Create a multimodal assistant with superior RAG and Amazon Bedrock
Retrieval Augmented Technology (RAG) fashions have emerged as a promising method to boost the capabilities of language fashions by incorporating exterior data from giant textual content corpora. Nonetheless, regardless of their spectacular efficiency in numerous pure language processing duties, RAG fashions nonetheless face a number of limitations that should be addressed.
Naive RAG fashions face limitations similar to lacking content material, reasoning mismatch, and challenges in dealing with multimodal information. Though they will retrieve related info, they might battle to generate full and coherent responses when required info is absent, resulting in incomplete or inaccurate outputs. Moreover, even with related info retrieved, the fashions could have problem accurately deciphering and reasoning over the content material, leading to inconsistencies or logical errors. Moreover, successfully understanding and reasoning over multimodal information stays a big problem for these primarily text-based fashions.
On this submit, we current a brand new method named multimodal RAG (mmRAG) to sort out these current limitations in higher element. The answer intends to deal with these limitations for sensible generative artificial intelligence (AI) assistant use instances. Moreover, we study potential options to boost the capabilities of enormous language fashions (LLMs) and visible language fashions (VLMs) with superior LangChain capabilities, enabling them to generate extra complete, coherent, and correct outputs whereas successfully dealing with multimodal information. The answer makes use of Amazon Bedrock, a totally managed service that gives a alternative of high-performing basis fashions (FMs) from main AI firms, offering a broad set of capabilities to construct generative AI purposes with safety, privateness, and accountable AI.
Answer structure
The mmRAG answer is predicated on a simple idea: to extract totally different information varieties individually, you generate textual content summarization utilizing a VLM from totally different information varieties, embed textual content summaries together with uncooked information accordingly to a vector database, and retailer uncooked unstructured information in a doc retailer. The question will immediate the LLM to retrieve related vectors from each the vector database and doc retailer and generate significant and correct solutions.
The next diagram illustrates the answer structure.

The structure diagram depicts the mmRAG structure that integrates superior reasoning and retrieval mechanisms. It combines textual content, desk, and picture (together with chart) information right into a unified vector illustration, enabling cross-modal understanding and retrieval. The method begins with various information extractions from numerous sources similar to URLs and PDF information by parsing and preprocessing textual content, desk, and picture information varieties individually, whereas desk information is transformed into uncooked textual content and picture information into captions.
These parsed information streams are then fed right into a multimodal embedding mannequin, which encodes the varied information varieties into uniform, excessive dimensional vectors. The ensuing vectors, representing the semantic content material no matter unique format, are listed in a vector database for environment friendly approximate similarity searches. When a question is obtained, the reasoning and retrieval part performs similarity searches throughout this vector area to retrieve probably the most related info from the huge built-in data base.
The retrieved multimodal representations are then utilized by the era part to provide outputs similar to textual content, pictures, or different modalities. The VLM part generates vector representations particularly for textual information, additional enhancing the system’s language understanding capabilities. Total, this structure facilitates superior cross-modal reasoning, retrieval, and era by unifying totally different information modalities into a standard semantic area.
Builders can entry mmRAG supply codes on the GitHub repo.
Configure Amazon Bedrock with LangChain
You begin by configuring Amazon Bedrock to combine with numerous elements from the LangChain Community library. This lets you work with the core FMs. You employ the BedrockEmbeddings class to create two totally different embedding fashions: one for textual content (embedding_bedrock_text) and one for pictures (embeddings_bedrock_image). These embeddings characterize textual and visible information in a numerical format, which is crucial for numerous pure language processing (NLP) duties.
Moreover, you employ the LangChain Bedrock and BedrockChat courses to create a VLM mannequin occasion (llm_bedrock_claude3_haiku) from Anthropic Claude 3 Haiku and a chat occasion primarily based on a special mannequin, Sonnet (chat_bedrock_claude3_sonnet). These cases are used for superior question reasoning, argumentation, and retrieval duties. See the next code snippet:
from langchain_community.embeddings import BedrockEmbeddings
from langchain_community.chat_models.bedrock import BedrockChat
embedding_bedrock_text = BedrockEmbeddings(consumer=boto3_bedrock, model_id="amazon.titan-embed-g1-text-02")
embeddings_bedrock_image = BedrockEmbeddings(consumer=boto3_bedrock, model_id="amazon.titan-embed-image-v1")
model_kwargs = {
"max_tokens": 2048,
"temperature": 0.0,
"top_k": 250,
"top_p": 1,
"stop_sequences": ["nnn"],
}
chat_bedrock_claude3_haiku = BedrockChat(
model_id="anthropic:claude-3-haiku-20240307-v1:0",
consumer=boto3_bedrock,
model_kwargs=model_kwargs,
)
chat_bedrock_claude3_sonnet = BedrockChat(
model_id="anthropic.claude-3-sonnet-20240229-v1:0",
consumer=boto3_bedrock,
model_kwargs=model_kwargs,
)Parse content material from information sources and embed each textual content and picture information
On this part, we discover learn how to harness the facility of Python to parse textual content, tables, and pictures from URLs and PDFs effectively, utilizing two highly effective packages: Beautiful Soup and PyMuPDF. Lovely Soup, a library designed for internet scraping, makes it easy to sift by way of HTML and XML content material, permitting you to extract the specified information from internet pages. PyMuPDF gives an intensive set of functionalities for interacting with PDF information, enabling you to extract not simply textual content but additionally tables and pictures with ease. See the next code:
from bs4 import BeautifulSoup as Soup
import fitz
def parse_tables_images_from_urls(url:str):
...
# Parse the HTML content material utilizing BeautifulSoup
soup = Soup(response.content material, 'html.parser')
# Discover all desk parts
tables = soup.find_all('desk')
# Discover all picture parts
pictures = soup.find_all('img')
...
def parse_images_tables_from_pdf(pdf_path:str):
...
pdf_file = fitz.open(pdf_path)
# Iterate by way of every web page
for page_index in vary(len(pdf_file)):
# Choose the web page
web page = pdf_file[page_index]
# Seek for tables on the web page
tables = web page.find_tables()
df = desk.to_pandas()
# Seek for pictures on the web page
pictures = web page.get_images()
image_info = pdf_file.extract_image(xref)
image_data = image_info["image"]
...The next code snippets reveal learn how to generate picture captions utilizing Anthropic Claude 3 by invoking the bedrock_get_img_description utility operate. Moreover, they showcase learn how to embed picture pixels together with picture captioning utilizing the Amazon Titan picture embedding mannequin amazon.titan_embeding_image_v1 by calling the get_text_embedding operate.
image_caption = bedrock_get_img_description(model_id,
immediate="You might be an knowledgeable at analyzing pictures in nice element. Your activity is to rigorously study the offered
mage and generate an in depth, correct textual description capturing the entire vital parts and
context current within the picture. Pay shut consideration to any numbers, information, or quantitative info seen,
and remember to embrace these numerical values together with their semantic which means in your description.
Totally learn and interpret the complete picture earlier than offering your detailed caption describing the
picture content material in textual content format. Attempt for a truthful and exact illustration of what's depicted",
picture=image_byteio,
max_token=max_token,
temperature=temperature,
top_p=top_p,
top_k=top_k,
stop_sequences="Human:")
image_sum_vectors = get_text_embedding(image_base64=image_base64, text_description=image_caption, embd_model_id=embd_model_id) Embedding and vectorizing multimodality information
You possibly can harness the capabilities of the newly launched Anthropic Claude 3 Sonnet and Haiku on Amazon Bedrock, mixed with the Amazon Titan picture embedding mannequin and LangChain. This highly effective mixture means that you can generate complete textual content captions for tables and pictures, seamlessly integrating them into your content material. Moreover, you possibly can retailer vectors, objects, uncooked picture file names, and supply paperwork in an Amazon OpenSearch Serverless vector retailer and object retailer. Use the next code snippets to create picture captions by invoking the utility operate bedrock_get_img_description. Embed picture pixels together with picture captions utilizing the Amazon Titan picture embedding mannequin amazon.titan_embeding_image_v1 by calling the get_text_embedding capabilities.
def get_text_embedding(image_base64=None, text_description=None, embd_model_id:str="amazon.titan-embed-image-v1"):
input_data = {}
if image_base64 isn't None:
input_data["inputImage"] = image_base64
if text_description isn't None:
input_data["inputText"] = text_description
if not input_data:
elevate ValueError("At the very least one in every of image_base64 or text_description should be offered")
physique = json.dumps(input_data)
response = boto3_bedrock.invoke_model(
physique=physique,
modelId=embd_model_id,
settle for="utility/json",
contentType="utility/json"
)
response_body = json.hundreds(response.get("physique").learn())
return response_body.get("embedding")
image_caption = bedrock_get_img_description(model_id,
immediate="You might be an knowledgeable at analyzing pictures in nice element. Your activity is to rigorously study the offered
mage and generate an in depth, correct textual description capturing the entire vital parts and
context current within the picture. Pay shut consideration to any numbers, information, or quantitative info seen,
and remember to embrace these numerical values together with their semantic which means in your description.
Totally learn and interpret the complete picture earlier than offering your detailed caption describing the
picture content material in textual content format. Attempt for a truthful and exact illustration of what's depicted",
picture=image_byteio,
max_token=max_token,
temperature=temperature,
top_p=top_p,
top_k=top_k,
stop_sequences="Human:")
image_sum_vectors = get_text_embedding(image_base64=image_base64, text_description=image_sum, embd_model_id=embd_model_id) You possibly can seek the advice of the offered code examples for extra info on learn how to embed multimodal and insert vector paperwork into the OpenSearch Serverless vector retailer. For extra details about information entry, discuss with Data access control for Amazon OpenSearch Serverless.
# Kind an information dictionary with picture metatadata, uncooked picture object retailer location and base64 encoded picture information
doc = {
"doc_source": image_url,
"image_filename": s3_image_path,
"embedding": image_base64
}
# Parse out solely the iamge identify from the complete temp path
filename = f"jsons/{image_path.cut up('/')[-1].cut up('.')[0]}.json"
# Writing the info dict into JSON information
with open(filename, 'w') as file:
json.dump(doc, file, indent=4)
#Load all json information from the temp listing
loader = DirectoryLoader("./jsons", glob='**/*.json', show_progress=False, loader_cls=TextLoader)
#loader = DirectoryLoader("./jsons", glob='**/*.json', show_progress=True, loader_cls=JSONLoader, loader_kwargs = {'jq_schema':'.content material'})
new_documents = loader.load()
new_docs = text_splitter.split_documents(new_documents)
# Insert into AOSS
new_docsearch = OpenSearchVectorSearch.from_documents(
new_docs,
bedrock_embeddings,
opensearch_url=host,
http_auth=auth,
timeout = 100,
use_ssl = True,
verify_certs = True,
connection_class = RequestsHttpConnection,
index_name=new_index_name,
engine="faiss",
)Superior RAG with fusion and decomposition
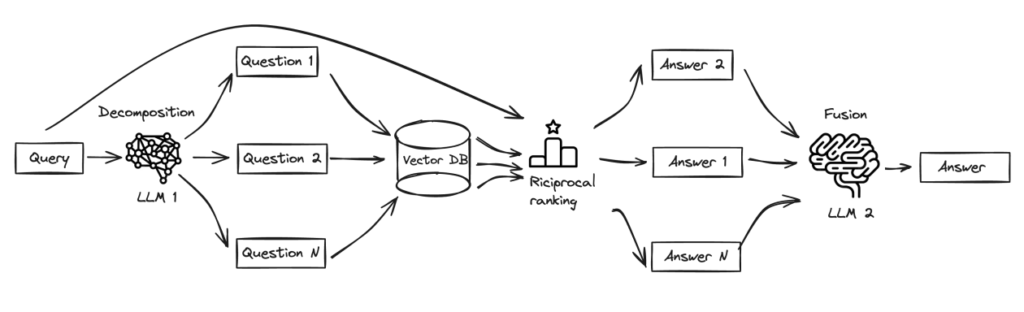
Fusion in RAG presents an modern search technique designed to transcend the restrictions of typical search methods, aligning extra carefully with the advanced nature of human inquiries. This initiative elevates the search expertise by integrating multi-faceted question era and utilizing Reciprocal Rank Fusion for an enhanced re-ranking of search outcomes. This method gives a extra nuanced and efficient approach to navigate the huge expanse of accessible info, catering to the intricate and diversified calls for of customers’ searches.
The next diagram illustrates this workflow.

We use the Anthropic Claude 3 Sonnet and Haiku fashions, which possess the potential to course of visible and language information, which allows them to deal with the question decomposition (Haiku) and reply fusion (Sonnet) levels successfully. The next code snippet demonstrates learn how to create a retriever utilizing OpenSearch Serverless:
from langchain.vectorstores import OpenSearchVectorSearch
retriever = OpenSearchVectorSearch(
opensearch_url = "{}.{}.aoss.amazonaws.com".format(<collection_id>, <my_region>),
index_name = <index_name>,
embedding_function = embd)The mix of decomposition and fusion intend to deal with the restrictions of the chain-of-thought (CoT) technique in language fashions. It entails breaking down advanced issues into easier, sequential sub-problems, the place every sub-problem builds upon the answer of the earlier one. This system considerably enhances the problem-solving talents of language fashions in areas similar to symbolic manipulation, compositional generalization, and mathematical reasoning.
The RAG-decomposition method, which makes use of the decomposition step (see the next code), underscores the potential of a method known as least-to-most prompting. This system not solely improves upon current strategies but additionally paves the way in which for extra superior, interactive studying frameworks for language fashions. The final word aim is to maneuver in direction of a future the place language fashions can study from bidirectional conversations, enabling simpler reasoning and problem-solving capabilities.
# Decomposition
prompt_rag = hub.pull("rlm/rag-prompt")
template = """You're a useful assistant that generates a number of sub-questions associated to an enter query. n
The aim is to interrupt down the enter right into a set of sub-problems / sub-questions that may be solutions in isolation. n
Generate a number of search queries semantically associated to: {query} n
Output (5 queries):"""
prompt_decomposition = ChatPromptTemplate.from_template(template)
generate_queries_decomposition = ( prompt_decomposition | llm_bedrock | StrOutputParser() | (lambda x: x.cut up("n")))
questions = generate_queries_decomposition.invoke({"query":query})
def reciprocal_rank_fusion(outcomes: checklist[list], ok=60):
# Initialize a dictionary to carry fused scores for every distinctive doc
fused_scores = {}
# Iterate by way of every checklist of ranked paperwork
for docs in outcomes:
# Iterate by way of every doc within the checklist, with its rank (place within the checklist)
for rank, doc in enumerate(docs):
# Convert the doc to a string format to make use of as a key (assumes paperwork may be serialized to JSON)
doc_str = dumps(doc)
# If the doc isn't but within the fused_scores dictionary, add it with an preliminary rating of 0
if doc_str not in fused_scores:
fused_scores[doc_str] = 0
# Retrieve the present rating of the doc, if any
previous_score = fused_scores[doc_str]
# Replace the rating of the doc utilizing the RRF method: 1 / (rank + ok)
fused_scores[doc_str] += 1 / (rank + ok)
# Type the paperwork primarily based on their fused scores in descending order to get the ultimate reranked outcomes
reranked_results = [
(loads(doc), score)
for doc, score in sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)
]
# Return the reranked outcomes as an inventory of tuples, every containing the doc and its fused rating
return reranked_results
def retrieve_and_rag(query,prompt_rag,sub_question_generator_chain):
sub_questions = sub_question_generator_chain.invoke({"query":query})
# Initialize an inventory to carry RAG chain outcomes
rag_results = []
for sub_question in sub_questions:
# Retrieve paperwork for every sub-question with reciprocal reranking
retrieved_docs = retrieval_chain_rag_fusion.invoke({"query": sub_question})
# Use retrieved paperwork and sub-question in RAG chain
reply = (prompt_rag
| chat_bedrock
| StrOutputParser()
| reciprocal_rank_fusion
).invoke({"context": retrieved_docs,"query": sub_question}
rag_results.append(reply)
return rag_results,sub_questions
def format_qa_pairs(questions, solutions):
"""Format Q and A pairs"""
formatted_string = ""
for i, (query, reply) in enumerate(zip(questions, solutions), begin=1):
formatted_string += f"Query {i}: {query}nAnswer {i}: {reply}nn"
return formatted_string.strip()
context = format_qa_pairs(questions, solutions)
# Immediate
template = """Here's a set of Q+A pairs:
{context}
Use these to synthesize a solution to the query: {query}
"""
prompt_fusion = ChatPromptTemplate.from_template(template)
final_rag_chain = (prompt_fusion | llm_bedrock| StrOutputParser())
# Decompsing and reciprocal reranking
retrieval_chain_rag_fusion = generate_queries_decomposition | retriever.map() | reciprocal_rank_fusion
# Wrap the retrieval and RAG course of in a RunnableLambda for integration into a series
solutions, questions = retrieve_and_rag(query, prompt_rag, generate_queries_decomposition)
final_rag_chain.invoke({"context":context,"query":query})The RAG course of is additional enhanced by integrating a reciprocal re-ranker, which makes use of subtle NLP methods. This makes certain the retrieved outcomes are related and likewise semantically aligned with the person’s supposed question. This multimodal retrieval method seamlessly operates throughout vector databases and object shops, marking a big development within the quest for extra environment friendly, correct, and contextually conscious search mechanisms.
Multimodality retrievals
The mmRAG structure allows the system to grasp and course of multimodal queries, retrieve related info from numerous sources, and generate multimodal solutions by combining textual, tabular, and visible info in a unified method. The next diagram highlights the info flows from queries to solutions by utilizing a sophisticated RAG and a multimodal retrieval engine powered by a multimodal embedding mannequin (amazon.titan-embed-image-v1), an object retailer (Amazon S3), and a vector database (OpenSearch Serverless). For tables, the system retrieves related desk places and metadata, and computes the cosine similarity between the multimodal embedding and the vectors representing the desk and its abstract. Equally, for pictures, the system retrieves related picture places and metadata, and computes the cosine similarity between the multimodal embedding and the vectors representing the picture and its caption.

# Connect with the AOSS with given host and index identify
docsearch = OpenSearchVectorSearch(
index_name=index_name, # TODO: use the identical index-name used within the ingestion script
embedding_function=bedrock_embeddings,
opensearch_url=host, # TODO: e.g. use the AWS OpenSearch area instantiated beforehand
http_auth=auth,
timeout = 100,
use_ssl = True,
verify_certs = True,
connection_class = RequestsHttpConnection,
engine="faiss",
)
# Question for pictures with textual content
question = "What's the math and reasoning rating MMMU (val) for Anthropic Claude 3 Sonnet ?"
t2i_results = docsearch.similarity_search_with_score(question, ok=3) # our search question # return 3 most related docs
# Or Question AOSS with picture aka image-to-image
with open(obj_image_path, "rb") as image_file:
image_data = image_file.learn()
image_base64 = base64.b64encode(image_data).decode('utf8')
image_vectors = get_image_embedding(image_base64=image_base64)
i2i_results = docsearch.similarity_search_with_score_by_vector(image_vectors, ok=3) # our search question # return 3 most related docs
The next screenshot illustrates the improved accuracy and complete understanding of the person’s question with multimodality functionality. The mmRAG method is able to greedy the intent behind the question, extracting related info from the offered chart, and estimating the general prices, together with the estimated output token measurement. Moreover, it might carry out mathematical calculations to find out the associated fee distinction. The output consists of the supply chart and a hyperlink to its unique location.

Use instances and limitations
Amazon Bedrock gives a complete set of generative AI fashions for enhancing content material comprehension throughout numerous modalities. By utilizing the newest developments in VLMs, similar to Anthropic Claude 3 Sonnet and Haiku, in addition to the Amazon Titan picture embedding mannequin, Amazon Bedrock lets you increase your doc understanding past textual content to incorporate tables, charts, and pictures. The combination of OpenSearch Serverless supplies enterprise-grade vector storage and approximate k-NN search capabilities, enabling environment friendly retrieval of related info. With superior LangChain decomposition and fusion methods, you need to use multi-step querying throughout totally different LLMs to enhance accuracy and achieve deeper insights. This highly effective mixture of cutting-edge applied sciences means that you can unlock the complete potential of multimodal content material comprehension, enabling you to make knowledgeable choices and drive innovation throughout numerous information sources.
The reliance on visible language fashions and picture embedding fashions for complete and correct picture captions has its limitations. Though these fashions excel at understanding visible and textual information, the multi-step question decomposition, reciprocal rating, and fusion processes concerned can result in elevated inference latency. This makes such options much less appropriate for real-time purposes or eventualities that demand instantaneous responses. Nonetheless, these options may be extremely useful in use instances the place increased accuracy and fewer time-sensitive responses are required, permitting for extra detailed and correct evaluation of advanced visible and textual information.
Conclusion
On this submit, we mentioned how you need to use multimodal RAG to deal with limitations in multimodal generative AI assistants. We invite you to discover mmRAG and make the most of the superior options of Amazon Bedrock. These highly effective instruments can help your corporation in gaining deeper insights, making well-informed choices, and fostering innovation pushed by extra correct information. Ongoing analysis efforts are targeted on growing an agenic and graph-based pipeline to streamline the processes of parsing, injection, and retrieval. These approaches maintain the promise of enhancing the reliability and reusability of the mmRAG system.
Acknowledgement
Authors wish to expression honest gratitude to Nausheen Sayed, Karen Twelves, Li Zhang, Sophia Shramko, Mani Khanuja, Santhosh Kuriakose, and Theresa Perkins for his or her complete opinions.
In regards to the Authors
 Alfred Shen is a Senior AI/ML Specialist at AWS. He has been working in Silicon Valley, holding technical and managerial positions in various sectors together with healthcare, finance, and high-tech. He’s a devoted utilized AI/ML researcher, concentrating on CV, NLP, and multimodality. His work has been showcased in publications similar to EMNLP, ICLR, and Public Well being.
Alfred Shen is a Senior AI/ML Specialist at AWS. He has been working in Silicon Valley, holding technical and managerial positions in various sectors together with healthcare, finance, and high-tech. He’s a devoted utilized AI/ML researcher, concentrating on CV, NLP, and multimodality. His work has been showcased in publications similar to EMNLP, ICLR, and Public Well being.
 Changsha Ma is an generative AI Specialist at AWS. She is a technologist with a PhD in Laptop Science, a grasp’s diploma in Training Psychology, and years of expertise in information science and impartial consulting in AI/ML. She is keen about researching methodological approaches for machine and human intelligence. Outdoors of labor, she loves mountaineering, cooking, looking meals, mentoring school college students for entrepreneurship, and spending time with associates and households.
Changsha Ma is an generative AI Specialist at AWS. She is a technologist with a PhD in Laptop Science, a grasp’s diploma in Training Psychology, and years of expertise in information science and impartial consulting in AI/ML. She is keen about researching methodological approaches for machine and human intelligence. Outdoors of labor, she loves mountaineering, cooking, looking meals, mentoring school college students for entrepreneurship, and spending time with associates and households.
 Julianna Delua is a Principal Specialist for AI/ML and generative AI. She serves the monetary providers trade clients together with these in Capital Markets, Fintech and Funds. Julianna enjoys serving to companies flip new concepts into options and remodel the organizations with AI-powered options.
Julianna Delua is a Principal Specialist for AI/ML and generative AI. She serves the monetary providers trade clients together with these in Capital Markets, Fintech and Funds. Julianna enjoys serving to companies flip new concepts into options and remodel the organizations with AI-powered options.





