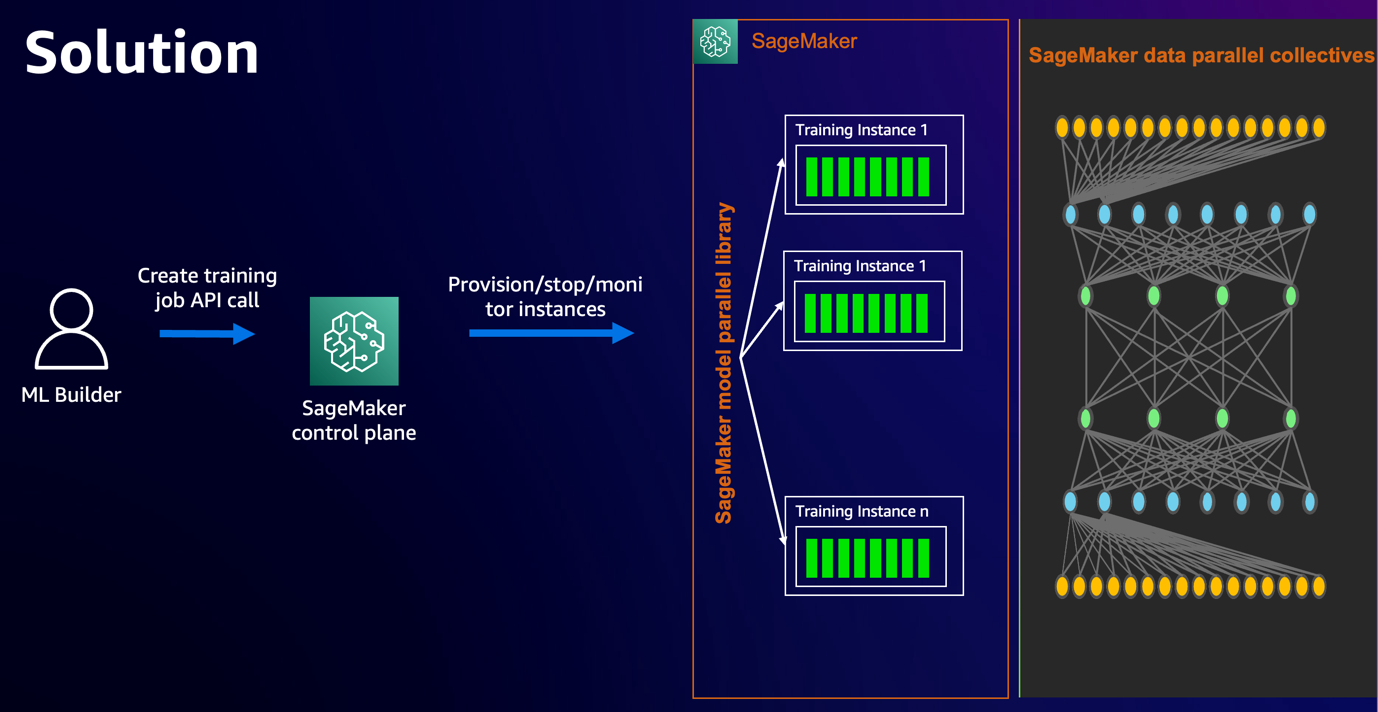
On this instance, we use SageMaker coaching jobs. With SageMaker coaching jobs, you possibly can launch and handle clusters of high-performance cases with easy API calls. For instance, you need to use the SageMaker Estimator to specify the kind and amount of cases to make use of in your distributed programs with only a few traces of code. Later on this put up, we use a cluster of two ml.p4d.24xlarge cases to coach our mannequin by specifying these parameters in our Estimator. To study SageMaker coaching jobs, see Train a Model with Amazon SageMaker.
On this put up, we use the SMP library to effectively distribute the workload throughout the cluster utilizing hybrid sharded information parallelism and professional parallelism. Along with these implementations, SMP gives many different performance-improving and memory-saving methods, equivalent to:
- Blended precision coaching and fp8 assist for dense Llama fashions (which accelerates distributed coaching and takes benefit of the efficiency enhancements on P5 cases)
- Tensor parallelism composable with sharded information parallelism
- Delayed parameter initialization
- Activation checkpointing (a method to scale back reminiscence utilization by clearing activations of sure layers and recomputing them through the backward go)
For the newest updates, discuss with SageMaker model parallelism library v2.
Together with SMP, this instance additionally makes use of the SageMaker distributed information parallel library (SMDDP). As you scale your workload and add cases to your cluster, the overhead of communication between cases additionally will increase, which may result in a drop in general computational efficiency and coaching effectivity. That is the place SMDDP helps. SMDDP consists of optimized communication collectives equivalent to AllGather which are designed for AWS community infrastructure. Due to this, SMDDP can outperform different extra common communications libraries equivalent to NCCL when coaching on SageMaker.
Collectively, the SMP and SMDDP libraries can speed up massive distributed coaching workloads by as much as 20%. Moreover, these libraries are suitable with customary PyTorch APIs and capabilities, which makes it handy to adapt any present PyTorch FSDP coaching script to the SageMaker coaching platform and make the most of the efficiency enhancements that SMP and SMDDP present. To study extra, see SageMaker model parallelism library v2 and Run distributed training with the SageMaker distributed data parallelism library.
Within the following sections, we showcase how one can speed up distributed coaching of the Hugging Face Transformers Mixtral 8*7B mannequin on P4 cases utilizing SMP and SMDDP.
Stipulations
You want to full some stipulations earlier than you possibly can run the Mixtral pocket book.
First, ensure you have created a Hugging Face access token so you possibly can obtain the Hugging Face tokenizer for use later. After you might have the entry token, you could make a couple of quota enhance requests for SageMaker. You want to request a minimal of two P4d cases ranging to a most of 8 P4d cases (relying on time-to-train and cost-to-train trade-offs in your use case).
On the Service Quotas console, request the next SageMaker quotas:
- P4 cases (ml.p4d.24xlarge) for coaching job utilization: 2–8
It might take as much as 24 hours for the quota enhance to get accepted.
Now that you simply’re prepared to start the method to pre-train the Mixtral mannequin, we begin with dataset preparation within the subsequent step.
Put together the dataset
We start our tutorial with making ready the dataset. It will cowl loading the GLUE/SST2 dataset, tokenizing and chunking the dataset, and configuring the information channels for SageMaker coaching on Amazon Simple Storage Service (Amazon S3). Full the next steps:
- You first have to load the GLUE/SST2 dataset and cut up it into coaching and validation datasets:
- Load the Mixtral-8x7B tokenizer from the Hugging Face Transformers library:
Subsequent, you outline two utility capabilities: tokenize_function() and group_texts(). The tokenize_function() runs the tokenizer on the textual content information. The group_texts() operate concatenates all texts from the dataset and generates chunks of a block measurement that corresponds to the mannequin’s enter size (2048) for this instance. By chunking the textual content information into smaller items, you be sure that the mannequin can course of all the dataset throughout coaching, even when some textual content examples are longer than the enter size (2048).
- Outline the capabilities with the next code:
- Name the previous utility capabilities in your dataset to tokenize and generate chunks appropriate for the mannequin:
- Put together the coaching and validation datasets for SageMaker coaching by saving them as JSON information and developing the S3 paths the place these information will likely be uploaded:
- Lastly, arrange the information channels for SageMaker coaching by creating TrainingInput objects from the offered S3 bucket paths for the coaching and take a look at/validation datasets:
You’re now able to run pre-training or fine-tuning on the dataset.
Pre-train Mixtral 8x7B with professional parallelism on SMP
To pre-train the Mixtral 8x7B mannequin, full the next steps:
- Initialize the script with
torch.sagemaker.init()to activate the SMP library: - Import the MoEConfig class from the torch.sagemaker.transform API. We use the MoEConfig class to allow the mannequin to make use of the SMP implementation of MoE:
- Create a mannequin configuration for Mixtral 8x7B mannequin. This will likely be handed to
AutoModelForCausalLM.from_config(model_config, attn_implementation="flash_attention_2") from the Hugging Face Transformers library to initialize the mannequin with random weights. If you wish to fine-tune, you possibly can present the trail to the pre-trained weights as a substitute of the mannequin configuration.
Within the example Jupyter Notebook, you employ a create_model() operate that invokes the AutoModelForCausalLM.from_config() operate.
- Create the SMP MoE configuration class. Within the following code, you specify parameters within the coaching estimator within the subsequent steps. To study extra in regards to the SMP MoEConfig class, see torch.sagemaker.moe.moe_config.MoEConfig.
- With the mannequin and MoE configuration prepared, you wrap the mannequin with the SMP remodel API and go the MoE configuration. Right here, the
tsm.remodeltechnique adapts the mannequin from Hugging Face format to SMP format. For extra info, discuss with torch.sagemaker.transform. - Outline the coaching hyperparameters, together with the MoE configuration and different settings particular to the mannequin and coaching setup:
We allow delayed parameter initialization in SMP, which permits initializing massive fashions on a meta gadget with out attaching information. This will resolve restricted GPU reminiscence points if you first load the mannequin. This strategy is especially helpful for coaching LLMs with tens of billions of parameters, the place even CPU reminiscence may not be ample for initialization.
SMP helps varied routing methods, together with sinkhorn, balanced, and aux_loss. Every supplies distinct load balancing approaches to realize equitable token project amongst consultants, thereby sustaining balanced workload distribution.
- Specify the parameters for expert_parallel_degree and hybrid_shard_degree:
Hybrid sharding is a reminiscence saving approach between `FULL_SHARD` and `NO_SHARD`, with `FULL_SHARD` saving probably the most reminiscence and `NO_SHARD` not saving any. This method shards parameters inside the hybrid shard diploma (HSD) group and replicates parameters throughout teams. The HSD controls sharding throughout GPUs and will be set to an integer from 0 to `world_size`.
An HSD of 8 applies `FULL_SHARD` inside a node after which replicates parameters throughout nodes as a result of there are 8 GPUs within the nodes we’re utilizing. This ends in lowered communication quantity as a result of costly all-gathers and reduce-scatters are solely completed inside a node, which will be extra performant for medium-sized fashions. Typically, you wish to use the smallest HSD that doesn’t trigger out of reminiscence (OOM) errors. If you happen to’re experiencing OOM, attempt rising the hybrid shard diploma to scale back reminiscence utilization on every node.
- With all the mandatory configurations in place, you now create the PyTorch estimator operate to encapsulate the coaching setup and launch the coaching job. We run the pre-training on the two ml.p4d.24xlarge cases, the place every occasion comprises 8 A100 Nvidia GPUs:
- Lastly, launch the pre-training workload:
Clear up
As a part of cleanup, you possibly can delete the SageMaker default bucket created to host the GLUE/SST2 dataset.
Conclusion
Coaching massive MoE language fashions just like the 47 billion parameter Mistral 8x7B will be difficult attributable to excessive computational and reminiscence necessities. By utilizing professional parallelism and sharded information parallelism from the SageMaker mannequin parallelism library, you possibly can successfully scale these MoE architectures throughout a number of GPUs and employees.
SMP’s professional parallelism implementation seamlessly integrates with PyTorch and the Hugging Face Transformers library, permitting you to allow MoE coaching utilizing easy configuration flags with out altering your present mannequin code. Moreover, SMP supplies efficiency optimizations like hybrid sharding, delayed parameter initialization, and activation offloading and recomputation to additional enhance coaching effectivity.
For the entire pattern to pre-train and fine-tune Mixtral 8x7B, see the GitHub repo.
Particular thanks
Particular because of Rahul Huilgol, Gautam Kumar, and Luis Quintela for his or her steering and engineering management in creating this new functionality.
In regards to the Authors
 Roy Allela is a Senior AI/ML Specialist Options Architect at AWS primarily based in Munich, Germany. Roy helps AWS clients—from small startups to massive enterprises—prepare and deploy massive language fashions effectively on AWS. Roy is enthusiastic about computational optimization issues and enhancing the efficiency of AI workloads.
Roy Allela is a Senior AI/ML Specialist Options Architect at AWS primarily based in Munich, Germany. Roy helps AWS clients—from small startups to massive enterprises—prepare and deploy massive language fashions effectively on AWS. Roy is enthusiastic about computational optimization issues and enhancing the efficiency of AI workloads.
 Kanwaljit Khurmi is a Principal Options Architect at Amazon Internet Providers. He works with AWS clients to offer steering and technical help, serving to them enhance the worth of their options when utilizing AWS. Kanwaljit focuses on serving to clients with containerized and machine studying purposes.
Kanwaljit Khurmi is a Principal Options Architect at Amazon Internet Providers. He works with AWS clients to offer steering and technical help, serving to them enhance the worth of their options when utilizing AWS. Kanwaljit focuses on serving to clients with containerized and machine studying purposes.
 Robert Van Dusen is a Senior Product Supervisor with Amazon SageMaker. He leads frameworks, compilers, and optimization methods for deep studying coaching.
Robert Van Dusen is a Senior Product Supervisor with Amazon SageMaker. He leads frameworks, compilers, and optimization methods for deep studying coaching.
 Teng Xu is a Software program Improvement Engineer within the Distributed Coaching group in AWS AI. He enjoys studying.
Teng Xu is a Software program Improvement Engineer within the Distributed Coaching group in AWS AI. He enjoys studying.
 Suhit Kodgule is a Software program Improvement Engineer with the AWS Synthetic Intelligence group engaged on deep studying frameworks. In his spare time, he enjoys climbing, touring, and cooking.
Suhit Kodgule is a Software program Improvement Engineer with the AWS Synthetic Intelligence group engaged on deep studying frameworks. In his spare time, he enjoys climbing, touring, and cooking.