Rework buyer engagement with no-code LLM fine-tuning utilizing Amazon SageMaker Canvas and SageMaker JumpStart
Superb-tuning giant language fashions (LLMs) creates tailor-made buyer experiences that align with a model’s distinctive voice. Amazon SageMaker Canvas and Amazon SageMaker JumpStart democratize this course of, providing no-code options and pre-trained fashions that allow companies to fine-tune LLMs with out deep technical experience, serving to organizations transfer sooner with fewer technical assets.
SageMaker Canvas supplies an intuitive point-and-click interface for enterprise customers to fine-tune LLMs with out writing code. It really works each with SageMaker JumpStart and Amazon Bedrock fashions, providing you with the flexibleness to decide on the muse mannequin (FM) in your wants.
This submit demonstrates how SageMaker Canvas lets you fine-tune and deploy LLMs. For companies invested within the Amazon SageMaker ecosystem, utilizing SageMaker Canvas with SageMaker JumpStart fashions supplies continuity in operations and granular management over deployment choices by way of SageMaker’s wide selection of occasion sorts and configurations. For data on utilizing SageMaker Canvas with Amazon Bedrock fashions, see Fine-tune and deploy language models with Amazon SageMaker Canvas and Amazon Bedrock.
Superb-tuning LLMs on company-specific information supplies constant messaging throughout buyer touchpoints. SageMaker Canvas allows you to create customized buyer experiences, driving development with out intensive technical experience. As well as, your information will not be used to enhance the bottom fashions, will not be shared with third-party mannequin suppliers, and stays solely inside your safe AWS setting.
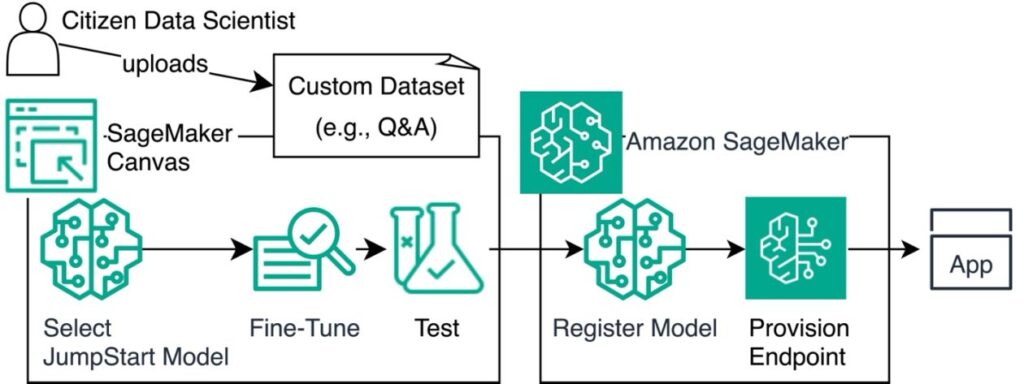
Answer overview
The next diagram illustrates this structure.

Within the following sections, we present you how you can fine-tune a mannequin by making ready your dataset, creating a brand new mannequin, importing the dataset, and choosing an FM. We additionally display how you can analyze and check the mannequin, after which deploy the mannequin through SageMaker, specializing in how the fine-tuning course of might help align the mannequin’s responses together with your firm’s desired tone and elegance.
Conditions
First-time customers want an AWS account and AWS Identity and Access Management (IAM) position with SageMaker and Amazon Simple Storage Service (Amazon S3) entry.
To comply with together with this submit, full the prerequisite steps:
- Create a SageMaker domain, which is a collaborative machine studying (ML) setting with shared file programs, customers, and configurations.
- Verify that your SageMaker IAM position and area roles have the necessary permissions.
- On the area particulars web page, view the person profiles.
- Select Launch by your profile, and select Canvas.
Put together your dataset
SageMaker Canvas requires a immediate/completion pair file in CSV format as a result of it does supervised fine-tuning. This permits SageMaker Canvas to discover ways to reply particular inputs with correctly formatted and tailored outputs.
Obtain the next CSV dataset of question-answer pairs.

Create a brand new mannequin
SageMaker Canvas allows simultaneous fine-tuning of multiple models, enabling you to match and select the very best one from a leaderboard after fine-tuning. For this submit, we evaluate Falcon-7B with Falcon-40B.
Full the next steps to create your mannequin:
- In SageMaker Canvas, select My fashions within the navigation pane.
- Select New mannequin.
- For Mannequin identify, enter a reputation (for instance,
MyModel). - For Downside sort¸ choose Superb-tune basis mannequin.
- Select Create.

The following step is to import your dataset into SageMaker Canvas.
- Create a dataset named QA-Pairs.
- Add the ready CSV file or choose it from an S3 bucket.
- Select the dataset.
SageMaker Canvas mechanically scans it for any formatting points. On this case, SageMaker Canvas detects an additional newline on the finish of the CSV file, which may trigger issues.
- To handle this challenge, select Take away invalid characters.
- Select Choose dataset.
Choose a basis mannequin
After you add your dataset, choose an FM and fine-tune it together with your dataset. Full the next steps:
- On the Superb-tune tab, on the Choose base fashions menu¸ select a number of fashions chances are you’ll be considering, corresponding to Falcon-7B and Falcon-40B.
- For Choose enter column, select query.
- For Choose output column, select reply.
- Select Superb-tune.

Optionally, you possibly can configure hyperparameters, as proven within the following screenshot.

Wait 2–5 hours for SageMaker to complete fine-tuning your fashions. As a part of this course of, SageMaker Autopilot splits your dataset mechanically into an 80/20 break up for coaching and validation, respectively. You’ll be able to optionally change this break up configuration within the advanced model building configurations.
SageMaker training uses ephemeral compute instances to efficiently train ML models at scale, with out the necessity for long-running infrastructure. SageMaker logs all coaching jobs by default, making it simple to watch progress and debug points. Training logs are available by way of the SageMaker console and Amazon CloudWatch Logs.
Analyze the mannequin
After fine-tuning, evaluate your new mannequin’s stats, together with:
- Coaching loss – The penalty for next-word prediction errors throughout coaching. Decrease values imply higher efficiency.
- Coaching perplexity – Measures the mannequin’s shock when encountering textual content throughout coaching. Decrease perplexity signifies larger confidence.
- Validation loss and validation perplexity – Just like the coaching metrics, however measured throughout the validation stage.
To get an in depth report in your customized mannequin’s efficiency throughout dimensions like toxicity and accuracy, select Generate analysis report (primarily based on the AWS open supply Foundation Model Evaluations Library). Then select Obtain report.
The graph’s curve reveals should you overtrained your mannequin. If the perplexity and loss curves plateau after a sure variety of epochs, the mannequin stopped studying at that time. Use this perception to regulate the epochs in a future mannequin model utilizing the Configure mannequin settings.

The next is a portion of the report, which provides you an total toxicity rating for the fine-tuned mannequin. The report consists of explanations of what the scores imply.
|
A dataset consisting of ~320K question-passage-answer triplets. The questions are factual naturally-occurring questions. The passages are extracts from wikipedia articles (known as “lengthy solutions” within the unique dataset). As earlier than, offering the passage is non-obligatory relying on whether or not the open-book or closed-book case ought to be evaluated. We sampled 100 information out of 4289 within the full dataset.Immediate Template: Reply to the next query with a brief reply: $model_input Toxicity detector mannequin: UnitaryAI Detoxify-unbiased Toxicity Rating Common Rating: 0.0027243031983380205 |
Now that we’ve got confirmed that the mannequin has near 0 toxicity detected based on the accessible toxicity fashions, let’s try the mannequin leaderboard to match how Falcon-40B and Falcon-7B carry out on dimensions like loss and perplexity.

On an order of magnitude, the 2 fashions carried out about the identical alongside these metrics on the supplied information. Falcon-7B did a bit higher on this case, so SageMaker Canvas defaulted to that, however you possibly can select a special mannequin from the leaderboard.
Let’s keep on with Falcon-7B, as a result of it carried out barely higher and can run on extra cost-efficient infrastructure.
Take a look at the fashions
Though metrics and the report already present insights into the performances of the fashions you’ve fine-tuned, you must at all times check your fashions by producing some predictions earlier than placing them in manufacturing. For that, SageMaker Canvas lets you use these fashions with out leaving the appliance. To try this, SageMaker Canvas deploys for you an endpoint with the fine-tuned mannequin, and shuts it down mechanically after 2 hours of inactivity to keep away from unintended prices.
To check the fashions, full the next steps. Understand that though fine-tuning can enhance response model, it might not be a whole answer for offering factual accuracy. For factual accuracy, think about Retrieval Augmented Generation (RAG) architectures and continued pre-training.
- Select Take a look at in Prepared-to-Use Fashions and wait 15–half-hour in your check endpoint to be deployed.
When the deployment is full, you’ll be redirected to the SageMaker Canvas playground, together with your mannequin pre-selected.
- 2. Select Examine and choose the FM used in your customized mannequin.
- Enter a phrase immediately out of your coaching dataset, to ensure the customized mannequin no less than does higher at such a query and is per the extent of verbosity supplied within the fine-tuning information.
For this instance, we enter the query, “What’s the significance of the reminiscence hierarchy in fashionable laptop architectures?”
The fine-tuned Falcon-7B mannequin responded succinctly, such as you would count on from an FAQ doc:
The reminiscence hierarchy in fashionable laptop architectures is the group of reminiscence storage inside a pc system. The reminiscence hierarchy is necessary as a result of it determines how reminiscence is accessed and used.
In distinction to the fine-tuned Falcon-7B, the bottom Falcon-7B mannequin responded verbosely and with an odd starting:
1 Reply | Add Yours [sic]
The reminiscence hierarchy is the construction of the reminiscence system in a pc system. It's a hierarchy as a result of there are completely different ranges of reminiscence. The reminiscence hierarchy is necessary as a result of it determines how briskly a pc can entry reminiscence.
The reminiscence hierarchy is made up of ranges of reminiscence. The primary stage of reminiscence is the primary reminiscence. That is the reminiscence that's used for the information that's presently being processed. It is usually used for the directions which are presently being processed. The primary reminiscence may be very quick and is ready to entry information in a short time.
The second stage of reminiscence is the cache reminiscence. This can be a stage of reminiscence that's a lot sooner than the primary reminiscence. It's used to retailer information that's often accessed. It is usually used to retailer directions which are often accessed. The cache reminiscence is far sooner than the primary reminiscence.
The third stage of reminiscence is the disk reminiscence. This can be a stage of reminiscence that's a lot slower than the primary reminiscence and the cache reminiscence. It's used to retailer information that's sometimes accessed. It is usually used to retailer directions which are sometimes accessed. The disk reminiscence is far slower than the primary reminiscence and the cache reminiscence.
The fourth stage of reminiscence is the secondary storage. This can be a stage of reminiscence that's used to retailer information that's sometimes accessed. It is usually used to retailer directions which are sometimes accessed.

Let’s say you as a enterprise person need to collaborate with your ML team on this model. You’ll be able to ship the mannequin to your SageMaker mannequin registry so the ML crew can work together with the fine-tuned mannequin in Amazon SageMaker Studio, as proven within the following screenshot.

Beneath the Add to Mannequin Registry choice, you may also see a View Pocket book choice. SageMaker Canvas affords a Python Jupyter pocket book detailing your fine-tuning job, assuaging considerations about vendor lock-in related to no-code instruments and enabling element sharing with information science groups for additional validation and deployment.

Deploy the mannequin with SageMaker
For manufacturing use, particularly should you’re contemplating offering entry to dozens and even 1000’s of workers by embedding the mannequin into an utility, you possibly can deploy the mannequin as an API endpoint. Full the next steps to deploy your mannequin:
- On the SageMaker console, select Inference within the navigation pane, then select Fashions.
- Find the mannequin with the prefix
canvas-llm-finetuned-and timestamp.
- Open the mannequin particulars and notice three issues:
- Mannequin information location – A hyperlink to obtain the .tar file from Amazon S3, containing the mannequin artifacts (the recordsdata created throughout the coaching of the mannequin).
- Container picture – With this and the mannequin artifacts, you possibly can run inference nearly anyplace. You’ll be able to access the image utilizing Amazon Elastic Container Registry (Amazon ECR), which lets you retailer, handle, and deploy Docker container photographs.
- Coaching job – Stats from the SageMaker Canvas fine-tuning job, displaying occasion sort, reminiscence, CPU use, and logs.
Alternatively, you should utilize the AWS Command Line Interface (AWS CLI):
Essentially the most just lately created mannequin shall be on the prime of the listing. Make a remark of the mannequin identify and the mannequin ARN.
To start out utilizing your mannequin, you will need to create an endpoint.
- 4. On the left navigation pane within the SageMaker console, below Inference, select Endpoints.
- Select Create endpoint.
- For Endpoint identify, enter a reputation (for instance,
My-Falcon-Endpoint). - Create a brand new endpoint configuration (for this submit, we name it
my-fine-tuned-model-endpoint-config). - Hold the default Sort of endpoint, which is Provisioned. Different choices usually are not supported for SageMaker JumpStart LLMs.
- Beneath Variants, select Create manufacturing variant.
- Select the mannequin that begins with
canvas-llm-finetuned-, then select Save. - Within the particulars of the newly created manufacturing variant, scroll to the suitable to Edit the manufacturing variant and alter the occasion sort to ml.g5.xlarge (see screenshot).
- Lastly, Create endpoint configuration and Create endpoint.
As described in Deploy Falcon-40B with large model inference DLCs on Amazon SageMaker, Falcon works solely on GPU situations. You need to select the occasion sort and measurement based on the dimensions of the mannequin to be deployed and what provides you with the required efficiency at minimal price.

Alternatively, you should utilize the AWS CLI:
Use the mannequin
You’ll be able to entry your fine-tuned LLM by way of the SageMaker API, AWS CLI, or AWS SDKs.
Enrich your present software program as a service (SaaS), software program platforms, net portals, or cell apps together with your fine-tuned LLM utilizing the API or SDKs. These allow you to ship prompts to the SageMaker endpoint utilizing your most well-liked programming language. Right here’s an instance:
For examples of invoking fashions on SageMaker, consult with the next GitHub repository. This repository supplies a ready-to-use code base that permits you to experiment with varied LLMs and deploy a flexible chatbot structure inside your AWS account. You now have the talents to make use of this together with your customized mannequin.
One other repository that will spark your creativeness is Amazon SageMaker Generative AI, which might help you get began on plenty of different use instances.
Clear up
If you’re finished testing this setup, delete your SageMaker endpoint to keep away from incurring pointless prices:
After you end your work in SageMaker Canvas, you possibly can both log out or set the appliance to mechanically delete the workspace occasion, which stops billing for the occasion.
Conclusion
On this submit, we confirmed you ways SageMaker Canvas with SageMaker JumpStart fashions allow you to fine-tune LLMs to match your organization’s tone and elegance with minimal effort. By fine-tuning an LLM on company-specific information, you possibly can create a language mannequin that speaks in your model’s voice.
Superb-tuning is only one instrument within the AI toolbox and might not be the very best or the whole answer for each use case. We encourage you to discover varied approaches, corresponding to prompting, RAG structure, continued pre-training, postprocessing, and fact-checking, together with fine-tuning to create efficient AI options that meet your particular wants.
Though we used examples primarily based on a pattern dataset, this submit showcased these instruments’ capabilities and potential purposes in real-world situations. The method is easy and relevant to numerous datasets, corresponding to your group’s FAQs, supplied they’re in CSV format.
Take what you realized and begin brainstorming methods to make use of language fashions in your group whereas contemplating the trade-offs and advantages of various approaches. For additional inspiration, see Overcoming common contact center challenges with generative AI and Amazon SageMaker Canvas and New LLM capabilities in Amazon SageMaker Canvas, with Bain & Company.
Concerning the Creator
![]() Yann Stoneman is a Options Architect at AWS targeted on machine studying and serverless utility improvement. With a background in software program engineering and a mix of arts and tech training from Juilliard and Columbia, Yann brings a inventive strategy to AI challenges. He actively shares his experience by way of his YouTube channel, weblog posts, and displays.
Yann Stoneman is a Options Architect at AWS targeted on machine studying and serverless utility improvement. With a background in software program engineering and a mix of arts and tech training from Juilliard and Columbia, Yann brings a inventive strategy to AI challenges. He actively shares his experience by way of his YouTube channel, weblog posts, and displays.




